


. (malapetaka melupakan) . Perbezaan antara pembelajaran berterusan dan pembelajaran pelbagai tugas ialah yang kedua boleh mendapatkan semua tugas pada masa yang sama, dan model boleh mempelajari semua tugas pada masa yang sama manakala dalam pembelajaran berterusan, tugasan muncul satu demi satu, dan model boleh hanya Belajar ilmu tentang sesuatu tugasan dan elakkan melupakan ilmu lama dalam proses mempelajari ilmu baru.
Universiti California Selatan dan Penyelidikan Google telah mencadangkan kaedah baharu untuk menyelesaikan pembelajaran berterusan
Pemrograman Semula Ringan (CLR) Bijak Saluran: Dengan menambahkan modul ringan yang boleh dilatih tanpa perubahan kepada tulang belakang tetap , peta ciri setiap lapisan saluran diprogramkan semula, menjadikan peta ciri yang diprogramkan semula sesuai untuk tugasan baharu. Modul ringan yang boleh dilatih ini hanya menyumbang 0.6% daripada keseluruhan tulang belakang Setiap tugasan baharu boleh mempunyai modul ringannya sendiri Secara teorinya, tugasan baharu yang tidak terhingga boleh dipelajari secara berterusan tanpa melupakan bencana. Kertas itu telah diterbitkan dalam ICCV 2023.

Kaedah berdasarkan regularisasi ialah model menambah sekatan pada kemas kini parameter semasa proses mempelajari tugasan baharu dan menyatukan pengetahuan lama sambil mempelajari pengetahuan baharu.
