


Transformer telah berjaya dalam pelbagai tugas pembelajaran dalam bidang seperti pemprosesan bahasa semula jadi, penglihatan komputer dan ramalan siri masa. Walaupun kejayaan mereka, model ini masih menghadapi had kebolehskalaan yang teruk. Sebabnya ialah pengiraan tepat lapisan perhatian menghasilkan masa berjalan kuadratik (dalam urutan panjang) dan kerumitan memori. Ini membawa cabaran asas untuk memanjangkan model Transformer kepada panjang konteks yang lebih panjang
Industri telah meneroka pelbagai kaedah untuk menyelesaikan masalah lapisan perhatian temporal kuadratik, salah satu arahan yang perlu diberi perhatian ialah perhatian anggaran Matriks pertengahan dalam lapisan daya. Kaedah untuk mencapai ini termasuk penghampiran melalui matriks jarang, matriks peringkat rendah, atau gabungan kedua-duanya.
Walau bagaimanapun, kaedah ini tidak memberikan jaminan hujung ke hujung untuk anggaran matriks keluaran perhatian. Kaedah ini bertujuan untuk menganggarkan komponen perhatian individu dengan lebih cepat, tetapi tiada satu pun memberikan anggaran hujung ke hujung perhatian produk titik penuh. Kaedah ini juga tidak menyokong penggunaan topeng kausal, yang merupakan bahagian penting dalam seni bina Transformer moden. Batasan teori terkini menunjukkan bahawa secara amnya adalah tidak mungkin untuk melakukan penghampiran istilah bagi matriks perhatian dalam masa sub-kuadrat
Walau bagaimanapun, kajian terbaru yang dipanggil KDEFormer menunjukkan bahawa apabila istilah matriks perhatian disempadani Di bawah andaian , ia boleh memberikan anggaran yang boleh dibuktikan dalam masa subkuadrat. Secara teorinya, masa jalan KDEFormer adalah lebih kurang 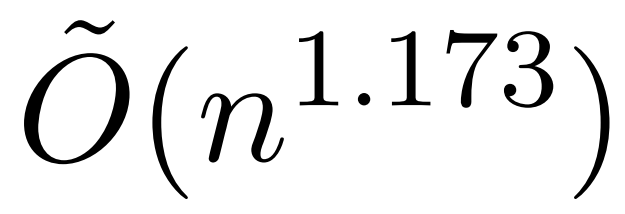 ; ia menggunakan anggaran ketumpatan kernel (KDE) untuk menganggarkan norma lajur, membolehkan pengiraan kebarangkalian pensampelan lajur matriks perhatian. Walau bagaimanapun, algoritma KDE semasa tidak mempunyai kecekapan praktikal, malah dalam teori terdapat jurang antara masa jalan KDEFormer dan algoritma masa O(n) yang boleh dilaksanakan secara teori. Dalam artikel itu, penulis membuktikan bahawa di bawah andaian kemasukan terhad yang sama, algoritma masa hampir linear
; ia menggunakan anggaran ketumpatan kernel (KDE) untuk menganggarkan norma lajur, membolehkan pengiraan kebarangkalian pensampelan lajur matriks perhatian. Walau bagaimanapun, algoritma KDE semasa tidak mempunyai kecekapan praktikal, malah dalam teori terdapat jurang antara masa jalan KDEFormer dan algoritma masa O(n) yang boleh dilaksanakan secara teori. Dalam artikel itu, penulis membuktikan bahawa di bawah andaian kemasukan terhad yang sama, algoritma masa hampir linear 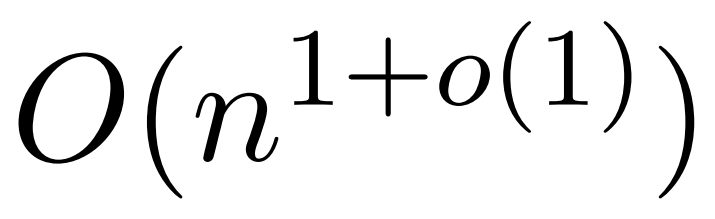 adalah mungkin. Walau bagaimanapun, algoritma mereka juga melibatkan penggunaan kaedah polinomial untuk menghampiri softmax, yang mungkin tidak praktikal.
adalah mungkin. Walau bagaimanapun, algoritma mereka juga melibatkan penggunaan kaedah polinomial untuk menghampiri softmax, yang mungkin tidak praktikal.
