


Keupayaan cemerlang model besar adalah jelas kepada semua, dan jika ia disepadukan ke dalam robot, diharapkan robot akan mempunyai otak yang lebih pintar, membawa kemungkinan baharu kepada bidang robotik, seperti pemanduan autonomi, robot rumah, industri robot, robot tambahan, Robot perubatan, robot medan dan sistem berbilang robot.
Model Bahasa Besar (LLM) yang telah dilatih sebelumnya, Model Bahasa Penglihatan Besar (VLM), Model Bahasa Audio Besar (ALM) dan Model Navigasi Visual Besar (VNM) boleh digunakan untuk menangani pelbagai masalah dalam bidang robotik dengan lebih baik. Tugasan. Mengintegrasikan model asas ke dalam robotik ialah bidang yang berkembang pesat, dan komuniti robotik baru-baru ini mula meneroka penggunaan model besar ini dalam bidang robotik yang perlu ditulis semula: persepsi, ramalan, perancangan dan kawalan.
Baru-baru ini, pasukan penyelidikan bersama yang terdiri daripada Universiti Stanford, Universiti Princeton, NVIDIA, Google DeepMind dan syarikat lain mengeluarkan laporan semakan yang meringkaskan pembangunan dan cabaran masa depan model asas dalam bidang penyelidikan robotik

Kertas alamat: https://arxiv.org/pdf/2312.07843.pdf
Kandungan yang ditulis semula ialah: Pustaka kertas: https://github.com/robotics-survey/Awesome-Robotics-Foundation -Models
Terdapat ramai ulama Cina yang kita kenali di kalangan ahli pasukan, termasuk Zhu Yuke, Song Shuran, Wu Jiajun, Lu Cewu, dll.
Model asas yang telah dilatih secara meluas menggunakan data berskala besar boleh digunakan pada pelbagai tugas hiliran selepas penalaan halus. Model asas ini telah membuat penemuan besar dalam bidang penglihatan dan pemprosesan bahasa, termasuk model berkaitan seperti BERT, GPT-3, GPT-4, CLIP, DALL-E dan PaLM-E
Sebelum kemunculan model asas, untuk robot Model pembelajaran mendalam tradisional dilatih menggunakan set data terhad yang dikumpul untuk tugasan yang berbeza. Sebaliknya, model asas telah dilatih terlebih dahulu menggunakan pelbagai data yang pelbagai dan telah menunjukkan kebolehsuaian, generalisasi dan prestasi keseluruhan dalam bidang lain seperti pemprosesan bahasa semula jadi, penglihatan komputer dan penjagaan kesihatan. Akhirnya, model asas juga dijangka menunjukkan potensinya dalam bidang robotik. Rajah 1 menunjukkan gambaran keseluruhan model asas dalam bidang robotik.
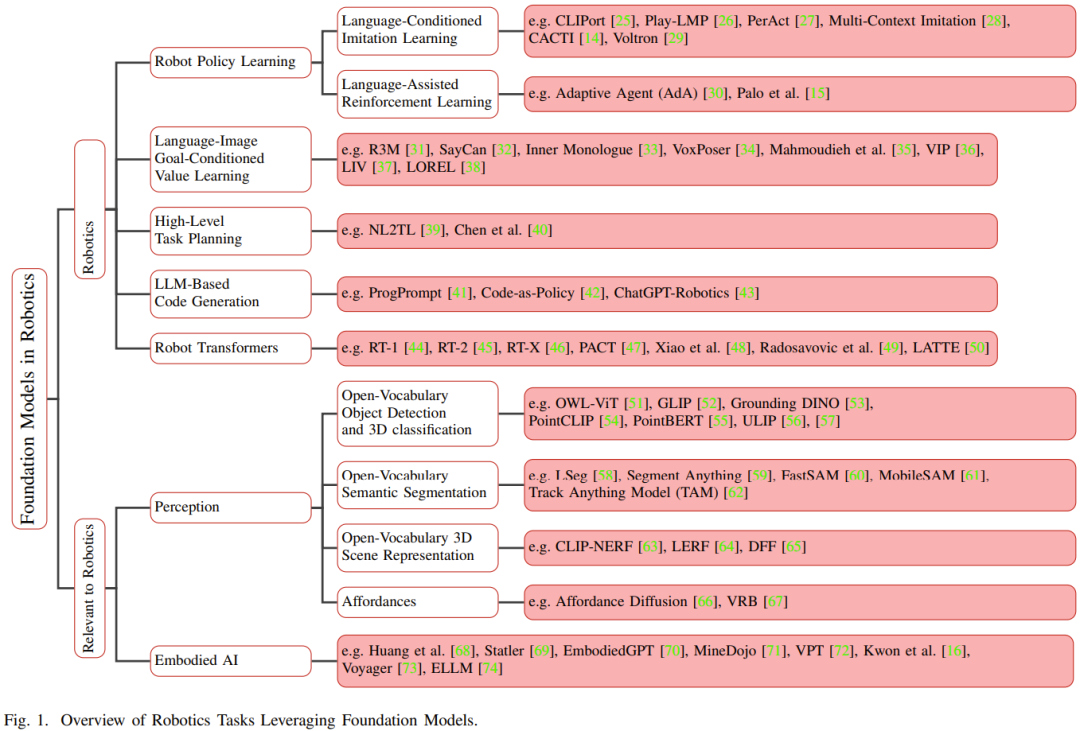