Motivasi penyelidikan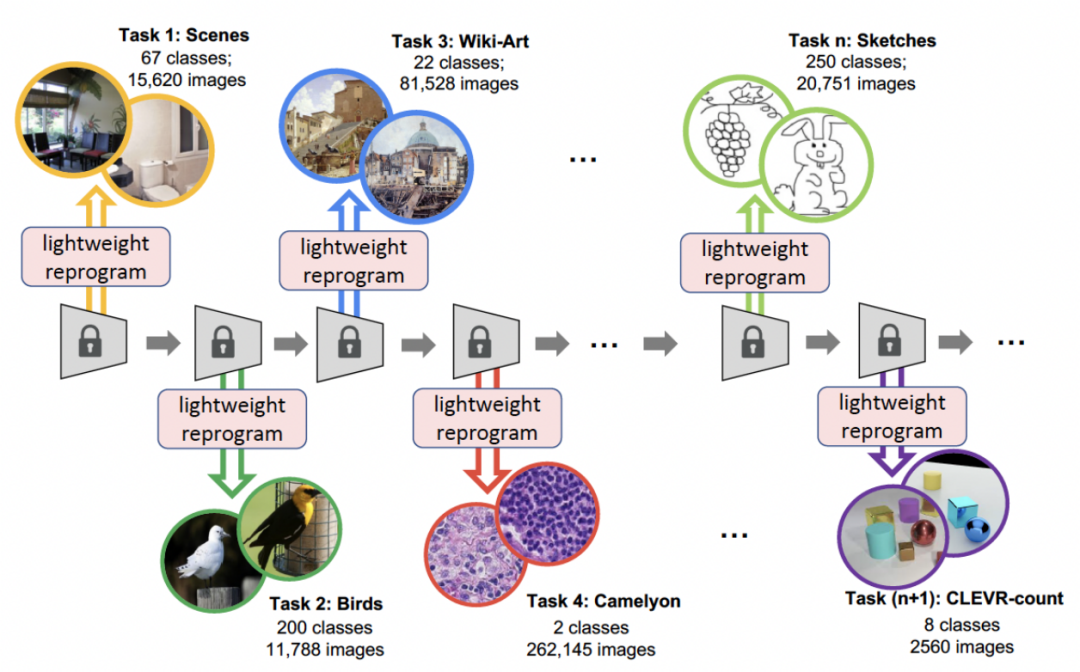
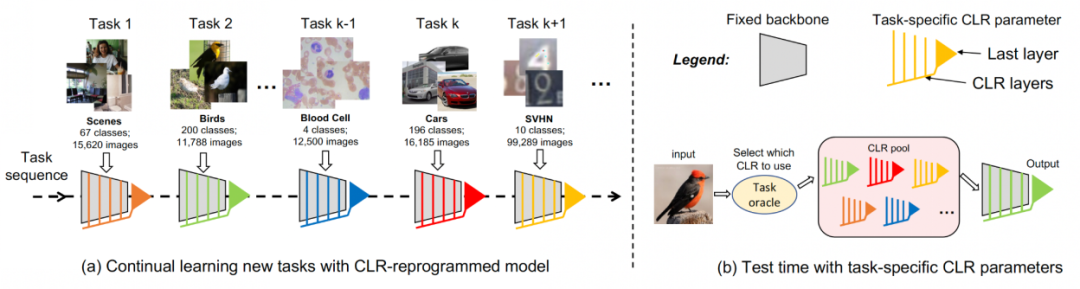
##-#Channel ringan gaya #Pertama gunakan tulang belakang tetap sebagai struktur perkongsian tugas, yang boleh menjadi pra-latihan untuk pembelajaran diselia pada set data yang agak pelbagai (ImageNet-1k, Pascal VOC) Model ini juga boleh model pembelajaran penyeliaan sendiri (DINO, SwAV) yang belajar mengenai tugas ejen tanpa label semantik. Berbeza daripada kaedah pembelajaran berterusan yang lain (seperti SUPSUP menggunakan struktur tetap yang dimulakan secara rawak, CCLL dan EFT menggunakan model yang dipelajari daripada tugas pertama sebagai tulang belakang), model pra-latihan yang digunakan oleh CLR boleh menyediakan pelbagai ciri visual, tetapi ini ciri visual Ciri memerlukan lapisan CLR untuk pengekodan semula pada tugasan lain. Khususnya, penyelidik menggunakantransformasi linear mengikut saluranuntuk mengekod semula imej ciri yang dijana oleh kernel lilitan asal.
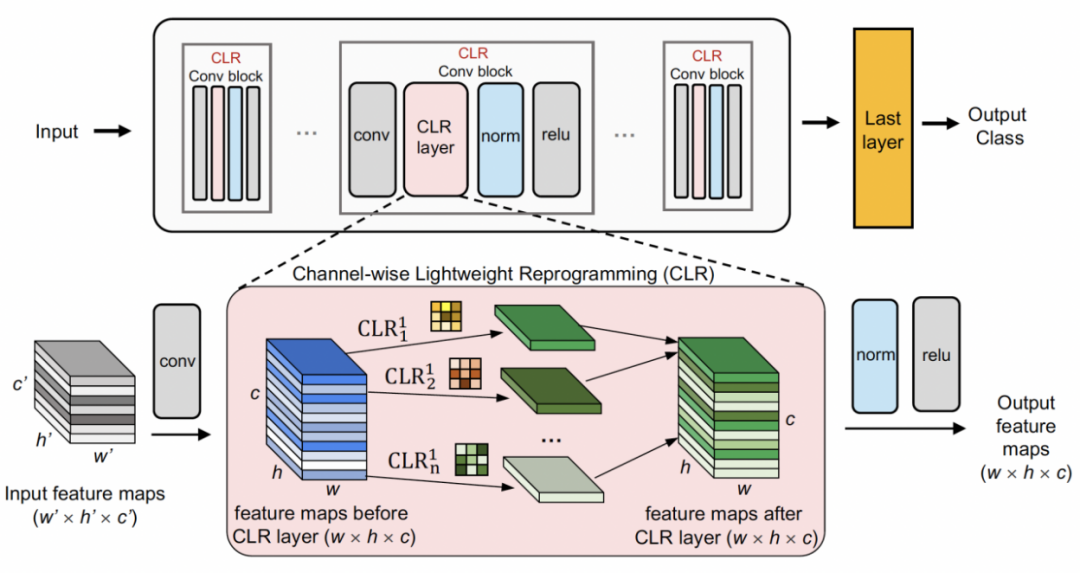
Penyelidik mula-mula membetulkan tulang belakang pra-latihan, dan kemudian menambah lapisan pengaturcaraan semula ringan jenis saluran selepas lapisan lilitan dalam setiap blok lilitan tetap ( lapisan CLR) ke melakukan perubahan linear seperti saluran pada peta ciri selepas kernel lilitan tetap.
