



Berita pada 10 November, peningkatan pesat model bahasa besar (LLM) menunjukkan prospek cerah dalam penjanaan dan pemahaman bahasa, dan pengaruhnya melangkaui bidang bahasa dan meluas kepada logik, matematik, fizik dan bidang lain.
Namun, jika anda ingin membuka kunci "tenaga luar biasa" ini, anda perlu membayar harga yang tinggi Contohnya, melatih model 540B memerlukan 6144 Cip TPUv4 Projek PaLM ;
Penyelesaian yang baik adalah dengan melakukan latihan ketepatan rendah, yang boleh meningkatkan kelajuan pemprosesan dan mengurangkan penggunaan memori dan kos komunikasi. Sistem latihan arus perdana semasa termasuk Megatron-LM, MetaSeq dan Colossal-AI, yang menggunakan ketepatan campuran FP16/BF16 atau ketepatan penuh FP32 secara lalai untuk melatih model bahasa besar
Walaupun tahap ketepatan ini tidak sesuai untuk model bahasa yang besar adalah penting, tetapi ia mahal dari segi pengiraan.
Jika anda menggunakan ketepatan rendah FP8, anda boleh meningkatkan kelajuan sebanyak 2 kali ganda, mengurangkan kos memori sebanyak 50% hingga 75%, dan menjimatkan kos komunikasi.
Pada masa ini hanya Enjin Transformer Nvidia yang serasi dengan rangka kerja FP8, terutamanya memanfaatkan ketepatan ini untuk pengiraan GEMM (pendaraban matriks am) sambil mengekalkan berat dan kecerunan induk pada ketepatan tinggi FP16 atau FP32.
Untuk menangani cabaran ini, pasukan penyelidik dari Microsoft Azure dan Microsoft Research memperkenalkan rangka kerja ketepatan campuran FP8 yang cekap yang disesuaikan untuk latihan model bahasa yang besar.
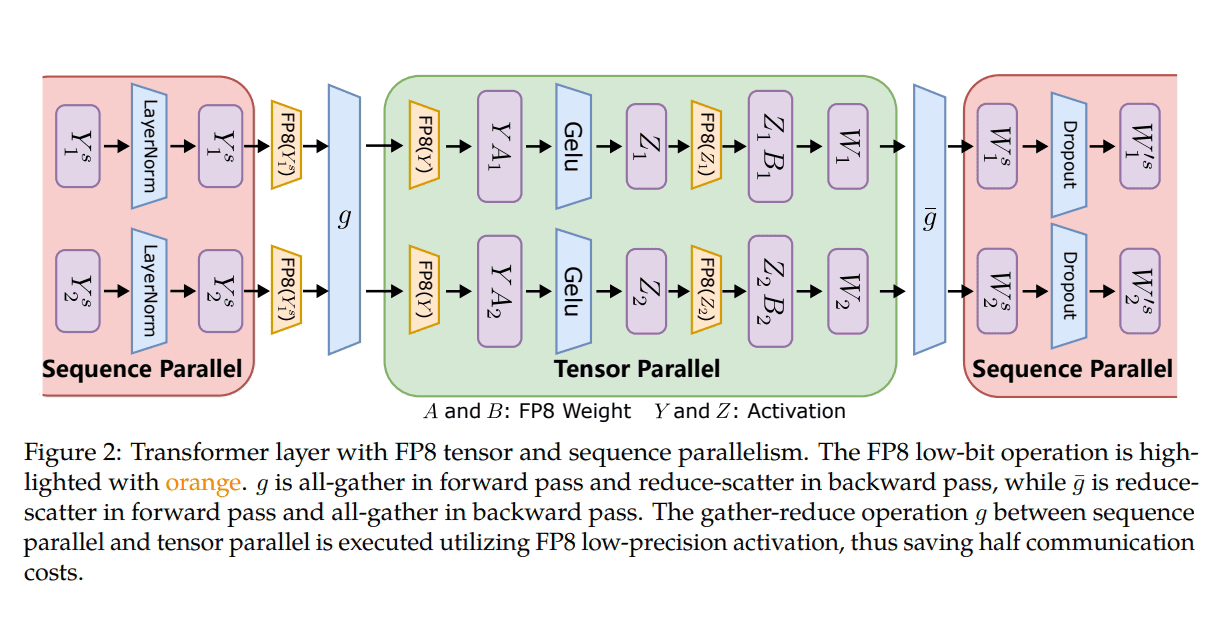
Microsoft telah memperkenalkan tiga peringkat pengoptimuman untuk memanfaatkan FP8 untuk latihan ketepatan teragih dan campuran. Apabila tahap ini berkembang, peningkatan integrasi FP8 menjadi jelas, mencadangkan kesan yang lebih besar pada proses latihan LLM.
