


Penyelidik dari Universiti Fudan dan Makmal Noah's Ark Huawei mencadangkan penyelesaian berulang untuk menghasilkan video berkualiti tinggi berdasarkan model penyebaran imej (LDM) - VidRD (Guna Semula dan Resap). Penyelesaian ini bertujuan untuk membuat penemuan dalam kualiti dan panjang jujukan video yang dijana, dan mencapai penjanaan jujukan panjang video yang berkualiti tinggi dan boleh dikawal. Ia berkesan mengurangkan masalah kegelisahan antara bingkai video yang dijana, mempunyai penyelidikan dan nilai praktikal yang tinggi, dan menyumbang kepada komuniti AIGC yang hangat semasa.
Latent Diffusion Model (LDM) ialah model generatif berdasarkan Denoising Autoencoder, yang boleh menjana sampel berkualiti tinggi daripada data yang dimulakan secara rawak dengan mengeluarkan bunyi secara beransur-ansur. Walau bagaimanapun, disebabkan oleh pengehadan pengiraan dan ingatan semasa latihan model dan inferens, satu LDM biasanya hanya boleh menjana bilangan bingkai video yang sangat terhad. Walaupun kerja sedia ada cuba menggunakan model ramalan yang berasingan untuk menjana lebih banyak bingkai video, ini juga memerlukan kos latihan tambahan dan menghasilkan jitter tahap bingkai.
Dalam kertas kerja ini, diilhamkan oleh kejayaan luar biasa model resapan terpendam (LDM) dalam sintesis imej, rangka kerja yang dipanggil "Guna Semula dan Resap", atau singkatannya VidRD, dicadangkan. Rangka kerja ini boleh menjana lebih banyak bingkai video selepas bilangan kecil bingkai video telah dijana oleh LDM, sekali gus menjana kandungan video yang lebih panjang, berkualiti tinggi dan pelbagai secara berulang. VidRD memuatkan model LDM imej pra-latihan untuk latihan yang cekap dan menggunakan rangkaian U-Net dengan maklumat temporal tambahan untuk penyingkiran hingar. . Projek Halaman utama: https://anonymous0x233.github.io/ReuseAndDiffuse/