Dalam artikel ini, penyelidik dari Universiti Yale, Google Research dan institusi lain menyediakan algoritma yang mempunyai yang terbaik dari kedua-dua dunia, yang praktikal dan cekap serta boleh mencapai jaminan masa hampir linear terbaik. Tambahan pula, kaedah ini menyokong penutupan sebab akibat, yang tidak mungkin dalam kerja sebelumnya.

Segarkan pautan berikut untuk melihat kertas: https://arxiv.org/abs/2310.05869
Artikel ini mencadangkan mekanisme perhatian anggaran yang disebut "hyperattention". dikemukakan dengan menggunakan konteks yang panjang dalam model bahasa yang besar. Penyelidikan terkini menunjukkan bahawa dalam kes yang paling teruk, melainkan jika entri matriks perhatian disempadani atau kedudukan stabil matriks adalah rendah, masa kuadratik diperlukan
Ditulis semula seperti berikut: Para penyelidik memperkenalkan dua Parameter untuk mengukur: (1) norma lajur maksimum matriks perhatian ternormal, (2) perkadaran norma baris dalam matriks perhatian tidak normal selepas mengalih keluar masukan besar. Mereka menggunakan parameter berbutir halus ini untuk menggambarkan kesukaran masalah. Selagi parameter di atas adalah kecil, algoritma pensampelan masa linear boleh dilaksanakan walaupun matriks mempunyai entri tidak terhad atau pangkat stabil yang besar
HyperAttention mempunyai ciri reka bentuk modular dan boleh disepadukan dengan mudah dengan pelaksanaan asas pantas yang lain. , terutamanya It's FlashAttention. Secara empirik, Super Attention mengatasi kaedah sedia ada apabila menggunakan algoritma LSH untuk mengenal pasti entri yang besar, dan mencapai peningkatan kelajuan yang ketara berbanding dengan penyelesaian terkini seperti FlashAttention. Penyelidik mengesahkan prestasi HyperAttention pada pelbagai set data konteks dengan panjang yang berbeza-beza
Contohnya, HyperAttention menjadikan masa inferens ChatGLM2 50% lebih pantas pada panjang konteks 32k, manakala kebingungan meningkat daripada 5.6 kepada 6.3. HyperAttention adalah 5x lebih pantas pada satu lapisan perhatian dengan panjang konteks yang lebih besar (cth. 131k) dan topeng penyebab.
Perhatian produk titik melibatkan pemprosesan tiga matriks input: Q (pertanyaan), K (kunci), V (nilai), semua saiz nxd, dengan n ialah bilangan token dalam urutan input , d ialah dimensi perwakilan asas. Output proses ini adalah seperti berikut:
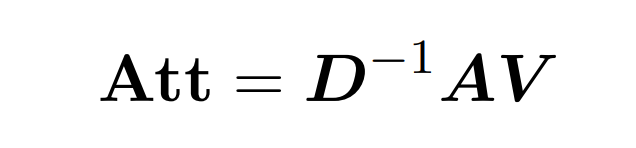
Di sini, matriks A := exp (QK^T) ditakrifkan sebagai indeks unsur QK^T. D ialah matriks pepenjuru n×n yang diperoleh daripada hasil tambah baris A, dengan 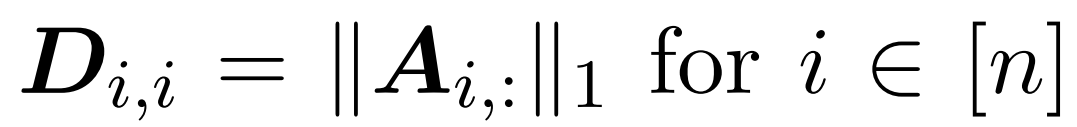 . Dalam kes ini, matriks A dipanggil "matriks perhatian" dan (D^-1) A dipanggil "matriks softmax". Perlu diingat bahawa pengiraan terus matriks perhatian A memerlukan operasi Θ(n²d), manakala menyimpannya menggunakan memori Θ(n²). Oleh itu, pengiraan Att secara langsung memerlukan masa jalan Ω(n²d) dan memori Ω(n²).
