


Dalam beberapa tahun kebelakangan ini, model bahasa besar (LLM) dan seni bina pengubah asasnya telah menjadi asas AI perbualan dan telah melahirkan pelbagai aplikasi pengguna dan perusahaan. Walaupun terdapat kemajuan yang besar, tetingkap konteks panjang tetap yang digunakan oleh LLM sangat mengehadkan kebolehgunaan untuk perbualan panjang atau penaakulan dokumen panjang. Walaupun untuk LLM sumber terbuka yang paling banyak digunakan, panjang input maksimumnya hanya membenarkan sokongan beberapa dozen balasan mesej atau inferens dokumen pendek.
Pada masa yang sama, dihadkan oleh mekanisme perhatian kendiri seni bina pengubah, hanya memanjangkan panjang konteks pengubah juga akan menyebabkan masa pengiraan dan kos memori meningkat secara eksponen, yang menjadikan seni bina konteks panjang baharu sebagai penyelidikan yang mendesak topik.
Walau bagaimanapun, walaupun kita boleh mengatasi cabaran pengiraan penskalaan konteks, penyelidikan terkini menunjukkan bahawa model konteks panjang bergelut untuk menggunakan konteks tambahan dengan berkesan.
Bagaimana untuk menyelesaikannya? Memandangkan sumber besar yang diperlukan untuk melatih SOTA LLM dan pulangan penskalaan konteks yang semakin berkurangan, kami memerlukan teknik alternatif yang menyokong konteks yang panjang dengan segera. Penyelidik di University of California, Berkeley, telah membuat kemajuan baru dalam hal ini.
Dalam artikel ini, penyelidik meneroka cara memberikan ilusi konteks tak terhingga sambil terus menggunakan model konteks tetap. Pendekatan mereka meminjam idea daripada paging memori maya, membolehkan aplikasi memproses set data yang jauh melebihi memori yang tersedia.
Berdasarkan idea ini, penyelidik mengambil kesempatan daripada kemajuan terkini dalam keupayaan memanggil fungsi ejen LLM untuk mereka bentuk sistem LLM yang diilhamkan oleh OS untuk pengurusan konteks maya - MemGPT.

Laman utama kertas: https://memgpt.ai/
alamat arXiv: https://arxiv.org/pdf/2310.08560.pdf
Projek ini telah menjadi sumber terbuka dan telah memperoleh 1.7k bintang di GitHub kuantiti.
Alamat GitHub: https://github.com/cpacker/MemGPT
Tinjauan Keseluruhan Kaedah
Penyelidikan ini mendapat inspirasi daripada pengurusan memori hierarki sistem pengendalian tradisional, dalam sistem pengendalian yang cekap (efficiently windows). maklumat "halaman" masuk dan keluar antara "memori utama") dan storan luaran. MemGPT bertanggungjawab untuk menguruskan aliran kawalan antara memori, modul pemprosesan LLM dan pengguna. Reka bentuk ini membenarkan pengubahsuaian konteks berulang semasa satu tugas, membolehkan ejen menggunakan tetingkap konteks terhadnya dengan lebih cekap.
MemGPT menganggap tetingkap konteks sebagai sumber ingatan yang terhad dan mereka bentuk struktur hierarki untuk LLM yang serupa dengan ingatan hierarki dalam sistem pengendalian tradisional (Patterson et al., 1988). Untuk memberikan panjang konteks yang lebih panjang, penyelidikan ini membolehkan LLM mengurus kandungan yang diletakkan dalam tetingkap konteksnya melalui "LLM OS" - MemGPT. MemGPT membolehkan LLM mendapatkan semula data sejarah berkaitan yang hilang dalam konteks, serupa dengan kerosakan halaman dalam sistem pengendalian. Selain itu, ejen boleh mengubah suai secara berulang kandungan tetingkap konteks tugas tunggal, sama seperti proses boleh berulang kali mengakses memori maya.
