



Dihasilkan oleh Big Data Digest
Keluarga, selepas kecerdasan buatan (AI) menakluki catur, Go, dan Dota, kemahiran memusing pena juga telah dipelajari oleh robot AI.

Robot memusing pen yang disebutkan di atas mendapat manfaat daripada ejen yang dipanggil Eureka, kajian penyelidikan daripada NVIDIA, Universiti Pennsylvania, Institut Teknologi California dan Universiti Texas di Austin.
Dengan "panduan" Eureka, robot juga boleh membuka laci dan kabinet, membaling dan menangkap bola, atau menggunakan gunting. Menurut Nvidia, Eureka datang dalam 10 jenis berbeza dan boleh melakukan 29 tugas berbeza.
Anda mesti tahu bahawa sebelum ini, fungsi pen transfer tidak dapat direalisasikan dengan begitu lancar dengan pengaturcaraan manual oleh pakar manusia sahaja.

Robot menghidangkan walnut
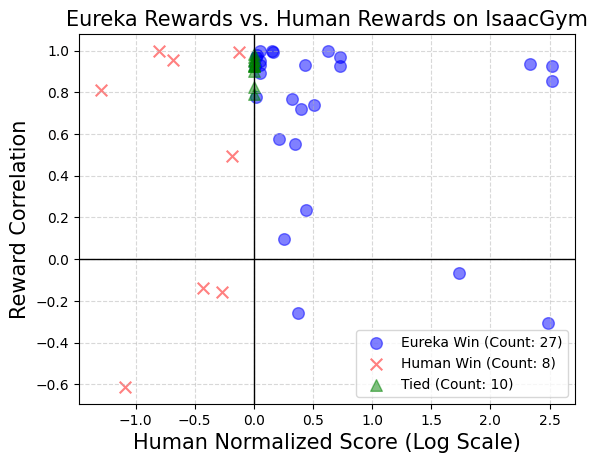
Dan Eureka boleh menulis algoritma ganjarannya sendiri untuk melatih robot, dan kuasa pengekodannya kuat: program ganjaran yang ditulis sendiri mengatasi pakar manusia dalam 83% tugasan , menjadikan robot lebih berkebolehan Prestasi dipertingkatkan dengan purata 52%.
Eureka telah mempelopori cara baharu pembelajaran bebas kecerunan daripada maklum balas manusia Ia boleh menyerap ganjaran dan maklum balas teks yang disediakan oleh manusia dengan mudah, dengan itu meningkatkan lagi mekanisme penjanaan ganjarannya sendiri.
Secara khusus, Eureka memanfaatkan GPT-4 OpenAI untuk menulis program ganjaran untuk pembelajaran percubaan dan kesilapan robot. Ini bermakna sistem tidak bergantung pada isyarat khusus tugas manusia atau corak ganjaran yang telah ditetapkan.
Menggunakan simulasi dipercepatkan GPU di Gim Isaac, Eureka boleh menilai dengan cepat merit sejumlah besar ganjaran calon, membolehkan latihan yang lebih cekap. Eureka kemudian menjana ringkasan statistik utama keputusan latihan dan membimbing LLM (Model Bahasa) untuk menambah baik penjanaan fungsi ganjaran. Dengan cara ini, ejen AI dapat memperbaiki arahannya kepada robot secara bebas. . Para penyelidik yang terlibat dalam kajian itu malah menggelar Eureka sebagai "jurutera ganjaran manusia luar biasa."
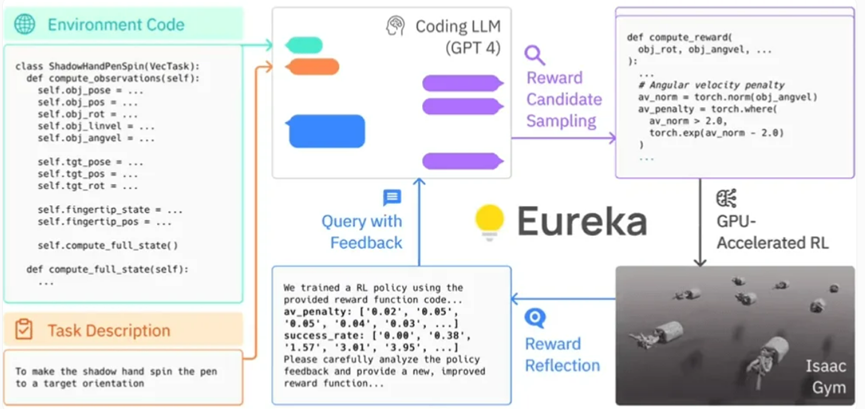
Eureka berjaya merapatkan jurang antara penaakulan (pengekodan) peringkat tinggi dan kawalan motor peringkat rendah. Ia menggunakan apa yang dipanggil "seni bina kecerunan hibrid": kotak hitam inferens tulen LLM (Model Bahasa, model bahasa) membimbing rangkaian saraf yang boleh dipelajari. Dalam seni bina ini, gelung luar menjalankan GPT-4 untuk mengoptimumkan fungsi ganjaran (bebas kecerunan), manakala gelung dalam menjalankan pembelajaran tetulang untuk melatih pengawal robot (berasaskan kecerunan).
- Linxi "Jim" Fan, Saintis Penyelidikan Kanan di NVIDIA
Eureka boleh menyepadukan maklum balas manusia untuk melaraskan ganjaran dengan lebih baik agar lebih sepadan dengan jangkaan pembangun. Nvidia memanggil proses ini "dalam konteks RLHF" (Pembelajaran Kontekstual daripada Maklum Balas Manusia)