. Dalam kes ini, matriks A dipanggil "matriks perhatian" dan (D^-1) A dipanggil "matriks softmax". Perlu diingat bahawa pengiraan terus matriks perhatian A memerlukan operasi Θ(n²d), manakala menyimpannya menggunakan memori Θ(n²). Oleh itu, pengiraan Att secara langsung memerlukan masa jalan Ω(n²d) dan memori Ω(n²).
Matlamat penyelidik adalah untuk menganggarkan matriks keluaran Att dengan cekap sambil mengekalkan ciri spektrumnya. Strategi mereka terdiri daripada mereka bentuk penganggar cekap masa hampir linear untuk matriks penskalaan pepenjuru D. Tambahan pula, mereka dengan cepat menganggarkan hasil matriks matriks softmax D^-1A dengan pensubsampelan. Lebih khusus lagi, mereka bertujuan untuk mencari matriks pensampelan 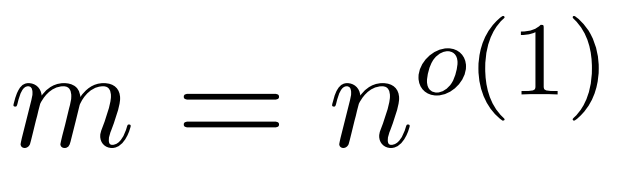 dengan bilangan baris yang terhingga
dengan bilangan baris yang terhingga 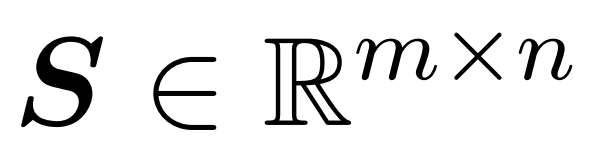 dan matriks pepenjuru
dan matriks pepenjuru 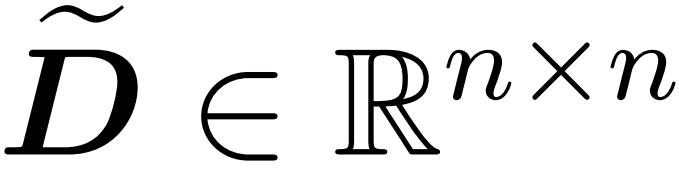 supaya kekangan berikut pada spesifikasi pengendali ralat dipenuhi:
supaya kekangan berikut pada spesifikasi pengendali ralat dipenuhi:
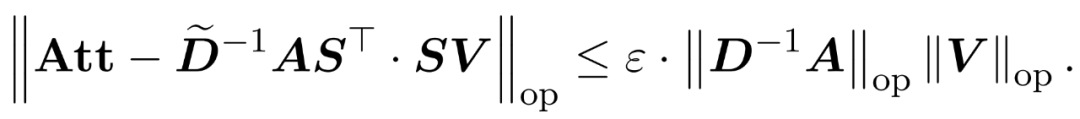
Penyelidik telah menunjukkan bahawa dengan mentakrifkan matriks persampelan S berdasarkan spesifikasi baris V, bahagian pendaraban matriks masalah penghampiran perhatian dalam formula (1) boleh diselesaikan dengan cekap. Masalah yang lebih mencabar ialah: bagaimana untuk mendapatkan anggaran yang boleh dipercayai bagi matriks pepenjuru D. Dalam keputusan terkini, Zandieh secara berkesan mengeksploitasi penyelesai KDE yang pantas untuk mendapatkan anggaran kualiti tinggi D. Kami memudahkan program KDEformer dan menunjukkan bahawa pensampelan seragam adalah mencukupi untuk mencapai jaminan spektrum yang diperlukan tanpa memerlukan pensampelan kepentingan berasaskan kepadatan kernel. Penyederhanaan ketara ini membolehkan mereka membangunkan algoritma masa linear yang praktikal dan boleh dibuktikan.
Berbeza dengan penyelidikan sebelum ini, kaedah kami tidak memerlukan penyertaan bersempadan atau pangkat stabil bersempadan. Tambahan pula, walaupun entri atau kedudukan stabil dalam matriks perhatian adalah besar, parameter berbutir halus yang diperkenalkan untuk menganalisis kerumitan masa mungkin masih kecil.