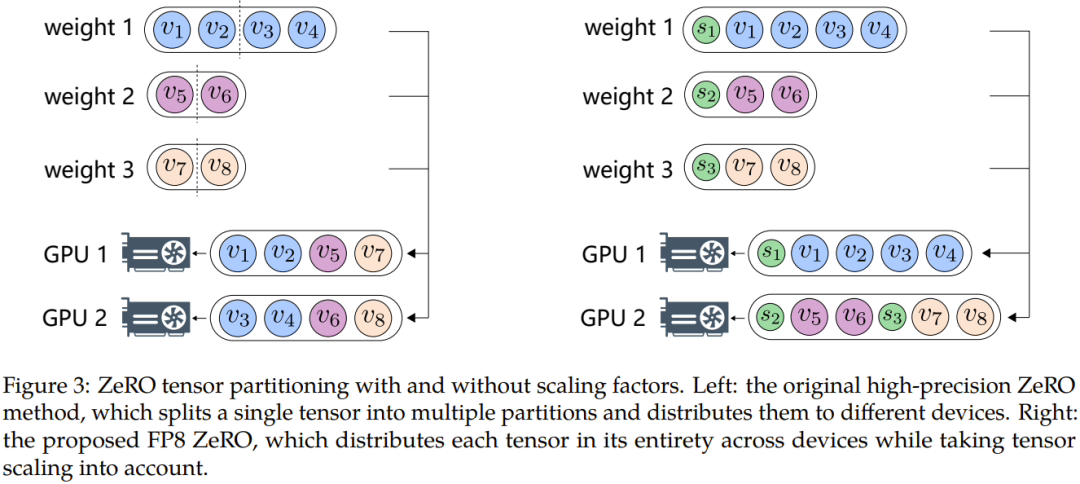
Selain itu, untuk mengatasi masalah seperti limpahan data atau aliran bawah, penyelidik Microsoft mencadangkan dua kaedah utama: pensampelan automatik dan penyahgandingan tepat yang pertama melibatkan komponen yang tidak sensitif kepada ketepatan, mengurangkan ketepatan dan melaraskan faktor pensampelan Tensor secara dinamik, untuk memastikan nilai kecerunan kekal dalam julat perwakilan FP8. Ini menghalang kejadian limpahan dan limpahan semasa komunikasi, memastikan proses latihan yang lebih lancar.
Microsoft telah menguji bahawa berbanding dengan kaedah ketepatan campuran BF16 yang diterima pakai secara meluas, penggunaan memori dikurangkan sebanyak 27% hingga 42%, overhed komunikasi kecerunan berat dikurangkan dengan ketara sebanyak 63 % hingga 65 %. Berjalan 64% lebih pantas daripada rangka kerja BF16 yang diterima pakai secara meluas seperti Megatron-LM dan 17% lebih pantas daripada Enjin Transformer Nvidia.
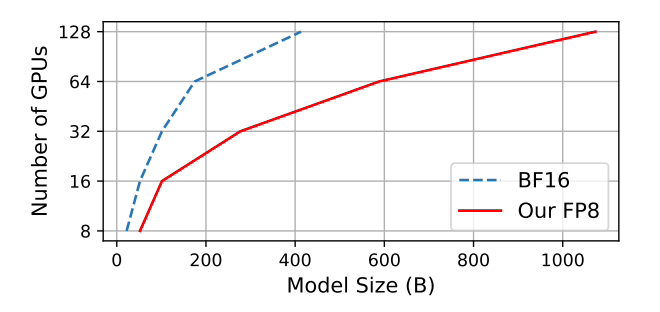
Apabila melatih model GPT-175B, rangka kerja ketepatan FP8 hibrid menjimatkan 21% memori pada platform GPU H100, dan dibandingkan dengan TE (Transformer Enjin ), masa latihan dikurangkan sebanyak 17%.
Laman ini melampirkan di sini alamat GitHub dan alamat tesis: //m.sbmmt.com/link/7b3564b05f984b05f984b05f984b6f9d78 🎜#
Atas ialah kandungan terperinci Microsoft melancarkan rangka kerja latihan ketepatan campuran baharu FP8: 64% lebih pantas daripada BF16 dan 42% lebih kecil dalam penggunaan memori. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
 javac tidak diiktiraf sebagai arahan dalaman atau luaran atau program yang boleh dikendalikan Bagaimana untuk menyelesaikan masalah?
javac tidak diiktiraf sebagai arahan dalaman atau luaran atau program yang boleh dikendalikan Bagaimana untuk menyelesaikan masalah?
 Bagaimanakah cara saya menyediakan WeChat untuk memerlukan persetujuan saya apabila orang menambahkan saya ke kumpulan?
Bagaimanakah cara saya menyediakan WeChat untuk memerlukan persetujuan saya apabila orang menambahkan saya ke kumpulan?
 Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
 Bagaimana untuk menulis kod kotak teks html
Bagaimana untuk menulis kod kotak teks html
 Platform dagangan pukal
Platform dagangan pukal
 Apakah perbezaan antara rangka kerja css dan perpustakaan komponen
Apakah perbezaan antara rangka kerja css dan perpustakaan komponen
 Bagaimana untuk membuang tera air pada TikTok
Bagaimana untuk membuang tera air pada TikTok








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



