


Penulis: Ye Xiaofei
Pautan: https://www.zhihu.com/question/2697072281/answer/369707281/answer 🎜 🎜#
Saya boleh melatih lebih daripada seratus model berbeza dalam seminggu Untuk tujuan ini, saya menggabungkan syarikat Amalan pendahulu kami dan beberapa pemikiran kami sendiri meringkaskan satu set kaedah pengurusan eksperimen kod yang cekap, yang berjaya membantu projek itu dilaksanakan sekarang kami berkongsi dengan anda di sini .
Gunakan fail Yaml untuk mengkonfigurasi parameter latihanSaya tahu bahawa banyak repo sumber terbuka suka menggunakan input argparse untuk menghantar banyak latihan dan parameter berkaitan model, yang sebenarnya sangat tidak cekap. Di satu pihak, ia akan menyusahkan untuk memasukkan sejumlah besar parameter secara manual setiap kali anda berlatih Jika anda terus menukar nilai lalai dan kemudian pergi ke kod untuk menukarnya, ia akan membuang banyak masa. Di sini saya mengesyorkan agar anda terusmenggunakan fail Yaml untuk mengawal semua model dan parameter berkaitan latihan, dan memautkan penamaan yaml dengan nama model dan cap masa , perpustakaan pengesanan awan titik 3d yang terkenal OpenPCDet That's bagaimana ia dilakukan, seperti yang ditunjukkan dalam pautan ini di bawah.
github.com/open-mmlab/OpenPCDet/blob/master/tools/cfgs/kitti_models/pointrcnn.yamlSaya memotong fail yaml daripada pautan yang diberikan di atas Bahagian daripada kandungan, seperti yang ditunjukkan dalam rajah di bawah, fail konfigurasi ini merangkumi cara pramemproses awan titik, jenis klasifikasi, serta pelbagai parameter tulang belakang, pengoptimum dan pemilihan kehilangan (tidak ditunjukkan dalam rajah, sila lihat pautan di atas untuk lengkap). Dalam erti kata lain,Pada asasnya semua faktor yang boleh mempengaruhi model anda disertakan dalam fail ini, dan dalam kod, anda hanya perlu menggunakan yaml.load() yang mudah Baca semua parameter ini ke dalam dict. Lebih penting lagi, fail konfigurasi ini boleh disimpan ke folder yang sama seperti pusat pemeriksaan anda, supaya anda boleh menggunakannya secara langsung untuk latihan titik putus, finetune atau ujian langsung Apabila digunakan untuk ujian, anda juga boleh Ia mudah dipadankan keputusan dengan parameter yang sepadan.

Ia membolehkan anda untuk tidak menentukan model atau sub-model yang hendak digunakan semasa latihan dalam kod, tetapi boleh ditakrifkan secara langsung dalam yaml.
Tensorboard, tqdm digunakan Saya pada asasnya menggunakan kedua-dua perpustakaan ini setiap kali. Tensorboard boleh menjejaki perubahan dalam lengkung kehilangan latihan anda dengan baik, menjadikannya lebih mudah untuk anda menilai sama ada model masih menumpu dan terlalu pasang Jika anda melakukan kerja berkaitan imej, anda juga boleh meletakkan beberapa hasil visualisasi padanya. Banyak kali anda hanya perlu melihat status penumpuan papan tensor untuk mengetahui prestasi model anda Adakah anda perlu meluangkan masa untuk menguji dan memperhalusinya secara berasingan Tqdm boleh membantu anda menjejaki kemajuan latihan anda secara intuitif, menjadikannya lebih mudah untuk anda berhenti awal.Gunakan sepenuhnya GithubSama ada anda sedang membangunkan bersama berbilang orang atau bekerja dalam projek solo, saya amat mengesyorkan menggunakan Github (syarikat mungkin menggunakan bitbucket, lebih kurang) untuk merekodkan kod anda . Untuk butiran, sila rujuk jawapan saya: Sebagai pelajar siswazah, apakah alat penyelidikan saintifik yang anda fikir berguna?https://www.zhihu.com/question/484596211/answer/2163122684
Pautan: https://www.zhihu.com/question/21970722 /470576066
Sebaliknya, selepas menguji beribu-ribu versi, saya percaya anda tidak akan tahu model mana yang mempunyai tabiat baik yang sangat berkesan. Di samping itu, cuba berikan nilai lalai untuk parameter yang baru ditambah untuk memudahkan panggilan versi lama fail konfigurasi.
