


Cipta saluran data pembelajaran mendalam yang cekap dengan Ray

GPU yang diperlukan untuk latihan model pembelajaran mendalam adalah berkuasa tetapi mahal. Untuk menggunakan GPU sepenuhnya, pembangun memerlukan saluran pemindahan data yang cekap yang boleh memindahkan data dengan cepat ke GPU apabila ia bersedia untuk mengira langkah latihan seterusnya. Menggunakan Ray boleh meningkatkan kecekapan saluran penghantaran data dengan ketara
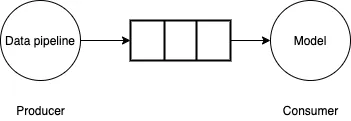
1 Struktur saluran paip data latihan
Pertama, mari kita lihat pseudokod latihan model
for step in range(num_steps):sample, target = next(dataset) # 步骤1train_step(sample, target) # 步骤2
Dalam langkah 1, dapatkan sampel dan label bagi kumpulan mini seterusnya. Dalam langkah 2, ia dihantar ke fungsi train_step, yang menyalinnya ke GPU, melakukan hantaran ke hadapan dan ke belakang untuk mengira kehilangan dan kecerunan serta mengemas kini berat pengoptimum.
Sila ketahui lebih lanjut tentang langkah 1. Apabila set data terlalu besar untuk dimuatkan dalam memori, langkah 1 akan mengambil kumpulan mini seterusnya daripada cakera atau rangkaian. Di samping itu, langkah 1 juga termasuk sejumlah prapemprosesan tertentu. Data input mesti ditukar kepada tensor berangka atau koleksi tensor sebelum disalurkan kepada model. Dalam sesetengah kes, transformasi lain juga dilakukan pada tensor sebelum dihantar kepada model, seperti normalisasi, putaran di sekeliling paksi, shuffling rawak, dsb.
Jika aliran kerja dilaksanakan mengikut urutan, iaitu, langkah 1 ialah dilakukan dahulu , dan kemudian laksanakan langkah 2, maka model akan sentiasa menunggu untuk input, output dan operasi prapemprosesan kumpulan data seterusnya. GPU tidak akan digunakan dengan cekap, ia akan terbiar semasa memuatkan kumpulan mini data seterusnya.
Untuk menyelesaikan masalah ini, saluran paip data boleh dilihat sebagai masalah pengeluar-pengguna. Saluran paip data menjana kumpulan kecil data dan menulisnya ke penimbal terhad. Model/GPU menggunakan kumpulan mini data daripada penimbal, melakukan pengiraan ke hadapan/terbalik dan mengemas kini berat model. Jika saluran paip data boleh menjana kumpulan kecil data secepat model/GPU menggunakannya, proses latihan akan menjadi sangat cekap.
 Pictures
Pictures
2. Tensorflow tf.data API
Tensorflow tf.data API menyediakan set ciri yang kaya yang boleh digunakan untuk mencipta saluran data dengan cekap, menggunakan benang latar untuk mendapatkan kumpulan kecil data, supaya model tidak perlu menunggu. Pra-mengambil data tidak mencukupi Jika menjana kumpulan kecil data adalah lebih perlahan daripada GPU boleh menggunakan data, maka anda perlu menggunakan penyejajaran untuk mempercepatkan bacaan dan transformasi data. Untuk tujuan ini, Tensorflow menyediakan fungsi interleave untuk memanfaatkan berbilang thread untuk membaca data secara selari dan fungsi pemetaan selari untuk menggunakan berbilang thread untuk mengubah kumpulan kecil data.
