


Builder News pada 12 Oktober, baru-baru ini, Zhipu AI & Tsinghua KEG mengeluarkan dan sumber terbuka secara langsung model besar berbilang mod-CogVLM-17B dalam komuniti Moda. Dilaporkan bahawa CogVLM ialah model bahasa visual sumber terbuka yang berkuasa yang menggunakan modul pakar visual untuk menyepadukan pengekodan bahasa dan pengekodan visual secara mendalam, dan telah mencapai prestasi SOTA pada 14 penanda aras silang modal yang berwibawa.
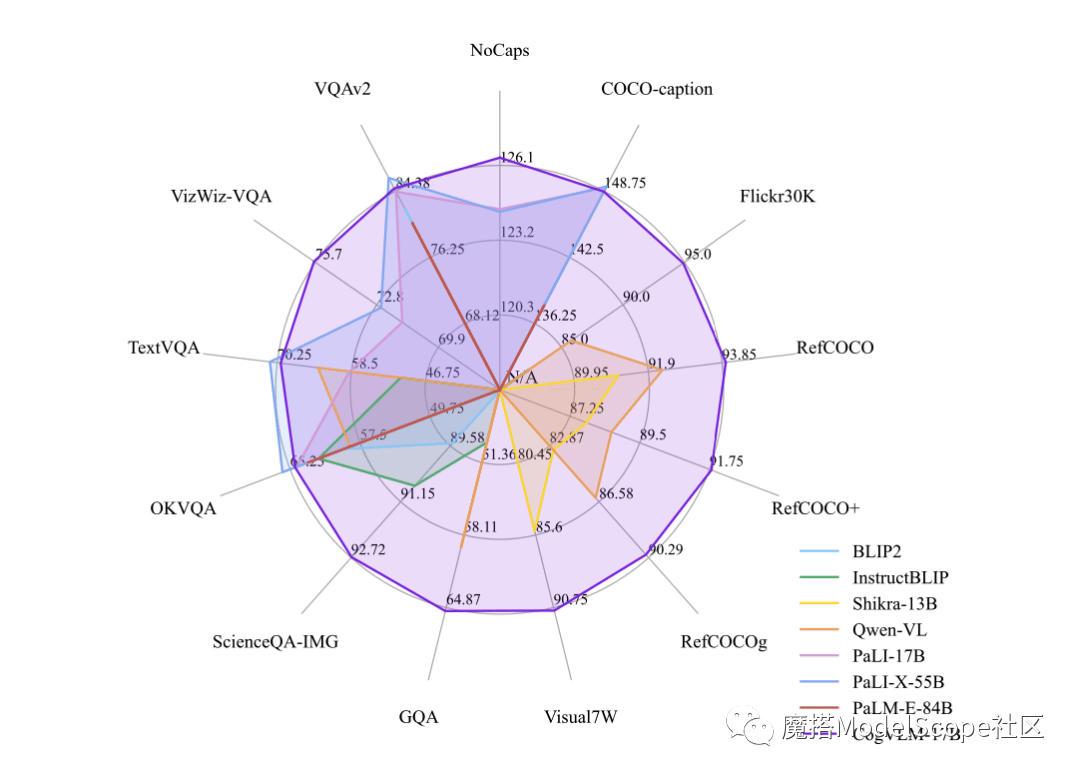
CogVLM-17B kini merupakan model dengan prestasi komprehensif pertama dalam senarai akademik berwibawa berbilang modal, dan telah mencapai keputusan tempat paling maju atau kedua pada 14 set data. Kesan CogVLM bergantung pada idea "keutamaan visual", iaitu, memberikan pemahaman visual keutamaan yang lebih tinggi dalam model berbilang modal. Ia menggunakan pengekod visual parameter 5B dan modul pakar visual parameter 6B, dengan jumlah parameter 11B untuk memodelkan ciri imej, malah lebih daripada parameter 7B teks
Atas ialah kandungan terperinci Zhipu AI bekerjasama dengan Tsinghua KEG untuk mengeluarkan model besar berbilang modal sumber terbuka yang dipanggil CogVLM-17B. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Berapakah Snapdragon 8gen2 yang setara dengan Apple?
Berapakah Snapdragon 8gen2 yang setara dengan Apple?
 Bagaimana untuk menyelesaikan ralat aplikasi WerFault.exe
Bagaimana untuk menyelesaikan ralat aplikasi WerFault.exe
 susun atur mutlak
susun atur mutlak
 Mongodb dan mysql mudah digunakan dan disyorkan
Mongodb dan mysql mudah digunakan dan disyorkan
 penggunaan format_nombor
penggunaan format_nombor
 rgb kepada penukaran heksadesimal
rgb kepada penukaran heksadesimal
 Cara membuat carta dan carta analisis data dalam PPT
Cara membuat carta dan carta analisis data dalam PPT
 Apakah perpustakaan pihak ketiga yang biasa digunakan dalam PHP?
Apakah perpustakaan pihak ketiga yang biasa digunakan dalam PHP?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