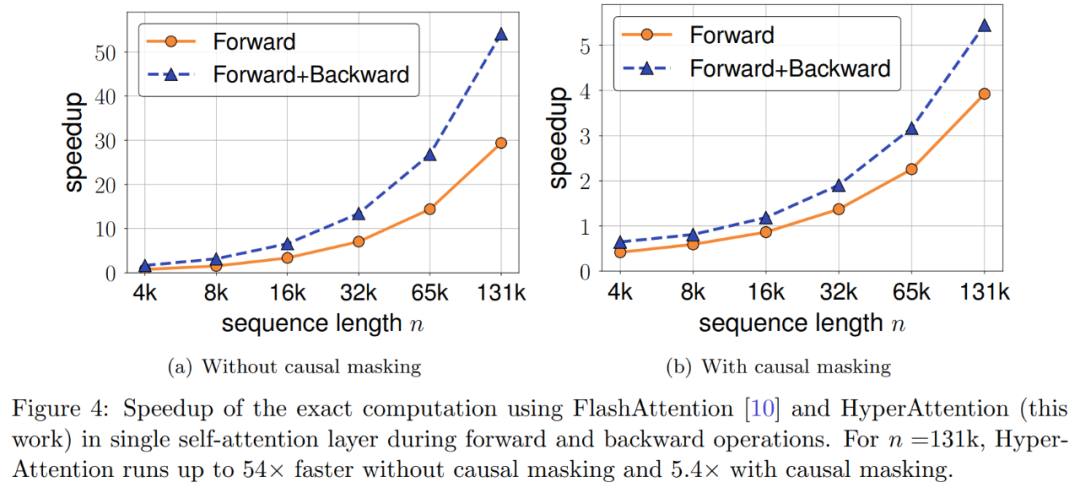
Akibatnya, HyperAttention jauh lebih pantas, dengan lebih 50 kali lebih pantas perambatan ke hadapan dan ke belakang pada panjang jujukan n= 131k. Kaedah ini masih mencapai kelajuan 5x yang besar apabila berurusan dengan topeng penyebab. Tambahan pula, apabila kaedah itu digunakan pada LLM pra-terlatih (seperti chatqlm2-6b-32k) dan dinilai pada set data penanda aras konteks panjang LongBench, ia mengekalkan tahap prestasi yang hampir dengan model asal walaupun tanpa memerlukan penalaan halus. . Para penyelidik juga menilai tugas tertentu dan mendapati bahawa tugasan ringkasan dan penyelesaian kod mempunyai kesan yang lebih besar pada lapisan perhatian anggaran berbanding tugas menyelesaikan masalah.
Untuk mendapatkan jaminan spektrum apabila menghampiri Att, langkah pertama dalam kertas ini ialah melakukan anggaran 1 ± ε pada sebutan pepenjuru matriks D. Selepas itu, hasil matriks antara A dan V dianggarkan dengan pensampelan (D^-1) mengikut baris persegi ℓ₂-norma V.
Proses menghampiri D terdiri daripada dua langkah. Pertama, algoritma yang berakar umbi dalam LSH pengisihan Hamming digunakan untuk mengenal pasti entri dominan dalam matriks perhatian, seperti yang ditunjukkan dalam Definisi 1. Langkah kedua ialah memilih subset kecil K secara rawak. Makalah ini akan menunjukkan bahawa, di bawah andaian ringan tertentu tentang matriks A dan D, kaedah mudah ini boleh mewujudkan sempadan spektrum matriks yang dianggarkan. Matlamat penyelidik adalah untuk mencari anggaran matriks D yang cukup tepat untuk memenuhi:

Andaian artikel ini ialah norma lajur matriks softmax mempamerkan pengedaran yang agak seragam. Lebih tepat lagi, pengkaji menganggap bahawa bagi mana-mana i ∈ [n] t terdapat beberapa 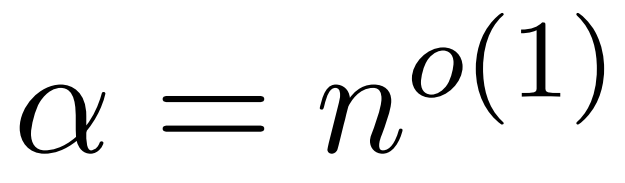 sedemikian rupa sehingga
sedemikian rupa sehingga 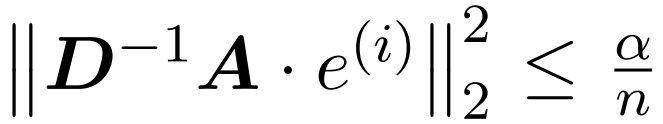 .