Memandangkan API ini berdasarkan berbilang benang, ia mungkin dihadkan oleh Python Global Interpreter Lock (GIL). GIL Python mengehadkan bytecode kepada hanya satu utas yang berjalan pada satu masa. Jika anda menggunakan kod TensorFlow tulen dalam saluran paip anda, anda biasanya tidak mengalami had ini kerana enjin pelaksanaan teras TensorFlow berfungsi di luar skop GIL. Walau bagaimanapun, jika pustaka pihak ketiga yang digunakan tidak membatalkan sekatan GIL atau menggunakan Python untuk melakukan sejumlah besar pengiraan, maka bergantung pada multi-benang untuk menyelaraskan saluran paip adalah tidak boleh dilaksanakan
3 saluran paip
Pertimbangkan fungsi penjana berikut, yang Fungsi ini mensimulasikan pemuatan dan melakukan beberapa pengiraan untuk menjana kumpulan mini sampel data dan label.
def data_generator():for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000):passyield (np.random.random((4, 1000000, 3)).astype(np.float32), np.random.random((4, 1)).astype(np.float32))
Seterusnya, gunakan penjana dalam saluran paip latihan palsu dan ukur purata masa yang diperlukan untuk menjana kumpulan mini data.
generator_dataset = tf.data.Dataset.from_generator(data_generator,output_types=(tf.float64, tf.float64),output_shapes=((4, 1000000, 3), (4, 1))).prefetch(tf.data.experimental.AUTOTUNE)st = time.perf_counter()times = []for _ in generator_dataset:en = time.perf_counter()times.append(en - st)# 模拟训练步骤time.sleep(0.1)st = time.perf_counter()print(np.mean(times))
Diperhatikan bahawa purata masa yang diambil adalah sekitar 0.57 saat (diukur pada komputer riba Mac dengan pemproses Intel Core i7). Jika ini adalah gelung latihan sebenar, penggunaan GPU akan menjadi agak rendah, ia hanya akan menghabiskan 0.1 saat melakukan pengiraan dan kemudian melahu selama 0.57 saat menunggu kumpulan data seterusnya.
Untuk mempercepatkan pemuatan data, anda boleh menggunakan penjana berbilang proses.
from multiprocessing import Queue, cpu_count, Processdef mp_data_generator():def producer(q):for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000000):passq.put((np.random.random((4, 1000000, 3)).astype(np.float32),np.random.random((4, 1)).astype(np.float32)))q.put("DONE")queue = Queue(cpu_count()*2)num_parallel_processes = cpu_count()producers = []for _ in range(num_parallel_processes):p = Process(target=producer, args=(queue,))p.start()producers.append(p)done_counts = 0while done_counts <p>Kini, jika kita mengukur masa yang dihabiskan untuk menunggu kumpulan mini data seterusnya, kita mendapat masa purata 0.08 saat. Itu hampir 7x kelajuan, tetapi idealnya mahu kali ini hampir kepada 0. </p><p>Jika anda menganalisisnya, anda boleh mendapati bahawa banyak masa dihabiskan untuk menyediakan penyahserialisasian data. Dalam penjana berbilang proses, proses pengeluar mengembalikan tatasusunan NumPy yang besar, yang perlu disediakan dan kemudian dinyahsiri dalam proses utama. Jadi bagaimana untuk meningkatkan kecekapan apabila menghantar tatasusunan besar antara proses? </p><h2>4 Gunakan Ray untuk menyelaraskan saluran paip data</h2><p>Di sinilah Ray memainkan peranan. Ray ialah rangka kerja untuk menjalankan pengkomputeran teragih dalam Python. Ia datang dengan stor objek memori kongsi untuk memindahkan objek dengan cekap antara proses yang berbeza. Khususnya, tatasusunan Numpy dalam stor objek boleh dikongsi antara pekerja pada nod yang sama tanpa sebarang pensirilan dan penyahsirilan. Ray juga memudahkan untuk menskalakan pemuatan data merentas berbilang mesin dan menggunakan Apache Arrow untuk mensiri dan menyahsiri tatasusunan besar dengan cekap. </p><p>Ray datang dengan fungsi utiliti from_iterators yang boleh mencipta iterator selari, dan pembangun boleh menggunakannya untuk membalut fungsi penjana data_generator. </p><pre class="brush:php;toolbar:false">import raydef ray_generator():num_parallel_processes = cpu_count()return ray.util.iter.from_iterators([data_generator]*num_parallel_processes).gather_async()Menggunakan ray_generator, masa yang dihabiskan untuk menunggu kumpulan mini data seterusnya diukur menjadi 0.02 saat, iaitu 4 kali lebih pantas daripada menggunakan pemprosesan berbilang proses.