Diberi gambar X, untuk setiap kernel lilitan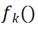 , kita boleh mendapatkan peta ciri Untuk menukar secara linear setiap saluran Penyelidik memulakanCLR konvolusi kernel kepada yang sama bertukar kernel (iaitu, untuk 2D convolution kernel, hanya parameter tengah ialah 1, dan selebihnya adalah 0),
, kita boleh mendapatkan peta ciri Untuk menukar secara linear setiap saluran Penyelidik memulakanCLR konvolusi kernel kepada yang sama bertukar kernel (iaitu, untuk 2D convolution kernel, hanya parameter tengah ialah 1, dan selebihnya adalah 0),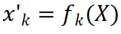 kerana ini boleh menjadikan tulang belakang tetap asal dijana semasa permulaan latihan Ciri-ciri adalah sama seperti yang dihasilkan oleh model selepas menambah lapisan CLR. Pada masa yang sama, untuk menyimpan parameter dan mengelakkan pemasangan berlebihan, penyelidik tidak akan menambah lapisan CLR selepas kernel lilitan Lapisan CLR hanya akan bertindak selepas kernel lilitan. Untuk ResNet50 selepas CLR, parameter boleh dilatih yang meningkat hanya menyumbang 0.59% berbanding tulang belakang ResNet50 tetap.
kerana ini boleh menjadikan tulang belakang tetap asal dijana semasa permulaan latihan Ciri-ciri adalah sama seperti yang dihasilkan oleh model selepas menambah lapisan CLR. Pada masa yang sama, untuk menyimpan parameter dan mengelakkan pemasangan berlebihan, penyelidik tidak akan menambah lapisan CLR selepas kernel lilitan Lapisan CLR hanya akan bertindak selepas kernel lilitan. Untuk ResNet50 selepas CLR, parameter boleh dilatih yang meningkat hanya menyumbang 0.59% berbanding tulang belakang ResNet50 tetap.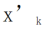
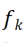 Untuk pembelajaran berterusan, model yang menambah parameter CLR boleh dilatih dan tulang belakang yang tidak boleh dilatih boleh mempelajari setiap tugas secara bergilir-gilir. Semasa menguji, penyelidik menganggap bahawa terdapat peramal tugas yang boleh memberitahu model tugas mana yang dimiliki oleh imej ujian, dan kemudian tulang belakang tetap dan parameter CLR khusus tugasan yang sepadan boleh membuat ramalan akhir. Memandangkan CLR mempunyai ciri pengasingan parameter mutlak (parameter lapisan CLR yang sepadan dengan setiap tugas adalah berbeza, dan tulang belakang yang dikongsi tidak akan berubah), CLR tidak akan terjejas oleh bilangan tugas
Untuk pembelajaran berterusan, model yang menambah parameter CLR boleh dilatih dan tulang belakang yang tidak boleh dilatih boleh mempelajari setiap tugas secara bergilir-gilir. Semasa menguji, penyelidik menganggap bahawa terdapat peramal tugas yang boleh memberitahu model tugas mana yang dimiliki oleh imej ujian, dan kemudian tulang belakang tetap dan parameter CLR khusus tugasan yang sepadan boleh membuat ramalan akhir. Memandangkan CLR mempunyai ciri pengasingan parameter mutlak (parameter lapisan CLR yang sepadan dengan setiap tugas adalah berbeza, dan tulang belakang yang dikongsi tidak akan berubah), CLR tidak akan terjejas oleh bilangan tugas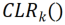 Hasil eksperimen
Hasil eksperimen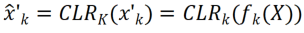 Set Data: Para penyelidik menggunakan klasifikasi imej sebagai tugas utama Makmal mengumpul 53 set data klasifikasi imej, dengan kira-kira 1.8 juta imej dan 1584 kategori. 53 set data ini mengandungi 5 matlamat klasifikasi berbeza: pengecaman objek, klasifikasi gaya, klasifikasi pemandangan, pengiraan dan diagnosis perubatan.
Set Data: Para penyelidik menggunakan klasifikasi imej sebagai tugas utama Makmal mengumpul 53 set data klasifikasi imej, dengan kira-kira 1.8 juta imej dan 1584 kategori. 53 set data ini mengandungi 5 matlamat klasifikasi berbeza: pengecaman objek, klasifikasi gaya, klasifikasi pemandangan, pengiraan dan diagnosis perubatan.
