


Stability AI melancarkan model sintesis imej generasi baharu - Stable Diffusion XL Turbo pada hari Selasa, yang telah membangkitkan sambutan yang bersemangat daripada orang ramai. Ramai orang berkata bahawa menggunakan model ini untuk penjanaan imej-ke-teks tidak pernah semudah ini
Masukkan idea anda dalam kotak input, SDXL Turbo akan bertindak balas dengan cepat dan menjana kandungan yang sepadan tanpa sebarang operasi lain. Tidak kira anda memasukkan lebih atau kurang kandungan, ia tidak akan menjejaskan kelajuannya


Anda boleh menggunakan imej sedia ada untuk melengkapkan ciptaan anda dengan lebih terperinci. Hanya ambil sehelai kertas putih dan beritahu SDXL Turbo anda mahu kucing putih Sebelum anda selesai menaip, kucing putih kecil itu telah muncul di tangan anda
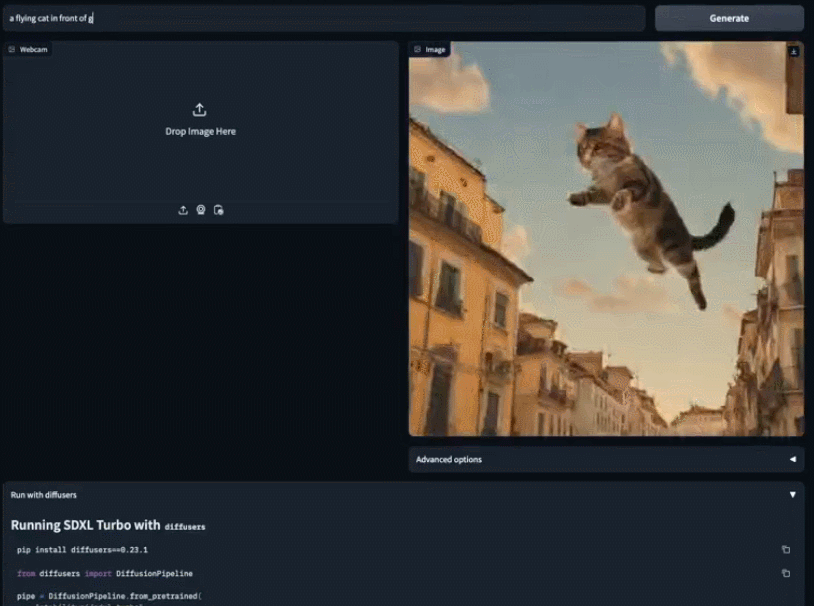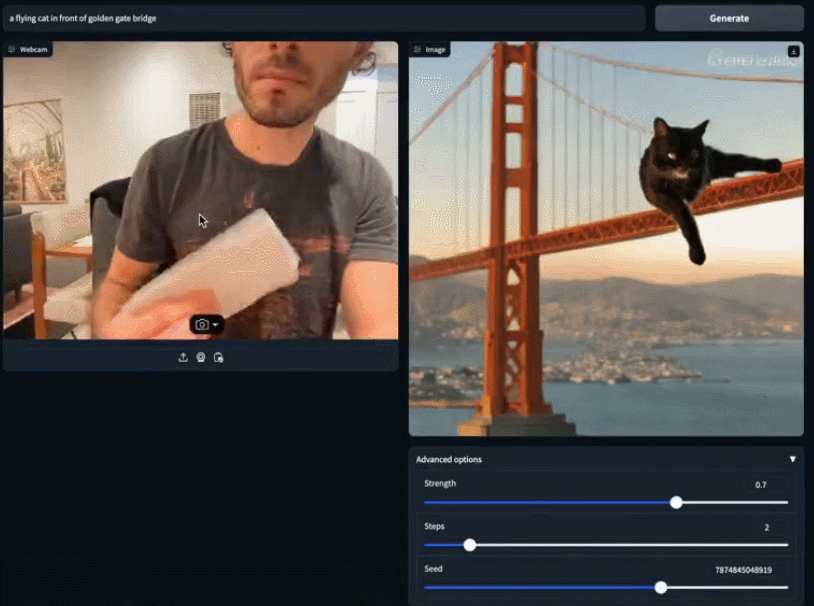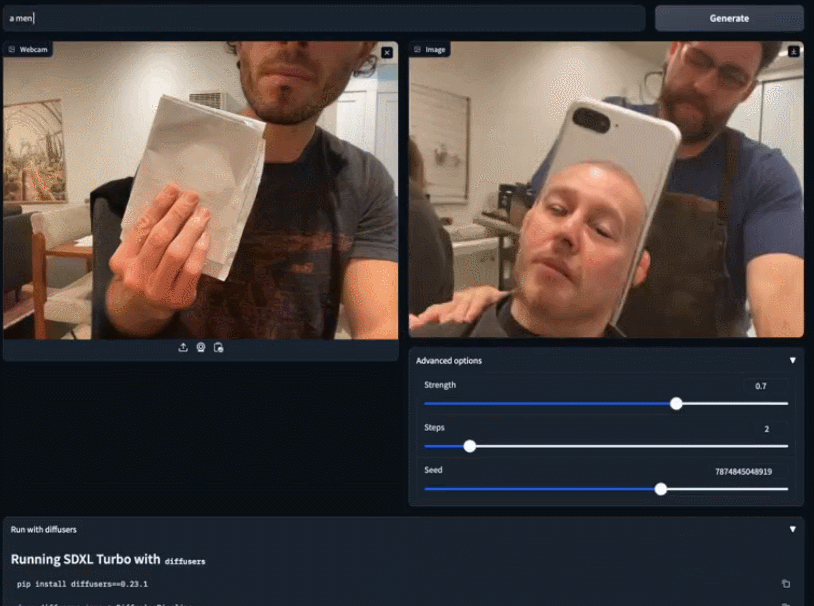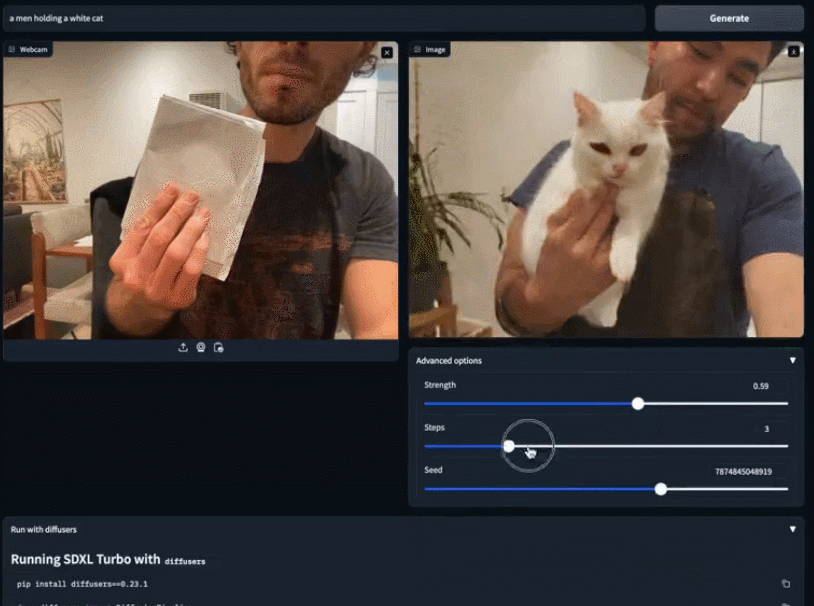
Kelajuan model SDXL Turbo itu sampai. hampir "masa nyata", dan orang ramai pasti tertanya-tanya: bolehkah model penjanaan imej digunakan untuk tujuan lain Seseorang yang disambungkan secara langsung ke permainan dan memperoleh skrin pemindahan gaya 2fps:
Menurut kepada rasmi Menurut blog itu, pada A100, SDXL Turbo boleh menjana imej 512x512 dalam 207 milisaat (pengekodan on-the-fly + langkah denoising tunggal + penyahkodan, fp16), yang mana satu penilaian ke hadapan UNet mengambil masa 67 milisaat. 
