


Neural Radiation Fields (NeRF) adalah paradigma yang agak baharu dalam bidang pembelajaran mendalam dan penglihatan komputer. Teknik ini diperkenalkan dalam kertas kerja ECCV 2020 "NeRF: Mewakili Pemandangan sebagai Medan Sinaran Neural untuk Sintesis Pandangan" (yang memenangi Anugerah Kertas Terbaik), dan sejak itu telah meledak dalam populariti, dengan hampir 800 petikan sehingga kini [ 1]. Pendekatan ini menandakan perubahan besar dalam cara tradisional pembelajaran mesin memproses data 3D.
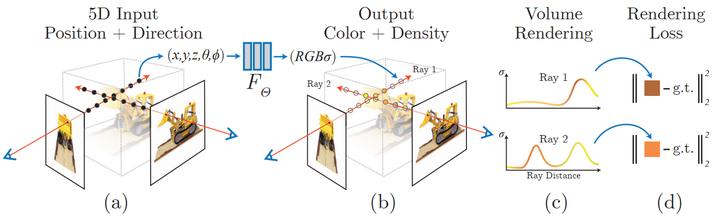
Perwakilan Pemandangan Medan Sinaran Neural dan Proses Rendering Boleh Dibezakan:
Sintesis imej dengan mensampel koordinat 5D (kedudukan dan arah tontonan) di sepanjang sinar kamera untuk menghasilkan warna dan ketumpatan; Teknik pemaparan volum mensintesis nilai ini ke dalam imej, fungsi pemaparan boleh dibezakan dan oleh itu mengoptimumkan perwakilan pemandangan dengan meminimumkan perbezaan baki antara imej yang disintesis dan imej yang diperhatikan sebenar. Apakah itu NeRF? Bukan itu sahaja, ia juga mentakrifkan dengan jelas bentuk dan rupa pemandangan 3D sebagai fungsi berterusan, yang boleh menjana jerat 3D dengan kiub kawad. Walaupun mereka belajar terus daripada data imej, mereka tidak menggunakan lapisan konvolusi atau pengubah.
Sebaliknya, NeRF adalah berdasarkan konsep medan cahaya sinar. Medan cahaya ialah fungsi yang menerangkan cara penghantaran cahaya berlaku sepanjang volum 3D. Ia menerangkan arah di mana sinar cahaya bergerak pada setiap x = (x, y, z) koordinat dalam ruang dan dalam setiap arah d, digambarkan sebagai sudut θ dan ξ atau vektor unit. Bersama-sama mereka membentuk ruang ciri 5D yang menerangkan penghantaran cahaya dalam pemandangan 3D. Diilhamkan oleh perwakilan ini, NeRF cuba untuk menganggarkan fungsi yang memetakan dari ruang ini ke ruang 4D yang terdiri daripada warna c = (R, G, B) dan ketumpatan (ketumpatan) σ, yang boleh dianggap sebagai ruang koordinat 5D ini. kemungkinan sinar ditamatkan (cth. oleh oklusi). Oleh itu, NeRF piawai ialah fungsi dalam bentuk F: (x, d) -> (c, σ).
Kertas NeRF asal meparameterkan fungsi ini menggunakan perceptron berbilang lapisan yang dilatih pada set imej dengan pose yang diketahui. Ini ialah satu kaedah dalam kelas teknik yang dipanggil pembinaan semula pemandangan umum, yang bertujuan untuk menerangkan pemandangan 3D terus daripada koleksi imej. Pendekatan ini mempunyai beberapa sifat yang sangat bagus:
Belajar terus daripada data Perwakilan adegan yang berterusan membolehkan struktur yang sangat nipis dan kompleks seperti daun atau jeratSecara keseluruhan, diberikan model NeRF terlatih dan kamera dengan pose dan dimensi imej yang diketahui, kami membina pemandangan melalui proses berikut:
Untuk setiap piksel, dari pusat optik kamera Tangkap sinar melalui adegan untuk mengumpul set sampel pada kedudukan (x, d) Menggunakan titik dan arah pandangan (x, d) setiap sampel sebagai input untuk menghasilkan nilai output (c, σ) (rgbσ)Sama seperti model pengubah [11] yang diperkenalkan pada 2017, NeRF juga mendapat manfaat daripada pengekod kedudukan sebagai inputnya. Ia menggunakan fungsi frekuensi tinggi untuk memetakan input berterusannya ke dalam ruang dimensi yang lebih tinggi untuk membantu model mempelajari perubahan frekuensi tinggi dalam data, menghasilkan model yang lebih bersih. Kaedah ini mengelakkan bias rangkaian saraf pada fungsi frekuensi rendah, membolehkan NeRF mewakili butiran yang lebih jelas. Penulis merujuk kepada kertas kerja mengenai ICML 2019 [12].
