


Secara amnya, penggunaan model bahasa besar biasanya menggunakan kaedah "pra-latihan-penalaan-halus". Walau bagaimanapun, apabila memperhalusi model asas untuk pelbagai tugas (seperti pembantu peribadi), kos latihan dan servis menjadi sangat tinggi. Penyesuaian Pangkat Rendah (LoRA) ialah kaedah penalaan halus parameter yang cekap, yang biasanya digunakan untuk menyesuaikan model asas kepada berbilang tugas, dengan itu menjana sejumlah besar penyesuai LoRA terbitan
Ditulis semula: Inferens kelompok memberikan banyak peluang semasa penyajian, dan corak ini telah ditunjukkan untuk mencapai prestasi yang setanding dengan penalaan halus penuh dengan penalaan halus pemberat penyesuai. Walaupun pendekatan ini mendayakan inferens penyesuai tunggal berkependaman rendah dan pelaksanaan bersiri merentas penyesuai, pendekatan ini mengurangkan daya pemprosesan keseluruhan perkhidmatan dengan ketara dan meningkatkan kependaman keseluruhan apabila menyediakan berbilang penyesuai secara serentak. Oleh itu, cara menyelesaikan masalah perkhidmatan berskala besar bagi varian yang diperhalusi ini masih tidak diketahui
Baru-baru ini, penyelidik dari UC Berkeley, Stanford dan universiti lain mencadangkan kaedah penalaan halus baharu yang dipanggil S-LoRA dalam kertas kerja

S-LoRA ialah sistem yang direka untuk penyajian berskala bagi banyak penyesuai LoRA. Ia menyimpan semua penyesuai dalam memori utama dan mengambil penyesuai yang digunakan oleh pertanyaan yang sedang dijalankan ke dalam memori GPU.
S-LoRA mencadangkan teknologi "Unified Paging", yang menggunakan kumpulan memori bersatu untuk mengurus tahap pemberat penyesuai dinamik yang berbeza dan tensor cache KV dengan panjang jujukan yang berbeza. Selain itu, S-LoRA menggunakan strategi selari tensor baharu dan kernel CUDA tersuai yang sangat dioptimumkan untuk membolehkan pemprosesan kumpulan heterogen pengiraan LoRA.
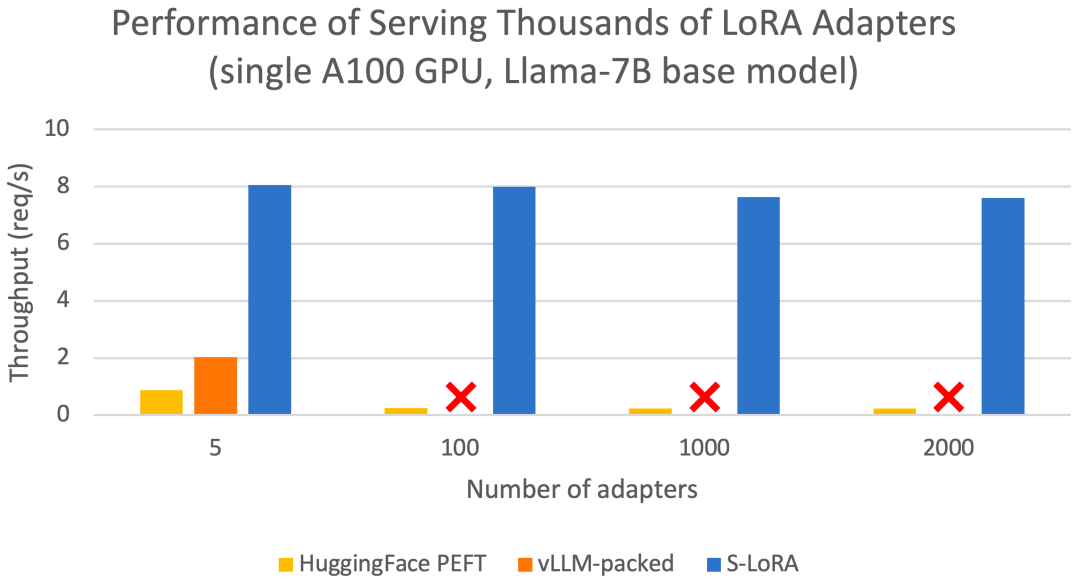
Ciri-ciri ini membolehkan S-LoRA menyediakan beribu-ribu penyesuai LoRA pada GPU tunggal atau berbilang pada sebahagian kecil daripada kos (menyediakan 2000 penyesuai serentak) dan meminimumkan kos pengiraan LoRA tambahan. Sebagai perbandingan, vLLM-packed perlu mengekalkan berbilang salinan pemberat dan hanya boleh menyediakan kurang daripada 5 penyesuai kerana had memori GPU