Berbanding dengan model khusus tugasan, pemindahan pengetahuan daripada model asas berpotensi untuk mengurangkan masa latihan dan sumber pengkomputeran. Terutamanya dalam bidang berkaitan robotik, model asas multimodal boleh menggabungkan dan menyelaraskan data heterogen berbilang mod yang dikumpul daripada penderia berbeza ke dalam perwakilan homogen padat, yang diperlukan untuk pemahaman dan penaakulan robot. Perwakilan yang dipelajarinya boleh digunakan dalam mana-mana bahagian tindanan teknologi automasi, termasuk yang perlu ditulis semula: persepsi, membuat keputusan dan kawalan.
Bukan itu sahaja, model asas juga boleh menyediakan keupayaan pembelajaran sifar pukulan, yang membolehkan sistem AI melaksanakan tugas tanpa sebarang contoh atau latihan yang disasarkan. Ini membolehkan robot menyamaratakan pengetahuan yang telah dipelajarinya kepada kes penggunaan baharu, meningkatkan kebolehsuaian dan fleksibiliti robot dalam persekitaran tidak berstruktur.
Mengintegrasikan model asas ke dalam sistem robot boleh meningkatkan keupayaan robot untuk melihat persekitaran dan berinteraksi dengan persekitaran Ia adalah mungkin untuk merealisasikan konteks yang perlu ditulis semula: sistem robot persepsi.
Sebagai contoh, perkara yang perlu ditulis semula ialah: dalam bidang persepsi, model bahasa visual (VLM) berskala besar boleh mempelajari perkaitan antara data visual dan teks, supaya mempunyai keupayaan pemahaman merentas mod, dengan itu membantu pengelasan imej tangkapan sifar, Tugas seperti sampel sifar pengesanan objek dan pengelasan 3D. Sebagai contoh lain, asas bahasa (iaitu, menjajarkan pemahaman kontekstual VLM dengan dunia sebenar 3D) dalam dunia 3D boleh meningkatkan keperluan ruang robot dengan mengaitkan sebutan dengan objek, lokasi atau tindakan tertentu dalam persekitaran 3D : keupayaan untuk melihat.
Dalam bidang membuat keputusan atau perancangan, penyelidikan mendapati bahawa LLM dan VLM boleh membantu robot dalam menentukan tugas yang melibatkan perancangan peringkat tinggi.
Dengan memanfaatkan isyarat bahasa yang berkaitan dengan operasi, navigasi dan interaksi, robot boleh melaksanakan tugas yang lebih kompleks. Sebagai contoh, untuk teknologi pembelajaran dasar robot seperti pembelajaran tiruan dan pembelajaran pengukuhan, model asas nampaknya mempunyai keupayaan untuk meningkatkan kecekapan data dan pemahaman konteks. Khususnya, ganjaran yang didorong oleh bahasa boleh membimbing agen pembelajaran pengukuhan dengan menyediakan ganjaran berbentuk.
