Baru-baru ini, sistem sintesis pertuturan berdasarkan Jambatan Schrödinger [1] yang dikeluarkan oleh kumpulan penyelidik Profesor Zhu Jun dari Jabatan Sains Komputer di Universiti Tsinghua mengalahkan model resapan dari segi kualiti sampel dan kelajuan pensampelan berdasarkan "data-"nya. paradigma penjanaan kepada-data". Paradigma "noise-to-data". 
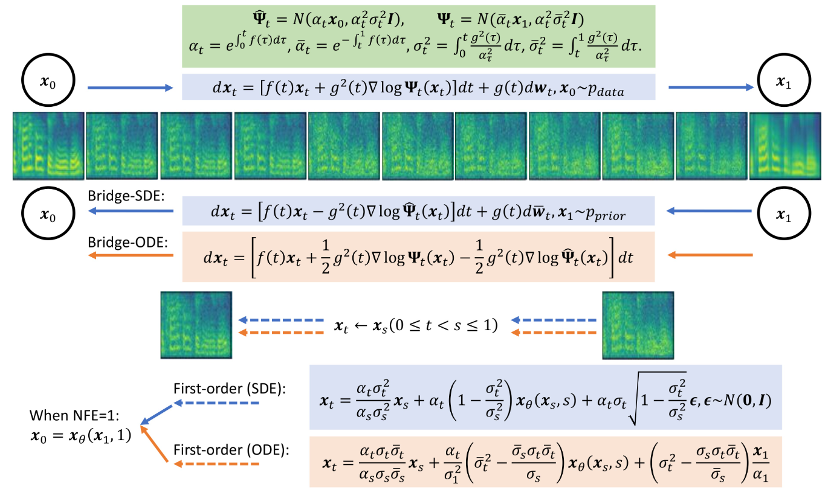
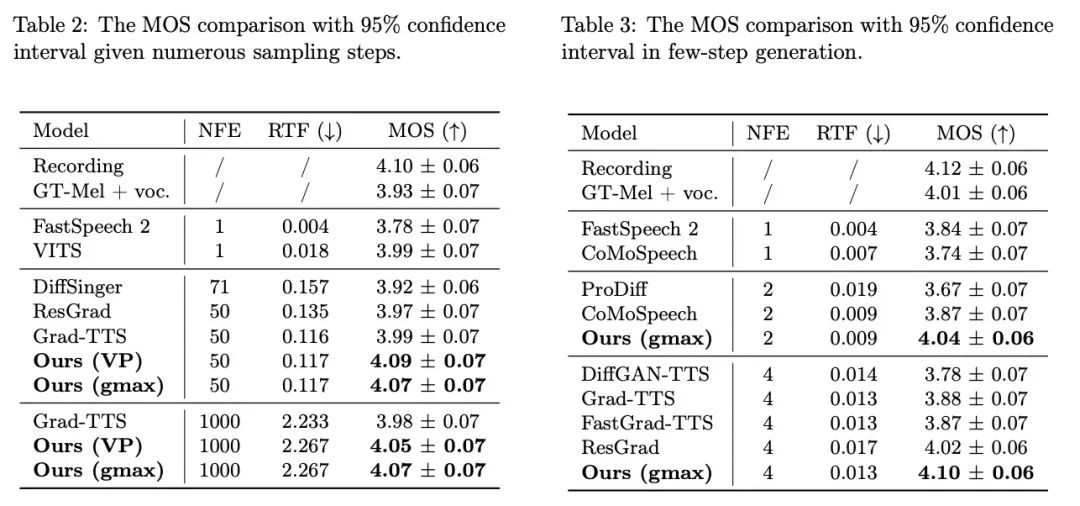
Pautan kertas: https://arxiv.org/abs/2312.03491 Tapak web projek: https://bridge-tts.github.io/ Pelaksanaan kod: https://github.com/thu -ml/Bridge-TTSSejak 2021, model resapan telah mula menjadi yang paling popular dalam bidang teks-ke-spesis , TTS) Salah satu kaedah penjanaan teras, seperti Grad-TTS [2] yang dicadangkan oleh Huawei's Noah's Ark Laboratory dan DiffSinger [3] yang dicadangkan oleh Universiti Zhejiang, telah mencapai kualiti generasi tinggi. Sejak itu, banyak kerja penyelidikan telah meningkatkan kelajuan pensampelan model resapan dengan berkesan, seperti melalui pengoptimuman terdahulu [2, 3, 4], penyulingan model [5, 6], ramalan baki [7] dan kaedah lain. Walau bagaimanapun, seperti yang ditunjukkan dalam kajian ini, kerana model resapan terhad kepada paradigma penjanaan "noise to data", pengedaran terdahulunya sentiasa memberikan maklumat terhad untuk sasaran penjanaan dan tidak dapat menggunakan sepenuhnya maklumat bersyarat. Kerja penyelidikan terkini dalam bidang sintesis pertuturan, Bridge-TTS, bergantung pada rangka kerja penjanaan berasaskan Jambatan Schrödinger untuk merealisasikan proses penjanaan "data-ke-data" Untuk pertama kalinya, maklumat terdahulu sintesis