


GPT-4V untuk pengesanan sasaran? Ujian sebenar oleh netizen: Belum bersedia lagi.
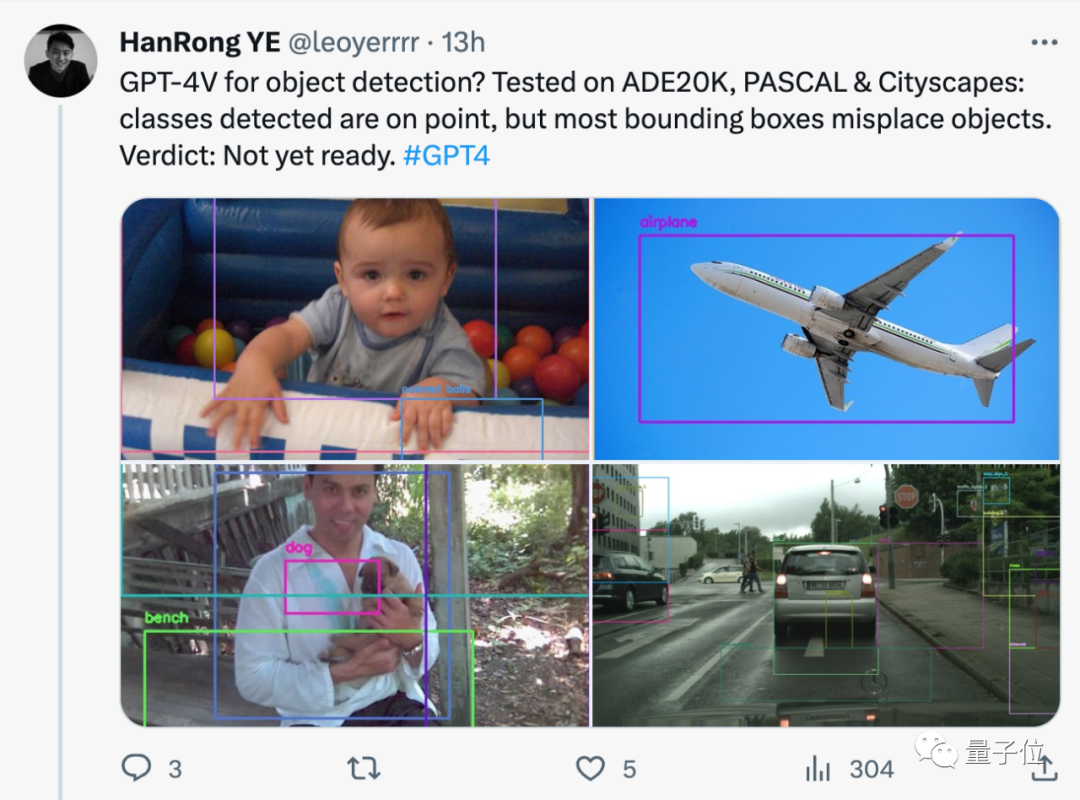
Walaupun kategori yang dikesan baik-baik saja, kebanyakan kotak sempadan tersasar.
Tidak mengapa, seseorang akan mengambil tindakan!
Mini GPT-4 yang mengalahkan GPT-4 dalam keupayaan melihat imej selama beberapa bulan telah dinaik taraf - MiniGPT-v2. .