Dengan cara ini, kita boleh menilai Vincent Picture telah memasuki era "masa nyata".
Kecekapan "generasi segera" sedemikian kelihatan agak serupa dengan model Tsinghua LCM yang menjadi popular tidak lama dahulu, tetapi kandungan teknikal di belakangnya berbeza. Kestabilan memperincikan kerja dalaman model dalam kertas penyelidikan yang dikeluarkan pada masa yang sama. Penyelidikan ini memberi tumpuan kepada teknologi yang dipanggil Penyulingan Resapan Adversarial (ADD). Salah satu kelebihan SDXL Turbo yang didakwa adalah persamaannya dengan rangkaian permusuhan generatif (GAN), terutamanya dalam menjana output imej satu langkah.
Alamat kertas: https://static1.squarespace.com/ad/static/6213c340453c3f502425776e/t/65663480a92fba51d0e10231f ation.pdf 
Butiran kertas
Untuk tujuan ini, penyelidik memperkenalkan gabungan dua objektif latihan: (i) kehilangan musuh dan (ii) kehilangan penyulingan sepadan dengan SDS. Kehilangan lawan memaksa model untuk menjana sampel secara langsung yang terletak pada manifold imej sebenar pada setiap hantaran hadapan, mengelakkan kekaburan dan artifak lain yang biasa dalam kaedah penyulingan lain. Kehilangan penyulingan menggunakan satu lagi model resapan terlatih (dan tetap) sebagai guru, dengan berkesan memanfaatkan pengetahuannya yang luas dan mengekalkan komposisi yang kukuh yang diperhatikan dalam model resapan besar. Semasa proses inferens, penyelidik tidak menggunakan panduan bebas pengelas, seterusnya mengurangkan keperluan ingatan. Mereka mengekalkan keupayaan model untuk meningkatkan hasil melalui penghalusan berulang, kelebihan berbanding pendekatan berasaskan GAN satu langkah sebelumnya.
