


Ketua Pegawai Eksekutif Microsoft Nadella mengumumkan pada persidangan Ignite bulan lepas bahawa model skala kecil Phi-2 akan menjadi sumber terbuka sepenuhnya. Langkah ini akan meningkatkan dengan ketara prestasi penaakulan akal, pemahaman bahasa dan penaakulan logik

Hari ini, Microsoft mengumumkan lebih banyak butiran model Phi-2 dan pangkalan segera teknologi dorongan baharunya. Model dengan hanya 2.7 bilion parameter ini mengatasi prestasi Llama2 7B, Llama2 13B, Mistral 7B dan menutup jurang (atau lebih baik lagi) dengan Llama2 70B pada kebanyakan tugas penaakulan akal, pemahaman bahasa, matematik dan pengekodan.
Pada masa yang sama, Phi-2 bersaiz kecil boleh dijalankan pada peranti mudah alih seperti komputer riba dan telefon bimbit. Nadella berkata bahawa Microsoft sangat gembira untuk berkongsi model bahasa kecil (SLM) terbaik dalam kelasnya dan teknologi segera SOTA dengan pembangun R&D.
Microsoft menerbitkan kertas kerja pada Jun tahun ini yang dipanggil "Just a Textbook" yang menggunakan data "kualiti buku teks" yang mengandungi hanya penanda 7B untuk melatih model dengan parameter 1.3B, iaitu phi-1. Walaupun mempunyai set data dan saiz model yang tertib magnitud lebih kecil daripada pesaing, phi-1 mencapai kadar lulus kali pertama sebanyak 50.6% dalam HumanEval dan ketepatan 55.5% dalam MBPP. phi-1 membuktikan bahawa walaupun "data kecil" berkualiti tinggi boleh menjadikan model itu mempunyai prestasi yang baik
Microsoft kemudiannya menerbitkan "Just a Textbook II: Phi-1.5 Technical Report" pada bulan September, yang memberi tumpuan kepada kualiti tinggi "data kecil" disiasat selanjutnya. Artikel itu mencadangkan Phi-1.5, yang sesuai untuk Q&A Q&A, pengekodan dan senario lain, dan boleh mencapai skala 1.3 bilion
Kini, Phi-2 dengan 2.7 bilion parameter sekali lagi menggunakan "badan kecil" untuk menyediakan penaakulan yang sangat baik dan keupayaan pemahaman Bahasa, menunjukkan prestasi SOTA dalam model bahasa asas di bawah 13 bilion parameter. Terima kasih kepada inovasi dalam penskalaan model dan pengurusan data latihan, Phi-2 sepadan atau melebihi model 25 kali ganda saiznya sendiri pada penanda aras yang kompleks.
Microsoft mengatakan bahawa Phi-2 akan menjadi model ideal untuk penyelidik menjalankan penerokaan kebolehtafsiran, penambahbaikan keselamatan atau eksperimen penalaan halus untuk pelbagai tugas. Microsoft telah menyediakan Phi-2 dalam katalog model Azure AI Studio untuk memudahkan pembangunan model bahasa.
Peningkatan saiz model bahasa kepada ratusan bilion parameter sememangnya telah mengeluarkan banyak keupayaan baharu dan mentakrifkan semula landskap pemprosesan bahasa semula jadi. Tetapi persoalan tetap ada: adakah keupayaan baharu ini juga boleh dicapai pada model skala yang lebih kecil melalui pemilihan strategi latihan (seperti pemilihan data)?
Penyelesaian yang disediakan oleh Microsoft ialah menggunakan siri model Phi untuk mencapai prestasi yang serupa dengan model besar dengan melatih model bahasa kecil. Phi-2 melanggar peraturan penskalaan model bahasa tradisional dalam dua aspek
Pertama, kualiti data latihan memainkan peranan penting dalam prestasi model. Microsoft mengambil pemahaman ini secara melampau dengan memfokuskan pada data "kualiti buku teks". Data latihan mereka terdiri daripada set data komprehensif yang dicipta khas yang mengajar model pengetahuan akal dan penaakulan, seperti sains, aktiviti harian dan psikologi. Selain itu, mereka mengembangkan lagi korpus latihan mereka dengan data web yang dipilih dengan teliti yang disaring untuk nilai pendidikan dan kualiti kandungan
Kedua, Microsoft menggunakan teknologi inovatif untuk skala dari Phi-1.5 dengan 1.3 bilion parameter Pada mulanya, pengetahuan telah dibenamkan secara beransur-ansur ke dalam Phi-2 dengan 2.7 bilion parameter. Pemindahan pengetahuan berskala ini mempercepatkan penumpuan latihan dan meningkatkan markah penanda aras Phi-2 dengan ketara.
