


Matematik, sebagai asas sains, sentiasa menjadi bidang utama penyelidikan dan inovasi.
Baru-baru ini, tujuh institusi termasuk Universiti Princeton telah bersama-sama mengeluarkan model bahasa besar LLEMMA khusus untuk matematik, dengan prestasi yang setanding dengan Google Minerva 62B, dan menjadikan model, set data dan kodnya awam, membawa manfaat yang belum pernah terjadi sebelumnya kepada peluang penyelidikan dan matematik sumber.

Alamat kertas: https://arxiv.org/abs/2310.10631
Alamat pautan set data ialah: https://huggingface.co/datasets/EleutherAI/proof 2
Alamat projek: https://github.com/EleutherAI/math-lm Apa yang perlu ditulis semula ialah:
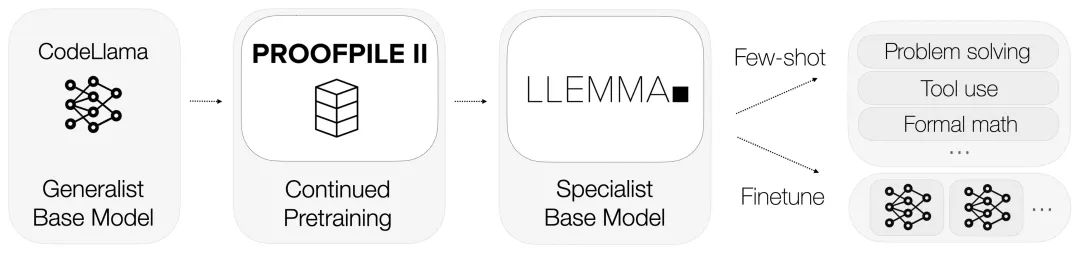
LLEMMA mewarisi asas Kod Llama dan dilatih terlebih dahulu pada Proof-Pile-2.
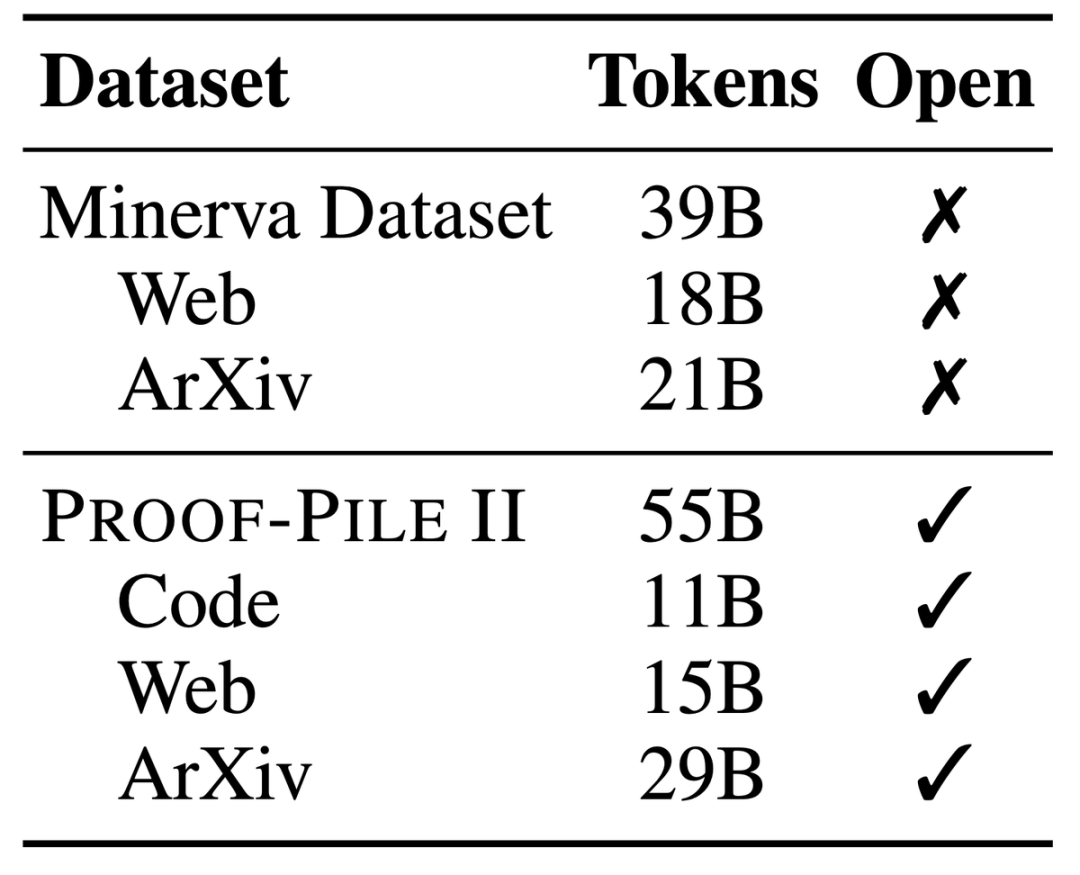
Proof-Pile-2, set data bercampur besar yang mengandungi maklumat 55 bilion token, termasuk kertas saintifik, data web yang kaya dengan kandungan matematik dan kod matematik.