Selain itu, penyelidik sudah pun menggunakan model bahasa untuk memberikan maklum balas bagi teknologi pembelajaran dasar. Beberapa kajian telah menunjukkan bahawa keupayaan menjawab soalan visual (VQA) model VLM boleh digunakan untuk kes penggunaan robotik. Sebagai contoh, penyelidik telah menggunakan VLM untuk menjawab soalan yang berkaitan dengan kandungan visual untuk membantu robot menyelesaikan tugas. Selain itu, sesetengah penyelidik menggunakan VLM untuk membantu dengan anotasi data dan menjana label penerangan untuk kandungan visual.
Walaupun model asas mempunyai keupayaan transformatif dalam pemprosesan penglihatan dan bahasa, generalisasi dan penalaan halus model asas untuk tugas robotik dunia sebenar masih agak mencabar.
Cabaran-cabaran ini termasuk:
1) Kekurangan data: Cara mendapatkan data berskala Internet untuk menyokong tugas seperti pengendalian robot, kedudukan, navigasi, dll., dan cara menggunakan data ini untuk latihan yang diselia sendiri
2) Perbezaan besar: Cara menangani kepelbagaian besar persekitaran fizikal, platform robot fizikal dan tugas robot yang berpotensi, sambil mengekalkan keluasan yang diperlukan bagi model asas
3) Masalah kuantifikasi ketidakpastian: Bagaimana untuk menyelesaikan contoh- ketidakpastian tahap (seperti kekaburan bahasa atau ilusi LLM), ketidakpastian tahap pengedaran dan masalah anjakan pengedaran, terutamanya masalah anjakan pengedaran yang disebabkan oleh penggunaan robot gelung tertutup.
4) Penilaian keselamatan: Cara menguji sistem robot dengan teliti berdasarkan model asas sebelum penggunaan, semasa proses kemas kini dan semasa proses kerja.
5) Prestasi masa nyata: Cara menangani masa inferens yang panjang bagi beberapa model asas - yang akan menghalang penggunaan model asas pada robot dan cara mempercepatkan inferens model asas - yang diperlukan untuk keputusan dalam talian- membuat.
Kertas ulasan ini meringkaskan penggunaan semasa model asas dalam bidang robotik. Para penyelidik meninjau kaedah, aplikasi dan cabaran semasa dan mencadangkan arah penyelidikan masa depan untuk menangani cabaran ini. Mereka juga menunjukkan potensi risiko menggunakan model asas untuk mencapai autonomi robot
Pengetahuan latar belakang model asas
Model asas mempunyai berbilion parameter dan dilatih terlebih dahulu menggunakan data berskala besar peringkat Internet. Melatih model yang besar dan kompleks itu sangat mahal. Kos untuk memperoleh, memproses dan mengurus data juga boleh menjadi tinggi. Proses latihannya memerlukan sejumlah besar sumber pengkomputeran, memerlukan penggunaan perkakasan khusus seperti GPU atau TPU, dan juga memerlukan perisian dan infrastruktur untuk latihan model, yang semuanya memerlukan pelaburan kewangan. Di samping itu, masa latihan model asas juga sangat panjang, yang juga membawa kepada kos yang tinggi. Oleh itu, model ini sering digunakan sebagai modul boleh pasang, iaitu menyepadukan model asas ke dalam pelbagai aplikasi tanpa kerja penyesuaian yang meluas
Jadual 1 memberikan butiran model asas yang biasa digunakan.