Berbanding dengan terkini seperti HuggingFace PEFT dan vLLM (hanya menyokong perkhidmatan LoRA ) Berbanding dengan perpustakaan, S-LoRA boleh meningkatkan daya pengeluaran sehingga 4 kali ganda, dan bilangan penyesuai yang disampaikan boleh ditingkatkan dengan beberapa urutan magnitud. Oleh itu, S-LoRA mampu menyediakan perkhidmatan berskala untuk banyak model penalaan halus khusus tugas dan menawarkan potensi untuk penyesuaian berskala besar perkhidmatan penalaan halus.
S-LoRA mengandungi tiga bahagian inovatif utama. Bahagian 4 memperkenalkan strategi kelompok yang digunakan untuk menguraikan pengiraan antara model asas dan penyesuai LoRA. Di samping itu, para penyelidik juga menyelesaikan cabaran penjadualan permintaan, termasuk aspek seperti pengelompokan penyesuai dan kawalan kemasukan. Keupayaan untuk membatch merentas penyesuai serentak membawa cabaran baharu kepada pengurusan memori. Pada bahagian kelima, penyelidik mempromosikan PagedAttention kepada Unfied Paging untuk menyokong pemuatan dinamik penyesuai LoRA. Pendekatan ini menggunakan kumpulan memori bersatu untuk menyimpan cache KV dan berat penyesuai dalam cara berhalaman, yang boleh mengurangkan pemecahan dan mengimbangi saiz cache KV dan berat penyesuai yang berubah secara dinamik. Akhir sekali, Bahagian 6 memperkenalkan strategi selari tensor baharu yang boleh memisahkan model asas dan penyesuai LoRA dengan cekap
Berikut ialah sorotan:
untuk penyesuai tunggal. (2021) mencadangkan kaedah yang disyorkan, iaitu menggabungkan pemberat penyesuai dengan pemberat model asas, menghasilkan model baharu (lihat Persamaan 1). Faedahnya ialah tiada overhed penyesuai tambahan semasa inferens kerana model baharu mempunyai bilangan parameter yang sama dengan model asas. Malah, ini juga merupakan ciri ketara karya LoRA asal
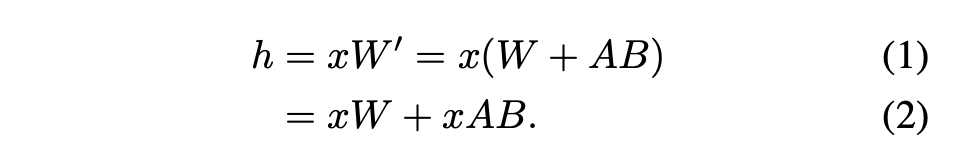
Artikel ini menunjukkan bahawa penggabungan penyesuai LoRA ke dalam model asas adalah tidak cekap untuk persediaan perkhidmatan pemprosesan tinggi berbilang LoRA. Sebaliknya, penyelidik mencadangkan untuk mengira LoRA dalam masa nyata untuk mengira xAB (seperti ditunjukkan dalam Persamaan 2).
