Sekarang ini, semua kerja rumah telah diambil alih oleh robot.
Robot dari Stanford yang boleh menggunakan periuk baru muncul, dan robot yang boleh menggunakan mesin kopi baru sahaja tiba, Rajah-01.

Rajah-01 Lihat sahaja video demonstrasi dan jalankan latihan selama 10 jam untuk dapat mengendalikan mesin kopi dengan mahir. Daripada memasukkan kapsul kopi hingga menekan butang mula, semuanya dilakukan sekali gus.
Walau bagaimanapun, ia adalah masalah yang sukar untuk membolehkan robot belajar secara bebas menggunakan pelbagai perabot dan peralatan rumah tanpa memerlukan video demonstrasi apabila menghadapinya. Ini memerlukan robot mempunyai persepsi visual yang kuat dan keupayaan membuat keputusan, serta kemahiran manipulasi yang tepat.
Kini, sistem model besar grafik dan teks terkandung tiga dimensi memberikan idea baharu untuk masalah di atas. Sistem ini menggabungkan model persepsi geometri yang tepat berdasarkan penglihatan tiga dimensi dengan model besar grafik dan teks dua dimensi yang pandai merancang Ia boleh menyelesaikan tugas jangka panjang yang kompleks berkaitan dengan perabot dan peralatan rumah tanpa memerlukan data sampel . Penyelidikan ini telah disiapkan oleh pasukan Profesor Leonidas Guibas dari Universiti Stanford, Profesor Wang He dari Universiti Peking, dan Institut Penyelidikan Kepintaran Buatan Zhiyuan. 
Pautan kertas: https://arxiv.org/abs/2312.01307
Laman utama projek: https://geometry.stanford.edu/projects/sage/
Kod: https://github.com/ geng-haoran/SAGE
Tinjauan Masalah Kajian

Rajah 1: Mengikut arahan manusia, lengan robot boleh menggunakan pelbagai peralatan rumah tanpa sebarang arahan.
Baru-baru ini, PaLM-E dan GPT-4V telah mempromosikan aplikasi model grafik besar dalam perancangan tugas robot, dan kawalan robot umum dipandu oleh bahasa visual telah menjadi bidang penyelidikan yang popular.
Kaedah biasa pada masa lalu ialah membina sistem dua lapisan Model grafik besar lapisan atas melakukan perancangan dan penjadualan kemahiran, dan model strategi kemahiran kawalan lapisan bawah bertanggungjawab untuk melaksanakan tindakan secara fizikal. Tetapi apabila robot menghadapi pelbagai peralatan rumah yang tidak pernah mereka lihat sebelum ini dan memerlukan operasi berbilang langkah dalam kerja rumah, kedua-dua lapisan atas dan bawah kaedah sedia ada akan menjadi tidak berdaya.
Ambil model grafik paling canggih GPT-4V sebagai contoh Walaupun ia boleh menggambarkan satu gambar dengan teks, ia masih penuh dengan ralat apabila ia berkaitan dengan pengesanan, pengiraan, kedudukan dan anggaran status bahagian yang boleh dikendalikan. Sorotan merah dalam Rajah 2 ialah pelbagai ralat GPT-4V yang dibuat semasa menerangkan gambar almari laci, ketuhar dan kabinet berdiri. Berdasarkan penerangan yang salah, penjadualan kemahiran robot itu jelas tidak boleh dipercayai.

Rajah 2: GPT-4V tidak boleh mengendalikan tugas yang tertumpu pada kawalan umum seperti mengira, pengesanan, penganggaran dan keadaan
Model strategi kemahiran kawalan peringkat bawah bertanggungjawab untuk melaksanakan tugasan yang diberikan oleh model grafik dan teks peringkat atas dalam pelbagai situasi sebenar. Kebanyakan hasil penyelidikan sedia ada secara tegar mengekod titik pegangan dan kaedah operasi beberapa objek yang diketahui berdasarkan peraturan, dan secara amnya tidak boleh menangani kategori objek baharu yang belum pernah dilihat sebelum ini. Walau bagaimanapun, model operasi hujung ke hujung (seperti RT-1, RT-2, dsb.) hanya menggunakan modaliti RGB, kurang persepsi jarak yang tepat dan mempunyai generalisasi yang lemah kepada perubahan dalam persekitaran baharu seperti ketinggian.