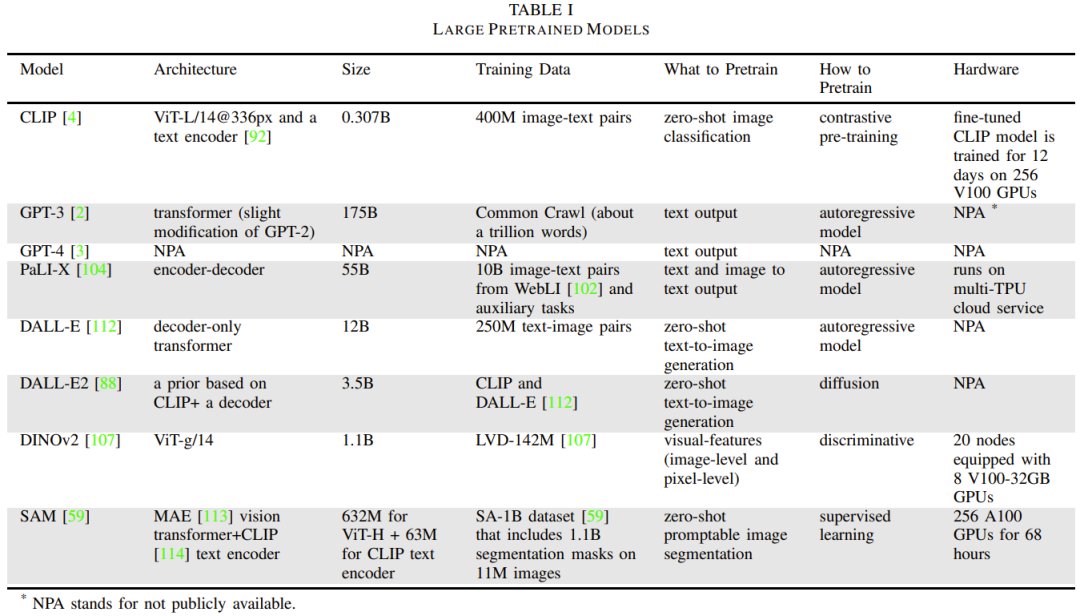
Bahagian ini akan memfokuskan pada LLM, Transformer visual, VLM, model bahasa berbilang modal terjelma dan model generatif visual. Selain itu, kaedah latihan berbeza yang digunakan untuk melatih model asas juga akan diperkenalkan
Mereka mula-mula memperkenalkan beberapa terminologi dan pengetahuan matematik yang berkaitan, yang melibatkan tokenisasi, model generatif, model diskriminatif, seni bina Transformer, model autoregresif, Pengekodan automatik bertopeng, pembelajaran kontrastif , dan model resapan.
Kemudian mereka memperkenalkan contoh dan latar belakang sejarah Model Bahasa Besar (LLM). Selepas itu, Transformer visual, model bahasa penglihatan multimodal (VLM), model bahasa multimodal yang terkandung, dan model generatif visual telah diserlahkan.
Penyelidikan Robot
Bahagian ini memfokuskan pada pembuatan keputusan, perancangan dan kawalan robot. Dalam bidang ini, kedua-dua model bahasa besar (LLM) dan model bahasa visual (VLM) mempunyai potensi untuk digunakan untuk meningkatkan keupayaan robot. Sebagai contoh, LLM boleh memudahkan proses spesifikasi tugas supaya robot boleh menerima dan mentafsir arahan peringkat tinggi daripada manusia.
VLM juga diharapkan dapat menyumbang kepada bidang ini. VLM cemerlang dalam menganalisis data visual. Untuk robot membuat keputusan termaklum dan melaksanakan tugas yang kompleks, pemahaman visual adalah penting. Kini, robot boleh menggunakan isyarat bahasa semula jadi untuk meningkatkan keupayaan mereka untuk melaksanakan tugas yang berkaitan dengan manipulasi, navigasi dan interaksi.
Pembelajaran dasar visual-linguistik berasaskan matlamat (sama ada melalui pembelajaran tiruan atau pembelajaran pengukuhan) dijangka akan ditambah baik oleh model asas. Model bahasa juga boleh memberikan maklum balas untuk teknik pembelajaran dasar. Gelung maklum balas ini membantu mempertingkatkan keupayaan membuat keputusan robot secara berterusan, kerana robot boleh mengoptimumkan tindakannya berdasarkan maklum balas yang diterima daripada LLM.
Bahagian ini memfokuskan kepada aplikasi LLM dan VLM dalam bidang pembuatan keputusan robot.
Bahagian ini terbahagi kepada enam bahagian. Bahagian pertama memperkenalkan pembelajaran dasar untuk membuat keputusan dan kawalan dan robot, termasuk pembelajaran tiruan berasaskan bahasa dan pembelajaran peneguhan berbantukan bahasa.
Bahagian kedua ialah pembelajaran nilai imej bahasa berasaskan matlamat.
Bahagian ketiga memperkenalkan penggunaan model bahasa yang besar untuk merancang tugasan robot, yang termasuk menerangkan tugasan melalui arahan bahasa dan menggunakan model bahasa untuk menjana kod untuk perancangan tugas.
Bahagian keempat ialah pembelajaran kontekstual (ICL) untuk membuat keputusan.