Sebahagian daripada set data ini, Tindanan Algebra, menghimpunkan set data 11B daripada 17 bahasa, meliputi pembuktian berangka, simbolik dan matematik.
Dengan 700 juta dan 3.4 bilion parameter, prestasinya amat baik dalam penanda aras MATH, mengatasi semua model asas sumber terbuka yang diketahui.
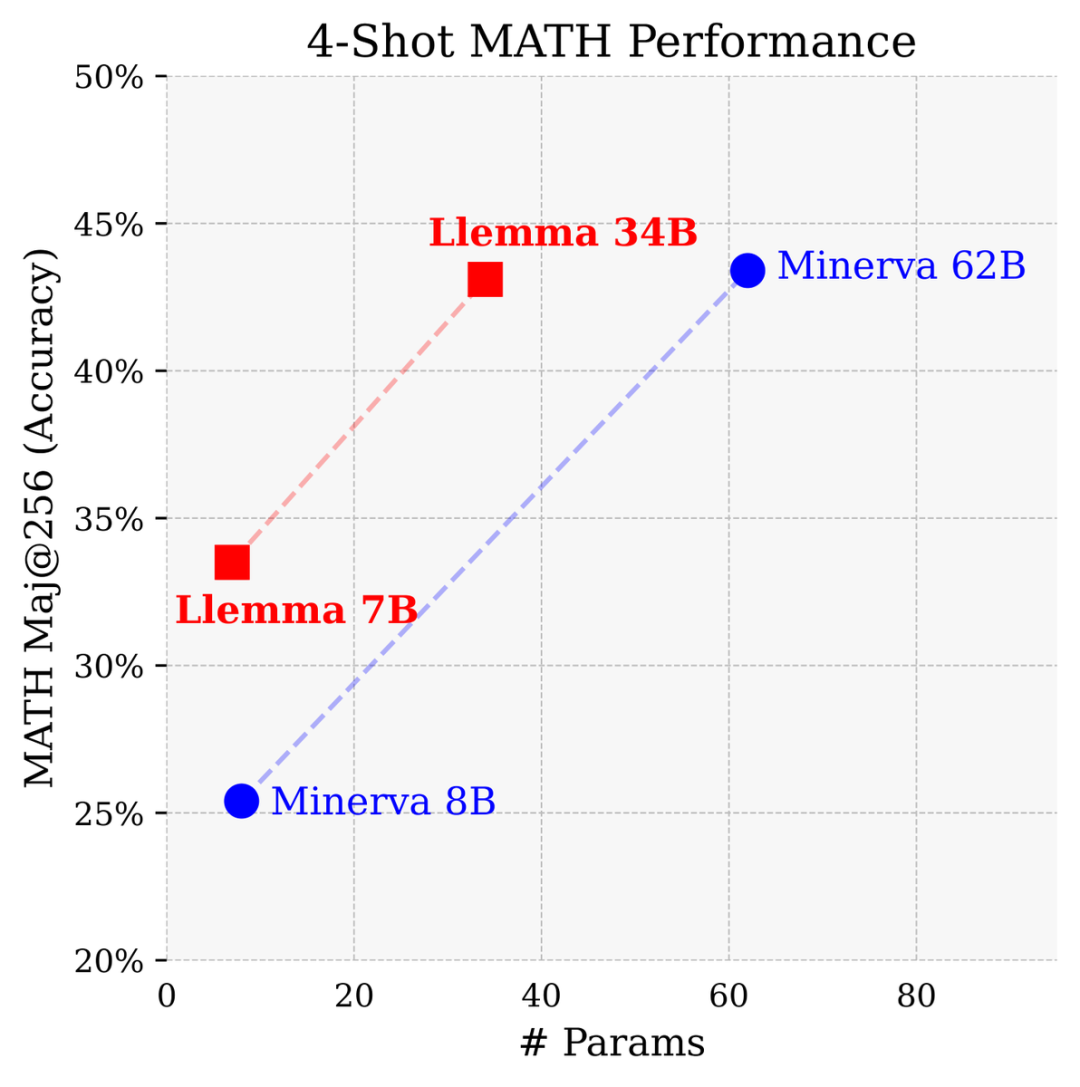
Berbanding dengan model tertutup yang dibangunkan oleh Google Research khusus untuk matematik, Llemma 34B mencapai prestasi yang hampir sama dengan separuh daripada bilangan parameter Minerva 62B.