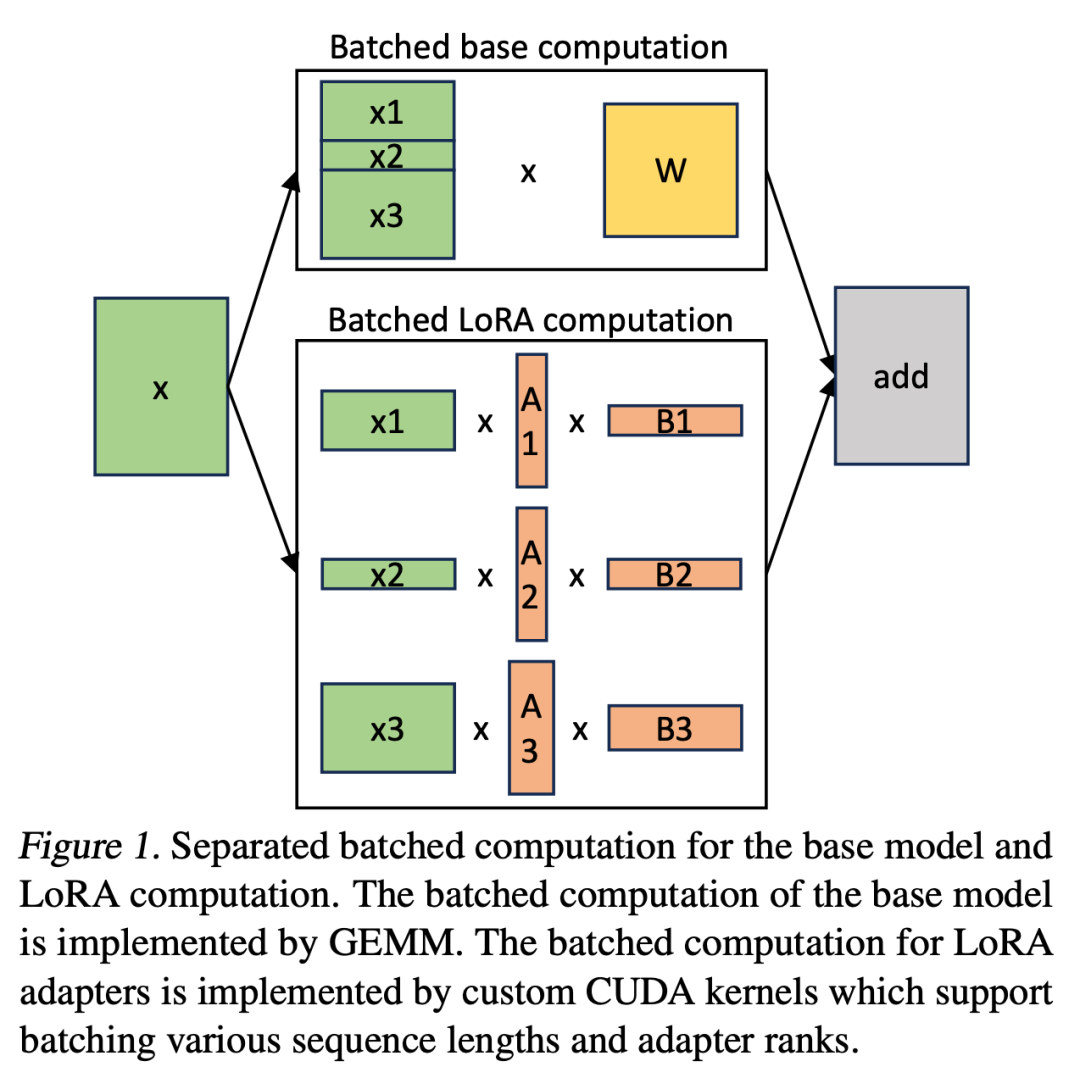
Dalam S-LoRA, pengiraan model asas dikumpulkan dan kemudian xAB tambahan dilakukan untuk semua penyesuai secara individu menggunakan kernel CUDA tersuai. Proses ini ditunjukkan dalam Rajah 1. Daripada menggunakan padding dan inti GEMM berkumpulan daripada perpustakaan BLAS untuk mengira LoRA, kami melaksanakan kernel CUDA tersuai untuk mencapai pengiraan yang lebih cekap tanpa padding, butiran pelaksanaan terdapat dalam subseksyen 5.3.