Atas ialah kandungan terperinci Cipta saluran data pembelajaran mendalam yang cekap dengan Ray. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1795
1795
 16
1740
56
1592
29
1475
72
267
587
16
1740
56
1592
29
1475
72
267
587

 Analisis fungsi pengaktifan AI yang biasa digunakan: amalan pembelajaran mendalam Sigmoid, Tanh, ReLU dan Softmax
Dec 28, 2023 pm 11:35 PM
Analisis fungsi pengaktifan AI yang biasa digunakan: amalan pembelajaran mendalam Sigmoid, Tanh, ReLU dan Softmax
Dec 28, 2023 pm 11:35 PM
Fungsi pengaktifan memainkan peranan penting dalam pembelajaran mendalam Ia boleh memperkenalkan ciri tak linear ke dalam rangkaian saraf, membolehkan rangkaian belajar dengan lebih baik dan mensimulasikan hubungan input-output yang kompleks. Pemilihan dan penggunaan fungsi pengaktifan yang betul mempunyai kesan penting terhadap prestasi dan hasil latihan rangkaian saraf Artikel ini akan memperkenalkan empat fungsi pengaktifan yang biasa digunakan: Sigmoid, Tanh, ReLU dan Softmax, bermula dari pengenalan, senario penggunaan, kelebihan, kelemahan dan penyelesaian pengoptimuman Dimensi dibincangkan untuk memberi anda pemahaman yang menyeluruh tentang fungsi pengaktifan. 1. Fungsi Sigmoid Pengenalan kepada formula fungsi SIgmoid: Fungsi Sigmoid ialah fungsi tak linear yang biasa digunakan yang boleh memetakan sebarang nombor nyata antara 0 dan 1. Ia biasanya digunakan untuk menyatukan
 Di luar ORB-SLAM3! SL-SLAM: Adegan bertekstur lemah ringan, kegelisahan teruk dan lemah semuanya dikendalikan
May 30, 2024 am 09:35 AM
Di luar ORB-SLAM3! SL-SLAM: Adegan bertekstur lemah ringan, kegelisahan teruk dan lemah semuanya dikendalikan
May 30, 2024 am 09:35 AM
Ditulis sebelum ini, hari ini kita membincangkan bagaimana teknologi pembelajaran mendalam boleh meningkatkan prestasi SLAM berasaskan penglihatan (penyetempatan dan pemetaan serentak) dalam persekitaran yang kompleks. Dengan menggabungkan kaedah pengekstrakan ciri dalam dan pemadanan kedalaman, di sini kami memperkenalkan sistem SLAM visual hibrid serba boleh yang direka untuk meningkatkan penyesuaian dalam senario yang mencabar seperti keadaan cahaya malap, pencahayaan dinamik, kawasan bertekstur lemah dan seks yang teruk. Sistem kami menyokong berbilang mod, termasuk konfigurasi monokular, stereo, monokular-inersia dan stereo-inersia lanjutan. Selain itu, ia juga menganalisis cara menggabungkan SLAM visual dengan kaedah pembelajaran mendalam untuk memberi inspirasi kepada penyelidikan lain. Melalui percubaan yang meluas pada set data awam dan data sampel sendiri, kami menunjukkan keunggulan SL-SLAM dari segi ketepatan kedudukan dan keteguhan penjejakan.