.
Langkah pertama algoritma ialah mengenal pasti entri besar dalam matriks perhatian A dengan mencincang kekunci dan pertanyaan ke dalam baldi bersaiz seragam menggunakan Hamming sorted LSH (sortLSH). Algoritma 1 memperincikan proses ini dan Rajah 1 menggambarkannya secara visual.
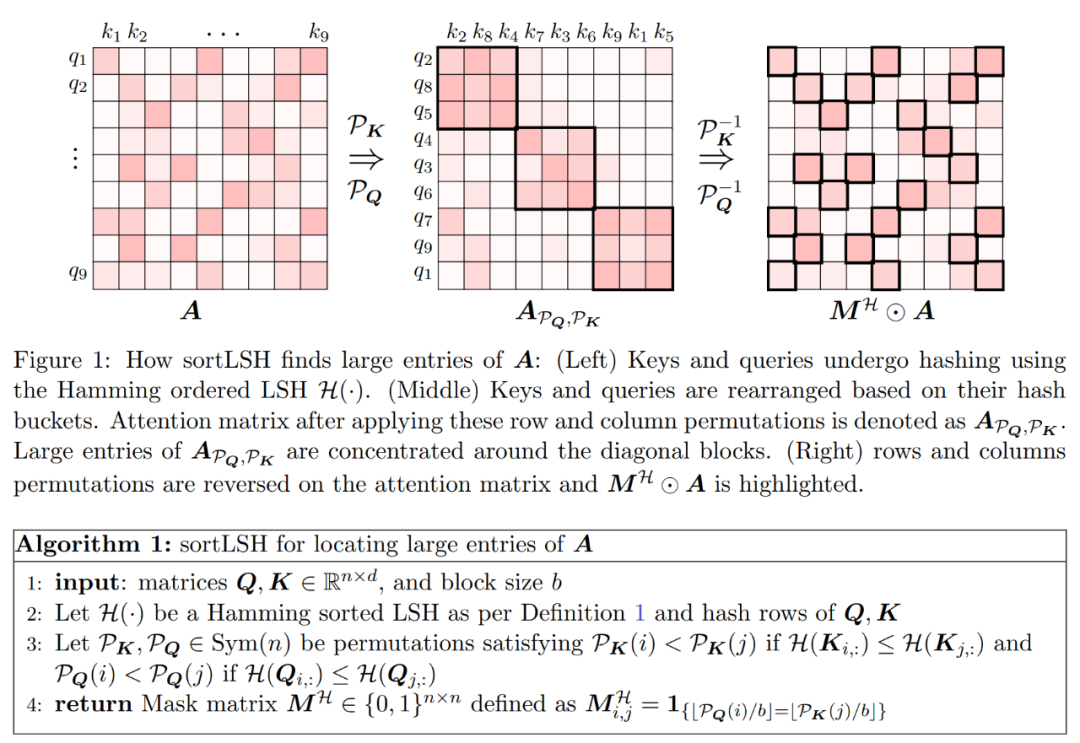
Fungsi Algoritma 1 adalah untuk mengembalikan topeng jarang yang digunakan untuk mengasingkan entri utama matriks perhatian. Selepas mendapat topeng ini, pengkaji boleh mengira anggaran matriks D dalam Algoritma 2 yang memenuhi jaminan spektrum dalam Persamaan (2). Algoritma ini dilaksanakan dengan menggabungkan nilai perhatian yang sepadan dengan topeng dengan set lajur yang dipilih secara rawak dalam matriks perhatian. Algoritma dalam kertas ini boleh digunakan secara meluas dan boleh digunakan dengan cekap dengan menggunakan topeng yang telah ditetapkan untuk menentukan kedudukan entri utama dalam matriks perhatian. Jaminan utama algoritma diberikan dalam Teorem 1. Subrutin yang menyepadukan anggaran pepenjuru
dan hasil matriks antara anggaran 
dan matriks nilai V. Oleh itu, para penyelidik memperkenalkan HyperAttention, algoritma yang cekap yang boleh menganggarkan mekanisme perhatian dengan jaminan spektrum dalam formula (1) dalam masa yang lebih kurang linear. Algoritma 3 mengambil sebagai input mask MH yang mentakrifkan kedudukan kemasukan dominan dalam matriks perhatian. Topeng ini boleh dijana menggunakan algoritma sortLSH (Algoritma 1) atau boleh menjadi topeng yang telah ditetapkan, serupa dengan pendekatan dalam [7]. Kami mengandaikan bahawa topeng kemasukan besar M^H adalah jarang mengikut reka bentuk dan bilangan penyertaan bukan sifarnya adalah terhad
.