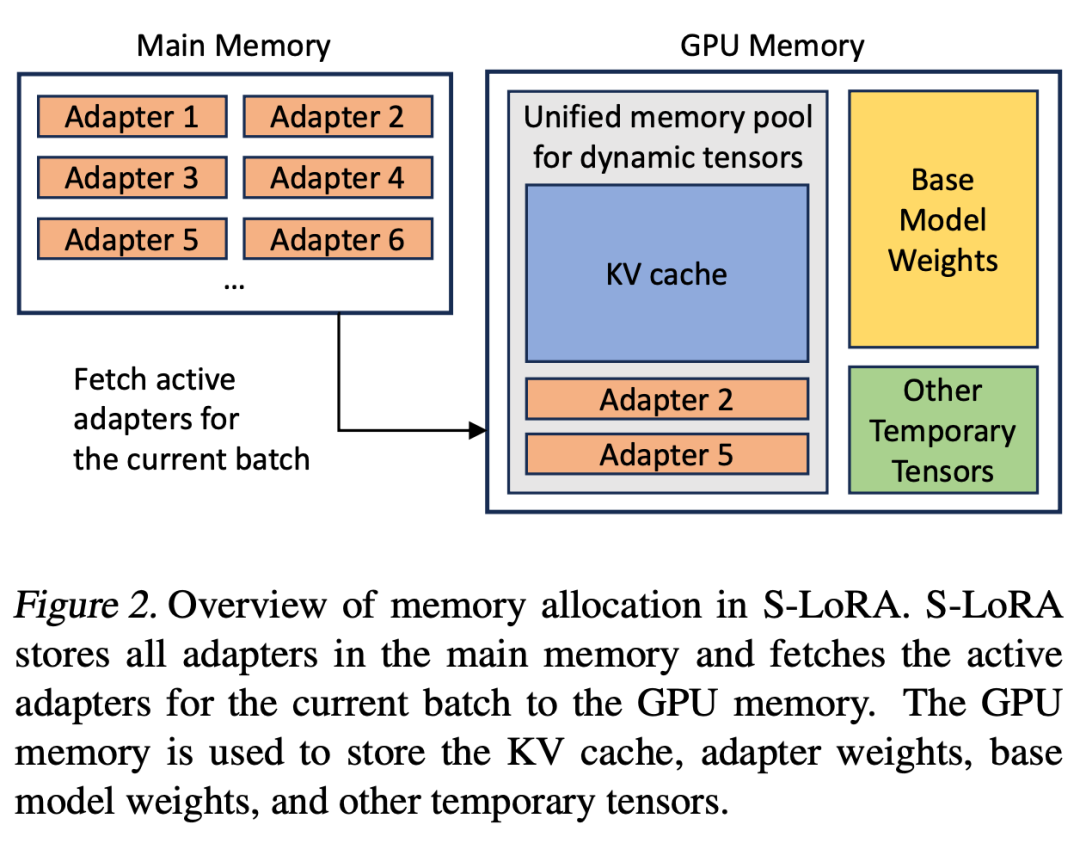
Jika penyesuai LoRA disimpan dalam ingatan utama, bilangannya mungkin besar, tetapi kumpulan sedang berjalan Bilangan Penyesuai LoRA yang diperlukan boleh dikawal kerana saiz kelompok dihadkan oleh memori GPU. Untuk memanfaatkan ini, kami menyimpan semua penyesuai LoRA dalam memori utama dan, apabila membuat kesimpulan untuk kumpulan yang sedang berjalan, ambil hanya penyesuai LoRA yang diperlukan untuk kumpulan itu ke dalam GPU RAM. Dalam kes ini, bilangan maksimum penyesuai yang boleh diservis dihadkan oleh saiz memori utama. Rajah 2 menggambarkan proses ini. Bahagian 5 juga membincangkan teknik untuk pengurusan ingatan yang cekap 🎜🎜#Melayani berbilang kad penyesuai LoRA secara serentak membawa cabaran pengurusan memori baharu berbanding dengan menyediakan model asas tunggal. Untuk menyokong berbilang penyesuai, S-LoRA menyimpannya dalam memori utama dan secara dinamik memuatkan berat penyesuai yang diperlukan untuk kumpulan yang sedang berjalan ke dalam RAM GPU.