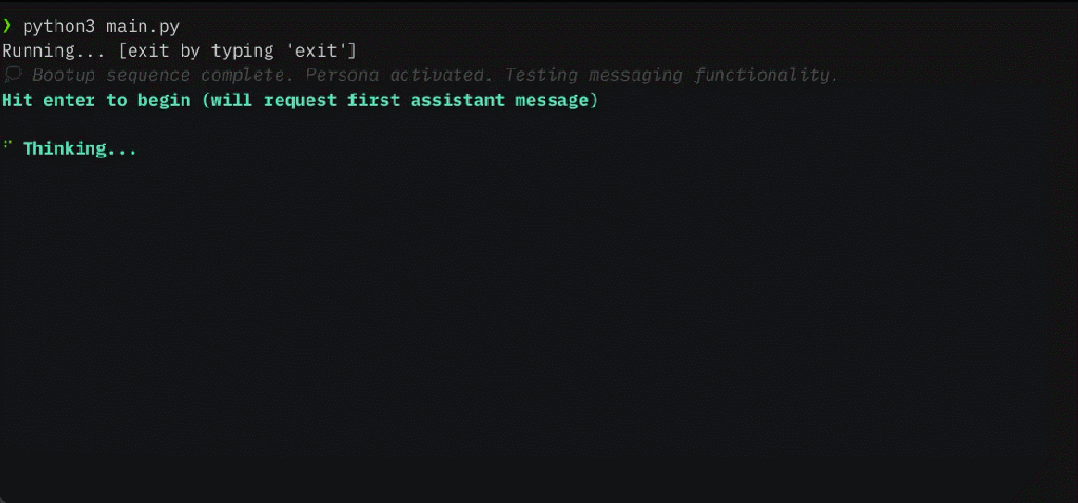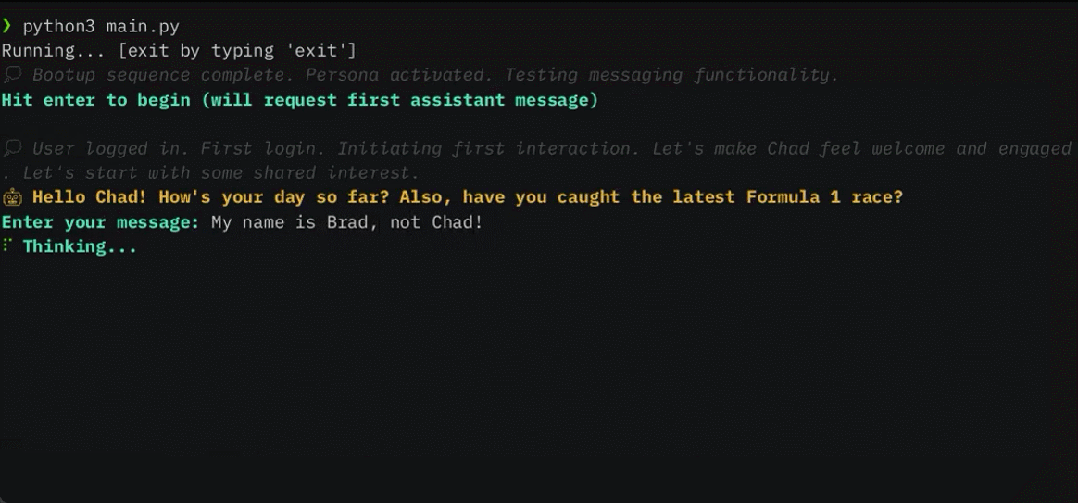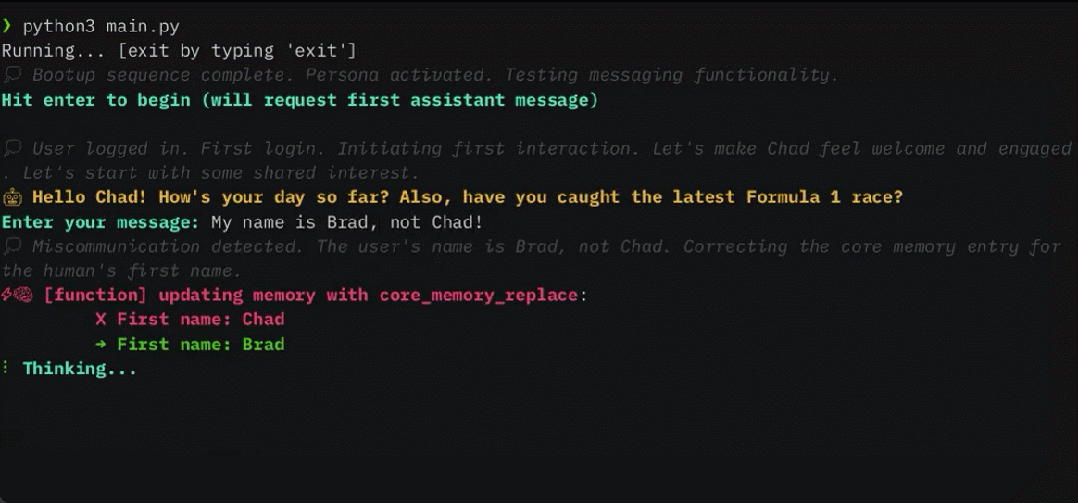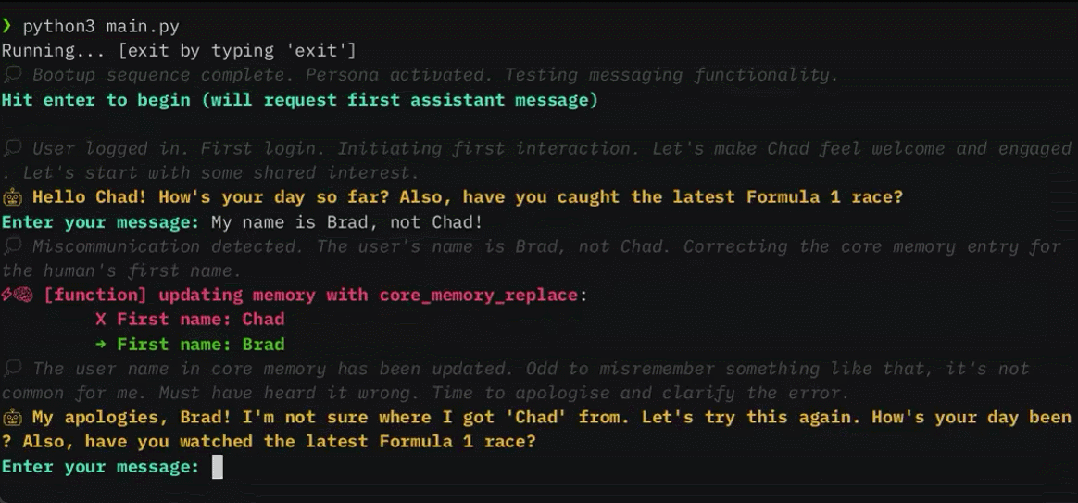
MemGPT membolehkan LLM mengendalikan konteks tanpa had apabila tetingkap konteks terhad Komponen MemGPT ditunjukkan dalam Rajah 1 di bawah.