Llemma mengatasi prestasi Minerva dalam menyelesaikan masalah berdasarkan parameter Ia menggunakan alat pengiraan dan bukti teorem formal untuk menyediakan kemungkinan tanpa had untuk menyelesaikan masalah matematik
. menunjukkan keupayaannya dalam menyelesaikan masalah matematik
Disebabkan penekanan khusus pada data bukti formal, Algebraic Stack menjadi sumber terbuka pertama yang menunjukkan keupayaan untuk membuktikan teorem beberapa pukulan Model asas

Gambar
Para penyelidik juga secara terbuka berkongsi semua data latihan dan kod LLEMMA. Berbeza daripada model matematik sebelumnya, LLEMMA ialah model sumber terbuka, terbuka dan dikongsi, membuka pintu kepada seluruh komuniti penyelidikan saintifik.
Para penyelidik cuba mengukur kesan memori model, dan secara mengejutkan, mereka mendapati bahawa Llemma tidak menjadi lebih tepat untuk masalah yang muncul dalam set latihan. Memandangkan kod dan data tersedia secara terbuka, para penyelidik menggalakkan orang lain untuk meniru dan melanjutkan analisis mereka 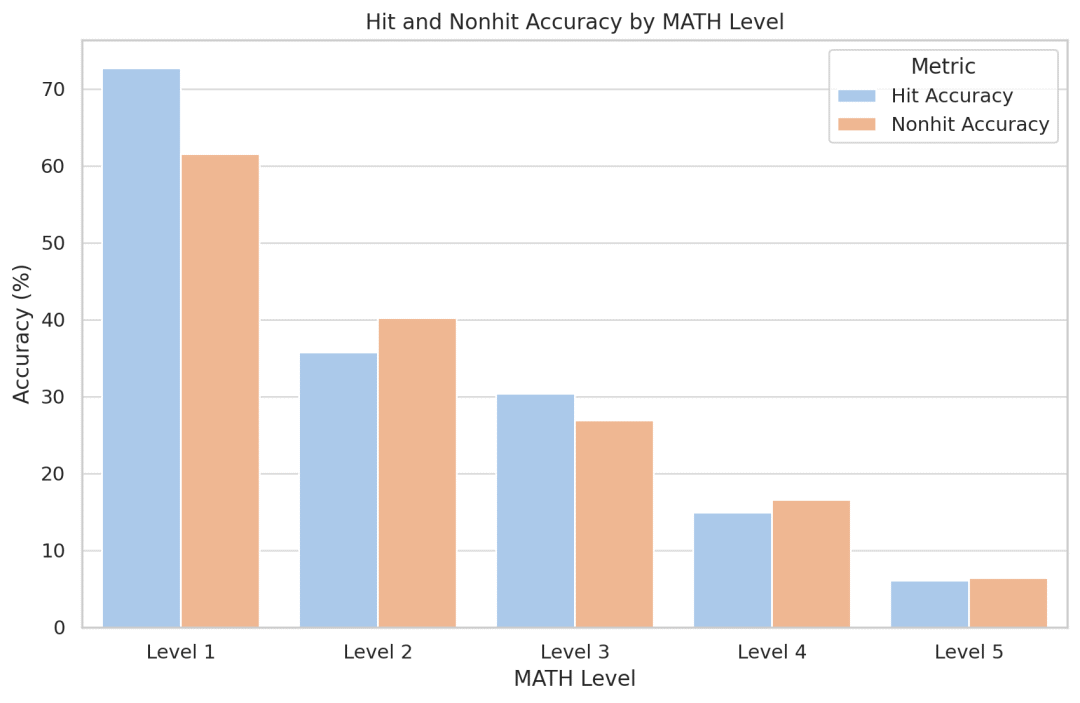
