


Regression ialah salah satu alat yang paling berkuasa dalam statistik Algoritma pembelajaran diselia pembelajaran mesin dibahagikan kepada dua jenis: algoritma klasifikasi dan algoritma regresi. Algoritma regresi digunakan untuk ramalan pengedaran berterusan dan boleh meramal data berterusan dan bukannya label kategori diskret sahaja.
Analisis regresi digunakan secara meluas dalam bidang pembelajaran mesin, seperti meramalkan jualan produk, aliran trafik, harga perumahan, keadaan cuaca, dll. Algoritma regresi ialah algoritma pembelajaran mesin yang biasa digunakan, digunakan untuk mewujudkan hubungan antara pembolehubah bebas X dan pembolehubah bersandar Y hubungan. Dari perspektif pembelajaran mesin, ia digunakan untuk membina model (fungsi) algoritma untuk mencapai hubungan pemetaan antara atribut X dan label Y. Semasa proses pembelajaran, algoritma cuba mencari hubungan parameter terbaik supaya kesesuaian adalah yang terbaik Dalam algoritma regresi, hasil akhir algoritma (fungsi) ialah nilai data berterusan. Nilai input (nilai atribut) ialah atribut d-dimensi/vektor angkaSesetengah algoritma regresi yang biasa digunakan termasuk regresi linear, regresi polinomial, regresi pepohon keputusan, regresi Ridge, regresi Lasso, regresi ElasticNet, dll.Artikel ini akan memperkenalkan beberapa yang biasa Algoritma regresi, dan ciri masing-masingWajaran Tempatan Regresi Linear
Satu , Regresi Linear
Regresi linear selalunya merupakan algoritma pertama yang orang pelajari tentang pembelajaran mesin dan sains data. Regresi linear ialah model linear yang menganggap hubungan linear antara pembolehubah input (X) dan pembolehubah keluaran tunggal (y). Secara umumnya, terdapat dua situasi:Beberapa perkara penting tentang regresi polinomial:
Jika bilangan ciri jauh lebih besar daripada bilangan sampel, ia adalah mudah untuk overfit
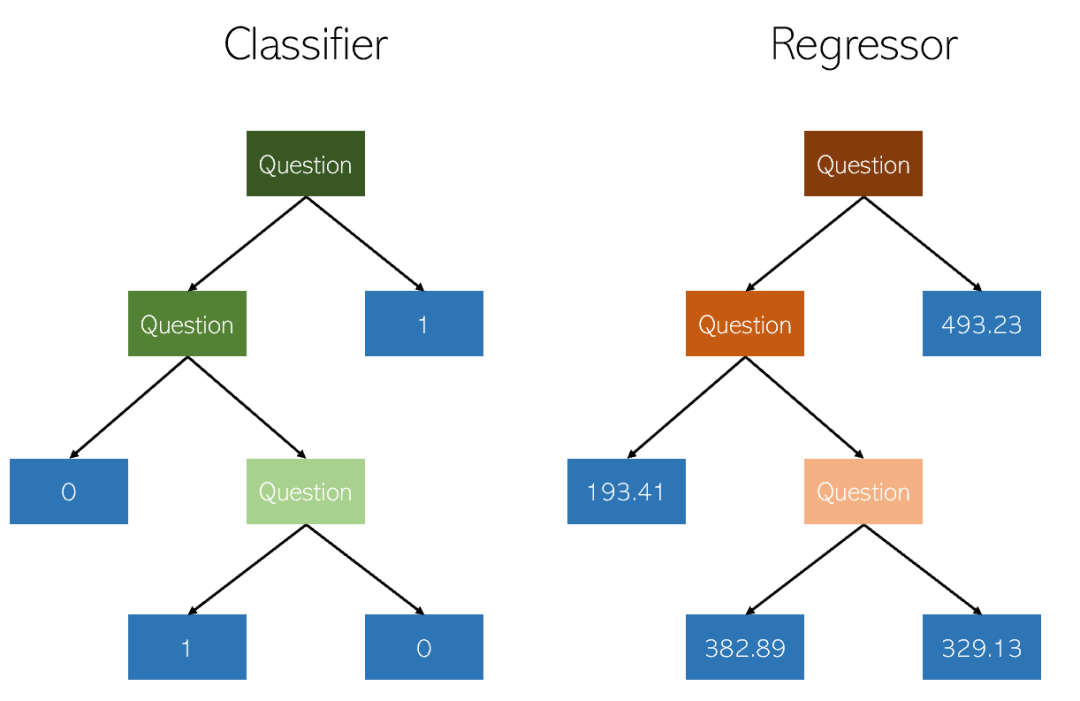
Kurangkan ketepatan yang berlebihan dalam pepohon keputusan.
Ia adalah ciri yang paling biasa digunakan untuk menghapuskan ciri automatik .