Diilhamkan oleh kerja CVPR Highlight GAPartNet [1] pasukan Profesor Wang He sebelum ini, pasukan penyelidik memfokuskan pada bahagian biasa (GAParts) dalam pelbagai kategori perkakas rumah. Walaupun perkakas rumah sentiasa berubah, sentiasa terdapat beberapa bahagian yang amat diperlukan. Terdapat geometri dan corak interaksi yang serupa antara setiap perkakas rumah dan bahagian biasa ini.
Hasilnya, pasukan penyelidik memperkenalkan konsep GAPart dalam kertas GAPartNet [1]. GAPart merujuk kepada komponen yang boleh digeneralisasikan dan interaktif. GAPart muncul pada kategori objek berengsel yang berbeza Contohnya, pintu berengsel boleh didapati dalam peti besi, almari pakaian dan peti sejuk. Seperti yang ditunjukkan dalam Rajah 3, GAPartNet [1] menganotasi semantik dan pose GAPart pada pelbagai jenis objek.

Rajah 3: GAPart: bahagian yang boleh digeneralisasikan dan interaktif [1].
Berdasarkan kajian terdahulu, pasukan penyelidik secara kreatif memperkenalkan GAPart berdasarkan penglihatan tiga dimensi ke dalam sistem manipulasi objek robot SAGE. SAGE akan menyediakan maklumat untuk VLM dan LLM melalui pengesanan bahagian 3D yang boleh digeneralisasikan dan anggaran pose yang tepat. Pada peringkat membuat keputusan, kaedah baharu menyelesaikan masalah pengiraan tepat yang tidak mencukupi dan keupayaan penaakulan model grafik dua dimensi pada peringkat pelaksanaan, kaedah baharu mencapai operasi umum pada setiap bahagian melalui API operasi fizikal yang teguh berdasarkan; GAPart bergambar.
SAGE membentuk sistem model grafik dan teks berskala besar terwujud tiga dimensi yang pertama, menyediakan idea baharu untuk keseluruhan pautan robot daripada persepsi, interaksi fizikal kepada maklum balas dan meneroka cara baharu bagi robot untuk mengawal objek kompleks secara bijak dan universal seperti sebagai perabot dan peralatan rumah.
Pengenalan Sistem
Rajah 4 menunjukkan proses asas SAGE. Pertama, modul tafsiran arahan yang mampu mentafsir konteks akan menghuraikan input arahan kepada robot dan pemerhatiannya, dan menukar penghuraian ini kepada program tindakan robot seterusnya dan bahagian semantiknya yang berkaitan. Seterusnya, SAGE memetakan bahagian semantik (seperti bekas) ke bahagian yang perlu dikendalikan (seperti butang peluncur) dan menjana tindakan (seperti tindakan "tekan" butang) untuk menyelesaikan tugas.

Rajah 4: Gambaran keseluruhan kaedah.