 Para penyelidik memilih 13 garis dasar, yang boleh dibahagikan secara kasar kepada 3 kategori
Para penyelidik memilih 13 garis dasar, yang boleh dibahagikan secara kasar kepada 3 kategori
Rangkaian dinamik: PSP, SupSup, CCLL, Confit, EFTs
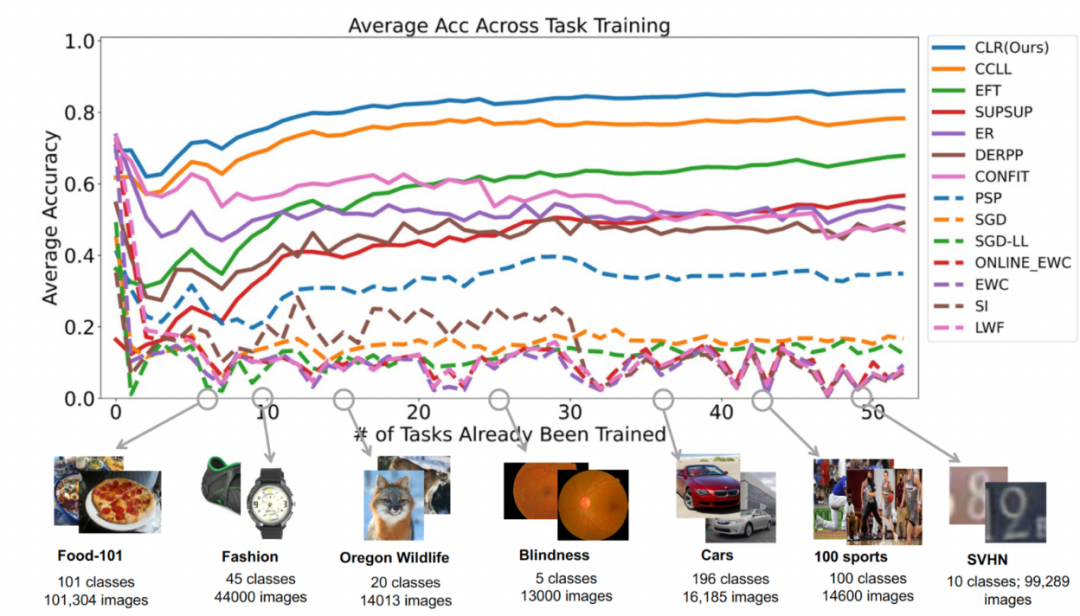
Percubaan kedua: purata pembelajaran ketepatan selepas menyelesaikan semua tugasan
Rajah di bawah menunjukkan ketepatan purata semua kaedah selepas mempelajari semua tugasan. Ketepatan purata mencerminkan prestasi keseluruhan kaedah pembelajaran berterusan. Memandangkan setiap tugasan mempunyai tahap kesukaran yang berbeza, apabila tugasan baharu ditambah, ketepatan purata merentas semua tugasan mungkin meningkat atau menurun, bergantung pada sama ada tugasan tambahan itu mudah atau sukar.
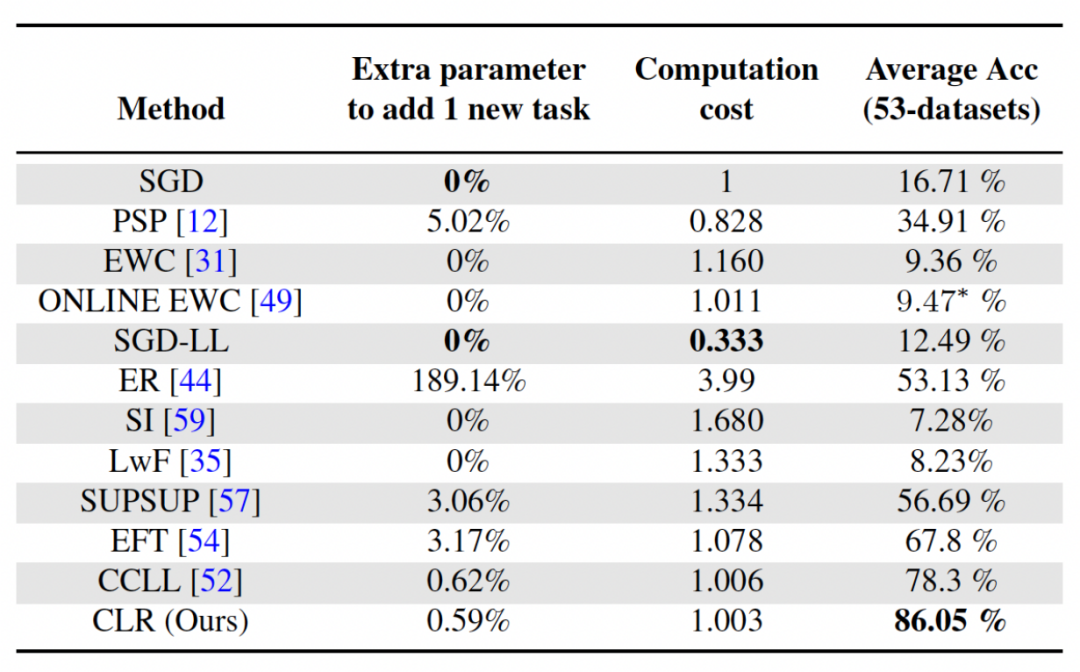
Pertama, mari analisa parameter dan kos pengiraan
Untuk pembelajaran berterusan, walaupun sangat penting untuk mendapatkan ketepatan purata yang lebih tinggi, algoritma tambahan yang baik juga berharap untuk memaksimumkan keperluan parameter rangkaian dan kos pengiraan. "Tambah parameter tambahan untuk tugas baharu" mewakili peratusan amaun parameter tulang belakang asal. Artikel ini menggunakan kos pengiraan SGD sebagai unit, dan kos pengiraan kaedah lain dinormalisasi mengikut kos SGD.