Yang seterusnya yang akan diperkenalkan ialah Robot Transformers
Bahagian keenam ialah navigasi robot dan operasi perpustakaan perbendaharaan kata terbuka.
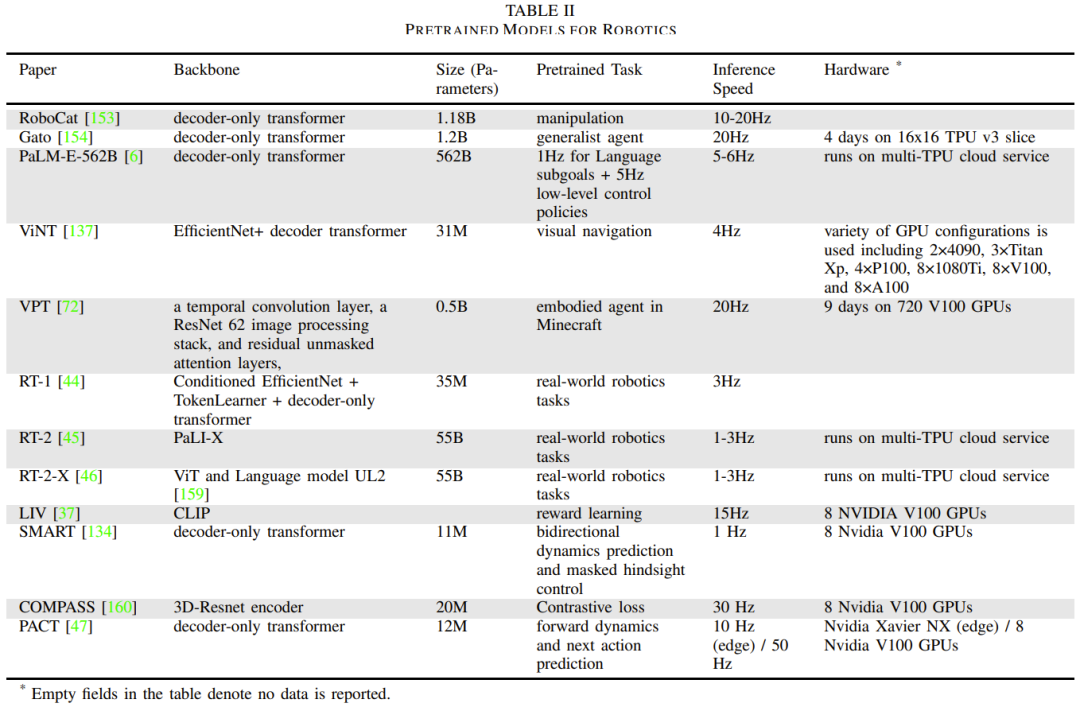
Jadual 2 memberikan beberapa model asas khusus robot, pelaporan saiz dan seni bina model, tugas pra-latihan, masa inferens dan persediaan perkakasan.
Apa yang perlu ditulis semula ialah: persepsi
Robot yang berinteraksi dengan persekitaran sekeliling menerima maklumat deria dalam modaliti yang berbeza, seperti imej, video, audio dan bahasa. Data berdimensi tinggi ini penting untuk robot memahami, menaakul dan berinteraksi dengan persekitaran mereka. Model asas boleh mengubah input berdimensi tinggi ini kepada perwakilan berstruktur abstrak yang mudah ditafsir dan dimanipulasi. Khususnya, model asas multimodal membenarkan robot untuk mengintegrasikan input daripada deria berbeza ke dalam perwakilan bersatu yang mengandungi maklumat semantik, ruang, temporal dan kemampuan. Model multimodal ini memerlukan interaksi silang modal, selalunya memerlukan penjajaran elemen daripada modaliti yang berbeza untuk memastikan konsistensi dan kesesuaian bersama. Sebagai contoh, tugas perihalan imej memerlukan penjajaran teks dan data imej.
Bahagian ini akan menumpukan pada perkara yang robot perlu tulis semula: satu siri tugasan yang berkaitan dengan persepsi, yang boleh dipertingkatkan dengan menggunakan model asas untuk menyelaraskan modaliti. Penekanan adalah pada penglihatan dan bahasa.