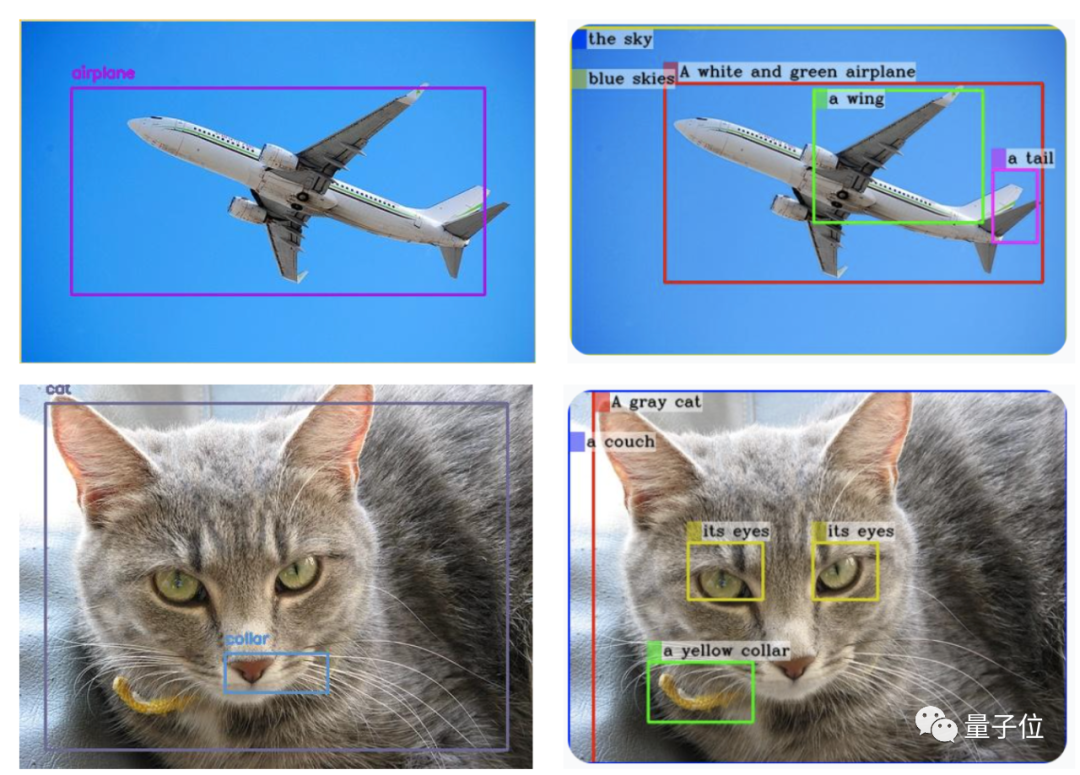
Sudah tentu, anda juga boleh menambah apa-apa dan bertanya terus~
MiniGPT-v2 terdiri daripada pasukan asal dari MiniGPT-4 (Universiti Sains dan Teknologi KAUST Raja Abdullah di Arab Saudi) dan lima penyelidik dari pembangunan bersama Meta.
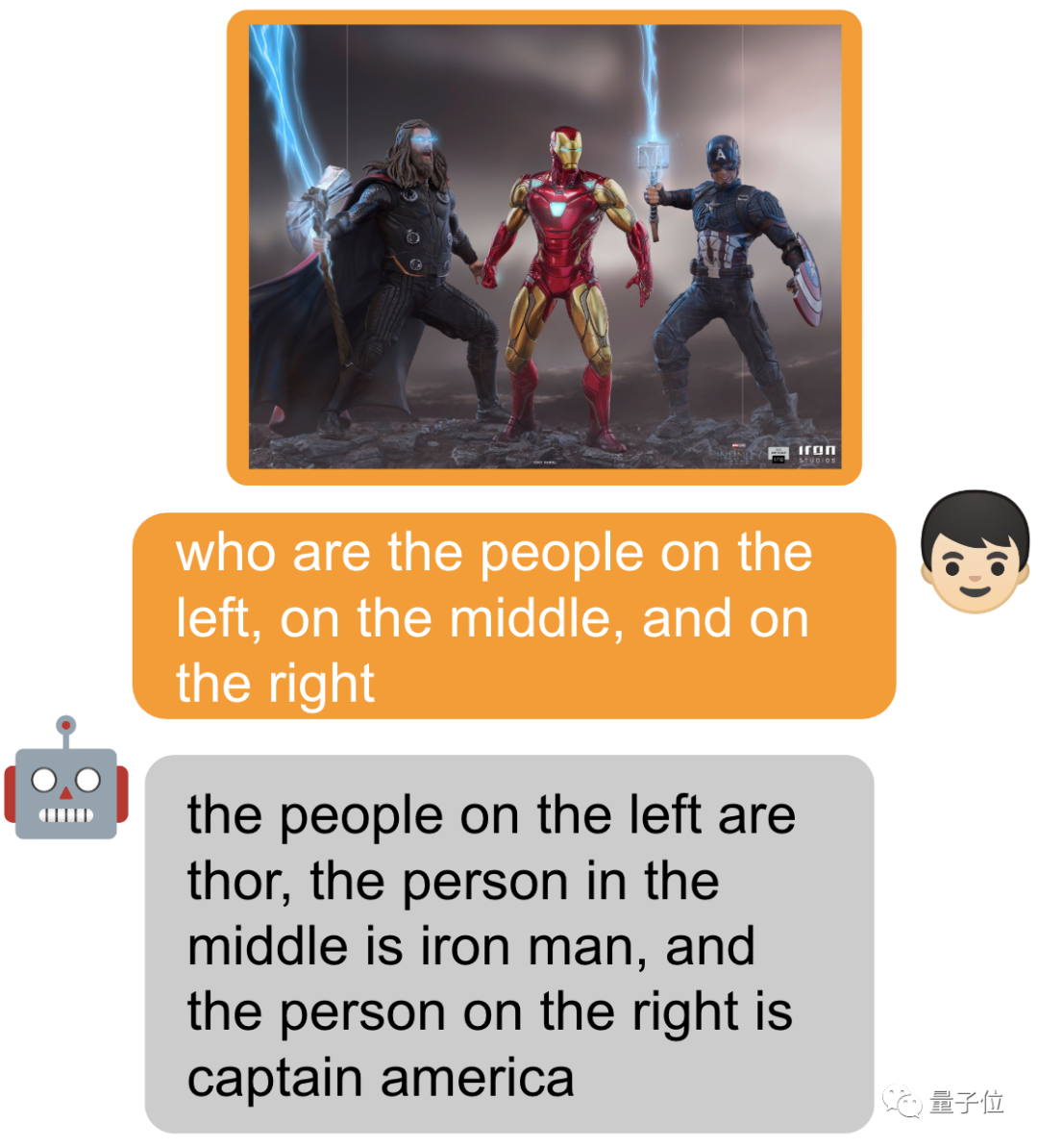

 Sebagai antara muka universal untuk pelbagai aplikasi teks, semua orang telah terbiasa dengannya. Diilhamkan oleh ini, pasukan penyelidik ingin membina antara muka bersatu yang boleh digunakan untuk pelbagai tugas visual, seperti penerangan imej, jawapan soalan visual, dsb.
