


Adalah diketahui umum bahawa model bahasa besar (LLM) boleh belajar daripada sebilangan kecil contoh melalui pembelajaran kontekstual tanpa memerlukan penalaan halus model. Pada masa ini, fenomena pembelajaran kontekstual ini hanya boleh diperhatikan dalam model besar. Contohnya, model besar seperti GPT-4, Llama, dsb. telah menunjukkan prestasi cemerlang dalam banyak bidang, tetapi disebabkan kekangan sumber atau keperluan masa nyata yang tinggi, model besar tidak boleh digunakan dalam banyak senario
Kemudian, biasa- model bersaiz Adakah anda mempunyai keupayaan ini? Untuk meneroka keupayaan pembelajaran kontekstual model kecil, pasukan penyelidik dari Byte dan East China Normal University menjalankan penyelidikan mengenai tugas pengecaman teks adegan.
Pada masa ini, dalam senario aplikasi sebenar, pengecaman teks adegan menghadapi pelbagai cabaran: adegan berbeza, susun atur teks, ubah bentuk, perubahan pencahayaan, tulisan tangan kabur, kepelbagaian fon, dll., jadi sukar untuk melatih mesin yang boleh mengatasi semua senario Model pengecaman teks bersatu.
Cara langsung untuk menyelesaikan masalah ini ialah dengan mengumpul data yang sepadan dan memperhalusi model dalam senario tertentu. Walau bagaimanapun, proses ini memerlukan latihan semula model, yang intensif secara pengiraan, dan memerlukan penjimatan berbilang berat model untuk menyesuaikan diri dengan senario yang berbeza. Jika model pengecaman teks boleh mempunyai keupayaan pembelajaran konteks, apabila menghadapi adegan baharu, ia hanya memerlukan sejumlah kecil data beranotasi sebagai gesaan untuk meningkatkan prestasinya pada babak baharu, sekali gus menyelesaikan masalah di atas. Walau bagaimanapun, pengecaman teks adegan adalah tugas sensitif sumber, dan menggunakan model besar sebagai pengecam teks akan menggunakan banyak sumber. Melalui pemerhatian percubaan awal, penyelidik mendapati bahawa kaedah latihan model besar tradisional tidak sesuai untuk tugas pengecaman teks adegan
Untuk menyelesaikan masalah ini, pasukan penyelidik dari ByteDance dan East China Normal University mencadangkan pengecam teks yang berkembang sendiri , E2STR (Pengecam Teks Adegan Berkembang Ego). Ini ialah pengecam teks bersaiz biasa yang menggabungkan keupayaan pembelajaran konteks dan boleh menyesuaikan dengan pantas kepada senario pengecaman teks yang berbeza tanpa memerlukan penalaan halus

Pautan kertas: https://arxiv.org/pdf/2311.13120 .pdf
E2STR dilengkapi dengan latihan kontekstual dan mod penaakulan kontekstual, yang bukan sahaja mencapai tahap SOTA pada set data konvensional, tetapi juga boleh menggunakan satu model untuk meningkatkan prestasi pengecaman dalam pelbagai senario dan mencapai penyesuaian pantas kepada senario baharu, malah mengatasi prestasi pengiktirafan model khusus selepas penalaan halus. E2STR menunjukkan bahawa model bersaiz biasa adalah mencukupi untuk mencapai keupayaan pembelajaran konteks yang berkesan dalam tugasan pengecaman teks.