pertuturan diubah suai daripada hingar kepada data Bersih , diubah suai daripada pengedaran kepada perwakilan deterministik . Seni bina utama kaedah ini ditunjukkan dalam rajah di atas Teks input pertama kali diekstrak melalui pengekod teks untuk mengekstrak perwakilan ruang terpendam bagi sasaran yang dijana (mel-spektrogram, spektrum mel). Selepas itu, tidak seperti model resapan yang menggabungkan maklumat ini ke dalam pengedaran hingar atau menggunakannya sebagai maklumat bersyarat, kaedah Bridge-TTS menyokong secara langsung menggunakannya sebagai maklumat terdahulu dan menyokong pensampelan rawak atau deterministik, Berkualiti tinggi dan pantas Menjana sasaran. Pada LJ-Speech, set data standard yang mengesahkan kualiti sintesis pertuturan, pasukan penyelidik dipercepatkan sistem 9 Bridge-TTS kualiti sintesis tinggi model Kaedah persampelan dibandingkan. Seperti yang ditunjukkan di bawah, kaedah ini mengalahkan sistem TTS berasaskan model resapan berkualiti tinggi [2, 3, 7] dalam kualiti sampel (1000 langkah, 50 langkah pensampelan), dan dalam kelajuan pensampelan tanpa sebarang pasca pemprosesan Dalam keadaan seperti penyulingan model tambahan, ia melebihi banyak kaedah pecutan, seperti ramalan sisa, penyulingan progresif, dan penyulingan konsensus terkini [5, 6, 7]. Berikut ialah contoh kesan penjanaan Bridge-TTS dan kaedah berasaskan model resapan Untuk lebih banyak perbandingan sampel generasi, sila lawati tapak web projek: https://bridge-tts.github.io/
-
Perbandingan kesan sintesis 1000 langkah
Masukkan teks: "Mencetak, maka, untuk tujuan kita, boleh dianggap sebagai seni membuat buku
boleh alih." 
- 4 Langkah perbandingan kesan sintesis
Input teks: "Buku pertama dicetak dalam huruf hitam, iaitu huruf yang merupakan perkembangan Gothic bagi watak Rom purba
,"
2 - Perbandingan kesan sintesis langkah
Input Teks: "Penduduk penjara berfluktuasi banyak,"
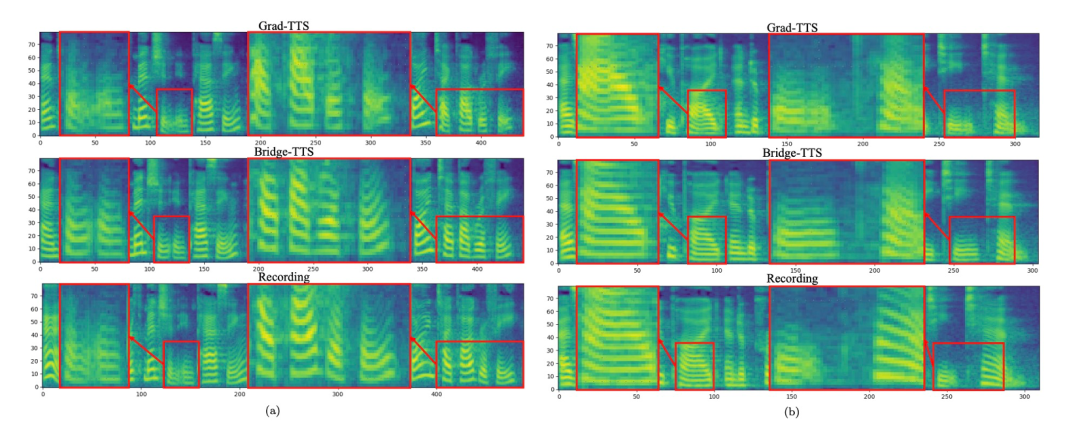
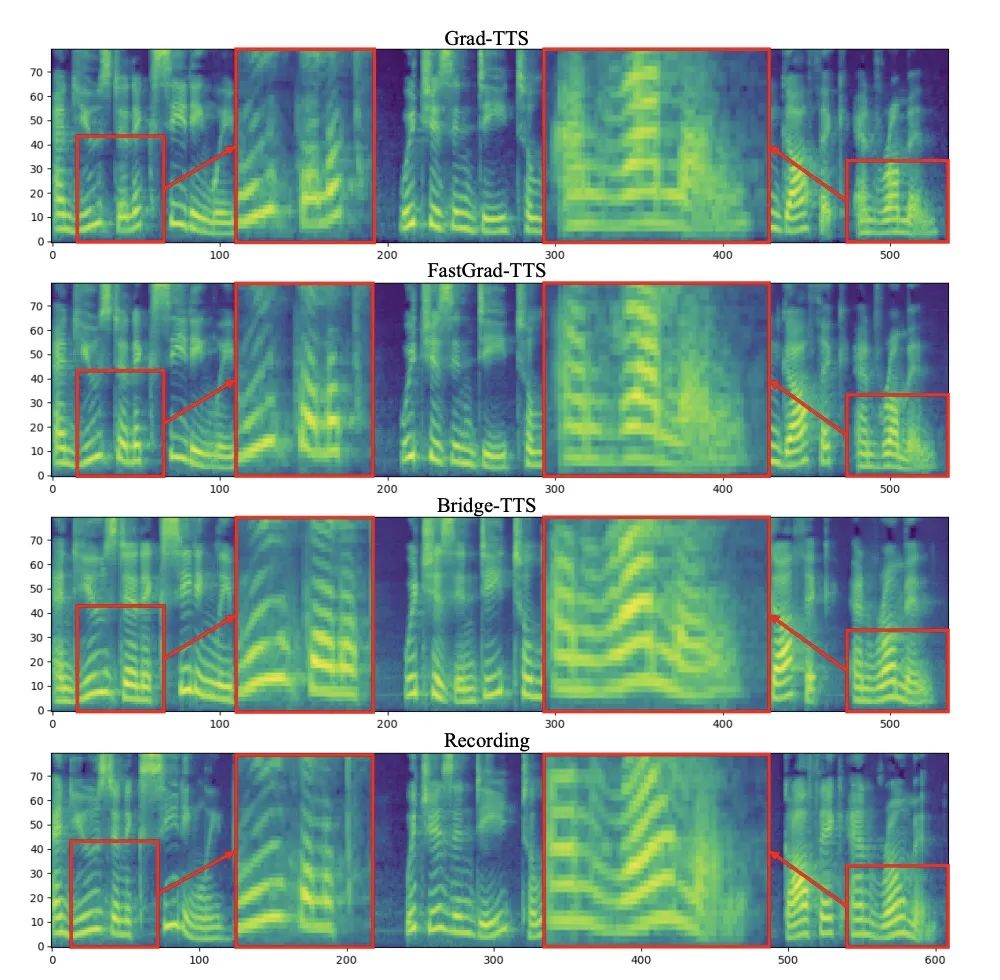
berikut menunjukkan sintesis deterministik (ode persampelan) TTS dalam 2 langkah dan 4 langkah ) kes. Dalam sintesis 4 langkah, kaedah ini mensintesis lebih banyak butiran sampel daripada model resapan, dan tiada masalah bunyi sisa. Dalam sintesis 2 langkah, kaedah ini mempamerkan trajektori pensampelan tulen sepenuhnya, dan memperhalusi lebih banyak butiran yang dijana pada setiap langkah.  Dalam domain frekuensi, lebih banyak sampel yang dihasilkan ditunjukkan di bawah Dalam 1000 langkah sintesis, kaedah ini menghasilkan spektrum mel yang lebih berkualiti berbanding model resapan Apabila bilangan langkah persampelan dikurangkan kepada 50 langkah model penyebaran telah mengorbankan beberapa butiran pensampelan, kaedah berasaskan jambatan Schrödinger masih mengekalkan hasil penjanaan berkualiti tinggi. Dalam sintesis 4 langkah dan 2 langkah, kaedah ini tidak memerlukan penyulingan, latihan berbilang peringkat, dan fungsi kehilangan lawan, dan masih mencapai kesan penjanaan berkualiti tinggi.