 Pembenaman ruang terpendam: penjelasan dan demonstrasi
Jan 22, 2024 pm 05:30 PM
Pembenaman ruang terpendam: penjelasan dan demonstrasi
Jan 22, 2024 pm 05:30 PM
Pembenaman Ruang Terpendam (LatentSpaceEmbedding) ialah proses memetakan data berdimensi tinggi kepada ruang berdimensi rendah. Dalam bidang pembelajaran mesin dan pembelajaran mendalam, pembenaman ruang terpendam biasanya merupakan model rangkaian saraf yang memetakan data input berdimensi tinggi ke dalam set perwakilan vektor berdimensi rendah ini sering dipanggil "vektor terpendam" atau "terpendam pengekodan". Tujuan pembenaman ruang terpendam adalah untuk menangkap ciri penting dalam data dan mewakilinya ke dalam bentuk yang lebih ringkas dan mudah difahami. Melalui pembenaman ruang terpendam, kami boleh melakukan operasi seperti memvisualisasikan, mengelaskan dan mengelompokkan data dalam ruang dimensi rendah untuk memahami dan menggunakan data dengan lebih baik. Pembenaman ruang terpendam mempunyai aplikasi yang luas dalam banyak bidang, seperti penjanaan imej, pengekstrakan ciri, pengurangan dimensi, dsb. Pembenaman ruang terpendam adalah yang utama
 Kaedah dan langkah untuk menggunakan BERT untuk analisis sentimen dalam Python
Jan 22, 2024 pm 04:24 PM
Kaedah dan langkah untuk menggunakan BERT untuk analisis sentimen dalam Python
Jan 22, 2024 pm 04:24 PM
BERT ialah model bahasa pembelajaran mendalam pra-latihan yang dicadangkan oleh Google pada 2018. Nama penuh ialah BidirectionalEncoderRepresentationsfromTransformers, yang berdasarkan seni bina Transformer dan mempunyai ciri pengekodan dwiarah. Berbanding dengan model pengekodan sehala tradisional, BERT boleh mempertimbangkan maklumat kontekstual pada masa yang sama semasa memproses teks, jadi ia berfungsi dengan baik dalam tugas pemprosesan bahasa semula jadi. Dwiarahnya membolehkan BERT memahami dengan lebih baik hubungan semantik dalam ayat, dengan itu meningkatkan keupayaan ekspresif model. Melalui kaedah pra-latihan dan penalaan halus, BERT boleh digunakan untuk pelbagai tugas pemprosesan bahasa semula jadi, seperti analisis sentimen, penamaan.
 Fahami dalam satu artikel: kaitan dan perbezaan antara AI, pembelajaran mesin dan pembelajaran mendalam
Mar 02, 2024 am 11:19 AM
Fahami dalam satu artikel: kaitan dan perbezaan antara AI, pembelajaran mesin dan pembelajaran mendalam
Mar 02, 2024 am 11:19 AM
Dalam gelombang perubahan teknologi yang pesat hari ini, Kecerdasan Buatan (AI), Pembelajaran Mesin (ML) dan Pembelajaran Dalam (DL) adalah seperti bintang terang, menerajui gelombang baharu teknologi maklumat. Ketiga-tiga perkataan ini sering muncul dalam pelbagai perbincangan dan aplikasi praktikal yang canggih, tetapi bagi kebanyakan peneroka yang baru dalam bidang ini, makna khusus dan hubungan dalaman mereka mungkin masih diselubungi misteri. Jadi mari kita lihat gambar ini dahulu. Dapat dilihat bahawa terdapat korelasi rapat dan hubungan progresif antara pembelajaran mendalam, pembelajaran mesin dan kecerdasan buatan. Pembelajaran mendalam ialah bidang khusus pembelajaran mesin dan pembelajaran mesin
 Super kuat! 10 algoritma pembelajaran mendalam teratas!