LLEMMA ialah model bahasa besar khusus untuk matematik, yang terus dilatih terlebih dahulu pada Proof-Pile-2 berdasarkan Kod Llama. Proof-Pile-2 ialah set data campuran yang mengandungi kertas saintifik, data halaman web dengan kandungan matematik, dan kod matematik Ia mengandungi 55 bilion tag Bahagian kod AlgebraicStack mengandungi set data 11B, termasuk 17 jenis kod sumber. meliputi matematik berangka, simbolik dan formal, dikeluarkan secara terbuka
Setiap model dalam LLEMMA dimulakan oleh Kod Llama. Model Kod Llama ialah model bahasa penyahkod sahaja yang dimulakan daripada Llama 2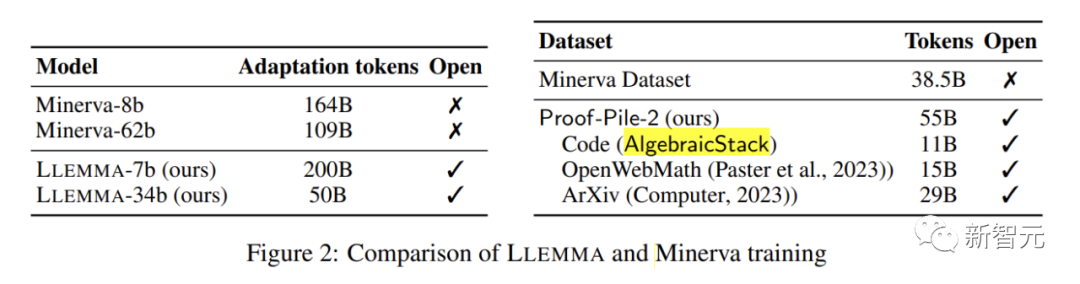
Pengarang terus melatih model Kod Llama pada Proof-Pile-2, menggunakan sasaran model pembinaan bahasa autoregresif standard. Bagi model 7B, penulis melakukan latihan dengan penanda 200B, manakala untuk model 34B, penulis melakukan latihan dengan penanda 50B
Kaedah penilaian dan hasil eksperimen
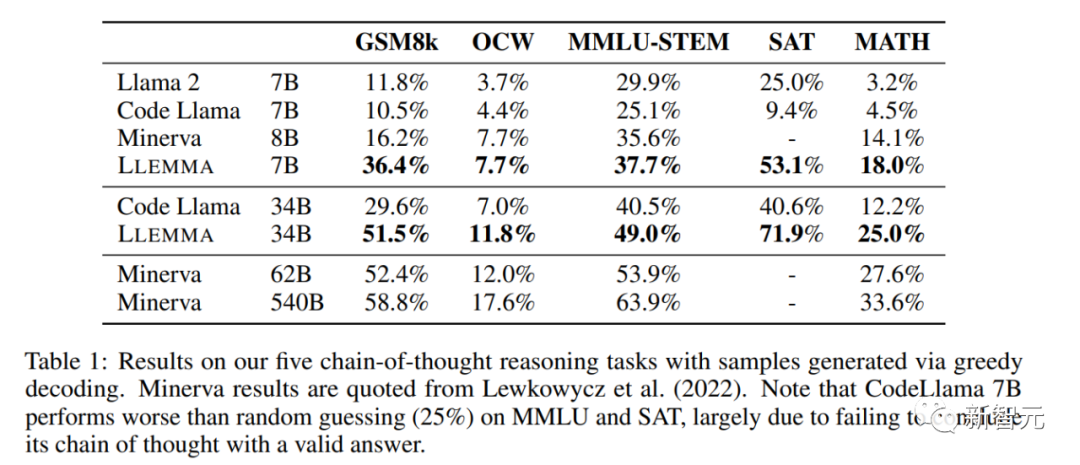
Penyelidik mendapati bahawa LLEMMA telah bertambah baik dengan ketara dalam tugasan ini dan dapat menyesuaikan diri dengan jenis masalah dan kesukaran yang berbeza. . pada lima tanda aras matematik.
