


Dalam dua tahun yang lalu, dengan pembukaan set data imej dan teks berskala besar seperti LAION-5B, satu siri kaedah dengan kesan yang menakjubkan telah muncul dalam bidang penjanaan imej, seperti Stable Diffusion, DALL-E 2, ControlNet dan Komposer. Kemunculan kaedah ini telah membuat terobosan dan kemajuan yang besar dalam bidang penjanaan imej. Bidang penjanaan imej telah berkembang pesat dalam tempoh dua tahun yang lalu.
Walau bagaimanapun, penjanaan video masih menghadapi cabaran besar. Pertama, berbanding dengan penjanaan imej, penjanaan video perlu memproses data berdimensi lebih tinggi dan perlu mengambil kira dimensi masa tambahan, yang membawa masalah pemodelan masa. Untuk memacu pembelajaran dinamik temporal, kami memerlukan lebih banyak data pasangan teks video. Walau bagaimanapun, anotasi temporal video yang tepat adalah sangat mahal, yang mengehadkan saiz set data teks video. Pada masa ini, set data video WebVid10M sedia ada hanya mengandungi 10.7M pasangan teks video Berbanding dengan set data imej LAION-5B, saiz data adalah jauh berbeza. Ini sangat mengehadkan kemungkinan pengembangan model penjanaan video secara besar-besaran.
Untuk menyelesaikan masalah di atas, pasukan penyelidik bersama Universiti Sains dan Teknologi Huazhong, Alibaba Group, Zhejiang University dan Ant Group baru-baru ini mengeluarkan penyelesaian video TF-T2V:

alamat: https: //arxiv.org/abs/2312.15770
Laman utama projek: https://tf-t2v.github.io/
Kod sumber akan dikeluarkan tidak lama lagi: https://github.com /ali-vilab/i2vgen -xl (projek VGen).