Sebagai antara muka universal untuk pelbagai aplikasi teks, semua orang telah terbiasa dengannya. Diilhamkan oleh ini, pasukan penyelidik ingin membina antara muka bersatu yang boleh digunakan untuk pelbagai tugas visual, seperti penerangan imej, jawapan soalan visual, dsb.
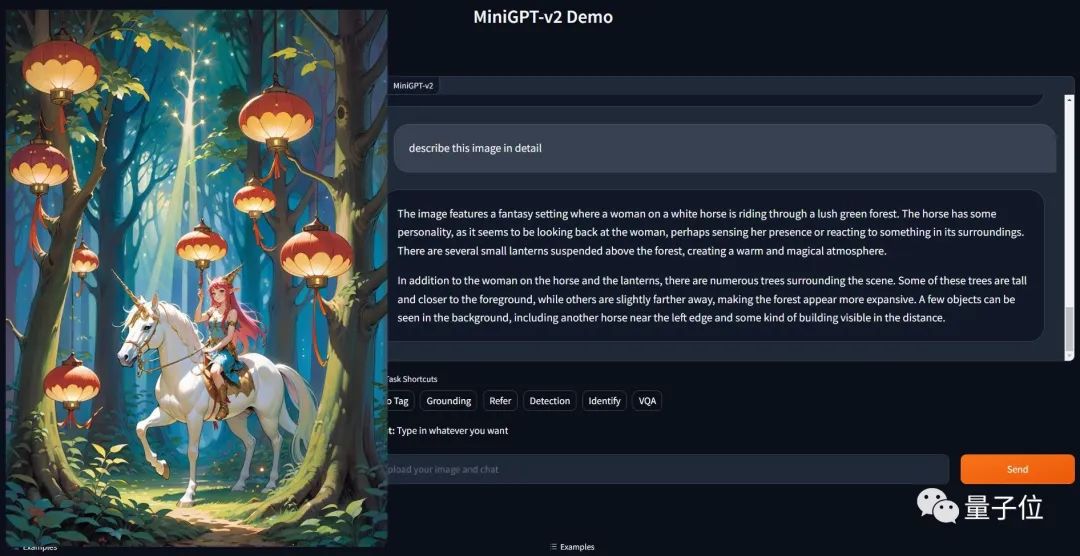 "Bagaimana cara menggunakan arahan berbilang modal yang mudah untuk menyelesaikan pelbagai tugas dengan cekap di bawah keadaan satu model telah menjadi masalah yang perlu diselesaikan oleh pasukan?"
"Bagaimana cara menggunakan arahan berbilang modal yang mudah untuk menyelesaikan pelbagai tugas dengan cekap di bawah keadaan satu model telah menjadi masalah yang perlu diselesaikan oleh pasukan?"