Seperti yang ditunjukkan dalam Rajah 2, kaedah ini berdasarkan pemerhatian penting. Perhatian bertopeng M^C⊙A boleh diuraikan kepada tiga matriks bukan sifar, setiap satunya adalah separuh saiz matriks perhatian asal. Blok A_21 sepenuhnya di bawah pepenjuru adalah perhatian terbuka. Oleh itu, kita boleh menganggarkan jumlah barisnya menggunakan Algoritma 2. 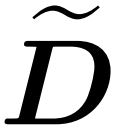 Dua bongkah pepenjuru
Dua bongkah pepenjuru 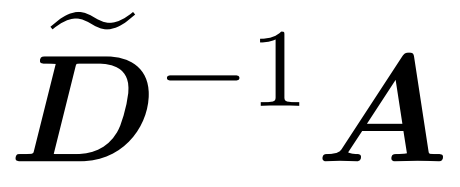 dan
dan 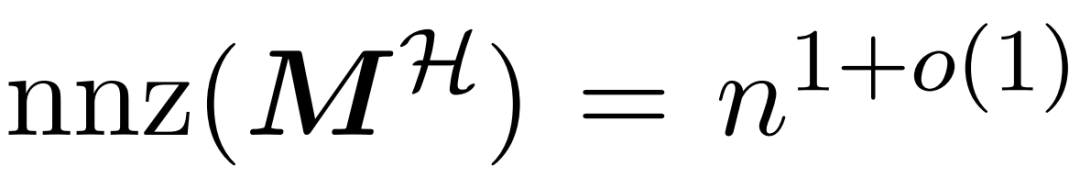 yang ditunjukkan dalam Rajah 2 ialah perhatian kausal, iaitu separuh daripada saiz asal. Untuk menangani hubungan kausal ini, para penyelidik menggunakan pendekatan rekursif, seterusnya membahagikannya kepada ketulan yang lebih kecil dan mengulangi proses tersebut. Pseudokod untuk proses ini diberikan dalam Algoritma 4.
yang ditunjukkan dalam Rajah 2 ialah perhatian kausal, iaitu separuh daripada saiz asal. Untuk menangani hubungan kausal ini, para penyelidik menggunakan pendekatan rekursif, seterusnya membahagikannya kepada ketulan yang lebih kecil dan mengulangi proses tersebut. Pseudokod untuk proses ini diberikan dalam Algoritma 4.