Jika anda biasa dengan pengekodan kedudukan transformerd, pelaksanaan NeRF yang berkaitan adalah agak standard, dengan ungkapan sinus dan kosinus berselang-seli yang sama. Pelaksanaan pengekod kedudukan:
# pyclass PositionalEncoder(nn.Module):# sine-cosine positional encoder for input points.def __init__( self,d_input: int,n_freqs: int,log_space: bool = False ):super().__init__()self.d_input = d_inputself.n_freqs = n_freqs # 是不是视线上的采样频率?self.log_space = log_spaceself.d_output = d_input * (1 + 2 * self.n_freqs)self.embed_fns = [lambda x: x] # 冒号前面的x表示函数参数,后面的表示匿名函数运算# Define frequencies in either linear or log scaleif self.log_space:freq_bands = 2.**torch.linspace(0., self.n_freqs - 1, self.n_freqs)else:freq_bands = torch.linspace(2.**0., 2.**(self.n_freqs - 1), self.n_freqs)# Alternate sin and cosfor freq in freq_bands:self.embed_fns.append(lambda x, freq=freq: torch.sin(x * freq))self.embed_fns.append(lambda x, freq=freq: torch.cos(x * freq))def forward(self, x) -> torch.Tensor:# Apply positional encoding to input.return torch.concat([fn(x) for fn in self.embed_fns], dim=-1)
Pemikiran: Pengekodan kedudukan ini mengekod titik input Adakah titik input ini titik persampelan pada garis penglihatan? Atau sudut pandangan yang berbeza? Adakah self.n_freqs kekerapan pensampelan pada garis penglihatan? Daripada pemahaman ini, ia sepatutnya menjadi kedudukan pensampelan pada garis penglihatan, kerana jika kedudukan pensampelan pada garis penglihatan tidak dikodkan, kedudukan ini tidak boleh diwakili dengan berkesan, dan RGBA mereka tidak boleh dilatih.
Dalam teks asal, fungsi medan cahaya diwakili oleh model NeRF Model NeRF ialah perceptron berbilang lapisan biasa yang mengambil titik 3D yang dikodkan dan arah tontonan sebagai input dan mengembalikan nilai RGBA. sebagai output. Walaupun artikel ini menggunakan rangkaian saraf, mana-mana penganggar fungsi boleh digunakan di sini. Sebagai contoh, kertas susulan Yu et al. Plenoxels menggunakan harmonik sfera untuk mencapai susunan magnitud latihan yang lebih pantas sambil mencapai keputusan kompetitif [10].