Perlu diambil perhatian bahawa pasukan penyelidik Nvidia telah sumber terbuka perpustakaan algoritma AI Eureka. Ini akan membolehkan individu dan institusi meneroka dan bereksperimen dengan algoritma ini melalui Gim Nvidia Isaac. Isaac Gym dibina pada platform Nvidia Omniverse, rangka kerja pembangunan untuk mencipta alat dan aplikasi 3D berdasarkan rangka kerja Open USD.
- Pautan kertas: https://arxiv.org/pdf/2310.12931.pdf
- Pautan projek: https://eureka-research.github.io/
- Pautan kod: https://github.com/eureka- Bagaimanakah anda menilai penyelidikan/Eureka
?
Pembelajaran pengukuhan telah mencapai kejayaan besar sepanjang dekad yang lalu, tetapi kita harus mengakui bahawa masih terdapat cabaran yang berterusan. Walaupun terdapat percubaan untuk memperkenalkan teknologi serupa sebelum ini, berbanding dengan L2R (Learning to Reward) yang menggunakan model bahasa (LLM) untuk membantu reka bentuk ganjaran, Eureka lebih menonjol kerana ia menghapuskan keperluan untuk gesaan khusus tugasan. Apa yang menjadikan Eureka lebih baik daripada L2R ialah keupayaannya untuk mencipta algoritma ganjaran yang dinyatakan secara bebas dan memanfaatkan kod sumber alam sekitar sebagai maklumat latar belakang.
Pasukan penyelidik NVIDIA menjalankan tinjauan untuk meneroka sama ada penyebuan dengan fungsi ganjaran manusia menawarkan beberapa kelebihan. Tujuan percubaan adalah untuk melihat sama ada anda berjaya menggantikan fungsi ganjaran manusia asal dengan output lelaran Eureka awal.
Dalam ujian, pasukan penyelidik NVIDIA mengoptimumkan semua fungsi ganjaran akhir menggunakan algoritma pembelajaran pengukuhan yang sama dan hiperparameter yang sama dalam konteks setiap tugas. Untuk menguji sama ada hiperparameter khusus tugasan ini ditala dengan baik untuk memastikan keberkesanan ganjaran yang direka bentuk secara buatan, mereka menggunakan pelaksanaan pengoptimuman dasar proksimal (PPO) yang ditala dengan baik yang berdasarkan kerja sebelumnya tanpa sebarang pengubahsuaian. Untuk setiap ganjaran, penyelidik melakukan lima larian latihan PPO bebas dan melaporkan purata nilai metrik tugasan maksimum yang dicapai di pusat pemeriksaan dasar sebagai ukuran prestasi ganjaran.
Hasilnya menunjukkan bahawa pereka manusia selalunya mempunyai pemahaman yang baik tentang pembolehubah keadaan yang berkaitan, tetapi mungkin tidak mempunyai kemahiran tertentu dalam mereka bentuk ganjaran yang berkesan.
Penyelidikan terobosan daripada Nvidia ini membuka sempadan baharu dalam pembelajaran pengukuhan dan reka bentuk ganjaran. Algoritma reka bentuk ganjaran sejagat mereka, Eureka, memanfaatkan kuasa model bahasa yang besar dan carian evolusi kontekstual untuk menjana ganjaran peringkat manusia merentas pelbagai domain tugasan robotik tanpa memerlukan gesaan khusus tugasan atau campur tangan manusia, dengan ketara mengubah Pemahaman kita tentang AI dan pembelajaran mesin.
Atas ialah kandungan terperinci Robot itu belajar memutar pen dan pinggan walnut! GPT-4 berkat, lebih kompleks tugas, lebih baik prestasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