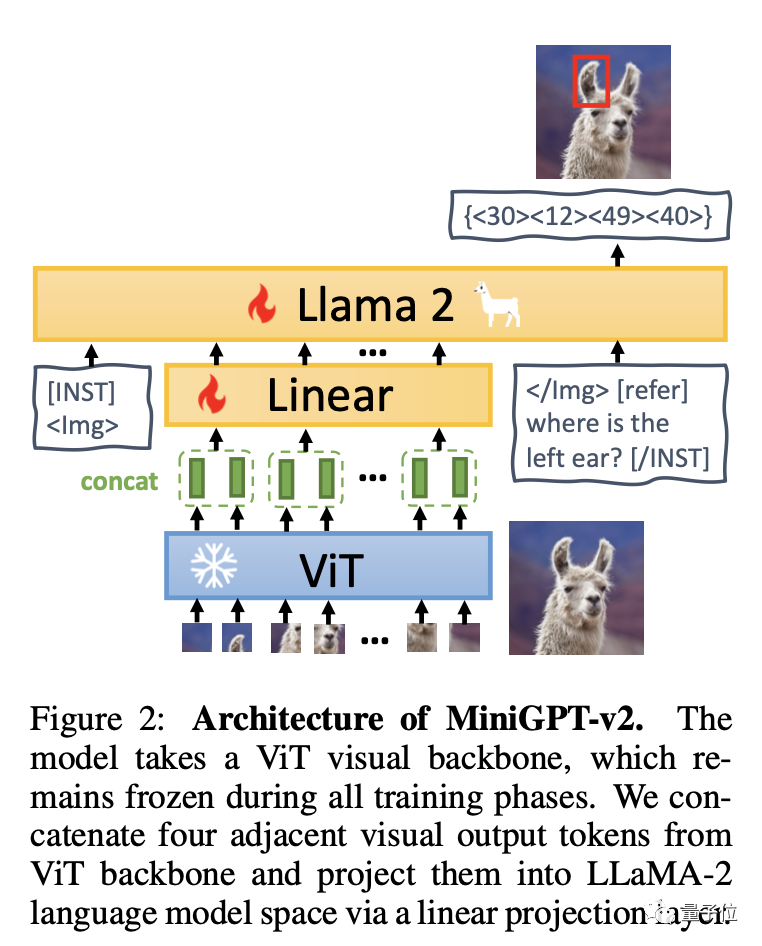
 Model ini berdasarkan tulang belakang visual ViT dan kekal tidak berubah dalam semua peringkat latihan. Empat token output visual bersebelahan diinduksi daripada ViT dan diunjurkan ke dalam ruang model bahasa LLaMA-2 melalui lapisan linear.
Model ini berdasarkan tulang belakang visual ViT dan kekal tidak berubah dalam semua peringkat latihan. Empat token output visual bersebelahan diinduksi daripada ViT dan diunjurkan ke dalam ruang model bahasa LLaMA-2 melalui lapisan linear.
Pasukan mengesyorkan menggunakan pengecam unik untuk tugasan berbeza dalam model latihan, supaya model besar boleh membezakan setiap arahan tugas dengan mudah dan meningkatkan kecekapan pembelajaran setiap tugas.
Latihan terbahagi kepada tiga peringkat: pra-latihan - latihan pelbagai tugas - pelarasan arahan berbilang mod.
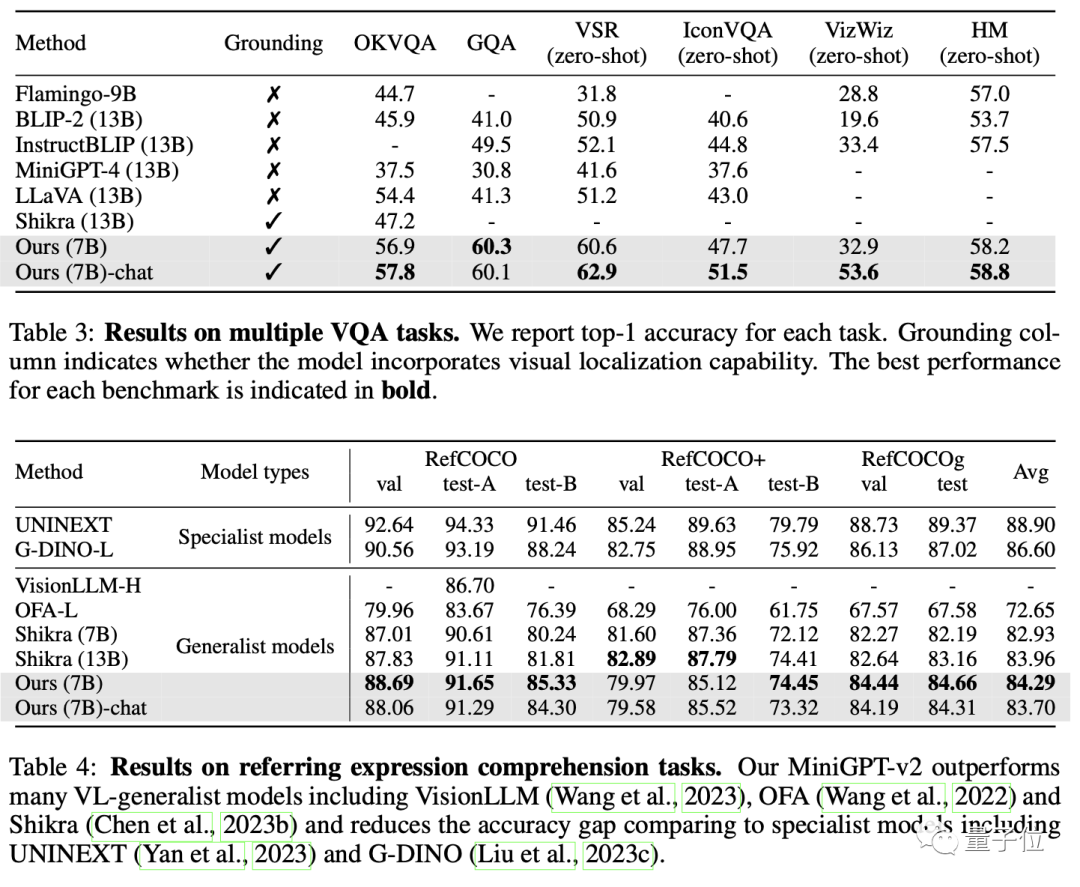
Pada akhirnya, MiniGPT-v2 mengatasi model umum bahasa visual yang lain dalam banyak jawapan soalan visual dan tanda aras asas visual.
Akhirnya, model ini boleh menyelesaikan pelbagai tugas visual, seperti penerangan objek sasaran, penyetempatan visual, penerangan imej, jawapan soalan visual, dan menghuraikan terus objek imej daripada teks input yang diberikan.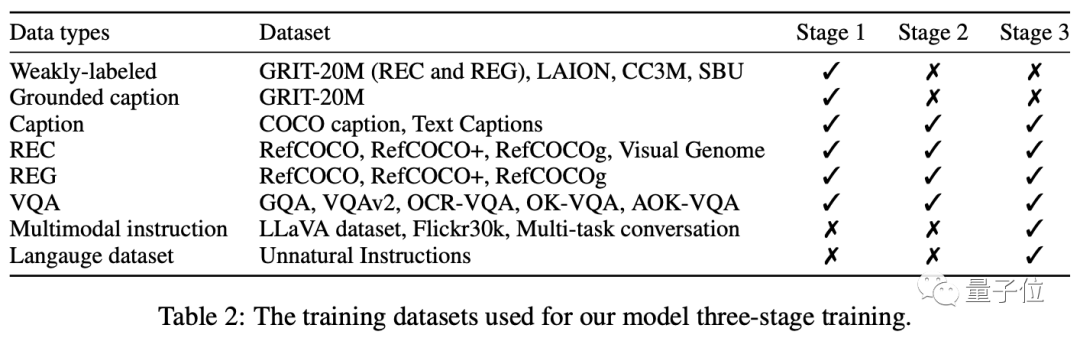
https://huggingface.co/spaces/Vision-CAIR/ MiniGPT -v2
pautanGitHub: https://github.com/Vision-CAIR/MiniGPT-4
Atas ialah kandungan terperinci Keupayaan visual mini GPT-4 yang sangat popular telah melonjak, dengan 20,000 bintang di GitHub, dihasilkan oleh pasukan China. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah fail sumber?
Apakah fail sumber?
 Bagaimana untuk menetapkan penutupan berjadual dalam UOS
Bagaimana untuk menetapkan penutupan berjadual dalam UOS
 Springcloud lima komponen utama
Springcloud lima komponen utama
 Peranan fungsi matematik dalam bahasa C
Peranan fungsi matematik dalam bahasa C
 Apakah maksud wifi dinyahaktifkan?
Apakah maksud wifi dinyahaktifkan?
 iPhone 4 jailbreak
iPhone 4 jailbreak
 Perbezaan antara fungsi anak panah dan fungsi biasa
Perbezaan antara fungsi anak panah dan fungsi biasa
 Bagaimana untuk melangkau sambungan ke Internet selepas boot Windows 11
Bagaimana untuk melangkau sambungan ke Internet selepas boot Windows 11








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