Dalam domain frekuensi, lebih banyak sampel yang dihasilkan ditunjukkan di bawah Dalam 1000 langkah sintesis, kaedah ini menghasilkan spektrum mel yang lebih berkualiti berbanding model resapan Apabila bilangan langkah persampelan dikurangkan kepada 50 langkah model penyebaran telah mengorbankan beberapa butiran pensampelan, kaedah berasaskan jambatan Schrödinger masih mengekalkan hasil penjanaan berkualiti tinggi. Dalam sintesis 4 langkah dan 2 langkah, kaedah ini tidak memerlukan penyulingan, latihan berbilang peringkat, dan fungsi kehilangan lawan, dan masih mencapai kesan penjanaan berkualiti tinggi. 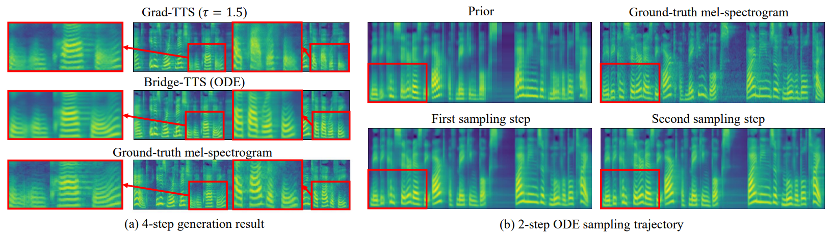
in 1000 langkah sintesis, perbandingan spektrum MEL jambatan dan kaedah berasaskan model penyebaran 50 langkah sintesis, jambatan dan kaedah berdasarkan model resapan Perbandingan spektrum Mel kaedah model resapan
. kaedah Mel spektrum perbandingan kaedah modelBridge-TTS sebaik sahaja dikeluarkan, dengan reka bentuk novel dan kesan sintesis berkualiti tinggi dalam sintesis pertuturan, menarik perhatian yang bersemangat di Twitter dan menerima ratusan komen Dengan lebih daripada 100 tweet semula dan beratus-ratus suka, Huggingface telah dipilih ke dalam Huggingface's Daily Paper pada 12.7 dan memenangi tempat pertama dalam kadar sokongan pada hari itu Pada masa yang sama, dia diikuti di banyak platform dalam dan luar negara seperti LinkedIn, Weibo, Zhihu, dan Xiaohongshu dan laporan hadapan. Laman web bahasa asing juga telah dilaporkan dan dibincangkan: 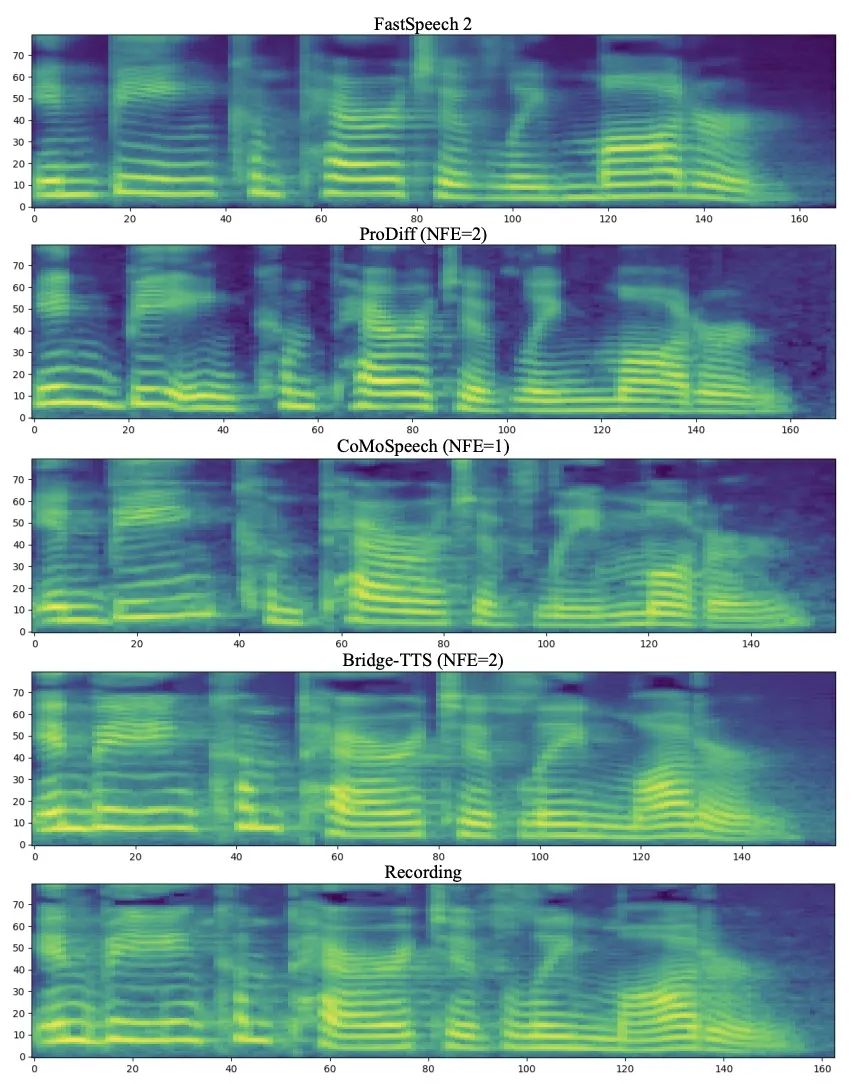 Schrodinger Bridge adalah sejenis model yang baru -baru ini muncul berikutan model penyebaran