Langkah latihan ditunjukkan dalam Rajah 2:
Jadual 1 menunjukkan keputusan eksperimen ablasi Berikut adalah kesimpulan utama: 
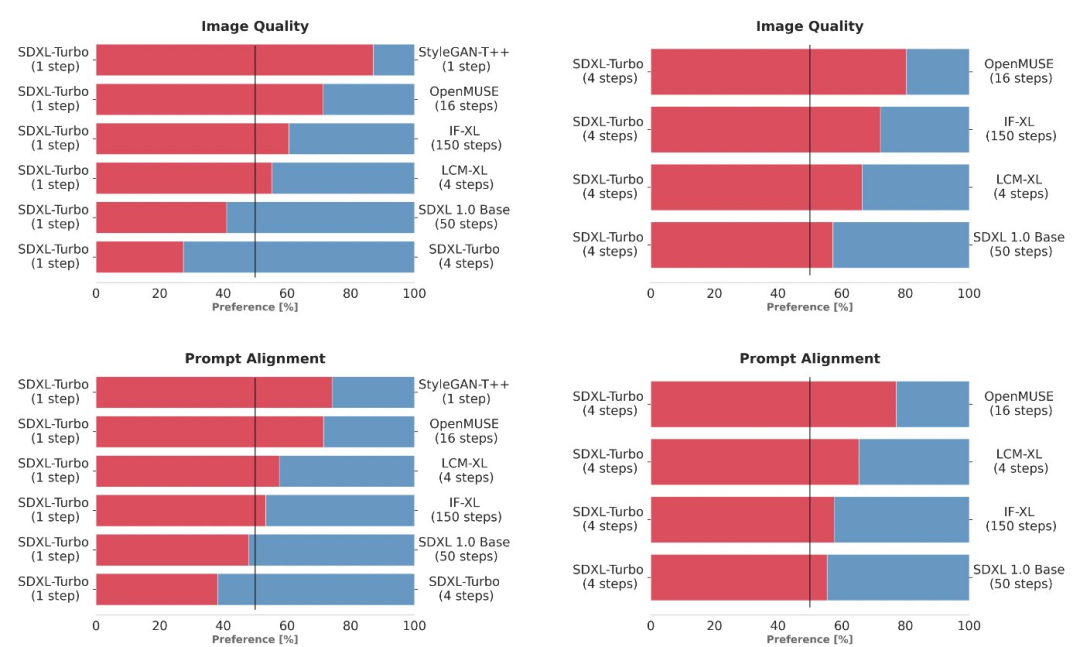
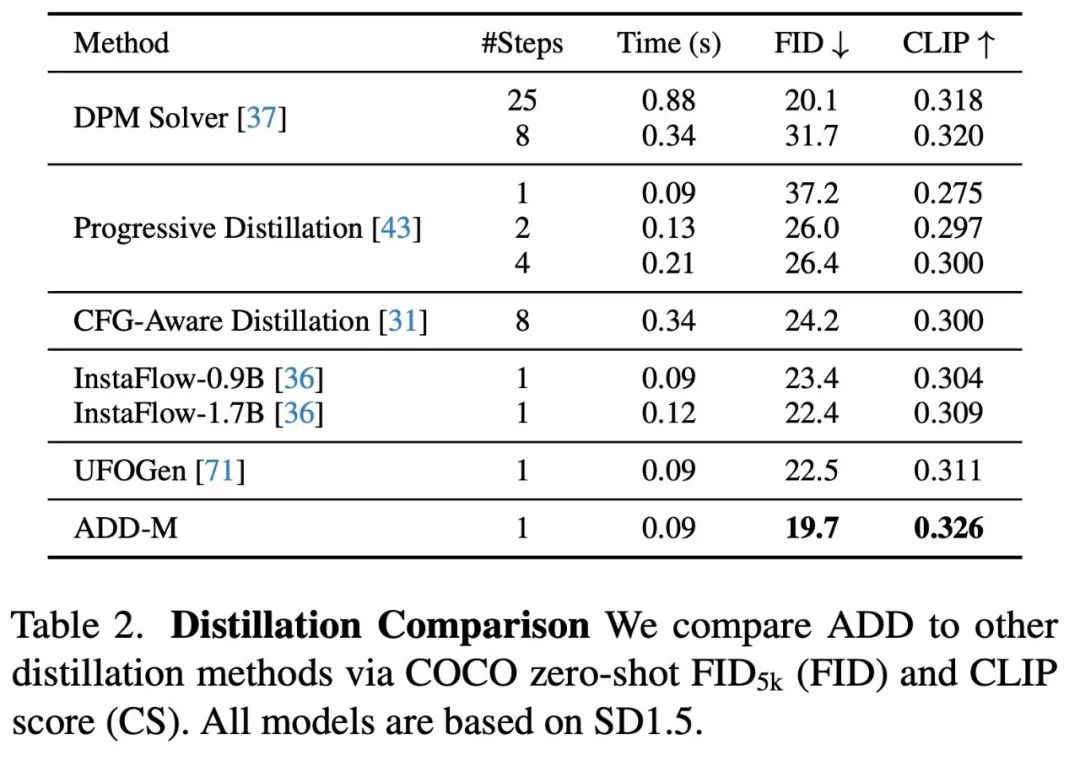
Seterusnya ialah perbandingan dengan model SOTA yang lain Di sini para penyelidik tidak menggunakan penunjuk automatik, tetapi memilih kaedah penilaian keutamaan pengguna yang lebih dipercayai Matlamatnya adalah untuk menilai pematuhan segera dan imej keseluruhan. Untuk membandingkan berbilang varian model berbeza (StyleGAN-T++, OpenMUSE, IF-XL, SDXL dan LCM-XL), percubaan menggunakan gesaan yang sama untuk menjana output. Dalam ujian buta, SDXL Turbo mengalahkan konfigurasi 4 langkah LCM-XL dalam satu langkah, dan mengalahkan konfigurasi 50 langkah SDXL dalam 4 langkah sahaja. Daripada keputusan ini, dapat dilihat bahawa SDXL Turbo mengungguli model berbilang langkah tercanggih sambil mengurangkan keperluan pengiraan dengan ketara tanpa mengorbankan kualiti imej Dibentangkan di sini ialah ELO untuk kelajuan inferens plot skor Dalam Jadual 2, kaedah pensampelan dan penyulingan beberapa langkah yang berbeza menggunakan model asas yang sama dibandingkan. Keputusan menunjukkan bahawa kaedah ADD mengatasi semua kaedah lain, termasuk penyelesai DPM standard 8 langkah Sebagai tambahan