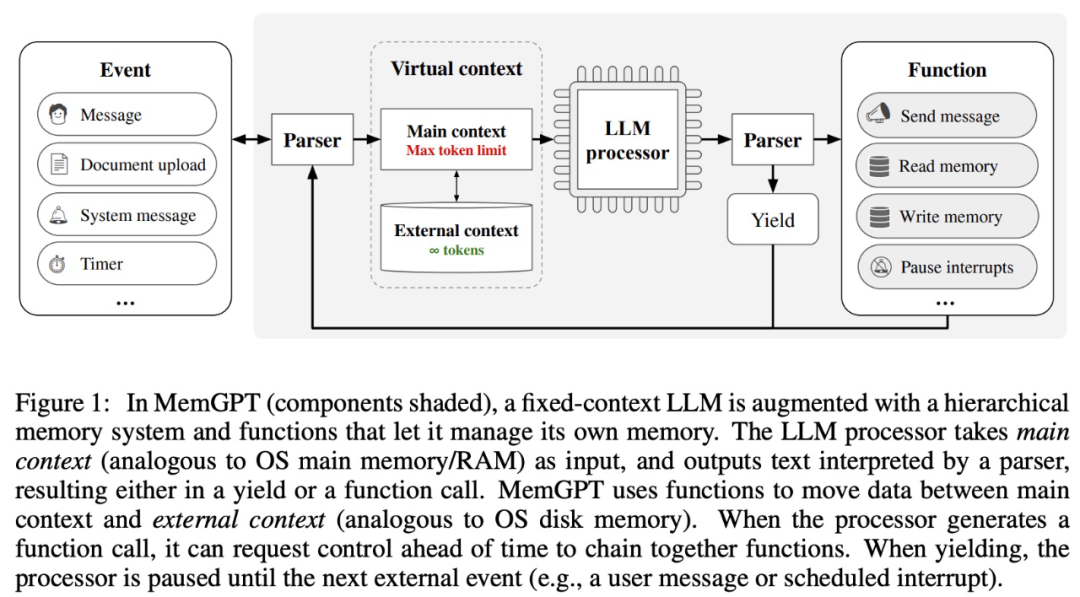
MemGPT menyelaras pergerakan data antara konteks utama (kandungan dalam tetingkap konteks) dan konteks luaran melalui panggilan fungsi MemGPT kemas kini dan mendapatkan semula secara autonomi berdasarkan konteks semasa.


