


Saya percaya rakan-rakan yang meminati bulatan telefon bimbit pasti tidak asing dengan ungkapan "dapat markah jika tidak menerimanya". Sebagai contoh, perisian ujian prestasi teori seperti AnTuTu dan GeekBench telah menarik banyak perhatian daripada pemain kerana ia boleh mencerminkan prestasi telefon mudah alih pada tahap tertentu. Begitu juga, terdapat perisian penanda aras yang sepadan untuk pemproses PC dan kad grafik untuk mengukur prestasi mereka
Memandangkan "semuanya boleh ditanda aras", model AI besar yang paling popular juga telah mula mengambil bahagian dalam pertandingan penanda aras Terutama selepas permulaan "Perang Model Ratus", penemuan dibuat hampir setiap hari, dan setiap syarikat memanggil dirinya sebagai ". No. 1 dalam penandaarasan".一"
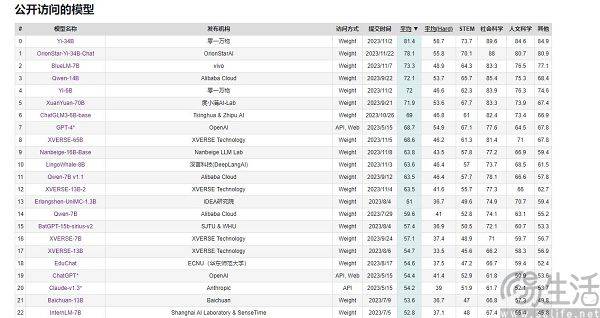
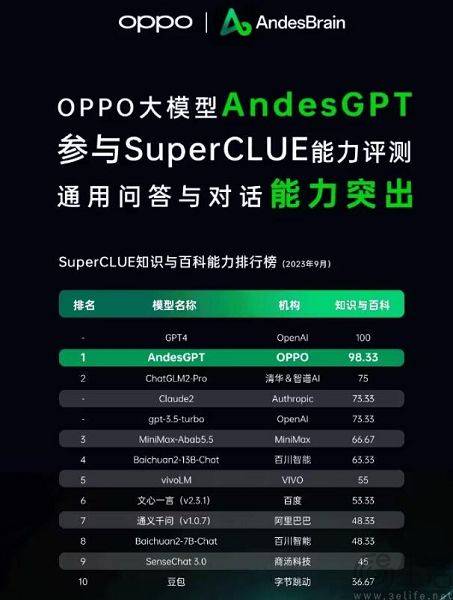
Model AI besar domestik hampir tidak pernah ketinggalan dari segi skor prestasi, tetapi mereka tidak boleh mengatasi GPT-4 dari segi pengalaman pengguna. Ini menimbulkan persoalan, iaitu, di pusat jualan utama, setiap pengeluar telefon mudah alih sentiasa boleh mendakwa bahawa produknya adalah "nombor satu dalam jualan". untuk menjadi nombor satu, tetapi dalam bidang model besar AI, keadaannya berbeza. Lagipun, kriteria penilaian mereka pada asasnya bersatu, termasuk MMLU (digunakan untuk mengukur keupayaan pemahaman bahasa berbilang tugas), Big-Bench (digunakan untuk mengukur dan mengekstrapolasi keupayaan LLM), dan AGIEval (digunakan untuk menilai keupayaan menangani masalah peringkat manusia).
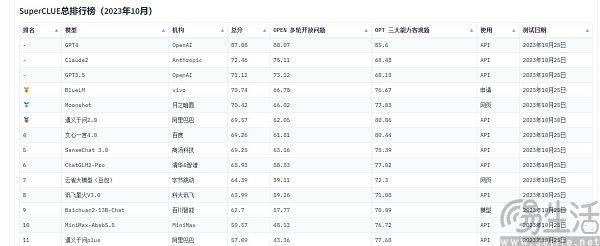
Pada masa ini, senarai penilaian model berskala besar yang sering disebut di China termasuk SuperCLUE, CMMLU dan C-Eval. Antaranya, CMMLU dan C-Eval adalah set penilaian peperiksaan komprehensif yang dibina bersama oleh Universiti Tsinghua, Universiti Jiao Tong Shanghai dan Universiti Edinburgh. CMMLU dilancarkan bersama oleh MBZUAI, Shanghai Jiao Tong University dan Microsoft Research Asia. Bagi SuperCLUE, ia ditulis bersama oleh profesional kecerdasan buatan dari universiti utama
Seperti yang kita sedia maklum, SoC telefon pintar, CPU komputer dan kad grafik secara automatik akan mengurangkan kekerapan di bawah suhu tinggi untuk melindungi jangka hayatnya, manakala suhu rendah boleh meningkatkan prestasi cip. Oleh itu, sesetengah orang akan meletakkan telefon bimbit mereka di dalam peti sejuk atau melengkapkan komputer mereka dengan sistem penyejukan yang lebih berkuasa untuk menjalankan ujian prestasi, dan mereka biasanya boleh mendapat markah yang lebih tinggi daripada biasa. Di samping itu, pengeluar telefon mudah alih utama juga akan melaksanakan "pengoptimuman eksklusif" untuk pelbagai perisian penanda aras, yang telah menjadi operasi standard mereka
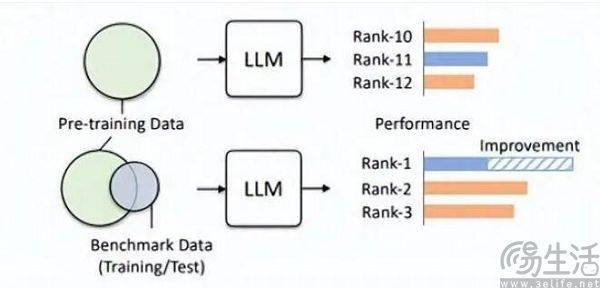
Anda boleh bayangkan sebelum peperiksaan, jika anda secara tidak sengaja melihat kertas ujian dan jawapan standard, dan kemudian menghafal soalan secara tidak dijangka, markah peperiksaan anda akan bertambah baik. Oleh itu, bank soalan yang dipratetap oleh senarai model besar ditambahkan pada set latihan, supaya model besar menjadi model yang sesuai dengan data penanda aras. Lebih-lebih lagi, LLM semasa itu sendiri terkenal dengan ingatan yang sangat baik, dan membaca jawapan standard hanyalah sekeping kek
Penyelidik dari pasukan Hillhouse mendapati bahawa kebocoran penanda aras boleh menyebabkan model besar menjalankan hasil yang berlebihan Contohnya, model 1.3B boleh mengatasi saiz model 10 kali ganda dalam beberapa tugasan, tetapi kesan sampingannya ialah ia direka khas untuk ". pengambilan peperiksaan" Untuk model besar, prestasi pada tugas ujian biasa yang lain akan terjejas dengan teruk. Lagipun, jika anda memikirkannya, anda akan tahu bahawa model AI yang besar sepatutnya menjadi "pembuat soalan", tetapi ia telah menjadi "penghafal soalan". pengetahuan khusus dan gaya keluaran senarai Ia pasti akan mengelirukan model besar.

