


Kandungan yang perlu ditulis semula oleh penterjemah ialah: |Kandungan yang perlu ditulis semula ialah: Bugatti
Kandungan yang perlu ditulis semula oleh penyemak ialah: |Kandungan yang perlu untuk ditulis semula ialah: Chonglou
Dari Mengekstrak pandangandaripada dokumen dan data adalah penting untuk andauntuk membuat keputusan termaklum. Namun, apabila berurusan dengan maklumat sensitif, isu privasi boleh timbul. Penggunaan gabungan LangChain dan OpenAI perlu ditulis semula: API, anda boleh menganalisis dokumen tempatan tanpa memuat naiknya ke Internet.
Mereka melakukannya ini dengan menyimpan data secara setempat, menggunakan pembenaman dan vektorisasi untuk analisis dan melaksanakan proses dalam persekitaran anda. OpenAI tidak menggunakan data yang diserahkan oleh pelanggan melalui APInya untuk melatih model atau menambah baik perkhidmatan. . Kemudian jalankan arahan terminal berikut untuk memasang perpustakaan yang diperlukan. e pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
Salin selepas log masuk
langchain: Anda akan menggunakannya untuk membuat dan mengurus aplikasi untuk pemprosesan teks dan linguistik rantaian analisis. Ia akan menyediakan modul untuk memuatkan dokumen, pembahagian teks, pembenaman dan storan volum.
OpenAI: Anda akan menggunakannya untuk menjalankan pertanyaan ,
APIKunci sebagai sebahagian daripada permintaan. Kunci ini membolehkan APIpembekal mengesahkan bahawa permintaan itu datang daripada sumber yang sah dan anda
mempunyaiKemudian di bawah akaun profil di bahagian atas sebelah kanan, klik pada "LihatAPI kekunci muncul APIRahsia halaman utama.
Klik butang "Buat Kunci Baharu"
. Namakan kunci
Namakan kunci
dan klik "Buat Kunci Baharu". OpenAI akan menjana kunci API, yang perlu anda salin dan simpan di tempat yang selamat. Atas sebab keselamatan, anda tidak akan dapat melihatnya lagi melalui akaun OpenAI anda. Jika anda kehilangan kunci , anda perlu menjana kunci baharu.
为了能够使用安装在虚拟环境中的库,您需要导入它们。
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。
先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。
接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。
需要改写的内容是:
text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。
您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
该函数使用创建的QA实例来运行查询并输出结果。
主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。
接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。
这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。
最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数:
if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。
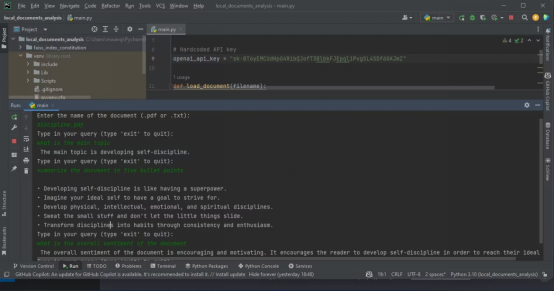
要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。
以下截图展示了对PDF进行分析的结果
Output di bawah menunjukkan hasil analisis fail teks yang mengandungi dengan kod sumber.
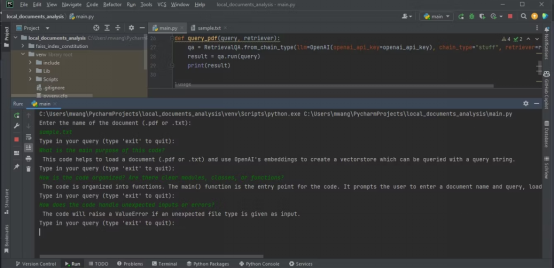
Pastikan fail yang ingin anda analisis adalah dalam format PDF atau teks. Jika dokumen anda berada dalam format lain , anda boleh menggunakan alatan dalam talian untuk menukarnya kepada format PDF . Kod sumber lengkap tersedia dalam repositori kod GitHub: https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI
Tajuk asal: ditulis semula Kandungan yang perlu ditulis semula ialah: hingga Kandungan yang perlu ditulis semula ialah: Menganalisis Kandungan yang perlu ditulis semula ialah: Dokumen Kandungan yang perlu ditulis semula ialah: Dengan Kandungan yang perlu ditulis semula ialah : LangChain Kandungan yang perlu ditulis semula ialah: dan Kandungan yang perlu ditulis semula ialah: kandungan yang perlu ditulis semula ialah: Kandungannya ialah: OpenAI Kandungan yang perlu ditulis semula ialah: API , pengarang: Denis Kandungan yang perlu ditulis semula ialah: Kuria
Kandungan yang perlu ditulis semula ialah:
Atas ialah kandungan terperinci Cara menggunakan LangChain dan OpenAI API untuk analisis dokumen. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Cara membetulkan get laluan lalai komputer tidak tersedia
Cara membetulkan get laluan lalai komputer tidak tersedia
 Bagaimana untuk mendayakan fungsi bandar yang sama pada Douyin
Bagaimana untuk mendayakan fungsi bandar yang sama pada Douyin
 Semak ruang cakera dalam linux
Semak ruang cakera dalam linux
 Bagaimana untuk mengecas semula Ouyiokx
Bagaimana untuk mengecas semula Ouyiokx
 permainan ipad tiada bunyi
permainan ipad tiada bunyi
 titik simbol khas
titik simbol khas
 kekunci pintasan komen python
kekunci pintasan komen python
 Penjelasan popular tentang maksud Metaverse XR
Penjelasan popular tentang maksud Metaverse XR








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