Penyelesaian ini mengambil pendekatan baharu dan mencadangkan penjanaan video berdasarkan data video beranotasi tanpa teks berskala besar, yang boleh mempelajari dinamik gerakan yang kaya.
Mula-mula, mari kita lihat kesan penjanaan video TF-T2V:
Tugasan Video Vincent
Kata-kata gesaan: Cipta video yang besar seperti salji tanah berbumbung. 
Kata gesaan: Hasilkan video animasi lebah kartun. 
Kata gesaan: Hasilkan video yang mengandungi motosikal fantasi futuristik. 
Kata gesaan: Hasilkan video budak kecil tersenyum gembira. 
Kata gesaan: Hasilkan video seorang lelaki tua berasa sakit kepala. Tugas penjanaan video 
combined
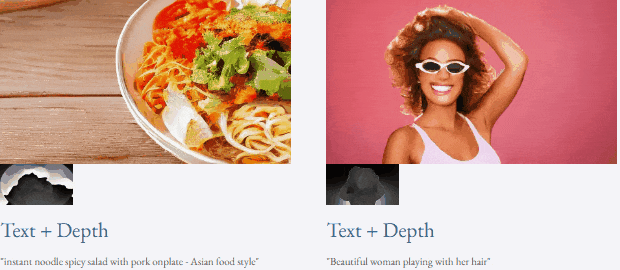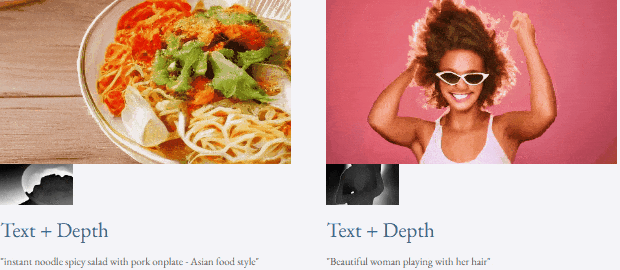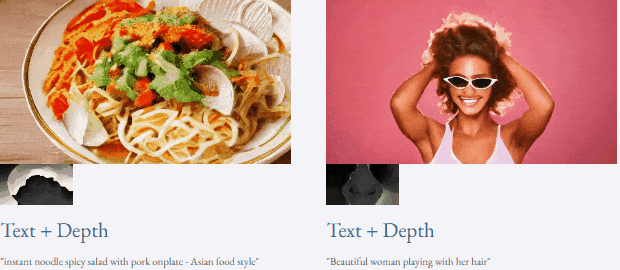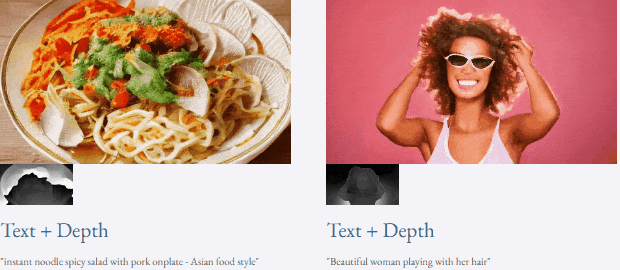