Dalam projek yang sama, kebolehgunaan semula yang baik adalah tabiat pengaturcaraan yang sangat baik, tetapi dalam pengekodan DL yang berkembang pesat, diandaikan bahawa projek itu didorong oleh tugas Ya, ini kadangkala menjadi. halangan, jadi cuba untuk mengekstrak beberapa fungsi boleh guna semula Mengenai struktur model, cuba untuk memisahkan model yang berbeza ke dalam fail yang berbeza, yang akan membuat kemas kini masa depan lebih mudah. Jika tidak, beberapa reka bentuk yang kelihatan cantik akan menjadi tidak berguna selepas beberapa bulan.
Selalunya terdapat situasi yang memalukan Dari awal hingga akhir sesuatu projek, rangka kerja telah dikemas kini kepada beberapa versi, dan versi baharu mempunyai beberapa ciri yang menarik, tetapi malangnya beberapa API telah berubah. Oleh itu, anda boleh cuba memastikan versi rangka kerja stabil dalam projek. Cuba pertimbangkan kebaikan dan keburukan versi yang berbeza sebelum memulakan projek Kadangkala pembelajaran yang betul diperlukan.
Selain itu, miliki hati yang bertolak ansur terhadap rangka kerja yang berbeza. .
Sumber: Zhihu
Hak cipta milik pengarang. Untuk pencetakan semula komersial, sila hubungi pengarang untuk mendapatkan kebenaran Untuk pencetakan semula bukan komersial, sila nyatakan sumbernya.
Helo, penyoal, jawapan sebelum ini menyebut penggunaan Tensorboard, Weights&Biases, MLFlow, Neptune dan alatan lain untuk mengurus data eksperimen. Walau bagaimanapun, apabila semakin banyak roda dibina untuk alat pengurusan eksperimen, kos pembelajaran alat itu semakin tinggi. Bagaimana kita harus memilih?
MMCV memenuhi semua fantasi anda, dan anda boleh menukar alatan dengan mengubah suai fail konfigurasi.
github.com/open-mmlab/mmcv
Papan tensor merekodkan data percubaan:log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
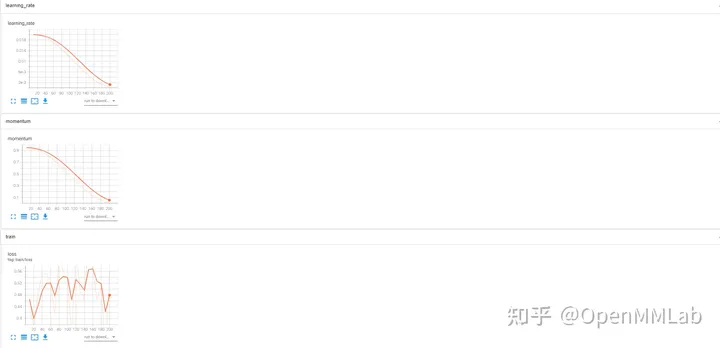
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='WandbLoggerHook') ])
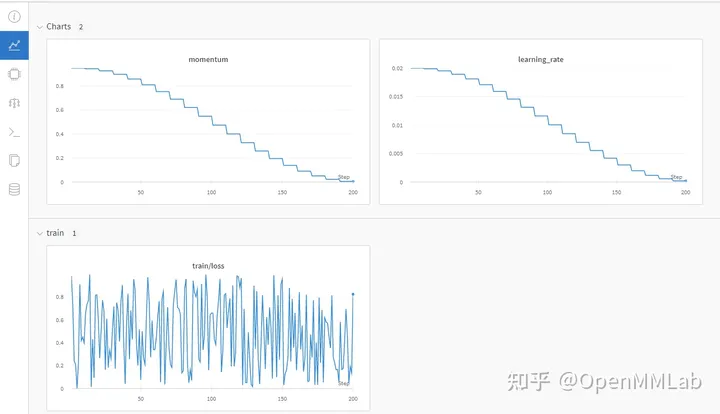 (anda perlu log masuk ke wandb dengan python api terlebih dahulu)
(anda perlu log masuk ke wandb dengan python api terlebih dahulu)