Mar 15, 2024 pm 03:46 PM
Super kuat! 10 algoritma pembelajaran mendalam teratas!
Mar 15, 2024 pm 03:46 PM
Hampir 20 tahun telah berlalu sejak konsep pembelajaran mendalam dicadangkan pada tahun 2006. Pembelajaran mendalam, sebagai revolusi dalam bidang kecerdasan buatan, telah melahirkan banyak algoritma yang berpengaruh. Jadi, pada pendapat anda, apakah 10 algoritma teratas untuk pembelajaran mendalam? Berikut adalah algoritma teratas untuk pembelajaran mendalam pada pendapat saya Mereka semua menduduki kedudukan penting dari segi inovasi, nilai aplikasi dan pengaruh. 1. Latar belakang rangkaian saraf dalam (DNN): Rangkaian saraf dalam (DNN), juga dipanggil perceptron berbilang lapisan, adalah algoritma pembelajaran mendalam yang paling biasa Apabila ia mula-mula dicipta, ia dipersoalkan kerana kesesakan kuasa pengkomputeran tahun, kuasa pengkomputeran, Kejayaan datang dengan letupan data. DNN ialah model rangkaian saraf yang mengandungi berbilang lapisan tersembunyi. Dalam model ini, setiap lapisan menghantar input ke lapisan seterusnya dan
 Daripada asas kepada amalan, semak sejarah pembangunan pengambilan vektor Elasticsearch
Oct 23, 2023 pm 05:17 PM
Daripada asas kepada amalan, semak sejarah pembangunan pengambilan vektor Elasticsearch
Oct 23, 2023 pm 05:17 PM
1. Pengenalan Pengambilan semula vektor telah menjadi komponen teras sistem carian dan pengesyoran moden. Ia membolehkan pemadanan pertanyaan dan pengesyoran yang cekap dengan menukar objek kompleks (seperti teks, imej atau bunyi) kepada vektor berangka dan melakukan carian persamaan dalam ruang berbilang dimensi. Daripada asas kepada amalan, semak semula sejarah pembangunan vektor retrieval_elasticsearch Elasticsearch Sebagai enjin carian sumber terbuka yang popular, pembangunan Elasticsearch dalam pengambilan vektor sentiasa menarik perhatian ramai. Artikel ini akan menyemak sejarah pembangunan pengambilan vektor Elasticsearch, memfokuskan pada ciri dan kemajuan setiap peringkat. Mengambil sejarah sebagai panduan, adalah mudah untuk semua orang mewujudkan rangkaian penuh pengambilan vektor Elasticsearch.
 Rangka kerja pembelajaran mendalam TensorFlow talian paip inferens untuk inferens potongan potret
Mar 26, 2024 pm 01:00 PM
Rangka kerja pembelajaran mendalam TensorFlow talian paip inferens untuk inferens potongan potret
Mar 26, 2024 pm 01:00 PM
Gambaran Keseluruhan Untuk membolehkan pengguna ModelScope menggunakan pelbagai model yang disediakan oleh platform dengan cepat dan mudah, satu set perpustakaan Python berfungsi sepenuhnya disediakan, yang termasuk pelaksanaan model rasmi ModelScope, serta alatan yang diperlukan untuk menggunakan model ini untuk inferens. , finetune dan tugas-tugas lain yang berkaitan dengan pra-pemprosesan data, pasca-pemprosesan, penilaian kesan dan fungsi lain, sambil turut menyediakan API yang ringkas dan mudah digunakan serta contoh penggunaan yang kaya. Dengan menghubungi perpustakaan, pengguna boleh menyelesaikan tugas seperti inferens model, latihan dan penilaian dengan menulis hanya beberapa baris kod Mereka juga boleh melakukan pembangunan sekunder dengan cepat atas dasar ini untuk merealisasikan idea inovatif mereka sendiri. Model algoritma yang disediakan oleh perpustakaan pada masa ini ialah:
