


Sejak kebelakangan ini, anda mungkin pernah mendengar lebih kurang "Subjek 3", yang melibatkan lambaian tangan, kaki separuh selangkangan dan muzik berirama yang sepadan ini telah ditiru oleh seluruh Internet.
Apakah yang akan berlaku jika tarian serupa dihasilkan oleh AI? Seperti yang ditunjukkan dalam gambar di bawah, kedua-dua orang moden dan orang kertas melakukan pergerakan seragam. Apa yang anda mungkin tidak meneka ialah ini adalah video tarian yang dihasilkan berdasarkan gambar.

Pergerakan watak menjadi lebih sukar, dan video yang dihasilkan juga sangat lancar (paling kanan):

Mudah untuk membuat Messi dan Iron Man bergerak:
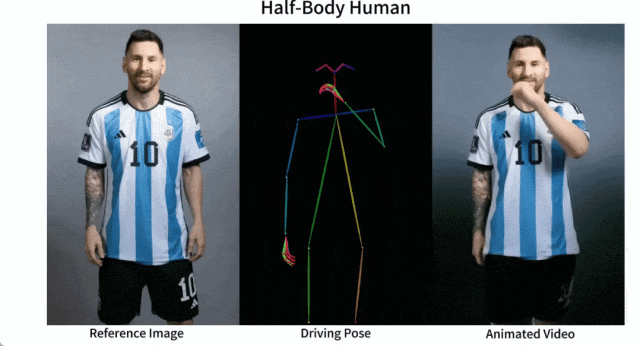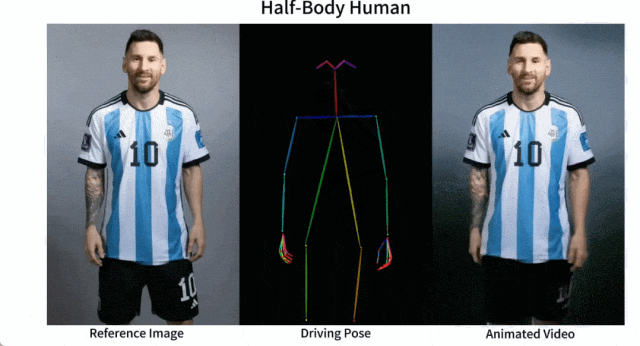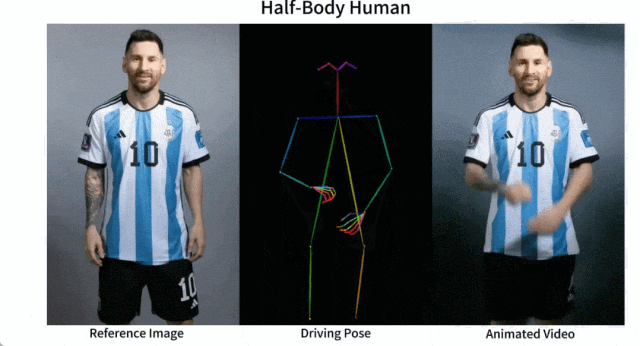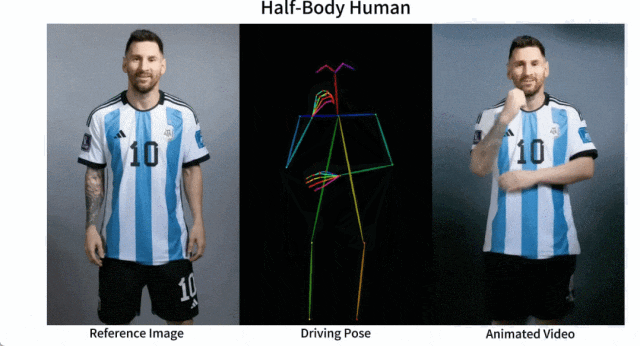