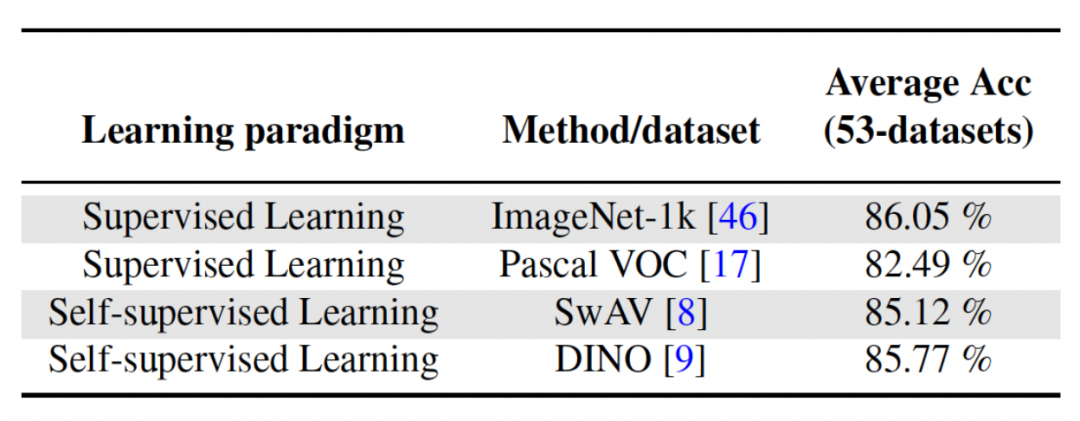
Kandungan yang ditulis: Analisis kesan rangkaian backbone yang berlainan
Kaedah dalam artikel ini melatih model pra-terlatih dengan menggunakan pembelajaran yang diselia atau pembelajaran diri yang diselia pada set data yang agak pelbagai sebagai parameter invarian bebas daripada tugas. Untuk meneroka kesan kaedah pra-latihan yang berbeza, kertas kerja ini memilih empat model pra-latihan bebas tugas yang berbeza yang dilatih menggunakan set data dan tugasan yang berbeza. Untuk pembelajaran diselia, penyelidik menggunakan model pra-latihan pada ImageNet-1k dan Pascal-VOC untuk klasifikasi imej untuk pembelajaran penyeliaan kendiri, penyelidik menggunakan model pra-latihan yang diperoleh melalui dua kaedah berbeza, DINO dan SwAV. Jadual berikut menunjukkan ketepatan purata model pra-latihan menggunakan empat kaedah yang berbeza Dapat dilihat bahawa keputusan akhir mana-mana kaedah adalah sangat tinggi (Nota: Pascal-VOC adalah set data yang agak kecil, jadi ketepatannya secara relatif. rendah. titik) dan teguh kepada tulang belakang pra-terlatih yang berbeza.
Atas ialah kandungan terperinci Optimumkan kecekapan pembelajaran: pindahkan model lama kepada tugas baharu dengan 0.6% parameter tambahan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana pycharm menjalankan fail python
Bagaimana pycharm menjalankan fail python Bagaimana untuk mendaftar di Binance
Bagaimana untuk mendaftar di Binance Tiga kaedah pencetus pencetus sql
Tiga kaedah pencetus pencetus sql Penyelesaian ralat AccessDenied
Penyelesaian ralat AccessDenied Senarai lengkap kekunci pintasan idea
Senarai lengkap kekunci pintasan idea Penyelesaian kepada ralat failedtofetch
Penyelesaian kepada ralat failedtofetch penggunaan fungsi griddata matlab
penggunaan fungsi griddata matlab Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej
Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