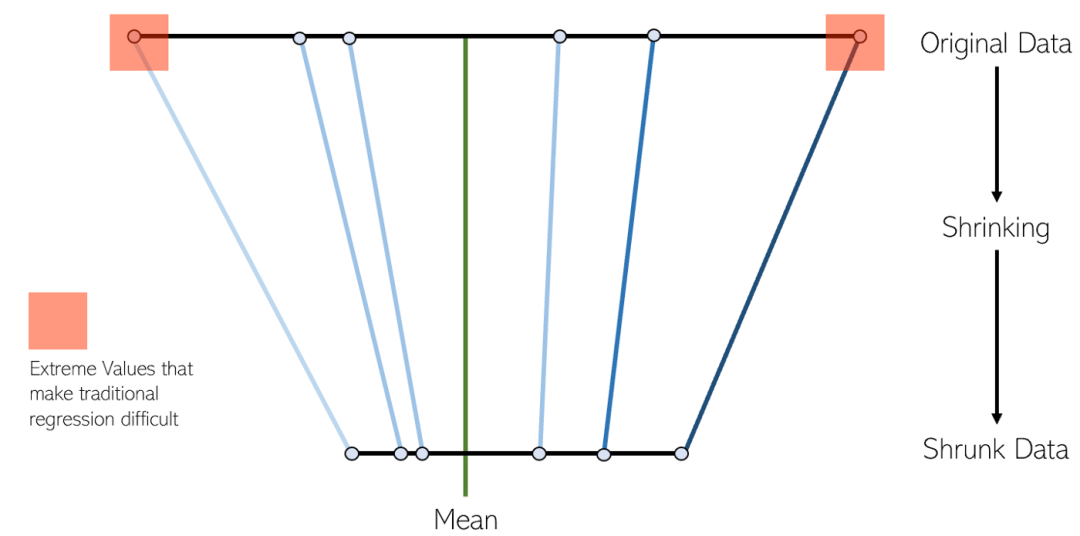
Ia sesuai untuk model yang menunjukkan multikolineariti yang teruk (ciri sangat berkorelasi antara satu sama lain).
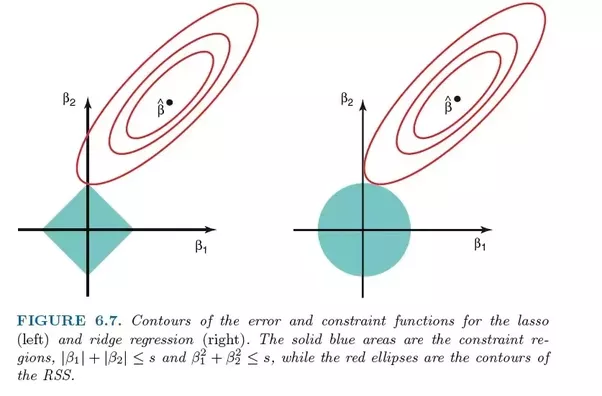
XGBoost ialah perpustakaan sumber terbuka yang pada asalnya dibangunkan oleh Chen Tianqi dalam makalah 2016 beliau "XGBoost: A Scalable Tree Boosting System". Algoritma direka untuk menjadi cekap dan cekap dari segi pengiraan
Dalam Regresi Linear Wajaran Tempatan (Regression Linear Wajaran Tempatan), kami juga melakukan regresi linear. Walau bagaimanapun, tidak seperti regresi linear biasa, regresi linear wajaran tempatan ialah kaedah regresi linear tempatan. Dengan memperkenalkan pemberat (fungsi kernel), semasa membuat ramalan, hanya beberapa sampel yang hampir dengan titik ujian digunakan untuk mengira pekali regresi. Regresi linear biasa ialah regresi linear global, yang menggunakan semua sampel untuk mengira pekali regresi Kelebihan melalui penurunan berat badan, pengurangan berat badan juga jelas. diperlukan. Apabila regresi linear berganda terlampau pasang, anda boleh mencuba pemberat tempatan kernel Gaussian untuk mengelakkan overfitting. Regresi Bayesian Ridge hitung bahagian belakang daripada sebelumnya. Regresi linear Bayesian boleh diselesaikan dengan kaedah berangka, dan dalam keadaan tertentu, statistik posterior atau berkaitan dalam bentuk analitik juga boleh diperolehi Kebaikan dan Kelemahan & Senario Berkenaan
Kelebihan regresi Bayesian ialah kebolehsuaian data yang berlebihan dan boleh mencegah penggunaan semula data Dalam proses penganggaran, istilah regularisasi boleh diperkenalkan Contohnya, dengan memperkenalkan istilah regularisasi L2 dalam regresi linear Bayesian, regresi rabung Bayesian boleh direalisasikan ialah proses pembelajaran yang terlalu mahal. Apabila bilangan ciri kurang daripada 10, anda boleh mencuba regresi Bayesian.
Sedikit perkara tentang XGBoost:
10. Regresi Linear Wajaran Tempatan
Kebaikan dan keburukan & senario yang boleh digunakan
Atas ialah kandungan terperinci Algoritma regresi yang biasa digunakan dan ciri-cirinya dalam aplikasi pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah platform e-dagang?
Apakah platform e-dagang?
 Apakah kuota cakera
Apakah kuota cakera
 Sepuluh pertukaran mata wang digital teratas
Sepuluh pertukaran mata wang digital teratas
 Pengenalan kepada mata wang digital konsep dex
Pengenalan kepada mata wang digital konsep dex
 Bagaimana untuk melihat prosedur tersimpan dalam MySQL
Bagaimana untuk melihat prosedur tersimpan dalam MySQL
 Apakah perisian lukisan yang ada?
Apakah perisian lukisan yang ada?
 Perbezaan antara halaman web statik dan halaman web dinamik
Perbezaan antara halaman web statik dan halaman web dinamik
 Pengenalan kepada komponen laravel
Pengenalan kepada komponen laravel








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