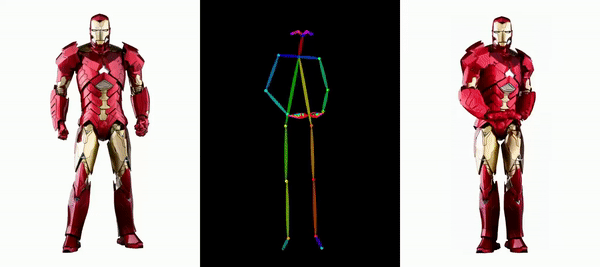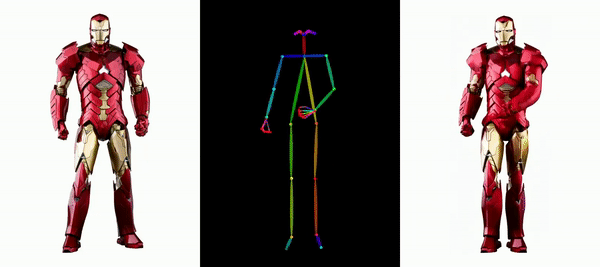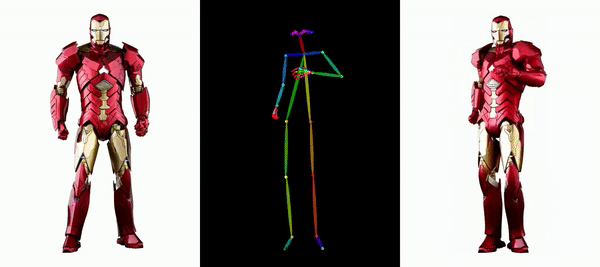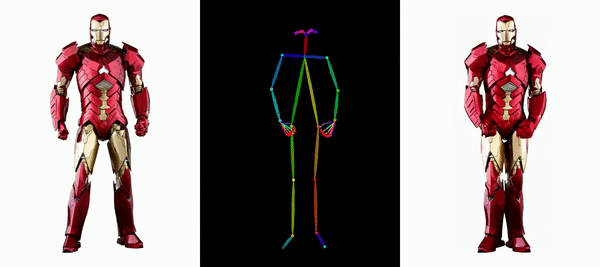
Terdapat juga pelbagai gadis anime.

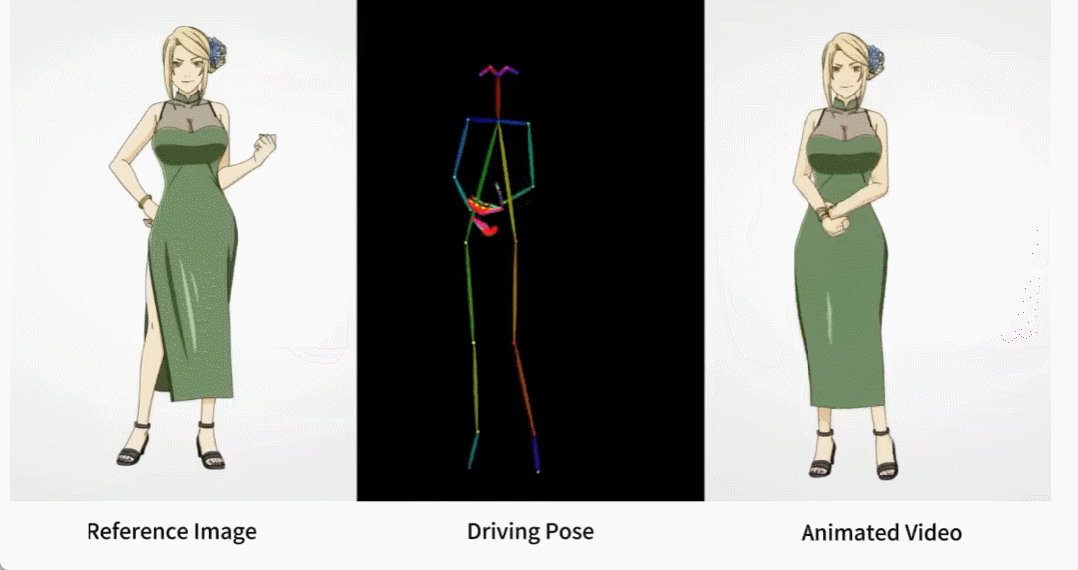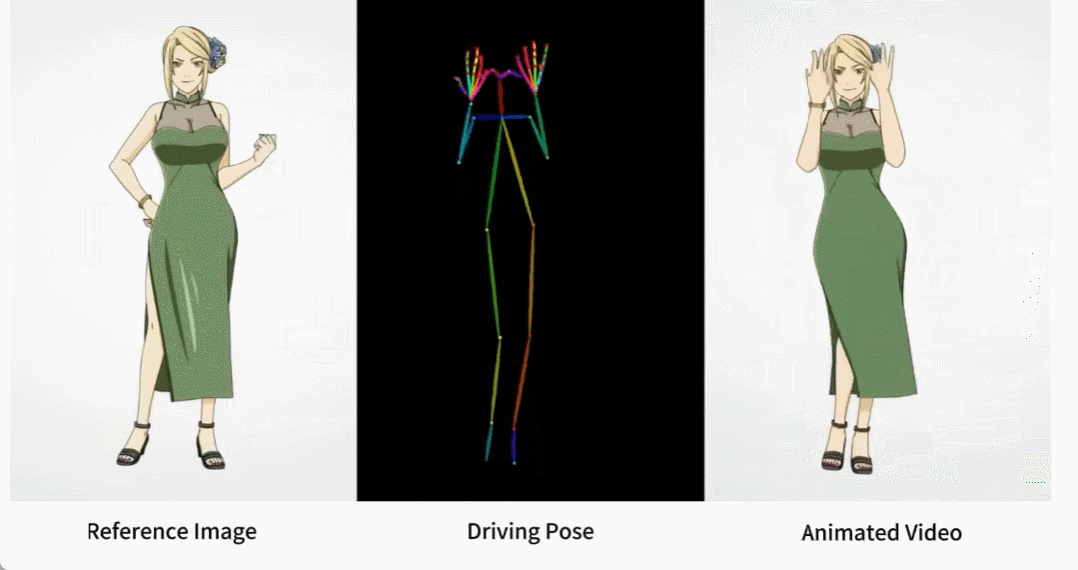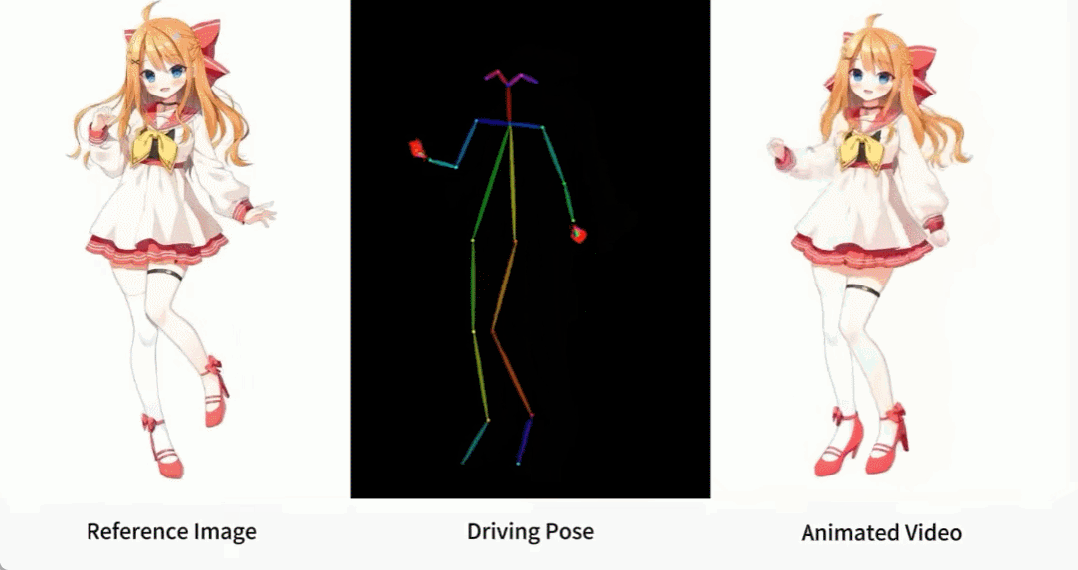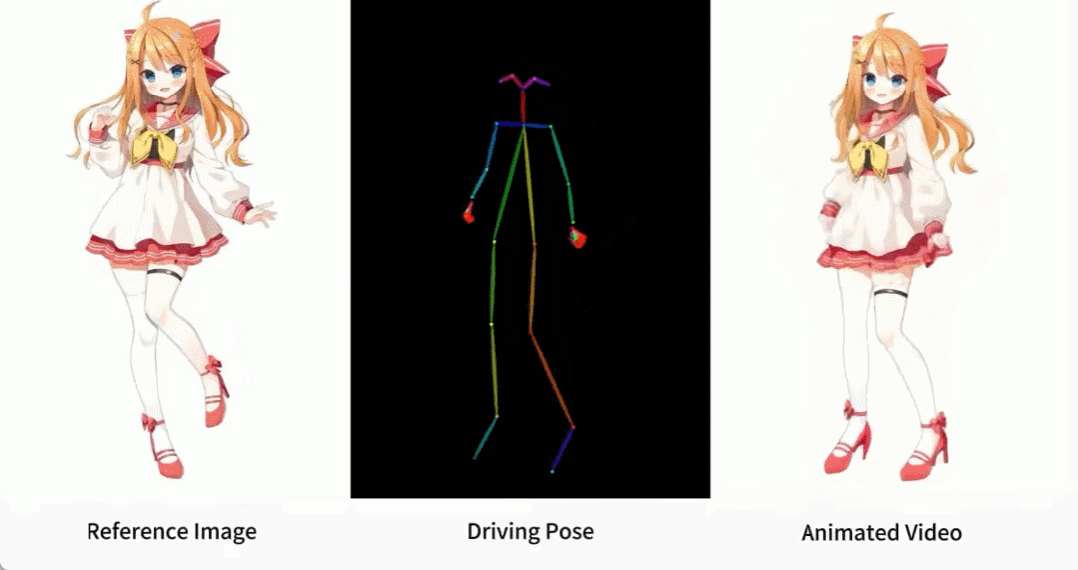
Bagaimana kesan ini dicapai? Mari teruskan membaca
Animasi watak ialah proses menukar imej watak asli kepada video realistik dalam urutan pose yang diingini. Tugas ini mempunyai banyak bidang aplikasi yang berpotensi, seperti peruncitan dalam talian, video hiburan, penciptaan seni dan watak maya, dsb. penyelesaian kaedah pemindahan pose. Walau bagaimanapun, imej atau video yang dijana masih mempunyai beberapa masalah, seperti herotan setempat, butiran kabur, ketidakkonsistenan semantik dan ketidakstabilan temporal, yang menghalang penggunaan kaedah ini
Penyelidik Ali mencadangkan kaedah yang dipanggil kaedah Animate Anybody's menukar imej watak ke dalam video animasi yang mengikut urutan pose yang dikehendaki. Kajian ini menggunakan reka bentuk rangkaian Stable Diffusion dan pemberat pra-latihan, dan mengubah suai denoising UNet untuk menyesuaikan diri dengan input berbilang bingkai

Untuk memastikan kebolehkawalan pose, kajian ini mereka bentuk panduan pose ringan untuk mengawal pose dengan berkesan. Isyarat disepadukan ke dalam proses denoising. Untuk mencapai kestabilan temporal, kertas kerja ini memperkenalkan lapisan temporal untuk memodelkan hubungan antara berbilang bingkai, dengan itu mengekalkan butiran resolusi tinggi kualiti visual sambil mensimulasikan proses gerakan temporal yang berterusan dan lancar.
Animate Anybody telah dilatih pada set data dalaman bagi klip video 5K aksara, seperti yang ditunjukkan dalam Rajah 1, menunjukkan hasil animasi untuk pelbagai watak. Berbanding dengan kaedah sebelum ini, kaedah dalam artikel ini mempunyai beberapa kelebihan yang jelas:
Kertas ini dinilai berdasarkan dua tanda aras sintesis video manusia tertentu (Set Data Video Fesyen UBC dan Set Data TikTok). Keputusan menunjukkan bahawa Animate Anybody mencapai keputusan SOTA. Selain itu, kajian itu membandingkan kaedah Animasikan Sesiapa sahaja dengan kaedah imej-ke-video umum yang dilatih pada data berskala besar, menunjukkan bahawa Animasikan Sesiapa sahaja menunjukkan keupayaan unggul dalam animasi watak.

Animate sesiapa sahaja perbandingan dengan kaedah lain:

Kaedah pemprosesan artikel ini ditunjukkan dalam Rajah 2. Input asal rangkaian terdiri daripada hingar berbilang bingkai . Untuk mencapai kesan denoising, penyelidik menggunakan konfigurasi berdasarkan reka bentuk SD, menggunakan rangka kerja dan unit blok yang sama, dan mewarisi pemberat latihan daripada SD. Secara khusus, kaedah ini merangkumi tiga bahagian utama, iaitu:
ReferenceNet direka dengan dua kelebihan. Pertama, ReferenceNet boleh memanfaatkan keupayaan pemodelan ciri imej pra-latihan SD mentah untuk menghasilkan ciri yang dimulakan dengan baik. Kedua, memandangkan ReferenceNet dan denoising UNet pada asasnya mempunyai struktur rangkaian yang sama dan berkongsi berat permulaan, denoising UNet boleh secara selektif mempelajari ciri yang dikaitkan dalam ruang ciri yang sama daripada ReferenceNet. . , 128, serupa dengan pengekod bersyarat dalam [56], digunakan untuk menjajarkan imej pose dengan resolusi yang sama seperti bunyi asas. Imej pose yang diproses ditambah pada hingar terpendam dan kemudian dimasukkan ke UNet denosing untuk diproses. Panduan pose dimulakan dengan pemberat Gaussian dan menggunakan lilitan sifar dalam lapisan pemetaan akhir 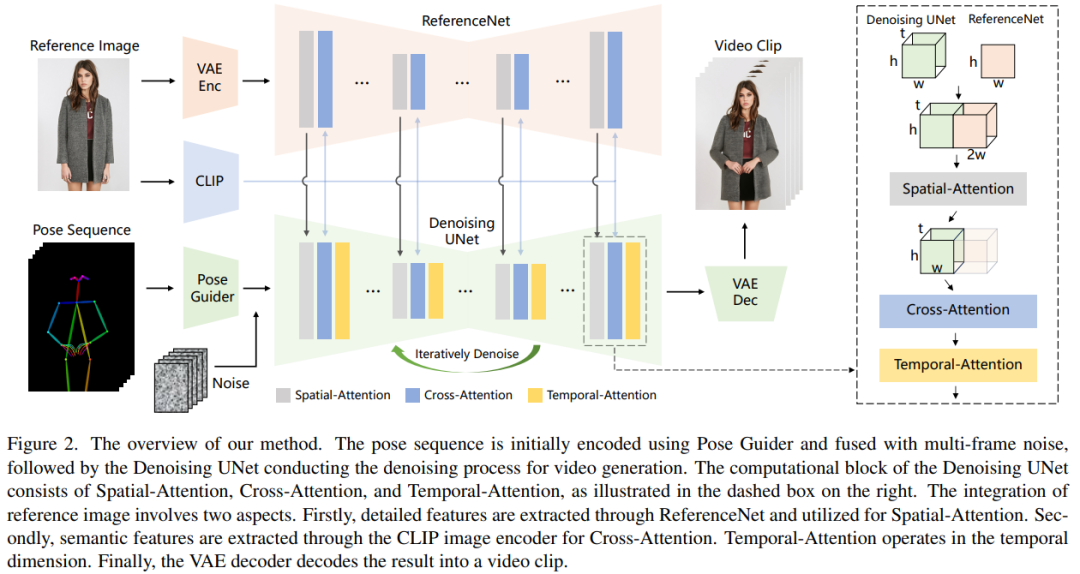
Lapisan sementara
Reka bentuk lapisan temporal diilhamkan oleh AnimateDiff. Untuk peta ciri x∈R^b×t×h×w×c, penyelidik mula-mula mengubah bentuknya menjadi x∈R^(b×h×w)×t×c, dan kemudian melakukan perhatian temporal, iaitu sepanjang Perhatian diri dalam dimensi t. Ciri-ciri lapisan temporal digabungkan ke dalam ciri asal melalui sambungan sisa Reka bentuk ini konsisten dengan kaedah latihan dua peringkat di bawah. Lapisan sementara digunakan secara eksklusif dalam blok Res-Trans untuk menafikan UNet.
Strategi latihan
Proses latihan terbahagi kepada dua peringkat.
Kandungan yang ditulis semula: Pada peringkat pertama latihan, satu bingkai video digunakan untuk latihan. Dalam model UNet denoising, penyelidik mengecualikan sementara lapisan temporal dan mengambil bunyi bingkai tunggal sebagai input. Pada masa yang sama, rangkaian rujukan dan panduan sikap juga dilatih. Imej rujukan dipilih secara rawak daripada keseluruhan klip video. Mereka menggunakan pemberat yang telah dilatih untuk memulakan model UNet dan ReferenceNet yang mengecil. Panduan pose dimulakan dengan pemberat Gaussian, kecuali untuk lapisan unjuran akhir, yang menggunakan lilitan sifar. Berat pengekod dan penyahkod VAE dan pengekod imej CLIP kekal tidak berubah. Matlamat pengoptimuman peringkat ini adalah untuk menjana imej animasi berkualiti tinggi berdasarkan imej rujukan dan pose sasaran
Pada peringkat kedua, penyelidik memperkenalkan lapisan temporal ke dalam model yang dilatih sebelum ini dan menggunakan AnimateDiff untuk pra-Memulakan yang terlatih berat. Input kepada model terdiri daripada klip video 24 bingkai. Pada peringkat ini, hanya lapisan temporal dilatih, manakala berat bahagian lain rangkaian ditetapkan.
Hasil kualitatif: Seperti yang ditunjukkan dalam Rajah 3, kaedah ini boleh menghasilkan animasi mana-mana watak, termasuk potret seluruh badan, potret separuh panjang, watak kartun dan watak humanoid. Kaedah ini mampu menghasilkan butiran manusia definisi tinggi dan realistik. Ia mengekalkan ketekalan temporal dengan imej rujukan dan mempamerkan kesinambungan temporal dari bingkai ke bingkai walaupun dalam kehadiran gerakan besar.

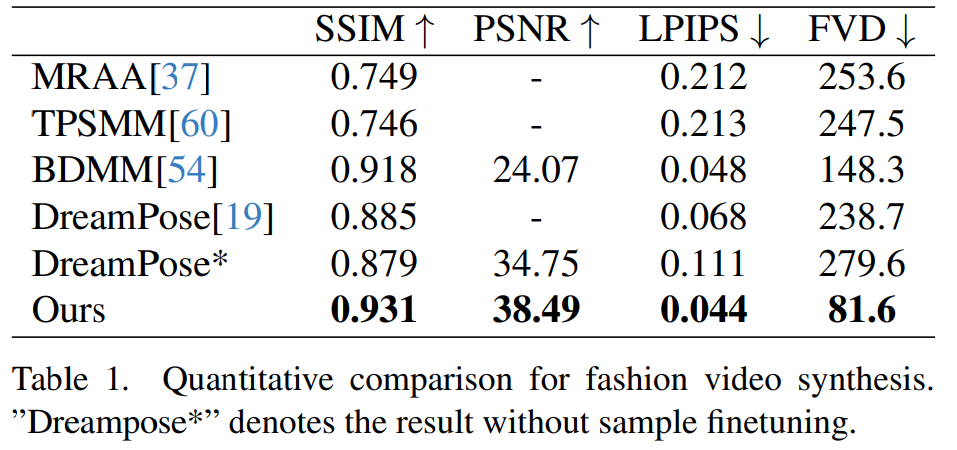
Sintesis video fesyen. Matlamat sintesis video fesyen adalah untuk mengubah foto fesyen menjadi video animasi realistik menggunakan urutan pose terdorong. Percubaan dijalankan pada Set Data Video Fesyen UBC, yang terdiri daripada 500 video latihan dan 100 video ujian, setiap satu mengandungi kira-kira 350 bingkai. Perbandingan kuantitatif ditunjukkan dalam Jadual 1. Ia boleh didapati dalam keputusan bahawa kaedah dalam kertas ini adalah lebih baik daripada kaedah lain, terutamanya dalam penunjuk pengukuran video, menunjukkan petunjuk yang jelas.
Perbandingan kualitatif ditunjukkan dalam Rajah 4. Untuk perbandingan yang adil, para penyelidik menggunakan kod sumber terbuka DreamPose untuk mendapatkan hasil tanpa penalaan halus sampel. Dalam bidang video fesyen, keperluan untuk butiran pakaian adalah sangat ketat. Walau bagaimanapun, video yang dijana oleh DreamPose dan BDMM gagal mengekalkan konsistensi dalam butiran pakaian dan mempamerkan ralat ketara dalam warna dan elemen struktur halus. Sebaliknya, hasil yang dihasilkan oleh kaedah ini dapat mengekalkan konsistensi butiran pakaian dengan lebih berkesan.

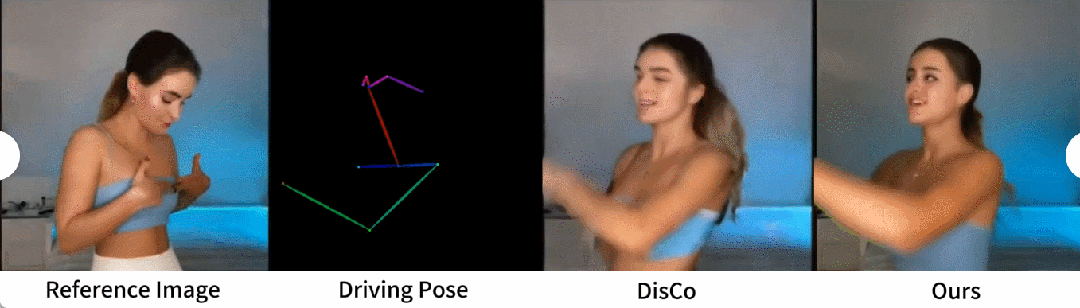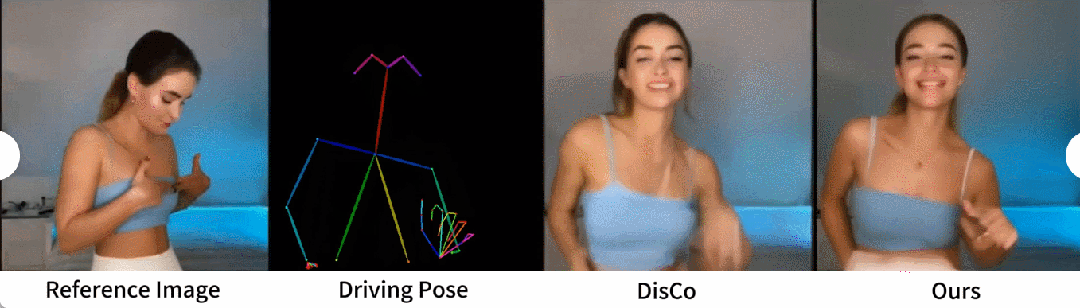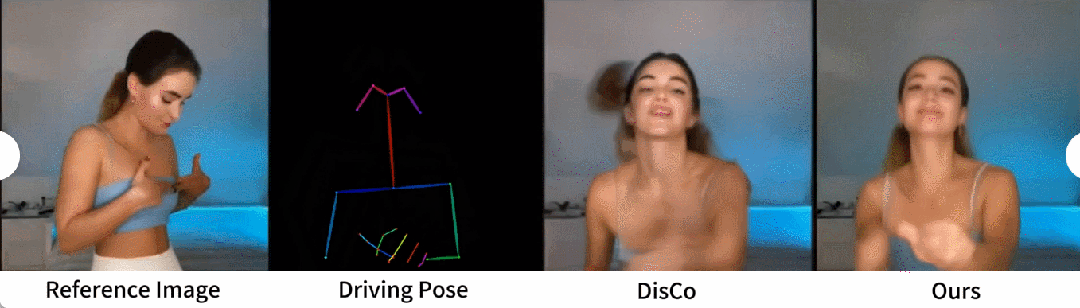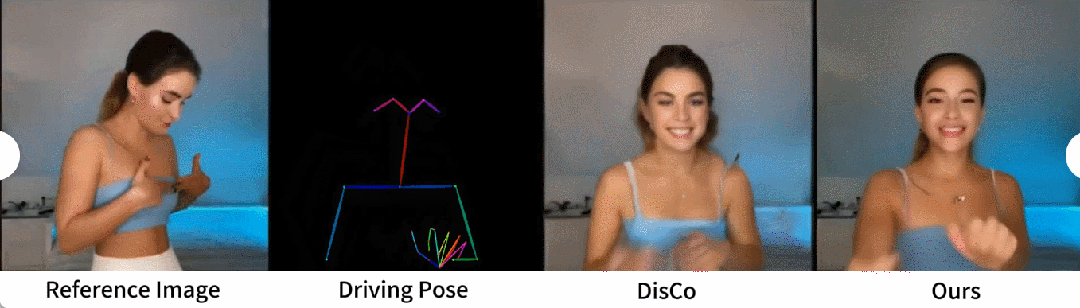
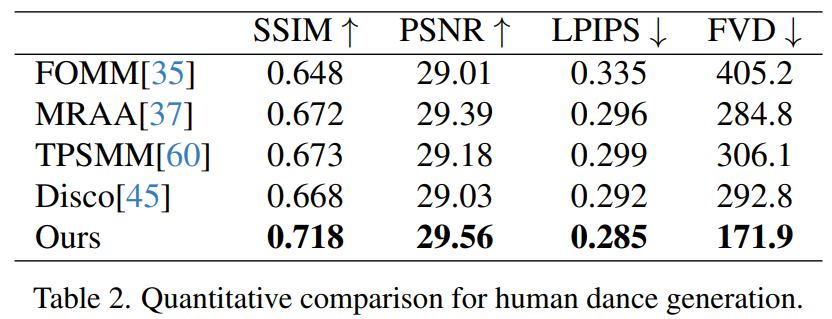
Generasi tarian manusia ialah kajian yang matlamatnya adalah untuk menjana tarian manusia dengan menghidupkan imej adegan tarian yang realistik. Para penyelidik menggunakan set data TikTok, yang merangkumi 340 video latihan dan 100 video ujian. Mereka melakukan perbandingan kuantitatif menggunakan set ujian yang sama, yang termasuk 10 video gaya TikTok, mengikut kaedah pembahagian dataset DisCo. Dari Jadual 2 dapat dilihat bahawa kaedah dalam kertas kerja ini mencapai hasil yang terbaik. Untuk meningkatkan keupayaan generalisasi model, DisCo menggabungkan pra-latihan atribut manusia dan menggunakan sebilangan besar pasangan imej untuk pra-melatih model. Sebaliknya, penyelidik lain hanya melatih set data TikTok, tetapi hasilnya masih lebih baik daripada DisCo
Perbandingan kualitatif dengan DisCo ditunjukkan dalam Rajah 5. Memandangkan kerumitan tempat kejadian, pendekatan DisCo memerlukan penggunaan tambahan SAM untuk menjana topeng latar depan manusia. Sebaliknya, kaedah kami menunjukkan bahawa walaupun tanpa pembelajaran topeng manusia yang eksplisit, model ini boleh memahami hubungan latar depan-latar belakang daripada gerakan subjek tanpa pembahagian manusia sebelumnya. Tambahan pula, dalam urutan tarian yang kompleks, model ini cemerlang dalam mengekalkan kesinambungan visual sepanjang aksi dan menunjukkan kemantapan yang lebih besar dalam mengendalikan penampilan watak yang berbeza.