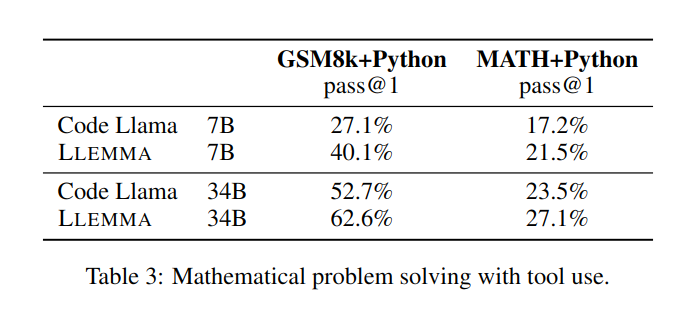
Peningkatan LLEMMA 34B adalah 20 mata peratusan lebih tinggi daripada Kod Llama pada GSM8k dan 13 mata peratusan lebih tinggi pada MATH. Selain itu, LLEMMA 7B juga mengatasi prestasi model Minerva proprietari dengan saiz yang sama, yang membuktikan bahawa pra-latihan pada Proof-Pile-2 secara berkesan boleh meningkatkan keupayaan penyelesaian masalah matematik model besar
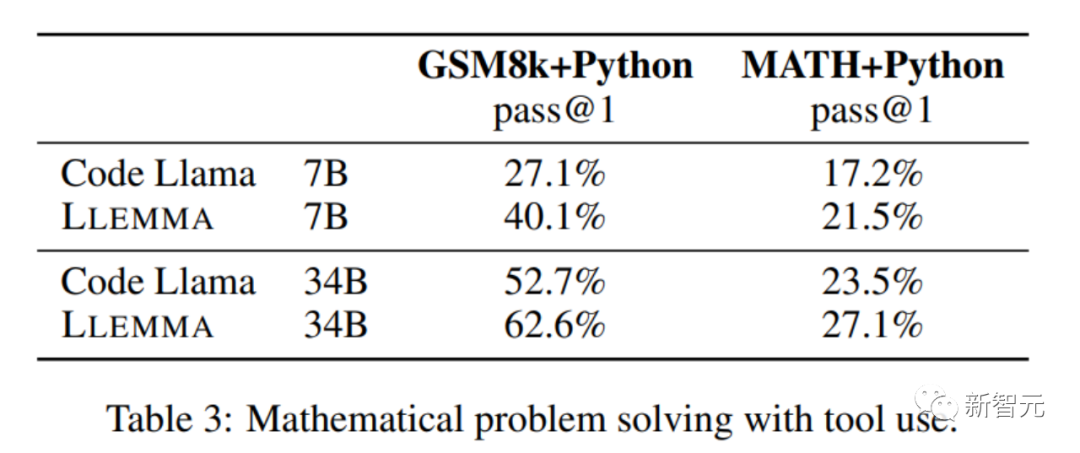
dalam menyelesaikan masalah matematik. menggunakan alat pengkomputeran seperti Python, LLEMMA berprestasi lebih baik daripada Code Llama pada kedua-dua tugas MATH+Python dan GSM8k+Python
Apabila menggunakan set data MATH dan GSM8k, prestasi LLEMMA adalah lebih baik daripada itu tanpa menggunakan alatan
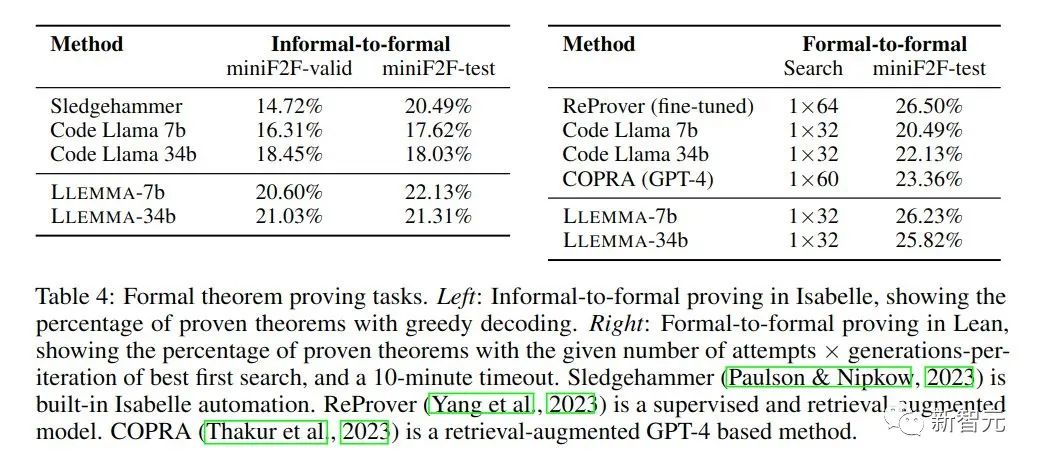
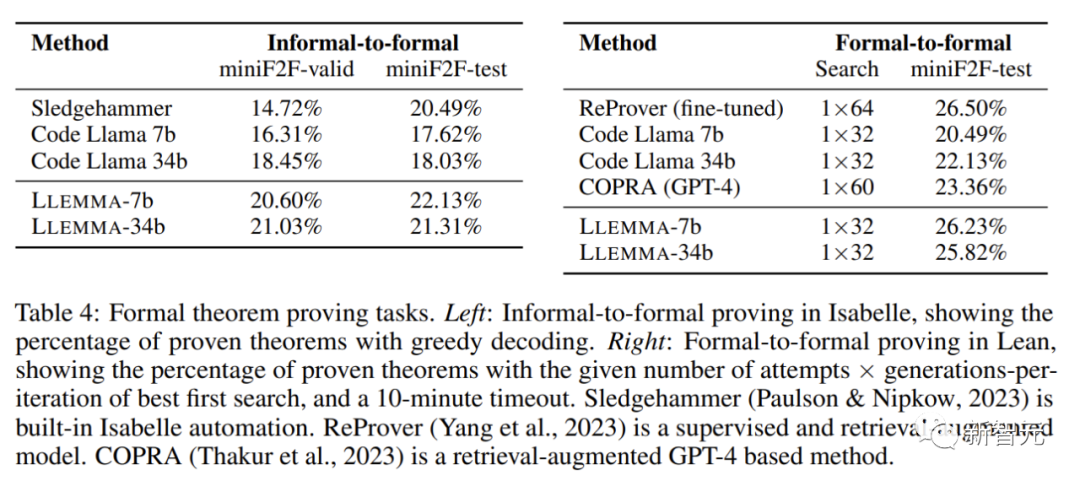
 Dalam tugasan pembuktian matematik, LLEMMA berprestasi baik
Dalam tugasan pembuktian matematik, LLEMMA berprestasi baik
Objektif tugasan pembuktian tidak formal kepada pembuktian formal diberikan pernyataan formal, penyataan LATEX tidak formal dan pembuktian LATEX tidak formal dijana dan kemudian disahkan oleh pembantu bukti.
Pembuktian rasmi kepada rasmi ialah membuktikan kenyataan rasmi dengan menghasilkan satu siri langkah pembuktian (strategi). Keputusan menunjukkan bahawa pra-latihan berterusan LLEMMA pada Proof-Pile-2 meningkatkan prestasi beberapa pukulan kedua-dua tugas pembuktian teorem formal ini.