given teks dan peta kedalaman atau teks dan lakaran lakaran, TF-T2V mampu generasi video yang dapat dikawal: 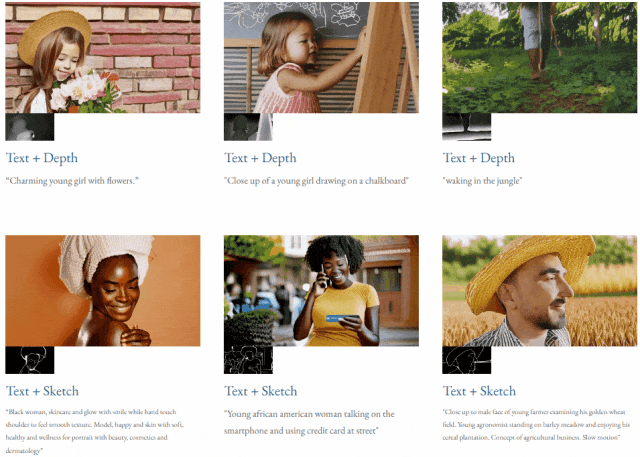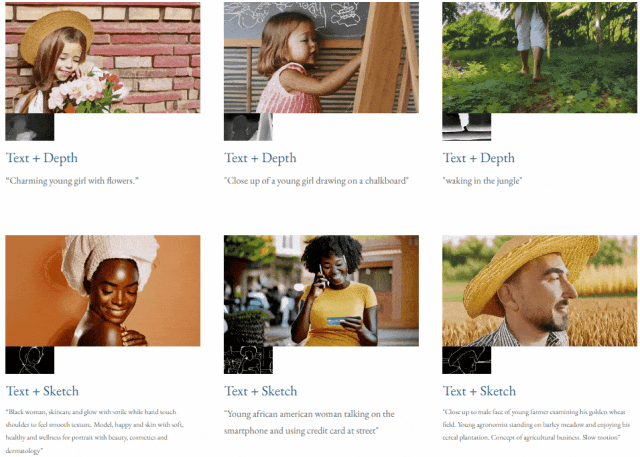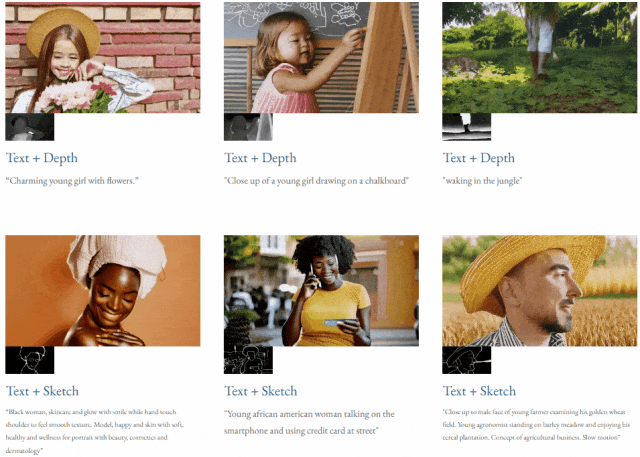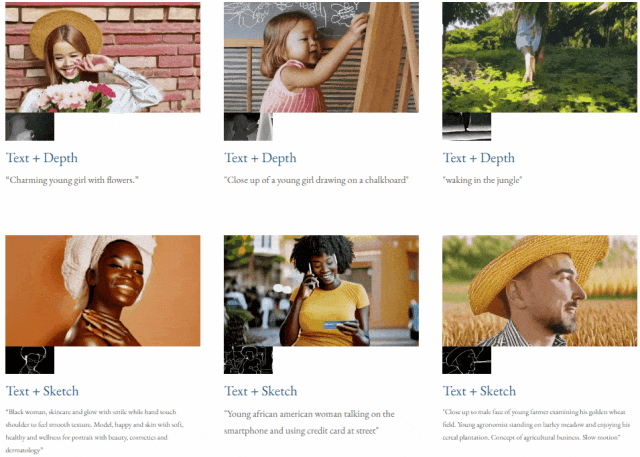
juga tersedia membuat tinggi- sintesis video resolusi: 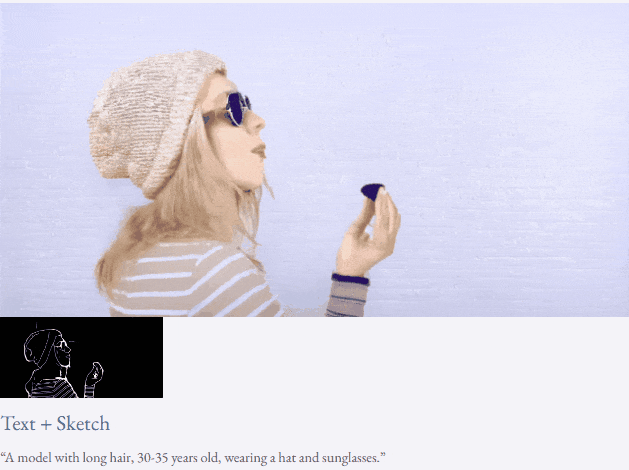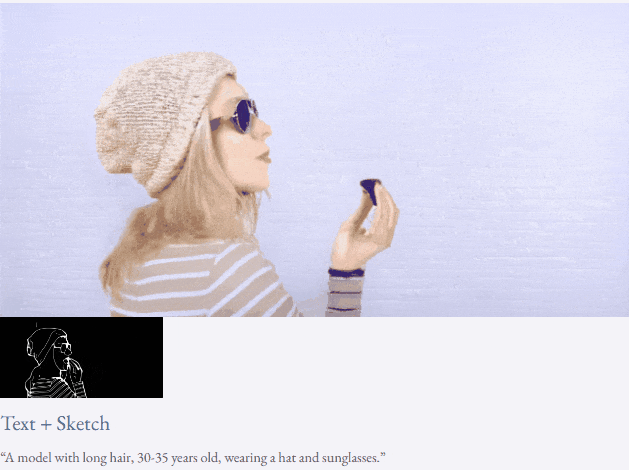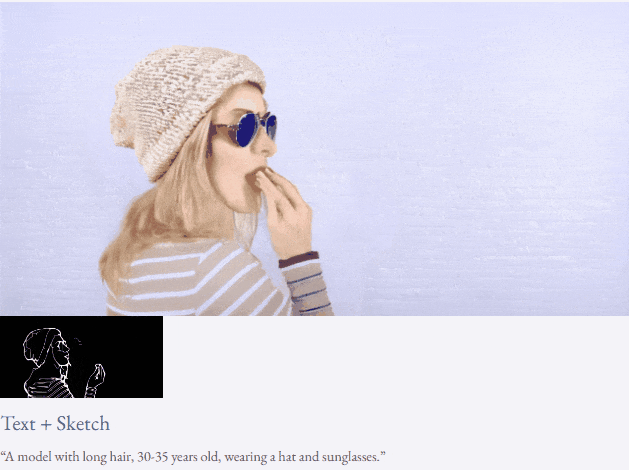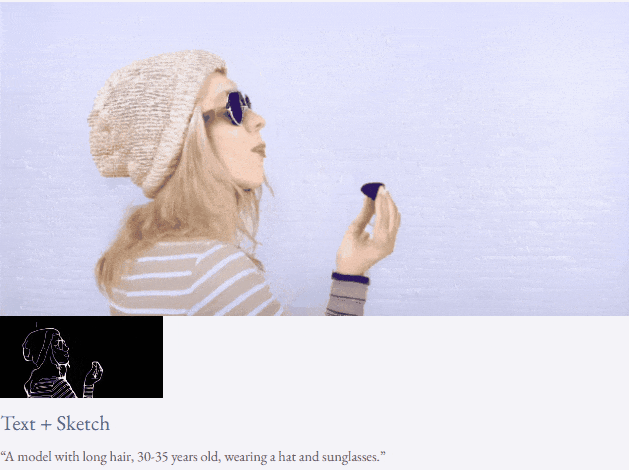
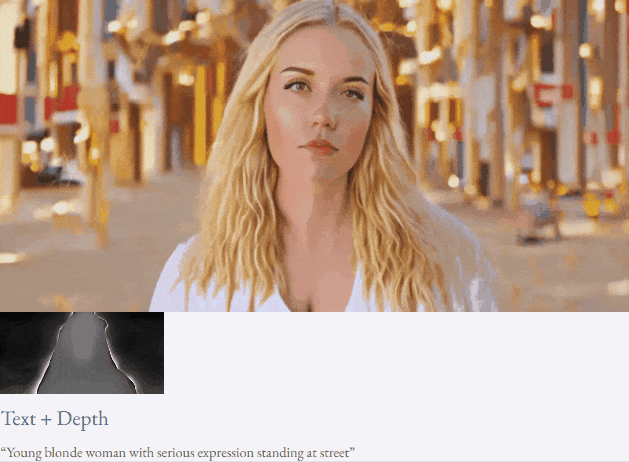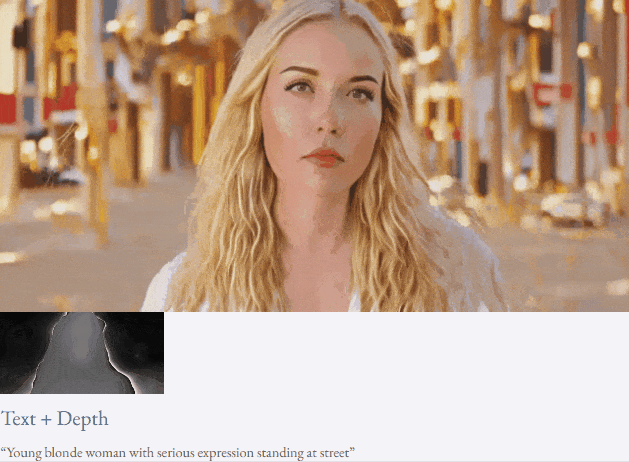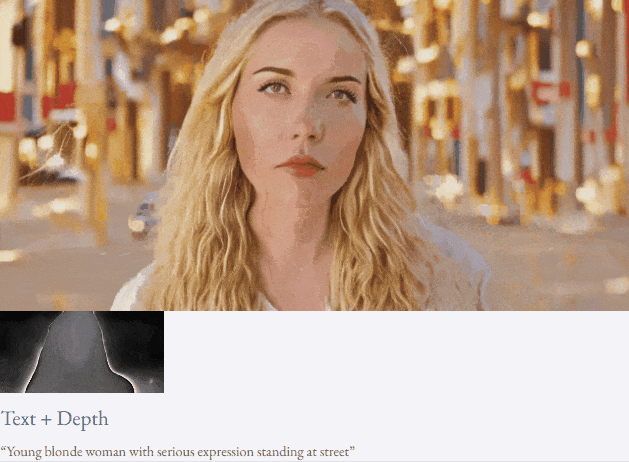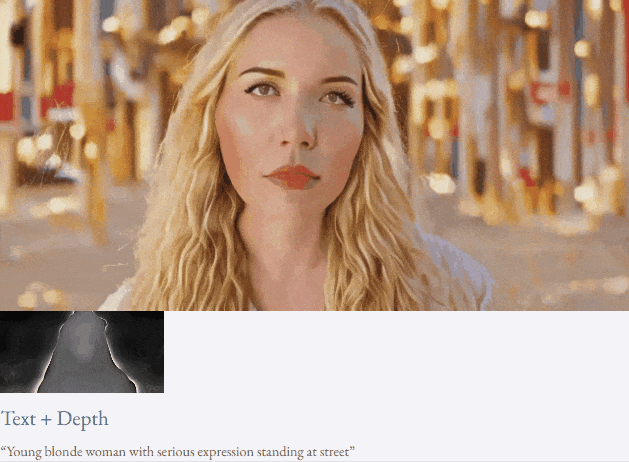
Tetapan separuh seliaan
Kaedah TF-T2V di bawah tetapan separa seliaan juga boleh menjana video yang sepadan dengan perihalan teks gerakan, seperti "Orang ramai berlari dari kanan ke kiri."