Para penyelidik mengembangkan konsep PagedAttention kepada Unified Paging. Paging bersatu digunakan bukan sahaja untuk mengurus cache KV, tetapi juga untuk mengurus berat penyesuai. Paging bersatu menggunakan kumpulan memori bersatu untuk mengurus bersama cache KV dan berat penyesuai. Untuk mencapai matlamat ini, mereka mula-mula memperuntukkan penimbal besar secara statik ke kolam memori, yang menggunakan semua ruang yang ada kecuali ruang yang digunakan untuk menyimpan berat model asas dan tensor pengaktifan sementara. Cache KV dan berat penyesuai disimpan dalam kolam memori dengan cara berhalaman, dan setiap halaman sepadan dengan vektor H. Oleh itu, tensor cache KV dengan panjang jujukan S menduduki halaman S, manakala tensor berat LoRA peringkat R menduduki halaman R. Rajah 3 menunjukkan susun atur kolam memori, di mana cache KV dan pemberat penyesuai disimpan dalam cara bersilang dan tidak bersebelahan. Pendekatan ini sangat mengurangkan pemecahan dan memastikan tahap pemberat penyesuai yang berbeza boleh wujud bersama cache KV dinamik dengan cara yang berstruktur dan sistematik 🎜🎜#
Tensor parallelism#🎜🎜🎜## 🎜🎜# Selain itu, para penyelidik mereka bentuk strategi selari tensor baru untuk inferens LoRA kelompok untuk menyokong pelbagai transformasi model Transformer besar. Tensor parallelism ialah pendekatan selari yang paling banyak digunakan kerana program tunggal, paradigma berbilang data memudahkan pelaksanaan dan penyepaduannya dengan sistem sedia ada. Keselarian tensor boleh mengurangkan penggunaan memori dan kependaman bagi setiap GPU apabila menyediakan model besar. Dalam tetapan ini, penyesuai LoRA tambahan memperkenalkan matriks berat dan pendaraban matriks baharu, yang memerlukan strategi pembahagian baharu untuk penambahan ini.