 Gambar
Gambar
Model NeRF sedalam 8 lapisan dan kebanyakan lapisan mempunyai dimensi ciri 256. Sambungan yang tinggal diletakkan pada lapisan 4. Selepas lapisan ini, nilai RGB dan σ dihasilkan. Nilai RGB diproses selanjutnya dengan lapisan linear, kemudian digabungkan dengan arah tontonan, kemudian melalui lapisan linear lain, dan akhirnya digabungkan semula dengan σ pada output. Pelaksanaan modul PyTorch model NeRF:
class NeRF(nn.Module):# Neural radiance fields module.def __init__( self,d_input: int = 3,n_layers: int = 8,d_filter: int = 256,skip: Tuple[int] = (4,), # (4,)只有一个元素4的元组 d_viewdirs: Optional[int] = None): super().__init__()self.d_input = d_input# 这里是3D XYZ,?self.skip = skip# 是要跳过什么?为啥要跳过?被遮挡?self.act = nn.functional.reluself.d_viewdirs = d_viewdirs# d_viewdirs 是2D方向?# Create model layers# [if_true 就执行的指令] if [if_true条件] else [if_false]# 是否skip的区别是,训练输入维度是否多3维,# if i in skip =if i in (4,),似乎是判断i是否等于4# self.d_input=3 :如果层id=4,网络输入要加3维,这是为什么?第4层有何特殊的?self.layers = nn.ModuleList([nn.Linear(self.d_input, d_filter)] +[nn.Linear(d_filter + self.d_input, d_filter) if i in skip else \ nn.Linear(d_filter, d_filter) for i in range(n_layers - 1)])# Bottleneck layersif self.d_viewdirs is not None:# If using viewdirs, split alpha and RGBself.alpha_out = nn.Linear(d_filter, 1)self.rgb_filters = nn.Linear(d_filter, d_filter)self.branch = nn.Linear(d_filter + self.d_viewdirs, d_filter // 2)self.output = nn.Linear(d_filter // 2, 3) # 为啥要取一半?else:# If no viewdirs, use simpler outputself.output = nn.Linear(d_filter, 4) # d_filter=256,输出是4维RGBAdef forward(self,x: torch.Tensor, # ?viewdirs: Optional[torch.Tensor] = None) -> torch.Tensor: # Forward pass with optional view direction.if self.d_viewdirs is None and viewdirs is not None:raise ValueError('Cannot input x_direction')# Apply forward pass up to bottleneckx_input = x# 这里的x是几维?从下面的分离RGB和A看,应该是4D# 下面通过8层MLP训练RGBAfor i, layer in enumerate(self.layers):# 8层,每一层进行运算x = self.act(layer(x)) if i in self.skip:x = torch.cat([x, x_input], dim=-1)# Apply bottleneckbottleneck 瓶颈是啥?是不是最费算力的模块?if self.d_viewdirs is not None:# 从网络输出分离A,RGB还需要经过更多训练alpha = self.alpha_out(x)# Pass through bottleneck to get RGBx = self.rgb_filters(x) x = torch.concat([x, viewdirs], dim=-1)x = self.act(self.branch(x)) # self.branch shape: (d_filter // 2)x = self.output(x) # self.output shape: (3)# Concatenate alphas to outputx = torch.concat([x, alpha], dim=-1)else:# Simple outputx = self.output(x)return xBerfikir: Apakah input dan output kelas NERF ini? Apa yang berlaku melalui kelas ini? Ia boleh dilihat daripada parameter fungsi __init__ bahawa ia terutamanya menetapkan input, tahap dan dimensi rangkaian saraf 5D adalah input, iaitu, kedudukan titik pandangan dan arah garis penglihatan, dan output adalah RGBA. Soalan, adakah output RGBA satu mata? Atau adakah ia satu siri garis penglihatan? Jika ia adalah satu siri, saya tidak melihat bagaimana pengekodan kedudukan menentukan RGBA setiap titik pensampelan Saya tidak melihat sebarang arahan seperti selang pensampelan jika ia adalah titik, yang mana pada garis penglihatan? kepunyaan RGBA ini? Adakah titik RGBA yang merupakan hasil koleksi titik pensampelan penglihatan yang dilihat oleh mata? Ia boleh dilihat daripada kod kelas NERF bahawa latihan suapan hadapan berbilang lapisan dilakukan terutamanya berdasarkan kedudukan titik pandang dan arah garisan pandangan Kedudukan titik pandang 5D dan arah garis penglihatan adalah input dan RGBA 4D adalah output.