Untuk memudahkan semua orang memahami keseluruhan proses sistem, mari kita lihat contoh penggunaan lengan robot untuk mengendalikan ketuhar gelombang mikro yang tidak kelihatan tanpa memerlukan sampel. . Selepas itu, LLM (GPT-4) mengambil arahan dan penerangan adegan sebagai input untuk menjana bahagian semantik dan program tindakan. Sebagai alternatif, anda boleh memasukkan manual pengguna tertentu dalam pautan ini. LLM akan menjana sasaran bahagian yang boleh dikendalikan berdasarkan input. Rajah 5: Penjanaan penerangan adegan (mengambil gambar sifar menggunakan ketuhar gelombang mikro sebagai contoh). Untuk membantu penjanaan aksi dengan lebih baik, penerangan adegan mengandungi maklumat objek, maklumat bahagian dan beberapa maklumat berkaitan interaksi. Sebelum menjana penerangan senario, SAGE juga akan menggunakan model GAPart pakar [1] untuk menjana penerangan pakar untuk VLM sebagai gesaan. Pendekatan ini, yang menggabungkan yang terbaik daripada kedua-dua model, berfungsi dengan baik. 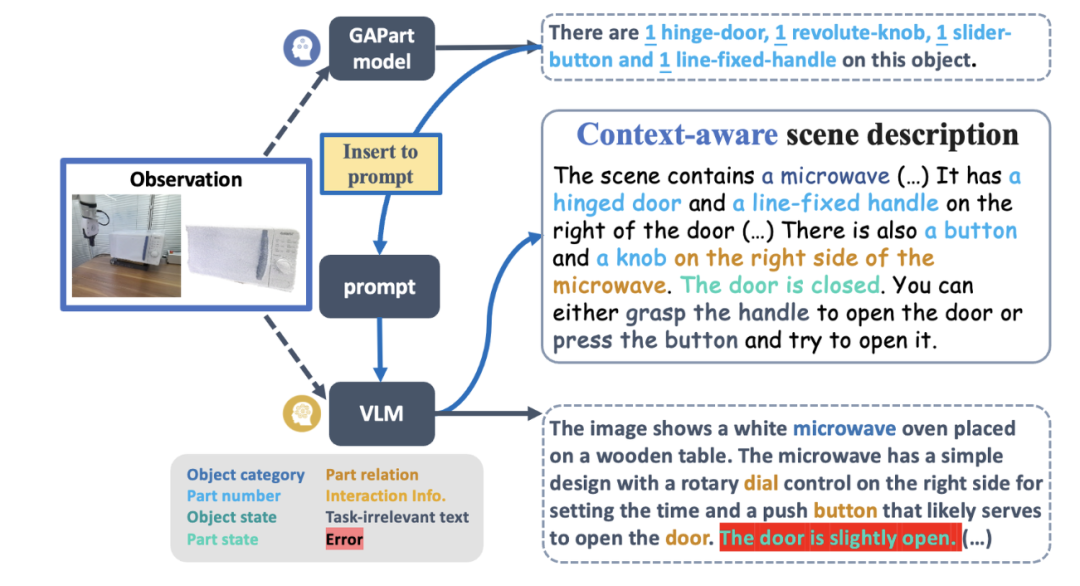 Rajah 6: Pemahaman arahan dan perancangan pergerakan (mengambil contoh sifar pukulan ketuhar gelombang mikro).
Rajah 6: Pemahaman arahan dan perancangan pergerakan (mengambil contoh sifar pukulan ketuhar gelombang mikro). 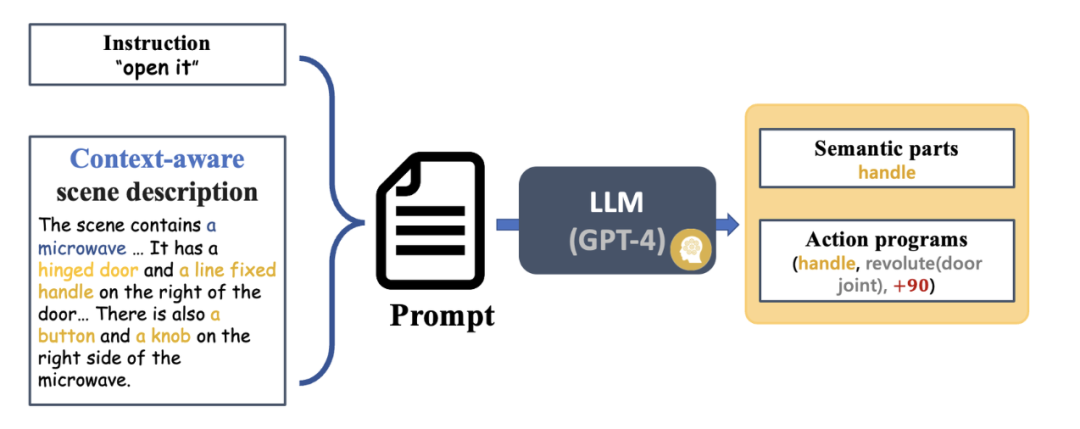 Pemahaman dan persepsi maklumat interaksi bahagian Rajah 7: Bahagian pemahaman.