Schrodinger Bridge adalah sejenis model yang baru -baru ini muncul berikutan model penyebaran
model generatif mendalam mempunyai aplikasi awal dalam penjanaan imej, terjemahan imej dan bidang lain [8,9]. Tidak seperti model resapan, yang mewujudkan proses transformasi antara data dan hingar Gaussian, jambatan Schrödinger menyokong transformasi antara mana-mana dua taburan sempadan. Dalam kajian Bridge-TTS, penulis mencadangkan rangka kerja sintesis pertuturan berdasarkan jambatan Schrödinger antara data berpasangan, yang menyokong pelbagai proses hadapan, sasaran ramalan dan proses pensampelan secara fleksibel. Gambaran keseluruhan kaedahnya ditunjukkan dalam rajah di bawah: Proses ke hadapan
: Penyelidikan ini membina jambatan Schrödinger yang boleh diselesaikan sepenuhnya antara maklumat awal yang kukuh dan matlamat generatif, menyokong proses ke hadapan yang fleksibel Pilih daripada noisesimetrik strategi
: , malar , dan
, dan
strategi hingar asimetri:
, linear, serta strategi pemeliharaan varians (VP)yang sepadan secara langsung dengan model resapan. Kaedah ini mendapati bahawa dalam tugasan sintesis pertuturan, strategi hingar tidak simetri: linear
(gmax) dan proses VP mempunyai kesan penjanaan yang lebih baik daripada strategi hingar simetri.