Sumbangan utama artikel ini adalah seperti berikut:
Dalam reka bentuk model artikel ini, ciri yang ketara ialah penggunaan penuh berat model pra-latihan. Khususnya, kebanyakan lapisan rangkaian, termasuk komponen VAE dan lapisan upsampling dan downsampling U-Net, dimulakan menggunakan pemberat pra-latihan model resapan stabil. Strategi ini bukan sahaja mempercepatkan proses latihan model dengan ketara, tetapi juga memastikan model menunjukkan kestabilan dan kebolehpercayaan yang baik dari awal. Model kami boleh menjana bingkai tambahan secara berulang daripada klip video awal yang mengandungi sebilangan kecil bingkai dengan menggunakan semula ciri terpendam asal dan meniru proses penyebaran sebelumnya. Di samping itu, untuk pengekod auto yang digunakan untuk menukar antara ruang piksel dan ruang terpendam, kami menyuntik lapisan rangkaian berkaitan pemasaan ke dalam penyahkodnya dan memperhalusi lapisan ini untuk meningkatkan ketekalan temporal.
Untuk memastikan kesinambungan antara bingkai video, artikel ini menambahkan lapisan Temp-conv dan Temp-attn 3D pada model. Lapisan Temp-conv mengikuti 3D ResNet, struktur yang boleh melaksanakan operasi konvolusi 3D untuk menangkap korelasi spatial dan temporal untuk memahami perubahan dinamik dan kesinambungan pengagregatan jujukan video. Struktur Temp-Attn adalah serupa dengan Self-attention dan digunakan untuk menganalisis dan memahami hubungan antara bingkai dalam jujukan video, membolehkan model menyegerakkan maklumat yang sedang berjalan antara bingkai dengan tepat. Parameter ini dimulakan secara rawak semasa latihan dan direka bentuk untuk menyediakan model dengan pemahaman dan pengekodan struktur temporal. Di samping itu, untuk menyesuaikan diri dengan struktur model, input data juga telah disesuaikan dan diselaraskan dengan sewajarnya.
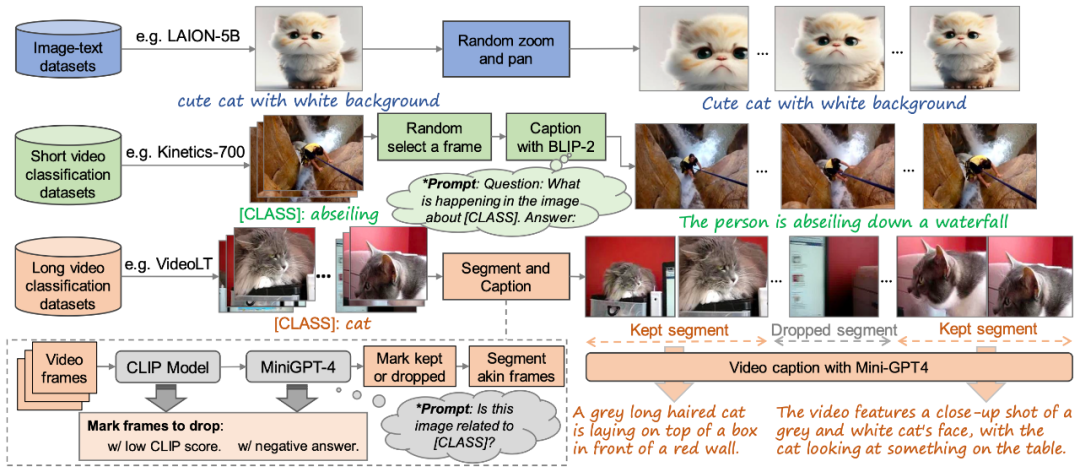
Rajah 2. Kaedah pembinaan set data latihan "teks-video" berkualiti tinggi yang dicadangkan dalam artikel ini# 🎜🎜#
Untuk melatih model VidRD, artikel ini mencadangkan kaedah membina set data latihan "text-video" berskala besar, seperti yang ditunjukkan dalam Rajah 2. Ini kaedah boleh mengendalikan data "imej teks" " dan data "video teks" tanpa penerangan. Selain itu, untuk mencapai penjanaan video berkualiti tinggi, artikel ini juga cuba mengalih keluar tera air daripada data latihan.
Walaupun set data perihalan video berkualiti tinggi agak terhad dalam pasaran semasa, sejumlah besar set data klasifikasi video wujud. Set data ini mempunyai kandungan video yang kaya dan setiap video disertakan dengan label klasifikasi. Contohnya, Moments-In-Time, Kinetics-700 dan VideoLT ialah tiga set data klasifikasi video berskala besar yang mewakili. Kinetics-700 merangkumi 700 kategori tindakan manusia dan mengandungi lebih 600,000 klip video. Moments-In-Time termasuk 339 kategori tindakan, dengan jumlah lebih daripada satu juta klip video. VideoLT, sebaliknya, mengandungi 1,004 kategori dan 250,000 video panjang yang tidak diedit.
Untuk menggunakan sepenuhnya data video sedia ada, artikel ini cuba menganotasi video ini secara automatik dengan lebih terperinci. Artikel ini menggunakan model bahasa besar berbilang mod seperti BLIP-2 dan MiniGPT4 Dengan menyasarkan bingkai utama dalam video dan menggabungkan label klasifikasi asalnya, artikel ini mereka bentuk banyak Gesaan untuk menjana anotasi melalui model soal jawab. Kaedah ini bukan sahaja meningkatkan maklumat pertuturan data video, tetapi juga boleh membawa penerangan video yang lebih komprehensif dan terperinci kepada video sedia ada tanpa penerangan terperinci, dengan itu mencapai penjanaan teg video yang lebih kaya untuk membantu model VidRD membawa kesan latihan yang lebih baik.
Selain itu, untuk data imej yang sangat kaya sedia ada, artikel ini juga mereka bentuk kaedah terperinci untuk menukar data imej kepada format video untuk latihan. Operasi khusus adalah untuk menyorot dan mengezum pada kedudukan imej yang berbeza pada kelajuan yang berbeza, dengan itu memberikan setiap imej bentuk persembahan dinamik yang unik dan mensimulasikan kesan menggerakkan kamera untuk menangkap objek pegun dalam kehidupan sebenar. Melalui kaedah ini, data imej sedia ada boleh digunakan dengan berkesan untuk latihan video.
Teks penerangan ialah: "Selang masa di tanah salji dengan aurora di langit .", "Lilin sedang menyala.", "Puting beliung epik menyerang di atas bandar yang bercahaya pada waktu malam.", dan "Pemandangan dari udara pantai berpasir putih di tepi laut yang indah." Lebih banyak visualisasi boleh didapati di halaman utama projek.

Rajah 3. Perbandingan visual kesan penjanaan dengan kaedah sedia ada #🎜🎜🎜##🎜🎜 🎜#Akhirnya, seperti yang ditunjukkan dalam Rajah 3, perbandingan visual hasil yang dihasilkan dalam artikel ini dengan kaedah sedia ada Make-A-Video [3] dan Imagen Video [4] menunjukkan bahawa model dalam artikel ini mempunyai kualiti yang lebih baik.
Atas ialah kandungan terperinci Universiti Fudan dan Huawei Noah mencadangkan rangka kerja VidRD untuk mencapai penjanaan video berkualiti tinggi berulang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 penggunaan fungsi memcpy
penggunaan fungsi memcpy
 Cara menutup pustaka sumber apl
Cara menutup pustaka sumber apl
 Pertanyaan blockchain pelayar Ethereum
Pertanyaan blockchain pelayar Ethereum
 Bagaimana untuk membaiki sistem win7 jika ia rosak dan tidak boleh boot
Bagaimana untuk membaiki sistem win7 jika ia rosak dan tidak boleh boot
 Adakah linux sistem terbenam?
Adakah linux sistem terbenam?
 html editor dalam talian
html editor dalam talian
 Bagaimana pycharm menjalankan fail python
Bagaimana pycharm menjalankan fail python








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