LLEMMA bukan sahaja mempunyai prestasi yang mengagumkan, tetapi juga membuka set data revolusioner dan menunjukkan keupayaan menyelesaikan masalah yang menakjubkan.
Semangat perkongsian sumber terbuka menandakan era baharu dalam dunia matematik. Masa depan matematik ada di sini, dan setiap seorang daripada kita peminat matematik, penyelidik dan pendidik akan mendapat manfaat daripadanya.
Kemunculan LLEMMA memberikan kita alat yang belum pernah terjadi sebelum ini untuk menjadikan penyelesaian masalah matematik lebih cekap dan inovatif.
Atas ialah kandungan terperinci Model matematik sumber terbuka 34B Princeton: parameter dibahagi separuh, prestasi setanding dengan Google Minerva dan 55 bilion Token digunakan untuk latihan data profesional. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Pengenalan kepada maksud javascript
Pengenalan kepada maksud javascript
 Perbezaan antara sistem Hongmeng dan sistem Android
Perbezaan antara sistem Hongmeng dan sistem Android
 penggunaan klonenod
penggunaan klonenod
 Bagaimana untuk membuka fail ofd
Bagaimana untuk membuka fail ofd
 Apakah aplikasi Internet of Things?
Apakah aplikasi Internet of Things?
 Penjelasan terperinci tentang acara onbeforeunload
Penjelasan terperinci tentang acara onbeforeunload
 Pengenalan kepada carriage return dan aksara suapan baris dalam java
Pengenalan kepada carriage return dan aksara suapan baris dalam java








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