Perlu diperhatikan bahawa tetingkap konteks perlu menggunakan token amaran untuk menandakan hadnya, seperti yang ditunjukkan dalam Rajah 3 di bawah:

Eksperimen dan keputusan
Dalam bahagian eksperimen, penyelidik menilai MemGPT dalam dua domain konteks panjang, iaitu ejen perbualan dan pemprosesan dokumen. Untuk ejen perbualan, mereka melanjutkan set data sembang berbilang sesi sedia ada (Xu et al. (2021)) dan memperkenalkan dua tugas perbualan baharu untuk menilai keupayaan ejen untuk mengekalkan pengetahuan dalam perbualan yang panjang. Untuk analisis dokumen, mereka menanda aras MemGPT pada tugas yang dicadangkan oleh Liu et al (2023a), termasuk menjawab soalan dan mendapatkan semula nilai kunci dokumen panjang. MemGPT untuk ejen perbualan
Yang pertama ialah konsistensi, iaitu ejen harus mengekalkan keselarasan perbualan, dan fakta, rujukan dan peristiwa baharu yang disediakan hendaklah konsisten dengan kenyataan sebelumnya daripada pengguna dan ejen.
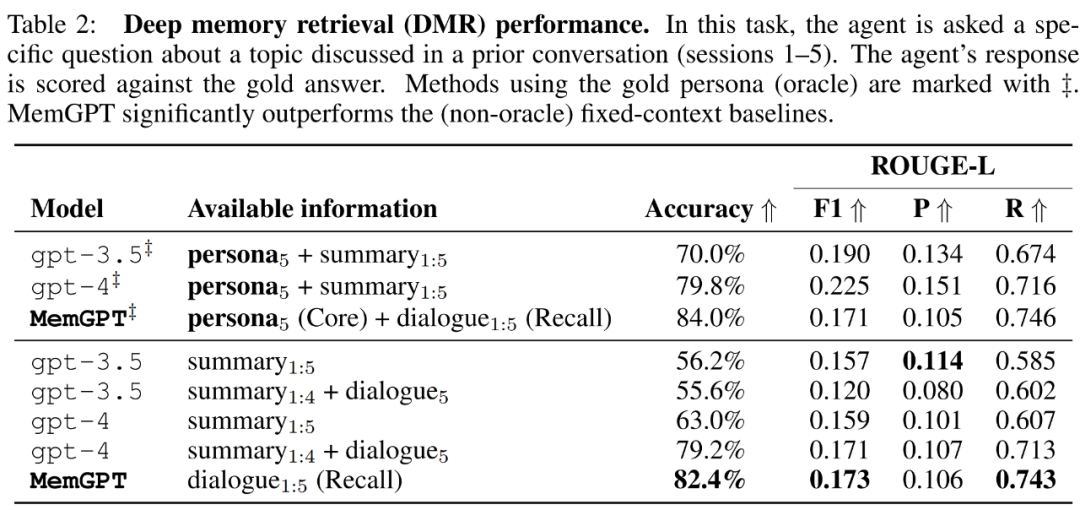
Mula-mula mari kita nilai konsistensi. Para penyelidik memperkenalkan tugas mendapatkan ingatan mendalam (DMR) berdasarkan set data MSC untuk menguji konsistensi ejen perbualan. Dalam DMR, pengguna mengemukakan soalan kepada ejen perbualan, dan soalan itu secara eksplisit merujuk perbualan sebelumnya, dengan jangkaan bahawa julat jawapan akan menjadi sangat sempit. Untuk butiran, sila rujuk contoh dalam Rajah 5 di bawah.