Berikut ialah graf perbandingan antara Phi-2 dan Phi-1.5, kecuali BBH (3-shot CoT) dan MMLU (5-shot), semua tugasan lain dinilai menggunakan 0-shot
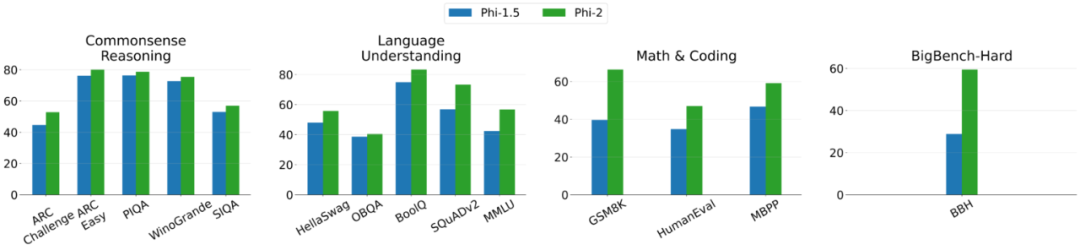
Phi-2 ialah model berasaskan Transformer yang matlamatnya adalah untuk meramal perkataan seterusnya. Ia dilatih pada set data sintetik dan rangkaian, menggunakan 96 GPU A100, dan mengambil masa 14 hari
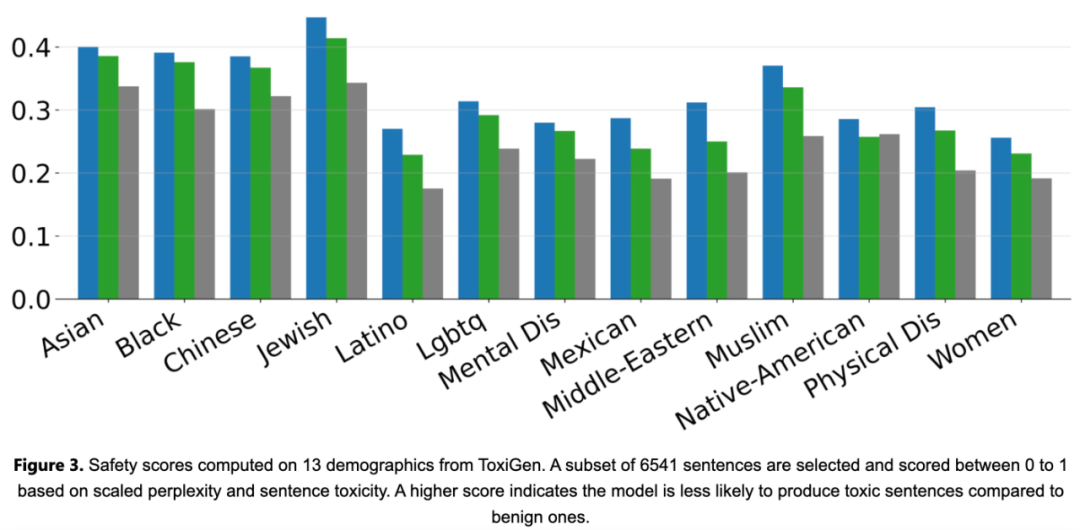
Phi-2 ialah model asas tanpa Penjajaran Pembelajaran Pengukuhan dengan Maklum Balas Manusia (RLHF) dan tiada penalaan halus arahan. Walaupun begitu, Phi-2 masih menunjukkan prestasi yang lebih baik dari segi ketoksikan dan berat sebelah berbanding model sumber terbuka sedia ada yang ditala, seperti yang ditunjukkan dalam Rajah 3 di bawah.
. )
Pemahaman bahasa (HellaSwag, OpenBookQA, MMLU (5-shot), SQuADv2 (2-shot), BoolQ Matematik (GSM8k (8 shot))
Pasukan penyelidik juga menguji secara meluas petua komuniti penyelidikan biasa. Phi-2 melakukan seperti yang diharapkan. Contohnya, untuk gesaan yang digunakan untuk menilai keupayaan model untuk menyelesaikan masalah fizik (baru-baru ini digunakan untuk menilai model Gemini Ultra), Phi-2 memberikan keputusan berikut:
Atas ialah kandungan terperinci Telefon mudah alih menjalankan model kecil Microsoft lebih baik daripada model besar dengan 2.7 bilion parameter. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