Idea teras TF-T2V adalah untuk membahagikan model kepada cabang gerakan dan cabang penampilan, model dan gerakan digunakan cabang rupa digunakan untuk mempelajari maklumat yang jelas. Kedua-dua cabang ini dilatih secara bersama, dan akhirnya boleh mencapai penjanaan video dipacu teks.
Untuk meningkatkan ketekalan temporal video yang dijana, pasukan pengarang juga mencadangkan kehilangan ketekalan temporal untuk mempelajari secara jelas kesinambungan antara bingkai video.
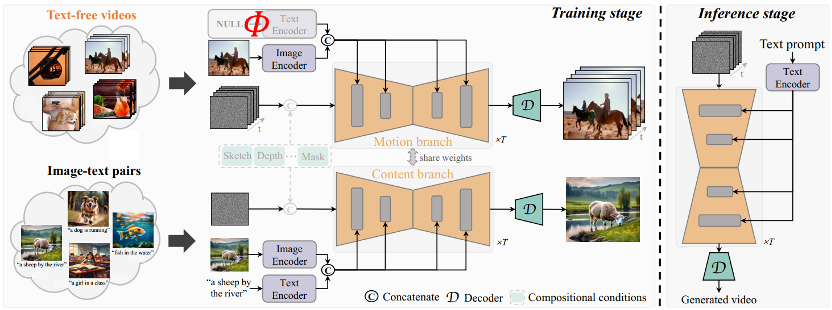
Perlu dinyatakan bahawa TF-T2V ialah rangka kerja umum yang bukan sahaja sesuai untuk tugasan video Vincent, tetapi juga untuk tugas penjanaan video gabungan, seperti lakaran-ke-video, lukisan video, bingkai pertama -ke-video dll.
Untuk butiran khusus dan lebih banyak hasil percubaan, sila rujuk kertas asal atau halaman utama projek.
Selain itu, pasukan pengarang juga menggunakan TF-T2V sebagai model guru dan menggunakan teknologi penyulingan yang konsisten untuk mendapatkan model VideoLCM:

Alamat kertas: https://arxiv.org/abs/ 2312.09109
Laman utama projek: https://tf-t2v.github.io/
Kod sumber akan dikeluarkan tidak lama lagi: https://github.com/ali-vilab/i2vgen-xl (projek VGen) .
Berbeza dengan kaedah penjanaan video sebelum ini yang memerlukan kira-kira 50 langkah denoising DDIM, kaedah VideoLCM berdasarkan TF-T2V boleh menjana video berkesetiaan tinggi dengan hanya kira-kira 4 langkah denoising inferens, yang sangat meningkatkan kecekapan penjanaan video. kecekapan.
Mari kita lihat keputusan inferens denoising 4-langkah VideoLCM:


untuk keputusan projek yang asli dan lebih lanjut sila rujuk kepada kertas kerja LC laman utama.
Secara keseluruhannya, penyelesaian TF-T2V membawa idea baharu kepada bidang penjanaan video dan mengatasi cabaran yang disebabkan oleh saiz set data dan masalah pelabelan. Memanfaatkan data video anotasi tanpa teks berskala besar, TF-T2V mampu menjana video berkualiti tinggi dan digunakan pada pelbagai tugas penjanaan video. Inovasi ini akan menggalakkan pembangunan teknologi penjanaan video dan membawa senario aplikasi dan peluang perniagaan yang lebih luas kepada semua lapisan masyarakat.
🎜Atas ialah kandungan terperinci Teknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apa yang perlu dilakukan dengan kad video
Apa yang perlu dilakukan dengan kad video
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Bagaimana untuk memuat turun video dari Douyin
Bagaimana untuk memuat turun video dari Douyin
 penggunaan fungsi rowcount
penggunaan fungsi rowcount
 Bagaimana untuk mengubah suai keizinan folder 777
Bagaimana untuk mengubah suai keizinan folder 777
 Cara menggunakan setrequestproperty
Cara menggunakan setrequestproperty
 Bagaimana untuk memadam halaman kosong dalam perkataan tanpa menjejaskan format lain
Bagaimana untuk memadam halaman kosong dalam perkataan tanpa menjejaskan format lain
 Bagaimana untuk memulihkan data pelayan
Bagaimana untuk memulihkan data pelayan







![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