Dalam Rajah 1, latihan dan proses inferens E2STR ditunjukkan
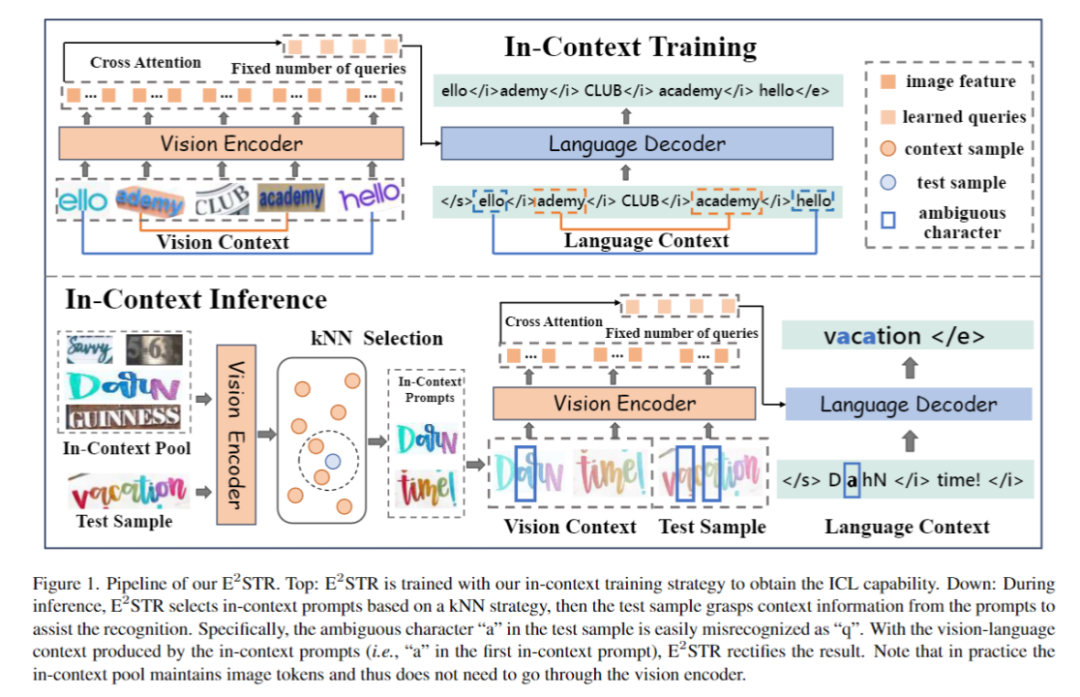
Pengecaman teks asas1. fasa latihan ion menggunakan autoregresif rangka kerja Tujuan melatih pengekod visual dan penyahkod bahasa adalah untuk mendapatkan keupayaan pengecaman teks:
Latihan konteks lanjutan akan dilatih mengikut E2STR yang dicadangkan. dalam artikel. Pada peringkat ini, E2STR akan belajar memahami perkaitan antara sampel yang berbeza untuk mendapatkan keupayaan penaakulan daripada isyarat kontekstual.
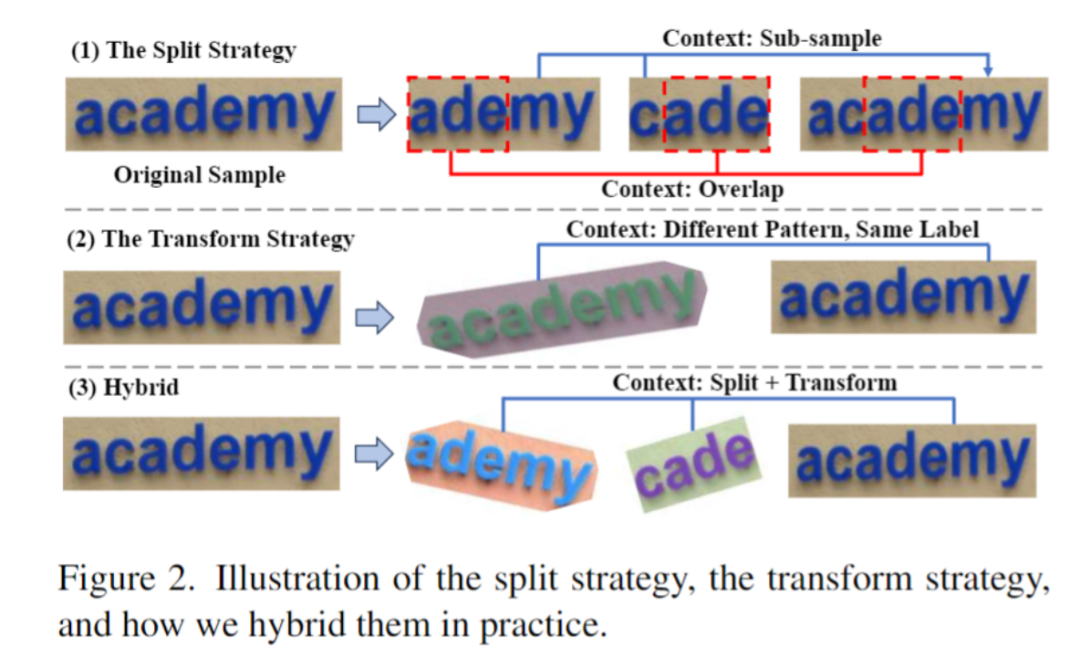 Seperti yang ditunjukkan dalam Rajah 2, artikel ini mencadangkan strategi ST untuk membahagikan dan mengubah data teks adegan secara rawak untuk menjana satu set "subsampel". Subsampel dikaitkan secara intrinsik secara visual dan linguistik. Sampel yang berkaitan secara dalaman ini disambungkan ke dalam urutan, dan model mempelajari pengetahuan kontekstual daripada jujukan yang kaya semantik ini, dengan itu memperoleh keupayaan untuk mempelajari konteks. Peringkat ini juga menggunakan rangka kerja autoregresif untuk latihan:
Seperti yang ditunjukkan dalam Rajah 2, artikel ini mencadangkan strategi ST untuk membahagikan dan mengubah data teks adegan secara rawak untuk menjana satu set "subsampel". Subsampel dikaitkan secara intrinsik secara visual dan linguistik. Sampel yang berkaitan secara dalaman ini disambungkan ke dalam urutan, dan model mempelajari pengetahuan kontekstual daripada jujukan yang kaya semantik ini, dengan itu memperoleh keupayaan untuk mempelajari konteks. Peringkat ini juga menggunakan rangka kerja autoregresif untuk latihan:
Isi yang perlu ditulis semula ialah: 3. Penaakulan kontekstual Kandungan yang ditulis semula: 3. Penaakulan berdasarkan konteks
Untuk sampel ujian, rangka kerja memilih N sampel daripada kumpulan isyarat kontekstual yang mempunyai persamaan tertinggi dengan sampel ujian dalam ruang terpendam visual. Secara khusus, artikel ini mengira pembenaman imej I dengan menghimpun purata pada jujukan token visual. Kemudian, sampel N teratas dengan persamaan kosinus tertinggi antara pembenaman imej dan I dipilih daripada kumpulan konteks, sekali gus membentuk isyarat kontekstual.
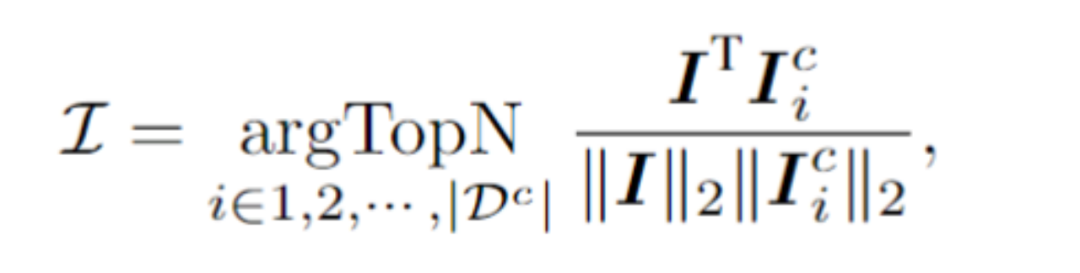
Selepas isyarat kontekstual dan sampel ujian disambungkan bersama dan dimasukkan ke dalam model, E2STR akan mempelajari pengetahuan baharu daripada isyarat kontekstual tanpa latihan, dengan itu meningkatkan ketepatan pengecaman sampel ujian. Adalah penting untuk ambil perhatian bahawa kumpulan kiu kontekstual hanya mengekalkan output token oleh pengekod visual, menjadikan proses pemilihan kiu kontekstual sangat cekap. Selain itu, memandangkan kolam pembayang konteks adalah kecil dan E2STR boleh melakukan inferens tanpa latihan, overhed pengiraan tambahan juga diminimumkan -pengiktirafan pemandangan domain dan pembetulan sampel yang sukar
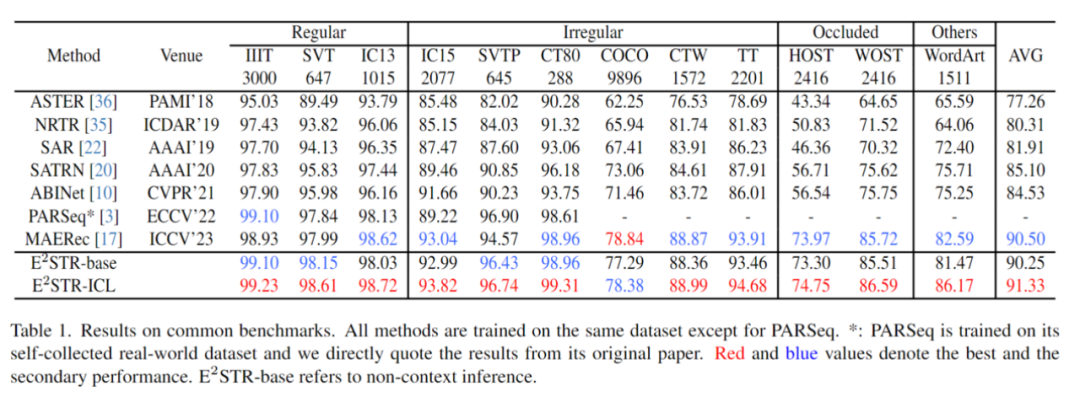
Pilih beberapa sampel secara rawak (1000, 0.025% daripada bilangan sampel dalam set latihan) daripada set latihan context prompt pool , ujian telah dijalankan pada 12 set ujian pengecaman teks adegan biasa, dan hasilnya adalah seperti berikut:
Boleh didapati bahawa E2STR masih bertambah baik pada set data tradisional di mana prestasi pengecaman adalah hampir tepu, mengatasi prestasi model SOTA .
 Kandungan yang perlu ditulis semula ialah: 2. Senario merentas domain
Kandungan yang perlu ditulis semula ialah: 2. Senario merentas domain
Dalam senario merentas domain, setiap set ujian hanya menyediakan 100 sampel latihan dalam domain antara no dan penalaan halus adalah seperti berikut, E2STR malah melebihi keputusan Penalaan halus kaedah SOTA.
Kandungan yang perlu ditulis semula ialah: 3. Ubah suai sampel yang sukar
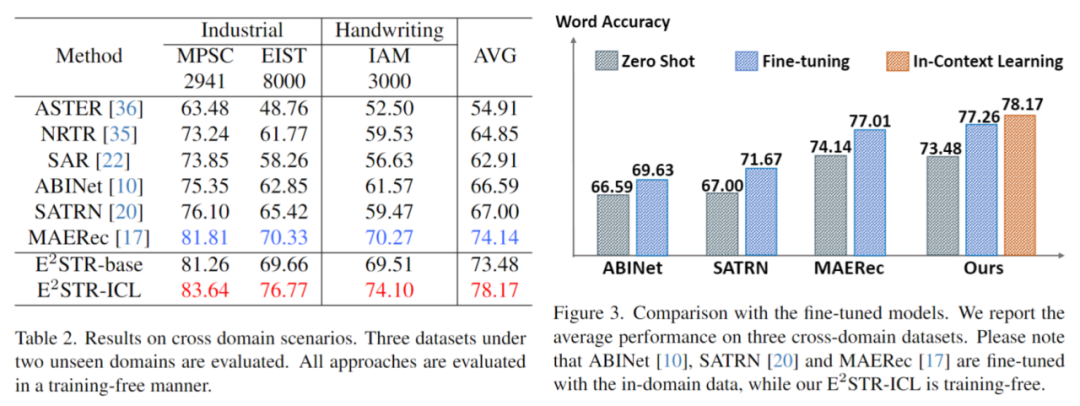
Berbanding dengan kaedah penalaan halus, E2STR-ICL mengurangkan kadar ralat sampel yang sukar dengan ketara.
Tinjauan Masa Depan
E2STR membuktikan bahawa menggunakan latihan dan strategi inferens yang sesuai, model kecil juga boleh mempunyai keupayaan pembelajaran dalam konteks yang serupa dengan LLM. Dalam sesetengah tugasan dengan keperluan masa nyata yang kukuh, model kecil juga boleh digunakan untuk menyesuaikan diri dengan cepat kepada senario baharu. Lebih penting lagi, kaedah menggunakan model tunggal ini untuk mencapai penyesuaian pantas kepada senario baharu membawa satu langkah lebih dekat untuk membina model kecil yang bersatu dan cekap.
Atas ialah kandungan terperinci Tajuk yang diutarakan semula ialah: ByteDance dan Kerjasama Universiti Normal China Timur: Meneroka Keupayaan Pembelajaran Kontekstual Model Kecil. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