3.3 Penyampai Isipadu Boleh Dibezakan
Paparan volum keluaran model NeRF asal:
def raw2outputs(raw: torch.Tensor,z_vals: torch.Tensor,rays_d: torch.Tensor,raw_noise_std: float = 0.0,white_bkgd: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:# 将原始的NeRF输出转为RGB和其他映射# Difference between consecutive elements of `z_vals`. [n_rays, n_samples]dists = z_vals[..., 1:] - z_vals[..., :-1]# ?这里减法的意义是啥?dists = torch.cat([dists, 1e10 * torch.ones_like(dists[..., :1])], dim=-1)# 将每个距离乘以其对应方向光线的范数,以转换为真实世界的距离(考虑非单位方向)dists = dists * torch.norm(rays_d[..., None, :], dim=-1)# 将噪声添加到模型对密度的预测中,用于在训练期间规范网络(防止漂浮物伪影)noise = 0.if raw_noise_std > 0.:noise = torch.randn(raw[..., 3].shape) * raw_noise_std# Predict density of each sample along each ray. Higher values imply# higher likelihood of being absorbed at this point. [n_rays, n_samples]alpha = 1.0 - torch.exp(-nn.functional.relu(raw[..., 3] + noise) * dists)# Compute weight for RGB of each sample along each ray. [n_rays, n_samples]# The higher the alpha, the lower subsequent weights are driven.weights = alpha * cumprod_exclusive(1. - alpha + 1e-10)# Compute weighted RGB map.rgb = torch.sigmoid(raw[..., :3])# [n_rays, n_samples, 3]rgb_map = torch.sum(weights[..., None] * rgb, dim=-2)# [n_rays, 3]# Estimated depth map is predicted distance.depth_map = torch.sum(weights * z_vals, dim=-1)# Disparity map is inverse depth.disp_map = 1. / torch.max(1e-10 * torch.ones_like(depth_map),depth_map / torch.sum(weights, -1))# Sum of weights along each ray. In [0, 1] up to numerical error.acc_map = torch.sum(weights, dim=-1)# To composite onto a white background, use the accumulated alpha map.if white_bkgd:rgb_map = rgb_map + (1. - acc_map[..., None])return rgb_map, depth_map, acc_map, weightsdef cumprod_exclusive(tensor: torch.Tensor) -> torch.Tensor:# (Courtesy of https://github.com/krrish94/nerf-pytorch)# Compute regular cumprod first.cumprod = torch.cumprod(tensor, -1)# "Roll" the elements along dimension 'dim' by 1 element.cumprod = torch.roll(cumprod, 1, -1)# Replace the first element by "1" as this is what tf.cumprod(..., exclusive=True) does.cumprod[..., 0] = 1.return cumprod
Soalan: Apakah fungsi utama di sini? Apa yang dimasukkan? Apakah output?
3.4 Persampelan Berstrata
Gambar Pensampelan hierarki yang dilaksanakan dalam PyTorch:
Pensampelan hierarki yang dilaksanakan dalam PyTorch:
def sample_stratified(rays_o: torch.Tensor,rays_d: torch.Tensor,near: float,far: float,n_samples: int,perturb: Optional[bool] = True,inverse_depth: bool = False) -> Tuple[torch.Tensor, torch.Tensor]:# Sample along ray from regularly-spaced bins.# Grab samples for space integration along rayt_vals = torch.linspace(0., 1., n_samples, device=rays_o.device)if not inverse_depth:# Sample linearly between `near` and `far`z_vals = near * (1.-t_vals) + far * (t_vals)else:# Sample linearly in inverse depth (disparity)z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))# Draw uniform samples from bins along rayif perturb:mids = .5 * (z_vals[1:] + z_vals[:-1])upper = torch.concat([mids, z_vals[-1:]], dim=-1)lower = torch.concat([z_vals[:1], mids], dim=-1)t_rand = torch.rand([n_samples], device=z_vals.device)z_vals = lower + (upper - lower) * t_randz_vals = z_vals.expand(list(rays_o.shape[:-1]) + [n_samples])# Apply scale from `rays_d` and offset from `rays_o` to samples# pts: (width, height, n_samples, 3)pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :, None]return pts, z_vals