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='NeptuneLoggerHook', init_kwargs=dict(project='Your Neptume account/mmcv')) ])
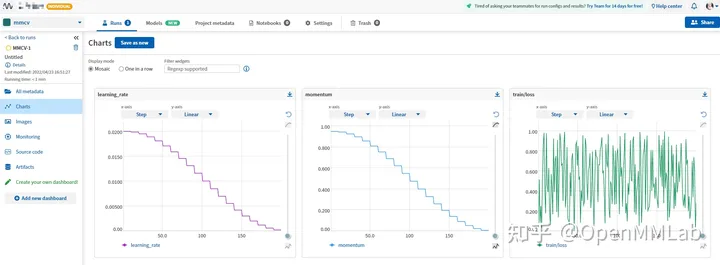 kesan visualisasi
kesan visualisasilog_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='MlflowLoggerHook') ])
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='DvcliveLoggerHook') ])
MLFlow visualisasi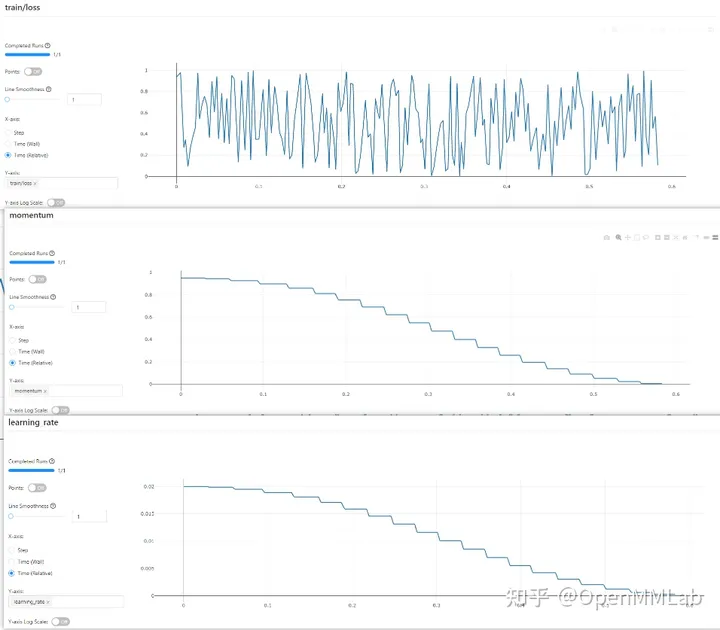
fail di atas🜜dijanakan🜎🜎 sahaja fungsi paling asas pelbagai alat pengurusan eksperimen , kita boleh Ubah suai profil lebih jauh untuk membuka lebih banyak pose. 
TextLoggerHook! Ia akan menyimpan semua maklumat yang dijana semasa proses latihan, seperti persekitaran peranti, set data, kaedah permulaan model, kehilangan, metrik dan maklumat lain yang dijana semasa latihan, ke fail xxx.log tempatan. Anda boleh menyemak data percubaan sebelumnya tanpa menggunakan sebarang alat. Masih tertanya-tanya alat pengurusan eksperimen yang manakah hendak digunakan? Masih bimbang tentang kos pembelajaran pelbagai alat? Cepat dan dapatkan MMCV, dan alami pelbagai alat tanpa rasa sakit dengan hanya beberapa baris fail konfigurasi.
github.com/open-mmlab/mmcvAtas ialah kandungan terperinci Dalam penyelidikan saintifik pembelajaran mendalam, bagaimana untuk mengurus kod dan eksperimen dengan cekap?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Cara membuat carta dan carta analisis data dalam PPT
Cara membuat carta dan carta analisis data dalam PPT
 Kaedah pelaksanaan fungsi main balik suara Android
Kaedah pelaksanaan fungsi main balik suara Android
 Penggunaan penyentuh AC
Penggunaan penyentuh AC
 Perbezaan antara vscode dan visual studio
Perbezaan antara vscode dan visual studio
 Perbezaan antara Java dan Java
Perbezaan antara Java dan Java
 Pengenalan kepada jenis antara muka cakera keras
Pengenalan kepada jenis antara muka cakera keras
 kaedah konfigurasi nagios
kaedah konfigurasi nagios
 Bagaimana untuk memadam folder dalam linux
Bagaimana untuk memadam folder dalam linux








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