Imej - Pendekatan universal untuk video. Pada masa ini, banyak kajian telah mencadangkan model penyebaran video dengan keupayaan penjanaan yang kukuh berdasarkan data latihan berskala besar. Para penyelidik memilih dua kaedah imej-video yang paling terkenal dan paling berkesan untuk perbandingan: AnimateDiff dan Gen2. Oleh kerana kedua-dua kaedah ini tidak melakukan kawalan pose, para penyelidik hanya membandingkan keupayaan mereka untuk mengekalkan kesetiaan penampilan imej rujukan. Seperti yang ditunjukkan dalam Rajah 6, pendekatan imej-ke-video semasa menghadapi cabaran dalam menghasilkan sejumlah besar tindakan watak dan perjuangan untuk mengekalkan konsistensi penampilan jangka panjang merentas video, sekali gus menghalang sokongan berkesan untuk animasi watak yang konsisten.

Sila semak kertas asal untuk maklumat lanjut
Atas ialah kandungan terperinci 'Subjek Tiga' yang menarik perhatian global: Messi, Iron Man dan wanita dua dimensi boleh mengendalikannya dengan mudah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 IIS penyelesaian ralat tidak dijangka 0x8ffe2740
IIS penyelesaian ralat tidak dijangka 0x8ffe2740
 format flac
format flac
 Apakah platform e-dagang?
Apakah platform e-dagang?
 Perbezaan antara ++a dan a++ dalam bahasa c
Perbezaan antara ++a dan a++ dalam bahasa c
 Di manakah saya harus mengisi tempat lahir saya: wilayah, bandar atau daerah?
Di manakah saya harus mengisi tempat lahir saya: wilayah, bandar atau daerah?
 Apakah perbezaan antara 5g dan 4g
Apakah perbezaan antara 5g dan 4g
 Bagaimana untuk menggunakan carian magnetik btbook
Bagaimana untuk menggunakan carian magnetik btbook
 Bagaimana untuk mengkonfigurasi pembolehubah persekitaran laluan dalam java
Bagaimana untuk mengkonfigurasi pembolehubah persekitaran laluan dalam java








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