kepada keputusan eksperimen kuantitatif, kertas itu juga menunjukkan beberapa keputusan eksperimen kualitatif, menunjukkan ADD- Keupayaan XL untuk memperbaiki sampel awal. Rajah 3 membandingkan ADD-XL (1 langkah) dengan garis dasar terbaik semasa dalam skim beberapa langkah. Rajah 4 menerangkan proses persampelan lelaran ADD-XL. Rajah 8 memberikan perbandingan langsung ADD-XL dengan model gurunya, SDXL-Base. Seperti yang ditunjukkan oleh kajian pengguna, ADD-XL mengatasi model guru dalam kedua-dua penjajaran kualiti dan segera. Untuk butiran penyelidikan lanjut, sila rujuk kertas asal 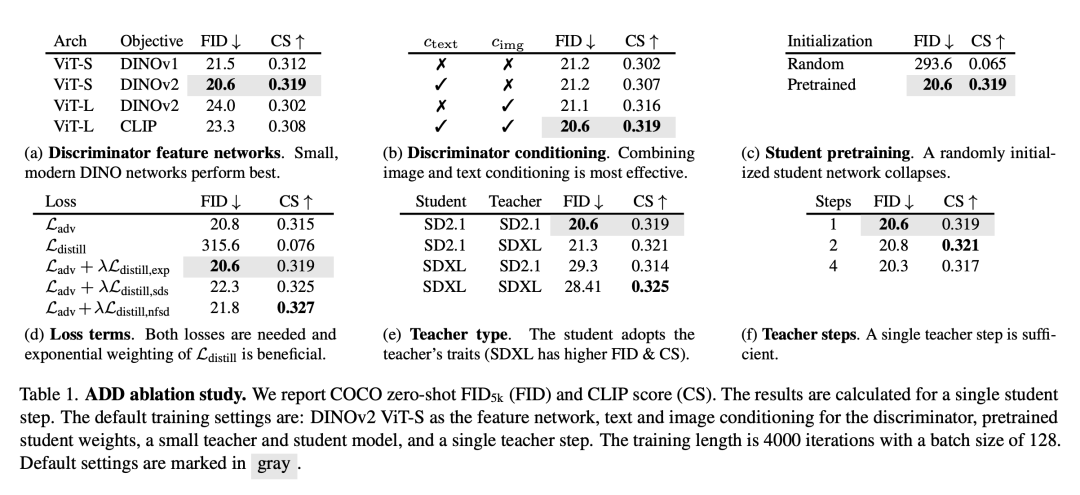 .
.




Atas ialah kandungan terperinci SDXL Turbo dan LCM membawa era penjanaan masa nyata lukisan AI: sepantas menaip, imej dipersembahkan serta-merta. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Perisian sambungan jauh yang popular
Perisian sambungan jauh yang popular
 Pengenalan kepada kekunci pintasan tangkapan skrin dalam sistem Windows 7
Pengenalan kepada kekunci pintasan tangkapan skrin dalam sistem Windows 7
 jejari sempadan
jejari sempadan
 perintah baris putus cad
perintah baris putus cad
 Bagaimana untuk menetapkan bahasa Cina dalam vscode
Bagaimana untuk menetapkan bahasa Cina dalam vscode
 fungsi direct3d tidak tersedia
fungsi direct3d tidak tersedia
 Penyelesaian kepada Google Chrome tidak berfungsi
Penyelesaian kepada Google Chrome tidak berfungsi








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