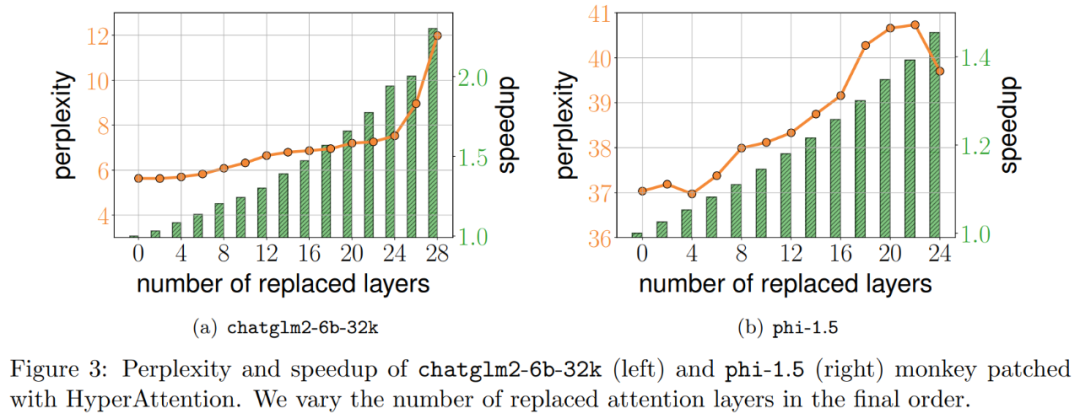
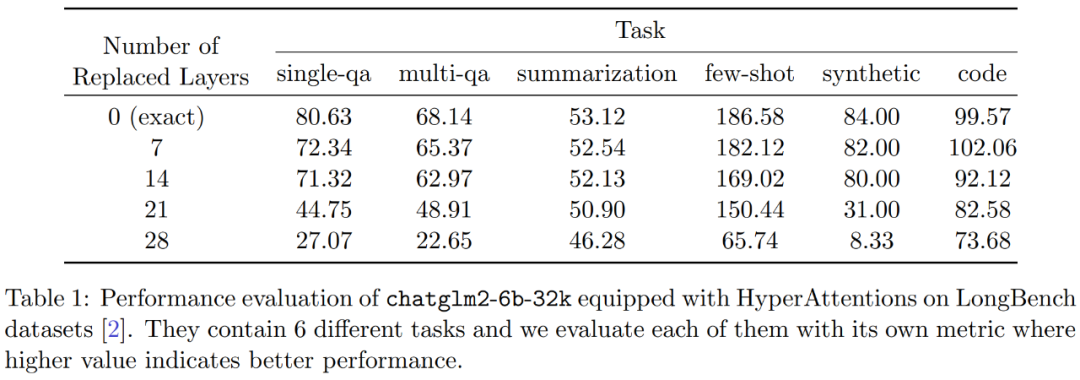
Eksperimen dan keputusan Untuk mengekalkan makna asal tidak berubah, kandungan perlu ditulis semula ke dalam bahasa Cina, dan ayat asal tidak perlu muncul Para penyelidik pertama kali menilai HyperAttention pada dua LLM yang telah dilatih, dan memilih model yang digunakan secara meluas dalam aplikasi praktikal Dua model dengan seni bina yang berbeza: chatglm2-6b-32k dan phi-1.5. Dalam operasi, mereka menampal lapisan perhatian ℓ terakhir dengan menggantikannya dengan HyperAttention, di mana bilangan ℓ boleh berbeza-beza daripada 0 hingga jumlah bilangan semua lapisan perhatian dalam setiap LLM. Ambil perhatian bahawa perhatian dalam kedua-dua model memerlukan topeng sebab, dan Algoritma 4 digunakan secara rekursif sehingga panjang jujukan input n kurang daripada 4,096. Untuk semua panjang jujukan, kami menetapkan saiz baldi b dan bilangan lajur sampel m kepada 256. Mereka menilai prestasi model tampalan monyet tersebut dari segi kebingungan dan pecutan. Pada masa yang sama, penyelidik menggunakan LongBench, koleksi set data penanda aras konteks panjang, yang mengandungi 6 tugasan berbeza, iaitu menjawab soalan tunggal/berbilang dokumen, rumusan, pembelajaran sampel kecil, tugasan sintesis dan penyelesaian kod. Mereka memilih subset set data dengan panjang jujukan pengekodan lebih daripada 32,768 dan memangkasnya jika panjangnya melebihi 32,768. Kemudian hitung kebingungan setiap model, iaitu kehilangan meramalkan token seterusnya. Untuk menyerlahkan kebolehskalaan untuk jujukan yang panjang, kami juga mengira jumlah kelajuan merentas semua lapisan perhatian, sama ada dilakukan oleh HyperAttention atau FlashAttention. Keputusan yang ditunjukkan dalam Rajah 3 di atas adalah seperti berikut Walaupun chatglm2-6b-32k telah melepasi patch monyet HyperAttention, ia masih menunjukkan tahap kekeliruan yang munasabah. Sebagai contoh, selepas menggantikan lapisan 20, kebingungan meningkat lebih kurang 1 dan terus meningkat secara perlahan sehingga mencapai lapisan 24. Masa jalan lapisan perhatian telah dipertingkatkan sebanyak kira-kira 50%. Jika semua lapisan diganti, kebingungan meningkat kepada 12 dan berjalan 2.3 kali lebih cepat. Model phi-1.5 juga menunjukkan situasi yang sama, tetapi apabila bilangan HyperAttention meningkat, kebingungan akan meningkat secara linear Selain itu, penyelidik juga menjalankan eksperimen ke atas monyet yang ditampal chatglm2-6b-32k pada Set data LongBench Penilaian prestasi telah dijalankan, dan markah penilaian untuk tugasan masing-masing seperti menjawab soalan tunggal/berbilang dokumen, rumusan, pembelajaran sampel kecil, tugasan sintesis dan penyelesaian kod telah dikira. Keputusan penilaian ditunjukkan dalam Jadual 1 di bawah Walaupun