Pemahaman dan persepsi maklumat interaksi bahagian Rajah 7: Bahagian pemahaman.
Dalam proses memasukkan pemerhatian, SAGE menggabungkan isyarat dua dimensi (2D) daripada GroundedSAM dan tiga dimensi (3D) daripada GAPartNet, yang kemudiannya digunakan sebagai kedudukan khusus bahagian yang boleh dikendalikan. Pasukan penyelidik menggunakan ScoreNet, penindasan bukan maksimum (NMS) dan PoseNet untuk menunjukkan hasil persepsi kaedah baharu. 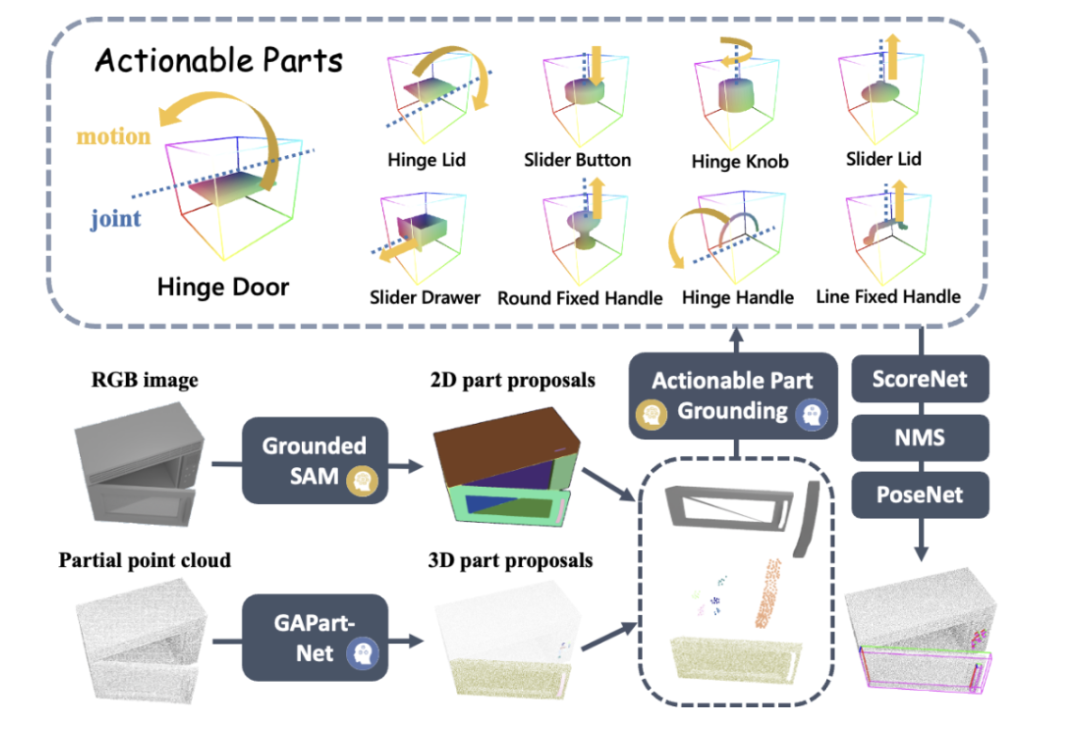 Antaranya: (1) Untuk penanda aras penilaian yang sedar sebahagian, artikel tersebut secara langsung menggunakan SAM [2]. Walau bagaimanapun, dalam aliran operasi, artikel menggunakan GroundedSAM, yang juga mengambil kira bahagian semantik sebagai input. (2) Jika model bahasa besar (LLM) secara langsung mengeluarkan sasaran bahagian yang boleh dikendalikan, proses penentududukan akan dipintas. Rajah 8: Pemahaman bahagian (mengambil ketuhar gelombang mikro pukulan sifar sebagai contoh).