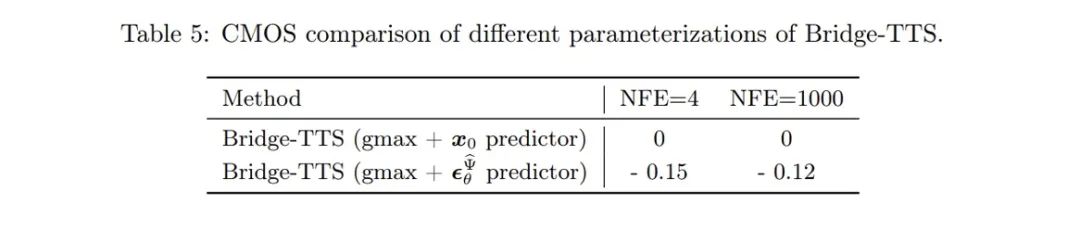
- Latihan model: Kaedah ini mengekalkan pelbagai kelebihan proses latihan model penyebaran, seperti peringkat tunggal, model tunggal dan fungsi kehilangan tunggal. Dan ia membandingkan pelbagai kaedah parameterisasi model (Parameterisasi model), iaitu pemilihan sasaran latihan rangkaian, termasuk ramalan hingar (Noise), ramalan sasaran penjanaan (Data), dan teknologi pemadanan aliran yang sepadan dengan model penyebaran [10,11]. ] Ramalan halaju (Velocity), dsb. Artikel tersebut mendapati apabila sasaran penjanaan, iaitu spektrum mel, digunakan sebagai sasaran ramalan rangkaian, hasil penjanaan yang lebih baik boleh dicapai.
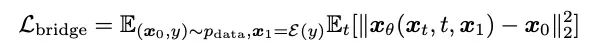
- Proses persampelan: Terima kasih kepada bentuk jambatan Schrödinger yang boleh diselesaikan sepenuhnya dalam kajian ini, dengan mengubah sistem SDE ke hadapan-belakang yang sepadan dengan jambatan Schrödinger, jambatan Schrödinger Bridge ODE digunakan untuk inferens. Pada masa yang sama, disebabkan oleh kelajuan perlahan simulasi langsung inferens Bridge SDE/ODE, untuk mempercepatkan pensampelan, kajian ini menggunakan penyepadu eksponen yang biasa digunakan dalam model resapan [12,13], dan memberikan urutan pertama. Bentuk pensampelan SDE dan ODE jambatan Schrödinger:
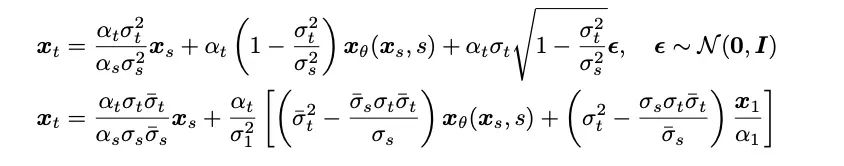
Dalam pensampelan 1 langkah, bentuk pensampelan SDE dan ODE tertib pertama secara bersama merosot menjadi ramalan satu langkah rangkaian. Pada masa yang sama, ia berkait rapat dengan persampelan posterior/model resapan persampelan DDIM, dan artikel tersebut memberikan analisis terperinci dalam lampiran. Artikel ini juga menyediakan algoritma pensampelan SDE dan ODE pensampelan tertib kedua bagi jambatan Schrödinger. Penulis mendapati bahawa dalam sintesis pertuturan, kualiti penjanaan adalah serupa dengan proses pensampelan urutan pertama. Dalam tugas-tugas lain seperti peningkatan pertuturan, pemisahan pertuturan, penyuntingan pertuturan dan tugas-tugas lain di mana maklumat terdahulu juga kukuh, penulis menjangkakan bahawa penyelidikan ini juga akan membawa nilai aplikasi yang lebih besar. Kajian ini mempunyai tiga pengarang pertama bersama: Chen Zehua, He Guande, dan Zheng Kaiwen, semuanya tergolong dalam kumpulan penyelidikan Zhu Jun di Jabatan Sains Komputer, Tsinghua . Penulis artikel yang sepadan ialah Profesor Zhu Jun, Microsoft Asia Research Tan Xu, ketua pengurus penyelidikan institut itu, adalah rakan usaha sama projek. 