Bahagian ini dibahagikan kepada lima bahagian, pertama ialah pengesanan sasaran dan klasifikasi 3D bagi perbendaharaan kata terbuka, kemudian pembahagian semantik perbendaharaan kata terbuka, kemudian ialah adegan 3D dan perwakilan sasaran bagi perbendaharaan kata terbuka, dan kemudian ialah kemampuan yang dipelajari, dan akhirnya model ramalan.
Embodied AI
Baru-baru ini, beberapa kajian telah menunjukkan bahawa LLM boleh berjaya digunakan dalam bidang Embodied AI, di mana "embodied" biasanya merujuk kepada penjelmaan maya dalam simulator dunia, dan bukannya mempunyai badan robot Fizikal.
Beberapa rangka kerja, set data dan model yang menarik telah muncul di kawasan ini. Nota khusus ialah penggunaan permainan Minecraft sebagai platform untuk melatih ejen yang terkandung. Contohnya, Voyager menggunakan GPT-4 untuk membimbing ejen meneroka persekitaran Minecraft. Ia boleh berinteraksi dengan GPT-4 melalui reka bentuk segera kontekstual tanpa perlu memperhalusi parameter model GPT-4.
Pembelajaran peneguhan ialah hala tuju penyelidikan yang penting dalam bidang pembelajaran robot Penyelidik cuba menggunakan model asas untuk mereka bentuk fungsi ganjaran untuk mengoptimumkan pembelajaran peneguhan
Untuk robot melaksanakan perancangan peringkat tinggi, penyelidik telah meneroka penggunaan asas. model untuk membantu. Di samping itu, beberapa penyelidik cuba menggunakan kaedah penaakulan berasaskan rantai pemikiran dan penjanaan tindakan untuk menjelmakan kecerdasan
Cabaran dan hala tuju masa hadapan
Bahagian ini akan memberikan cabaran yang berkaitan dengan menggunakan model asas untuk robot. Pasukan ini juga akan meneroka arah penyelidikan masa depan yang mungkin menangani cabaran ini.
Cabaran pertama adalah untuk mengatasi masalah kekurangan data semasa melatih model asas untuk robot, yang merangkumi:
1 Memperluas pembelajaran robot menggunakan data permainan tidak berstruktur dan video manusia tidak berlabel
2
3 Atasi masalah kekurangan data 3D semasa melatih model asas 3D
4. Hasilkan data sintetik melalui simulasi ketelitian tinggi
5 Menggunakan VLM untuk penambahan data ialah kaedah yang berkesan
6 Kemahiran fizikal robot dihadkan oleh pengagihan kemahiran
Cabaran kedua adalah berkaitan dengan prestasi masa nyata, di mana kuncinya ialah masa inferens model asas. .
Cabaran ketiga melibatkan batasan perwakilan multimodal.
Cabaran keempat ialah cara mengukur ketidakpastian pada tahap yang berbeza, seperti tahap contoh dan tahap pengedaran. Ia juga melibatkan masalah cara menentukur dan menangani anjakan pengedaran.
Cabaran kelima melibatkan penilaian keselamatan, termasuk ujian keselamatan sebelum penggunaan dan pemantauan masa jalan dan pengesanan situasi luar pengedaran.
Cabaran keenam melibatkan cara memilih: menggunakan model asas sedia ada atau membina model asas baharu untuk robot?
Cabaran ketujuh melibatkan kebolehubahan yang tinggi dalam persediaan robot.
Cabaran kelapan ialah cara menanda aras dan memastikan kebolehulangan dalam tetapan robot.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Model besar + robot, laporan ulasan terperinci ada di sini, dengan penyertaan ramai sarjana Cina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Kaedah untuk membaca dan menulis fail java dbf
Kaedah untuk membaca dan menulis fail java dbf
 kekunci pintasan kontras kecerahan ps
kekunci pintasan kontras kecerahan ps
 Padam medan jadual
Padam medan jadual
 penggunaan fungsi fungsi js
penggunaan fungsi fungsi js
 Analisis perbandingan vscode dan studio visual
Analisis perbandingan vscode dan studio visual
 Bagaimana untuk menyelesaikan masalah bahawa folder tidak mempunyai pilihan keselamatan
Bagaimana untuk menyelesaikan masalah bahawa folder tidak mempunyai pilihan keselamatan
 Harga Dogecoin hari ini
Harga Dogecoin hari ini
 psp3000 retak
psp3000 retak








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