Antaranya: (1) Untuk penanda aras penilaian yang sedar sebahagian, artikel tersebut secara langsung menggunakan SAM [2]. Walau bagaimanapun, dalam aliran operasi, artikel menggunakan GroundedSAM, yang juga mengambil kira bahagian semantik sebagai input. (2) Jika model bahasa besar (LLM) secara langsung mengeluarkan sasaran bahagian yang boleh dikendalikan, proses penentududukan akan dipintas. Rajah 8: Pemahaman bahagian (mengambil ketuhar gelombang mikro pukulan sifar sebagai contoh).  Penjanaan TindakanSetelah bahagian semantik diletakkan di atas bahagian yang boleh dikendalikan, SAGE akan menjana tindakan operasi boleh laku pada bahagian ini. Pertama, SAGE menganggarkan pose bahagian, mengira keadaan artikulasi (paksi dan kedudukan bahagian) dan kemungkinan arah gerakan berdasarkan jenis artikulasi (terjemahan atau putaran). Ia kemudian menjana pergerakan untuk robot mengendalikan bahagian berdasarkan anggaran ini. Dalam tugas menghidupkan ketuhar gelombang mikro, SAGE terlebih dahulu meramalkan bahawa lengan robot perlu mengambil postur pencengkam awal sebagai tindakan utama. Tindakan kemudian dijana berdasarkan strategi yang telah ditetapkan ditakrifkan dalam GAPartNet [1]. Strategi ini ditentukan berdasarkan pose bahagian dan status artikulasi. Contohnya, untuk membuka pintu dengan engsel berputar, kedudukan permulaan boleh berada di tepi pintu atau pada pemegang, dengan trajektori berorientasikan arka di sepanjang engsel pintu.
Penjanaan TindakanSetelah bahagian semantik diletakkan di atas bahagian yang boleh dikendalikan, SAGE akan menjana tindakan operasi boleh laku pada bahagian ini. Pertama, SAGE menganggarkan pose bahagian, mengira keadaan artikulasi (paksi dan kedudukan bahagian) dan kemungkinan arah gerakan berdasarkan jenis artikulasi (terjemahan atau putaran). Ia kemudian menjana pergerakan untuk robot mengendalikan bahagian berdasarkan anggaran ini. Dalam tugas menghidupkan ketuhar gelombang mikro, SAGE terlebih dahulu meramalkan bahawa lengan robot perlu mengambil postur pencengkam awal sebagai tindakan utama. Tindakan kemudian dijana berdasarkan strategi yang telah ditetapkan ditakrifkan dalam GAPartNet [1]. Strategi ini ditentukan berdasarkan pose bahagian dan status artikulasi. Contohnya, untuk membuka pintu dengan engsel berputar, kedudukan permulaan boleh berada di tepi pintu atau pada pemegang, dengan trajektori berorientasikan arka di sepanjang engsel pintu. Maklum balas interaksi