Bukan persimpangan set latihan, set pengesahan, dan set ujian jelas hanya keadaan yang ideal Lagipun, realitinya sangat kurus, dan masalah kebocoran data hampir tidak dapat dielakkan dari akar. Dengan kemajuan berterusan teknologi berkaitan, keupayaan memori dan penerimaan struktur Transformer, yang merupakan asas model besar semasa, sentiasa bertambah baik pada musim panas ini, strategi AI Umum Microsoft Research telah membolehkan model menerima 100 juta Token tanpa menyebabkan tidak boleh diterima kerana kealpaan. Dengan kata lain, pada masa hadapan, model AI yang besar berkemungkinan mempunyai keupayaan untuk membaca keseluruhan Internet.
Walaupun kemajuan teknologi diketepikan, pencemaran data sebenarnya sukar dielakkan berdasarkan tahap teknikal semasa, kerana data berkualiti tinggi sentiasa terhad dan kapasiti pengeluaran terhad. Satu kertas kerja yang diterbitkan oleh pasukan penyelidik AI Epoch pada awal tahun ini menunjukkan bahawa AI akan menggunakan semua data bahasa manusia berkualiti tinggi dalam masa kurang daripada 5 tahun, dan keputusan ini ialah ia akan meningkatkan kadar pertumbuhan data bahasa manusia, iaitu semua manusia akan menerbitkan dalam 5 tahun akan datang Buku yang ditulis, kertas yang ditulis, dan kod yang ditulis semuanya diambil kira untuk meramalkan hasilnya.
Sekiranya set data sesuai untuk penilaian, maka ia pasti akan menunjukkan prestasi yang lebih baik dalam pra-latihan. Sebagai contoh, GPT-4 OpenAI menggunakan set data penilaian inferens berwibawa GSM8K. Oleh itu, pada masa ini terdapat masalah yang memalukan dalam bidang penilaian model berskala besar Permintaan untuk data daripada model berskala besar nampaknya tidak berkesudahan, yang menyebabkan agensi penilaian perlu bergerak lebih pantas dan lebih jauh daripada pengeluar kecerdasan buatan. model berskala besar. Walau bagaimanapun, agensi penilaian hari ini nampaknya tidak mempunyai keupayaan untuk melakukan ini
Mengapakah sesetengah pengeluar memberi perhatian khusus kepada skor larian model besar dan cuba meningkatkan kedudukan satu demi satu? Malah, logik di sebalik tingkah laku ini adalah sama seperti pembangun Apl menyuntik air ke dalam bilangan pengguna Apl mereka sendiri. Lagipun, skala pengguna Apl adalah faktor utama dalam mengukur nilainya, dan pada peringkat awal model AI berskala besar semasa, keputusan dalam senarai penilaian adalah hampir satu-satunya kriteria yang agak objektif Lagipun, dalam persepsi awam, skor tinggi bermakna Ia menyamai prestasi yang kukuh.
Apabila menepis kedudukan mungkin membawa kesan publisiti yang kuat dan mungkin meletakkan asas untuk pembiayaan, penambahan kepentingan komersial sudah pasti akan mendorong pengeluar model AI yang besar untuk tergesa-gesa menepis kedudukan.
Atas ialah kandungan terperinci Markah akan diukur apabila terdapat percanggahan pendapat Mengapa model AI domestik yang besar ketagih untuk 'meleret kedudukan'?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Cara menggunakan fungsi baris
Cara menggunakan fungsi baris
 Bagaimana untuk membeli dan menjual Bitcoin di negara ini
Bagaimana untuk membeli dan menjual Bitcoin di negara ini
 penggunaan fungsi satu
penggunaan fungsi satu
 Apakah yang perlu saya lakukan jika spooler cetakan tidak boleh dimulakan?
Apakah yang perlu saya lakukan jika spooler cetakan tidak boleh dimulakan?
 Bagaimana untuk menyelesaikan menunggu peranti
Bagaimana untuk menyelesaikan menunggu peranti
 Bagaimana untuk memulakan semula dengan kerap
Bagaimana untuk memulakan semula dengan kerap
 Cara menggunakan arahan scannow
Cara menggunakan arahan scannow
 Berapa lamakah masa yang diambil untuk pengisian semula Douyin untuk tiba?
Berapa lamakah masa yang diambil untuk pengisian semula Douyin untuk tiba?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