3.5 Pensampelan Isipadu Hierarki (Pensampelan Isipadu Hierarki)
这种“珩磨”过程是通过层次体积采样流程完成的。3D空间实际上非常稀疏,存在遮挡,因此大多数点对渲染图像的贡献不大。因此,对具有对积分贡献可能性高的区域进行过采样(oversample)更有好处。他们将学习到的归一化权重应用于第一组样本,以在光线上创建PDF,然后再将inverse transform sampling应用于该PDF以收集第二组样本。该集合与第一集合相结合,并被馈送到精细网络以产生最终输出。
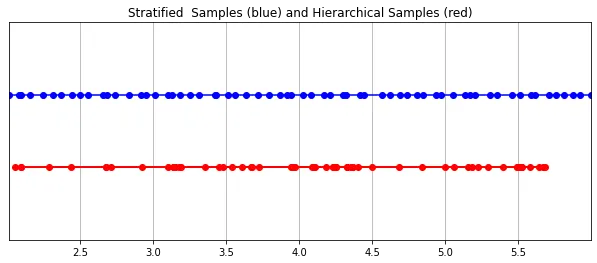
分层采样PyTorch实现:
def sample_hierarchical(rays_o: torch.Tensor,rays_d: torch.Tensor,z_vals: torch.Tensor,weights: torch.Tensor,n_samples: int,perturb: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:# Apply hierarchical sampling to the rays.# Draw samples from PDF using z_vals as bins and weights as probabilities.z_vals_mid = .5 * (z_vals[..., 1:] + z_vals[..., :-1])new_z_samples = sample_pdf(z_vals_mid, weights[..., 1:-1], n_samples, perturb=perturb)new_z_samples = new_z_samples.detach()# Resample points from ray based on PDF.z_vals_combined, _ = torch.sort(torch.cat([z_vals, new_z_samples], dim=-1), dim=-1)# [N_rays, N_samples + n_samples, 3]pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals_combined[..., :, None]return pts, z_vals_combined, new_z_samplesdef sample_pdf(bins: torch.Tensor, weights: torch.Tensor, n_samples: int, perturb: bool = False) -> torch.Tensor:# Apply inverse transform sampling to a weighted set of points.# Normalize weights to get PDF.# [n_rays, weights.shape[-1]]pdf = (weights + 1e-5) / torch.sum(weights + 1e-5, -1, keepdims=True) # Convert PDF to CDF.cdf = torch.cumsum(pdf, dim=-1) # [n_rays, weights.shape[-1]]# [n_rays, weights.shape[-1] + 1]cdf = torch.concat([torch.zeros_like(cdf[..., :1]), cdf], dim=-1) # Take sample positions to grab from CDF. Linear when perturb == 0.if not perturb:u = torch.linspace(0., 1., n_samples, device=cdf.device)u = u.expand(list(cdf.shape[:-1]) + [n_samples]) # [n_rays, n_samples]else:# [n_rays, n_samples]u = torch.rand(list(cdf.shape[:-1]) + [n_samples], device=cdf.device) # Find indices along CDF where values in u would be placed.u = u.contiguous() # Returns contiguous tensor with same values.inds = torch.searchsorted(cdf, u, right=True) # [n_rays, n_samples]# Clamp indices that are out of bounds.below = torch.clamp(inds - 1, min=0)above = torch.clamp(inds, max=cdf.shape[-1] - 1)inds_g = torch.stack([below, above], dim=-1) # [n_rays, n_samples, 2]# Sample from cdf and the corresponding bin centers.matched_shape = list(inds_g.shape[:-1]) + [cdf.shape[-1]]cdf_g = torch.gather(cdf.unsqueeze(-2).expand(matched_shape), dim=-1,index=inds_g)bins_g = torch.gather(bins.unsqueeze(-2).expand(matched_shape), dim=-1, index=inds_g)# Convert samples to ray length.denom = (cdf_g[..., 1] - cdf_g[..., 0])denom = torch.where(denom <h3>4 Training</h3><p>论文中训练NeRF推荐的每网络8层、每层256维的架构在训练过程中会消耗大量内存。缓解这种情况的方法是将前传(forward pass)分成更小的部分,然后在这些部分上积累梯度。注意与minibatching的区别:梯度是在采样光线的单个小批次上累积的,这些光线可能已经被收集成块。如果没有论文中使用的NVIDIA V100类似性能的GPU,可能必须相应地调整块大小以避免OOM错误。Colab笔记本采用了更小的架构和更适中的分块尺寸。</p><p>我个人发现,由于局部极小值,即使选择了许多默认值,NeRF的训练也有些棘手。一些有帮助的技术包括早期训练迭代和早期重新启动期间的中心裁剪(center cropping)。随意尝试不同的超参数和技术,以进一步提高训练收敛性。</p><h4>初始化</h4><pre class="brush:php;toolbar:false">def init_models():# Initialize models, encoders, and optimizer for NeRF training.encoder = PositionalEncoder(d_input, n_freqs, log_space=log_space)encode = lambda x: encoder(x)# View direction encodersif use_viewdirs:encoder_viewdirs = PositionalEncoder(d_input, n_freqs_views,log_space=log_space)encode_viewdirs= lambda x: encoder_viewdirs(x)d_viewdirs = encoder_viewdirs.d_outputelse:encode_viewdirs = Noned_viewdirs = Nonemodel = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)model.to(device)model_params = list(model.parameters())if use_fine_model:fine_model = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)fine_model.to(device)model_params = model_params + list(fine_model.parameters())else:fine_model = Noneoptimizer= torch.optim.Adam(model_params, lr=lr)warmup_stopper = EarlyStopping(patience=50)return model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper
def train():# Launch training session for NeRF.# Shuffle rays across all images.if not one_image_per_step:height, width = images.shape[1:3]all_rays = torch.stack([torch.stack(get_rays(height, width, focal, p), 0) for p in poses[:n_training]], 0)rays_rgb = torch.cat([all_rays, images[:, None]], 1)rays_rgb = torch.permute(rays_rgb, [0, 2, 3, 1, 4])rays_rgb = rays_rgb.reshape([-1, 3, 3])rays_rgb = rays_rgb.type(torch.float32)rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0train_psnrs = []val_psnrs = []iternums = []for i in trange(n_iters):model.train()if one_image_per_step:# Randomly pick an image as the target.target_img_idx = np.random.randint(images.shape[0])target_img = images[target_img_idx].to(device)if center_crop and i = rays_rgb.shape[0]:rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0target_img = target_img.reshape([-1, 3])# Run one iteration of TinyNeRF and get the rendered RGB image.outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)# Backprop!rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, target_img)loss.backward()optimizer.step()optimizer.zero_grad()psnr = -10. * torch.log10(loss)train_psnrs.append(psnr.item())# Evaluate testimg at given display rate.if i % display_rate == 0:model.eval()height, width = testimg.shape[:2]rays_o, rays_d = get_rays(height, width, focal, testpose)rays_o = rays_o.reshape([-1, 3])rays_d = rays_d.reshape([-1, 3])outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, testimg.reshape(-1, 3))val_psnr = -10. * torch.log10(loss)val_psnrs.append(val_psnr.item())iternums.append(i)# Check PSNR for issues and stop if any are found.if i == warmup_iters - 1:if val_psnr <h4>训练</h4><pre class="brush:php;toolbar:false"># Run training session(s)for _ in range(n_restarts):model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper = init_models()success, train_psnrs, val_psnrs = train()if success and val_psnrs[-1] >= warmup_min_fitness:print('Training successful!')breakprint(f'Done!')辐射场标志着处理3D数据的方式发生了巨大变化。NeRF模型和更广泛的可微分渲染正在迅速弥合图像创建和体积场景创建之间的差距。虽然我们的组件可能看起来非常复杂,但受vanilla NeRF启发的无数其他方法证明,基本概念(连续函数逼近器+可微分渲染器)是构建各种解决方案的坚实基础,这些解决方案可用于几乎无限的情况。
原文:NeRF From Nothing: A Tutorial with PyTorch | Towards Data Science
原文链接:https://mp.weixin.qq.com/s/zxJAIpAmLgsIuTsPqQqOVg
Atas ialah kandungan terperinci Apakah itu NeRF? Adakah pembinaan semula 3D berasaskan NeRF berasaskan voxel?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah itu Bitcoin Futures ETF?
Apakah itu Bitcoin Futures ETF?
 matematik.penggunaan fungsi rawak
matematik.penggunaan fungsi rawak
 Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
 Apakah perisian ujian dalam talian prestasi komputer?
Apakah perisian ujian dalam talian prestasi komputer?
 kalau apa maksudnya
kalau apa maksudnya
 Gambar rajah topologi rangkaian
Gambar rajah topologi rangkaian
 Apakah kekunci yang dirujuk oleh anak panah dalam komputer?
Apakah kekunci yang dirujuk oleh anak panah dalam komputer?
 menu konteks
menu konteks








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