Setakat ini, pasukan penyelidik hanya menggunakan pemerhatian awal untuk menjana interaksi gelung terbuka. Pada ketika ini, mereka memperkenalkan mekanisme untuk mengeksploitasi lebih lanjut pemerhatian yang diperoleh semasa interaksi, mengemas kini keputusan yang dirasakan dan menyesuaikan operasi dengan sewajarnya. Untuk mencapai matlamat ini, pasukan penyelidik memperkenalkan mekanisme maklum balas dua bahagian kepada proses interaksi. Perlu diingatkan bahawa ralat oklusi dan anggaran mungkin berlaku semasa proses persepsi pemerhatian pertama. Rajah 9: Pintu tidak boleh dibuka terus, dan pusingan interaksi ini gagal (ambil gambar sifar menggunakan ketuhar gelombang mikro sebagai contoh). Bagi menyelesaikan masalah ini, penyelidik seterusnya mencadangkan model yang menggunakan pemerhatian interaktif (Persepsi Interaktif) untuk meningkatkan operasi. Penjejakan pencengkam sasaran dan status bahagian dikekalkan sepanjang interaksi.Jika penyelewengan ketara berlaku, perancang boleh memilih salah satu daripada empat keadaan: "Teruskan", "Bergerak ke langkah seterusnya", "Berhenti dan rancang semula" atau "Berjaya". Sebagai contoh, jika anda menetapkan pencengkam untuk berputar 60 darjah di sepanjang sambungan, tetapi pintu hanya dibuka 15 darjah, perancang Model Bahasa Besar (LLM) akan memilih Berhenti dan Rancang Semula. Model penjejakan interaktif ini memastikan LLM boleh menganalisis masalah tertentu semasa proses interaksi dan boleh "berdiri" semula walaupun mengalami kegagalan permulaan ketuhar gelombang mikro. Rajah 10: Melalui maklum balas interaktif dan perancangan semula, robot menyedari cara untuk membuka butang dan berjaya. Pasukan penyelidik mula-mula membina tanda aras ujian interaksi objek artikulasi berpandukan bahasa berskala besar.
Rajah 11: Eksperimen simulasi SAPIEN.