Tan Xu, Ketua Pengurus Penyelidikan, Microsoft Research Asia, kesan bunyi, sintesis isyarat bioelektrik dan aplikasi lain. Beliau telah berkhidmat di banyak syarikat seperti Microsoft, JD.com, dan TikTok, dan menerbitkan banyak kertas kerja di persidangan antarabangsa penting dalam bidang pertuturan dan pembelajaran mesin, seperti ICML/NeurIPS/ICASSP.

He Guande ialah pelajar sarjana tahun ketiga di Universiti Tsinghua yang utama ialah anggaran ketidakpastian dan model generatif.

Zheng Kaiwen ialah pelajar sarjana tahun kedua di Universiti Tsinghua arah penyelidikan utamanya ialah teori dan algoritma model generatif, dan aplikasinya dalam penjanaan imej, audio dan 3D. Beliau sebelum ini telah menerbitkan banyak kertas kerja di persidangan teratas seperti ICML/NeurIPS/CVPR, yang melibatkan teknologi seperti pemadanan aliran dan penyepadu eksponen dalam model penyebaran. [1] Zehua Chen, Guande HE, Kaiwen Zheng, Xu Tan, dan Jun Zhu :2312.03491, 2023. [2] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova dan Mikhail A. Kudinov: Model Probabilistik IC Grad-Speace. 2021.[3] Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, dan Zhou Zhao DiffSinger: Menyanyi Sintesis Suara melalui Mekanisme Resapan Cetek, 2022.. ] Sang-gil Lee, Heeseung Kim, Chaehun Shin, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, Sungroh Yoon, dan Tie-Yan Liu PriorGrad: Memperbaik Model Resapan Bersyarat dengan Adaptif Bergantung kepada Data Sebelum ini. Dalam ICLR, 2022. [5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui dan Yi Ren: Model Resapan Pantas Berkualiti Tinggi ACM Multimedia, 2022. [6] Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu dan Yike Guo: Pertuturan Satu Langkah dan Sintesis Suara Menyanyi melalui Model Konsistensi ACM , 2023.[7] Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, Jiang Bian dan Danilo P. Mandic Resgrad: Model probabilistik penyebaran sisa untuk teks NeurIPS 2023.[9] Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A. Theodorou, Weili Nie dan Anima Anandkumar I2SB: Jambatan Imej-ke-Imej Schrödinger. 2023.[10] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel dan Matt Le Flow Matching untuk Pemodelan Generatif Dalam ICLR, 2023.. Kaiwen Zheng, Cheng Lu, Jianfei Chen dan Jun Zhu Memperbaik Teknik untuk Anggaran Kebarangkalian Maksimum untuk ODE Penyebaran Dalam ICML, 2023.[12] Cheng Lu, Yuhao Zhou, Fani Bao, Fani Bao. Li, dan Jun Zhu DPM-Solver: Penyelesai ODE Pantas untuk Persampelan Model Kebarangkalian Penyebaran dalam Sekitar 10 Langkah Dalam NeurIPS, 2022.[13] Kaiwen Zheng, Cheng Lu, Jianfei Chen. . DPM-Solver-v3: Penyelesai ODE Resapan yang Dipertingkatkan dengan Perangkaan Model Empirikal Dalam NeurIPS, 2023.Atas ialah kandungan terperinci Dengan bantuan Jambatan Schrödinger, pasukan Zhu Jun Tsinghua membangunkan sistem sintesis pertuturan baharu untuk menangani cabaran percambahan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