evaluation#🎜🎜🎜🎜🎜🎜,#
evaluation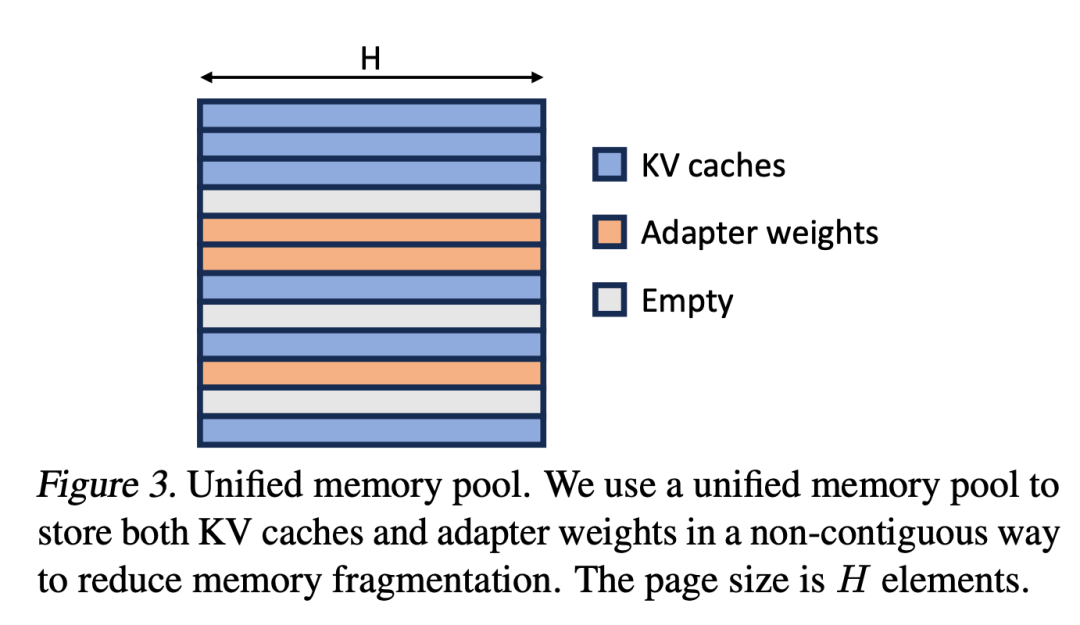 #🎜🎜🎜🎜,##🎜 Menyediakan perkhidmatan untuk Llama-7B/13B/30B/70B untuk menilai S-LoRA LoRA boleh menyediakan beribu-ribu penyesuai LoRA pada satu GPU atau berbilang GPU dengan sedikit overhed. S-LoRA mencapai daya pemprosesan sehingga 30x lebih tinggi berbanding Huggingface PEFT, perpustakaan penalaan halus cekap parameter terkini. S-LoRA meningkatkan daya pemprosesan sebanyak 4x dan meningkatkan bilangan penyesuai perkhidmatan dengan beberapa susunan magnitud berbanding menggunakan sistem perkhidmatan pemprosesan tinggi vLLM yang menyokong perkhidmatan LoRA.
#🎜🎜🎜🎜,##🎜 Menyediakan perkhidmatan untuk Llama-7B/13B/30B/70B untuk menilai S-LoRA LoRA boleh menyediakan beribu-ribu penyesuai LoRA pada satu GPU atau berbilang GPU dengan sedikit overhed. S-LoRA mencapai daya pemprosesan sehingga 30x lebih tinggi berbanding Huggingface PEFT, perpustakaan penalaan halus cekap parameter terkini. S-LoRA meningkatkan daya pemprosesan sebanyak 4x dan meningkatkan bilangan penyesuai perkhidmatan dengan beberapa susunan magnitud berbanding menggunakan sistem perkhidmatan pemprosesan tinggi vLLM yang menyokong perkhidmatan LoRA.
Atas ialah kandungan terperinci S-LoRA: Ada kemungkinan untuk menjalankan beribu-ribu model besar pada satu GPU. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Bagaimana untuk menyambung php ke pangkalan data mssql
Bagaimana untuk menyambung php ke pangkalan data mssql
 Kaedah BigDecimal untuk membandingkan saiz
Kaedah BigDecimal untuk membandingkan saiz
 Bagaimana untuk memampatkan fail html ke dalam zip
Bagaimana untuk memampatkan fail html ke dalam zip
 Platform data besar
Platform data besar
 psrpc.dll tidak menemui penyelesaian
psrpc.dll tidak menemui penyelesaian
 Bagaimana untuk menyemak penggunaan memori jvm
Bagaimana untuk menyemak penggunaan memori jvm
 Penyelesaian virus exe folder
Penyelesaian virus exe folder








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