Mereka menggunakan persekitaran SAPIEN [4] untuk menjalankan eksperimen simulasi dan mereka bentuk 12 tugas manipulasi objek diartikulasikan berpandukan bahasa. Untuk setiap kategori ketuhar gelombang mikro, perabot storan dan kabinet, 3 tugasan telah direka bentuk, termasuk keadaan terbuka dan tertutup dalam keadaan awal yang berbeza. Tugas lain ialah "Buka penutup periuk", "Tekan butang pada alat kawalan jauh" dan "Mulakan pengisar". Keputusan eksperimen menunjukkan bahawa SAGE berprestasi baik dalam hampir semua tugas. 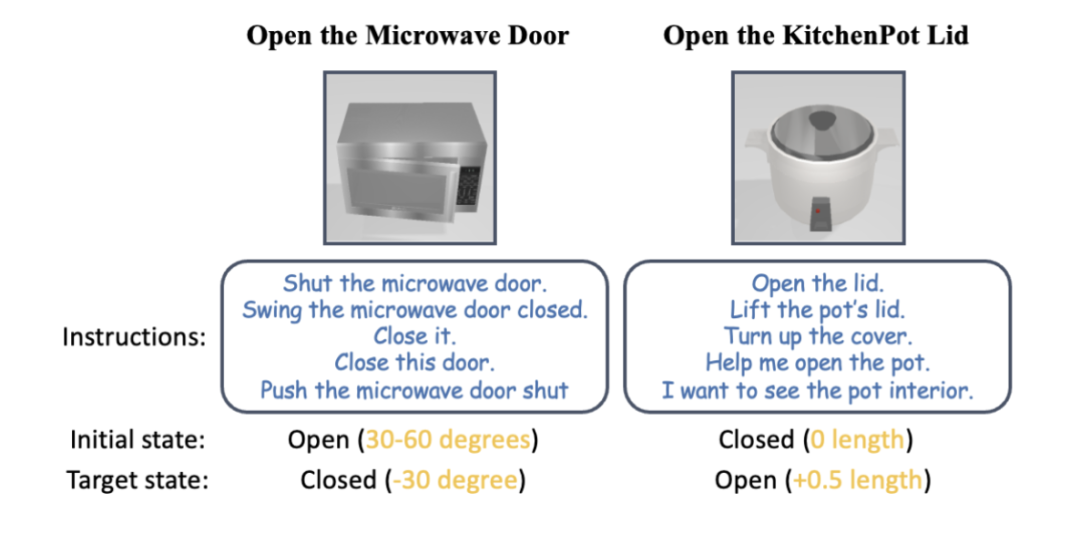 Rajah 12: Demonstrasi mesin sebenar. Pasukan penyelidik juga menjalankan eksperimen dunia nyata berskala besar menggunakan UFACTORY xArm 6 dan pelbagai objek artikulasi yang berbeza. Bahagian kiri atas imej di atas menunjukkan contoh memulakan pengisar. Bahagian atas pengisar dianggap sebagai bekas untuk jus, tetapi fungsi sebenar memerlukan tekan butang untuk mengaktifkan. Rangka kerja SAGE secara berkesan merapatkan pemahaman semantik dan tindakan serta berjaya melaksanakan tugas. Bahagian atas sebelah kanan gambar di atas menunjukkan robot, yang perlu menekan (bawah) butang berhenti kecemasan untuk menghentikan operasi dan berputar (atas) untuk memulakan semula. Lengan robot dipandu oleh SAGE menyelesaikan kedua-dua tugas dengan input tambahan daripada manual pengguna. Imej di bahagian bawah imej di atas menunjukkan lebih terperinci dalam tugas menghidupkan gelombang mikro.
Rajah 12: Demonstrasi mesin sebenar. Pasukan penyelidik juga menjalankan eksperimen dunia nyata berskala besar menggunakan UFACTORY xArm 6 dan pelbagai objek artikulasi yang berbeza. Bahagian kiri atas imej di atas menunjukkan contoh memulakan pengisar. Bahagian atas pengisar dianggap sebagai bekas untuk jus, tetapi fungsi sebenar memerlukan tekan butang untuk mengaktifkan. Rangka kerja SAGE secara berkesan merapatkan pemahaman semantik dan tindakan serta berjaya melaksanakan tugas. Bahagian atas sebelah kanan gambar di atas menunjukkan robot, yang perlu menekan (bawah) butang berhenti kecemasan untuk menghentikan operasi dan berputar (atas) untuk memulakan semula. Lengan robot dipandu oleh SAGE menyelesaikan kedua-dua tugas dengan input tambahan daripada manual pengguna. Imej di bahagian bawah imej di atas menunjukkan lebih terperinci dalam tugas menghidupkan gelombang mikro.
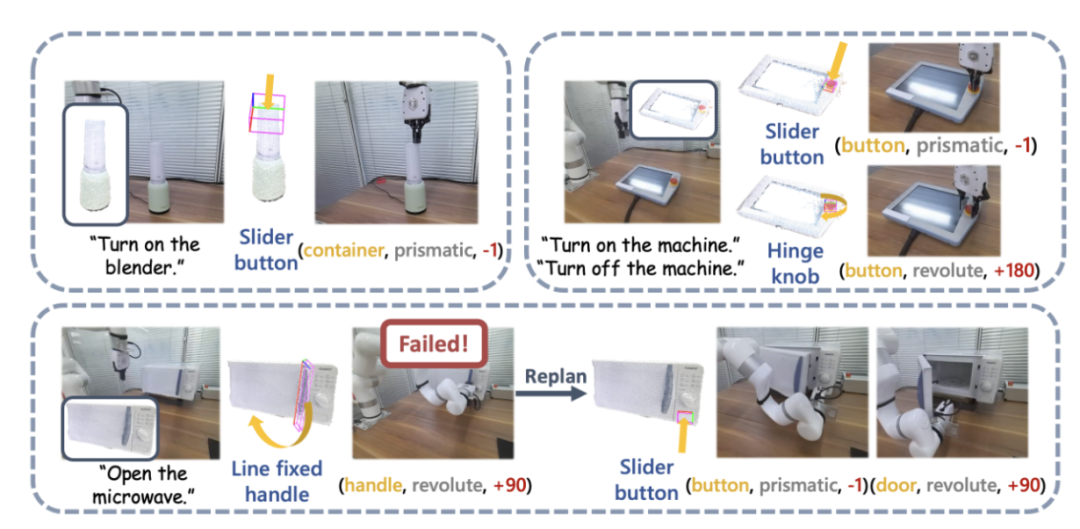
Rajah 13: Lebih banyak contoh demonstrasi mesin sebenar dan tafsiran arahan.