menggantikan HyperAttention biasanya menghasilkan penalti prestasi, mereka mendapati bahawa impaknya berbeza-beza berdasarkan tugas yang sedang dijalankan. Sebagai contoh, ringkasan dan penyiapan kod adalah yang paling kukuh berbanding tugasan lain. Perkara yang luar biasa ialah apabila separuh daripada lapisan perhatian (iaitu 14 lapisan) ditampal, para penyelidik mengesahkan bahawa penurunan prestasi untuk kebanyakan tugasan tidak akan melebihi 13%. Khususnya untuk tugasan ringkasan, prestasi kekal hampir tidak berubah, menunjukkan bahawa tugas ini adalah yang paling teguh kepada pengubahsuaian separa dalam mekanisme perhatian. Apabila n=32k, kelajuan pengiraan lapisan perhatian meningkat sebanyak 1.5 kali. Lapisan perhatian diri tunggal Para penyelidik meneroka lebih lanjut pecutan HyperAttention apabila panjang jujukan berbeza dari 4,096 hingga 131,072. Mereka mengukur masa jam dinding operasi hadapan dan hadapan+belakang apabila dikira menggunakan FlashAttention atau dipercepatkan oleh HyperAttention. Masa jam dinding dengan dan tanpa penutup sebab turut diukur. Semua input Q, K, dan V adalah sama panjang, dimensi ditetapkan kepada d = 64, dan bilangan kepala perhatian ialah 12. Mereka memilih parameter yang sama seperti sebelumnya dalam HyperAttention. Seperti yang ditunjukkan dalam Rajah 4, apabila topeng penyebab tidak digunakan, kelajuan HyperAttention meningkat sebanyak 54 kali, dan dengan topeng penyebab, kelajuan meningkat sebanyak 5.4 kali. Walaupun kebingungan temporal masking kausal dan bukan masking adalah sama, algoritma sebenar masking kausal (Algoritma 1) memerlukan operasi tambahan seperti membahagikan Q, K dan V, menggabungkan output perhatian, mengakibatkan peningkatan dalam masa jalan sebenar . Apabila panjang jujukan n bertambah, pecutan akan lebih tinggi Para penyelidik percaya bahawa keputusan ini bukan sahaja boleh digunakan untuk inferens, tetapi juga boleh digunakan untuk melatih atau memperhalusi LLM untuk menyesuaikan diri dengan jujukan yang lebih panjang, yang membuka pengembangan perhatian diri Kemungkinan baru  Para penyelidik melanjutkan model bahasa besar sedia ada untuk memproses jujukan jarak jauh dan kemudian menanda aras algoritma. Semua percubaan dijalankan pada satu GPU A100 40GB dan menggunakan FlashAttention 2 untuk pengiraan perhatian yang tepat.
Para penyelidik melanjutkan model bahasa besar sedia ada untuk memproses jujukan jarak jauh dan kemudian menanda aras algoritma. Semua percubaan dijalankan pada satu GPU A100 40GB dan menggunakan FlashAttention 2 untuk pengiraan perhatian yang tepat. 
Atas ialah kandungan terperinci Mekanisme perhatian anggaran baharu HyperAttention: mesra kepada konteks yang panjang, mempercepatkan inferens LLM sebanyak 50%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