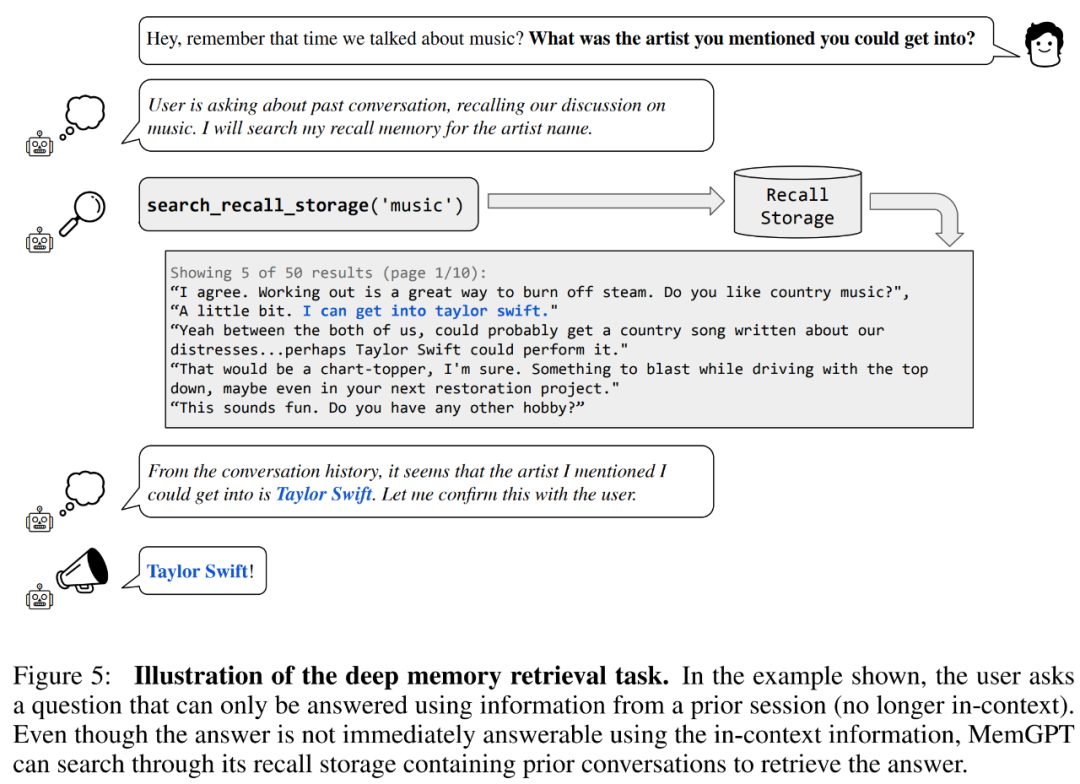
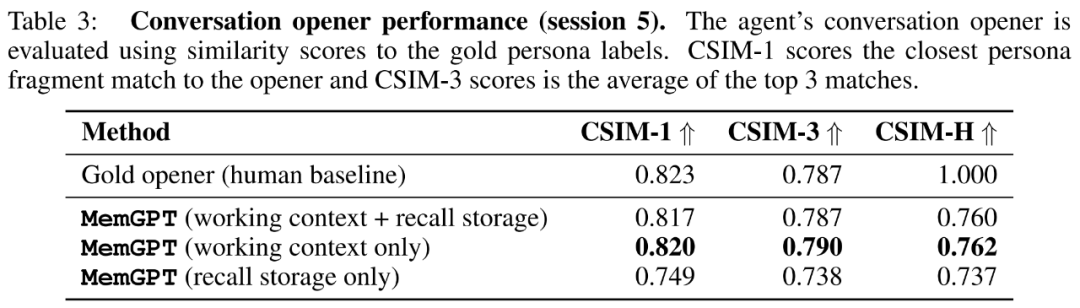
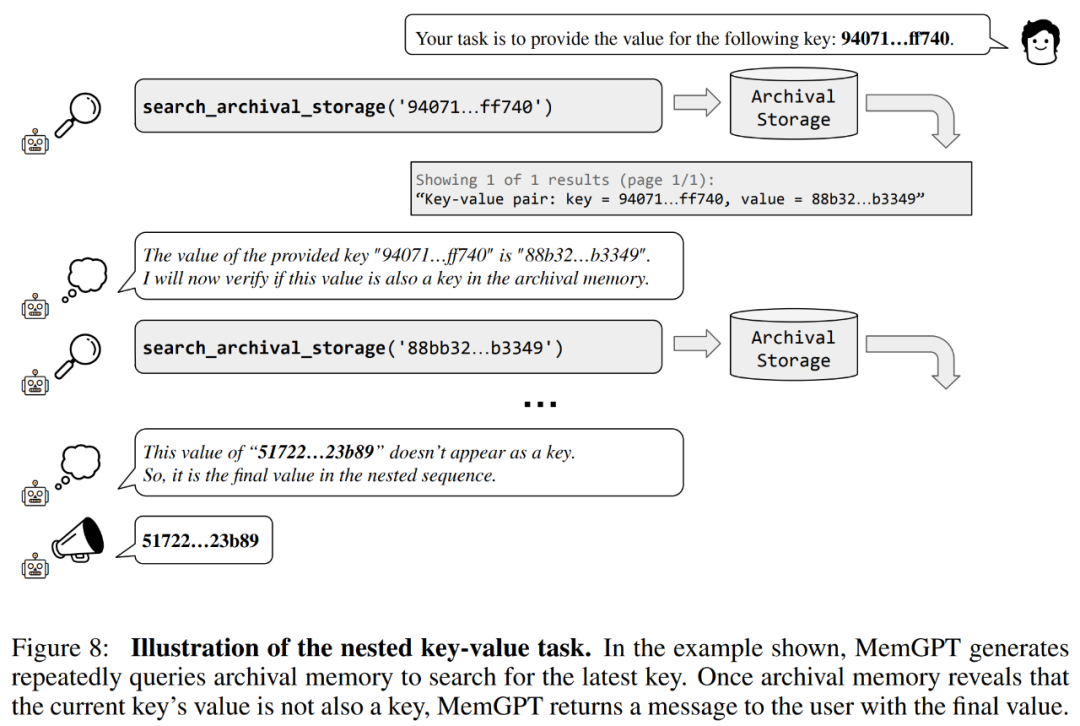
 Para penyelidik juga memperkenalkan tugas baharu berdasarkan perolehan nilai kunci sintetik, iaitu Pengambilan Nilai-Kunci Bersarang Untuk menunjukkan cara MemGPT menyusun maklumat daripada berbilang sumber data.
Para penyelidik juga memperkenalkan tugas baharu berdasarkan perolehan nilai kunci sintetik, iaitu Pengambilan Nilai-Kunci Bersarang Untuk menunjukkan cara MemGPT menyusun maklumat daripada berbilang sumber data. Daripada keputusan, walaupun GPT-3.5 dan GPT-4 menunjukkan prestasi yang baik pada tugasan nilai kunci asal, mereka menunjukkan prestasi yang lemah pada tugas mendapatkan nilai kunci bersarang. MemGPT tidak terjejas oleh bilangan tahap bersarang dan boleh melakukan carian bersarang dengan berulang kali mengakses pasangan nilai kunci yang disimpan dalam memori utama melalui pertanyaan fungsi.
Prestasi MemGPT pada tugas mendapatkan nilai kunci bersarang menunjukkan keupayaannya untuk melakukan berbilang carian menggunakan gabungan berbilang pertanyaan.
Sila rujuk kertas asal untuk butiran lanjut teknikal dan keputusan percubaan.
Atas ialah kandungan terperinci Fikirkan LLM sebagai sistem pengendalian, ia mempunyai konteks 'maya' tanpa had, kerja baharu Berkeley telah menerima 1.7k bintang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah perisian anti-virus?
Apakah perisian anti-virus?
 Platform mata wang digital domestik
Platform mata wang digital domestik
 Bagaimana untuk mengkonfigurasi pembolehubah persekitaran Tomcat
Bagaimana untuk mengkonfigurasi pembolehubah persekitaran Tomcat
 Apakah maksud c#?
Apakah maksud c#?
 Bagaimana untuk memulihkan fail yang dipadam secara kekal pada komputer
Bagaimana untuk memulihkan fail yang dipadam secara kekal pada komputer
 Bagaimana untuk membuka fail html pada telefon bimbit
Bagaimana untuk membuka fail html pada telefon bimbit
 Kaedah pemulihan pangkalan data Oracle
Kaedah pemulihan pangkalan data Oracle
 Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej
Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