Ringkasan
SAGE ialah rangka kerja model bahasa visual 3D pertama yang boleh menjana arahan umum untuk mengawal objek artikulasi yang kompleks seperti perabot dan peralatan rumah. Ia menukar tindakan yang diarahkan bahasa kepada manipulasi boleh laku dengan menghubungkan semantik objek dan pemahaman kebolehkendalian pada peringkat bahagian.

Selain itu, artikel ini juga mengkaji kaedah untuk menggabungkan model penglihatan/bahasa berskala besar umum dengan model pakar domain untuk meningkatkan kekomprekan dan ketepatan ramalan rangkaian, mengendalikan tugas ini dengan lebih baik dan mencapai keadaan terkini. persembahan seni. Keputusan eksperimen menunjukkan bahawa rangka kerja mempunyai keupayaan generalisasi yang kukuh dan boleh menunjukkan prestasi unggul pada kategori objek dan tugasan yang berbeza. Di samping itu, artikel itu menyediakan penanda aras baharu untuk manipulasi berpandukan bahasa bagi objek yang diartikulasikan.
Pengenalan Pasukan
SAGE Hasil penyelidikan ini datang daripada makmal Profesor Leonidas Guibas dari Universiti Stanford, Persepsi dan Interaksi Terwujud (EPIC Lab) Profesor Wang He dari Universiti Peking, dan Institut Penyelidikan Kepintaran Buatan Zhiyuan. Penulis kertas kerja ialah pelajar Universiti Peking dan sarjana pelawat Universiti Stanford Geng Haoran (pengarang bersama), pelajar kedoktoran Universiti Peking Wei Songlin (pengarang bersama), pelajar kedoktoran Universiti Stanford Deng Congyue dan Shen Bokui, dan penyelia ialah Profesor Leonidas Guibas dan Profesor Wang He .
Rujukan:
[1] Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi, Siyuan Huang dan He Wang. Gapartnet: Persepsi dan manipulasi objek boleh digeneralisasikan domain silang kategori melalui bahagian yang boleh digeneralisasikan dan boleh diambil tindakan. pracetak arXiv arXiv:2211.05272, 2022.
[2] Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao et al. "Segmenkan apa-apa sahaja."
[3] Zhang,Hao,Feng Li,Shilong Liu,Lei Zhang,Hang Su,Jun Zhu,Lionel M。Ni,dan Heung-Yeung Shum。"Dino: Detr dengan kotak sauh denoising yang dipertingkatkan untuk hujung ke- pengesanan objek tamat." pracetak arXiv arXiv:2203.03605 (2022).
[4] Xiang,Fanbo,Yuzhe Qin,Kaichun Mo,Yikuan Xia,Hao Zhu,Fangchen Liu,Minghua Liu et. persekitaran interaktif." Dalam Prosiding Persidangan IEEE/CVF mengenai Penglihatan Komputer dan Pengecaman Corak,pp。11097-11107。2020.
Atas ialah kandungan terperinci Sistem model grafik tiga dimensi tujuan umum pertama untuk perabot dan peralatan rumah yang tidak memerlukan bimbingan dan menggunakan model visual untuk generalisasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



