


Kini, model rangkaian saraf gergasi seperti GPT-4 dan PaLM telah muncul, dan mereka telah menunjukkan keupayaan pembelajaran beberapa sampel yang menakjubkan.
Hanya diberi gesaan mudah, mereka boleh melakukan penaakulan teks, menulis cerita, menjawab soalan, program...
Penyelidik dari Akademi Sains China dan Universiti Yale telah mencadangkan rangka kerja baharu , dinamakan "Penyebaran Pemikiran" , bertujuan untuk meningkatkan keupayaan penaakulan LLM melalui "pemikiran analog"

Alamat kertas: https://arxiv.org/abs/2310.03965
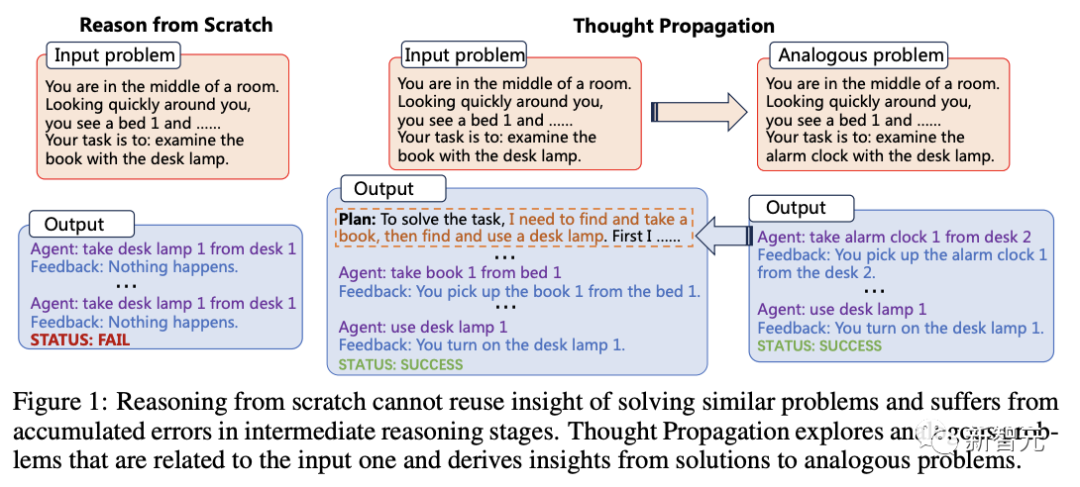
"Komunikasi yang difikirkan oleh manusia" adalah ingnition ialah apabila kita menghadapi masalah baru, kita sering membandingkannya dengan masalah serupa yang telah kita selesaikan untuk mendapatkan strategi.
Jadi kunci kepada pendekatan ini adalah untuk meneroka masalah "serupa" yang berkaitan dengan input sebelum menyelesaikan masalah input
Akhirnya, penyelesaian mereka boleh digunakan di luar kotak, atau untuk mengeluarkan cerapan untuk perancangan yang berguna.
Adalah boleh dijangka bahawa "komunikasi pemikiran" mencadangkan idea baharu untuk batasan yang wujud dalam keupayaan logik LLM, membolehkan model besar menggunakan "analogi" untuk menyelesaikan masalah seperti manusia.
Jelas sekali, LLM pandai membuat penaakulan asas berdasarkan gesaan, tetapi ia masih menghadapi kesukaran apabila menangani masalah pelbagai langkah yang kompleks, seperti pengoptimuman dan perancangan.
Sebaliknya, manusia akan mengambil intuisi daripada pengalaman yang sama untuk menyelesaikan masalah baharu.
Ketidakupayaan model besar untuk mencapai ini adalah disebabkan oleh batasan yang wujud
Oleh kerana pengetahuan LLM datang sepenuhnya daripada corak dalam data latihan dan tidak dapat benar-benar memahami bahasa atau konsep. Oleh itu, sebagai model statistik, mereka sukar untuk melakukan generalisasi gabungan yang kompleks.
LLM tidak mempunyai keupayaan penaakulan yang sistematik dan tidak boleh menaakul langkah demi langkah seperti manusia untuk menyelesaikan masalah yang mencabar, yang paling penting
Selain itu, memandangkan penaakulan model besar adalah separa, pandangan pendek. jadi sukar bagi LLM untuk mencari penyelesaian terbaik, dan sukar untuk mengekalkan ketekalan penaakulan dalam jangka masa yang panjang
Ringkasnya, masalah model besar dalam pembuktian matematik, perancangan strategik dan penaakulan logik terutamanya boleh dikaitkan dengan Dua faktor teras:
- Ketidakupayaan untuk menggunakan semula cerapan daripada pengalaman terdahulu.
Manusia mengumpul pengetahuan dan intuisi yang boleh diguna semula daripada amalan, yang membantu menyelesaikan masalah baharu. Sebaliknya, LLM mendekati setiap masalah "dari awal" dan tidak meminjam daripada penyelesaian sebelumnya.
Ralat kompaun dalam penaakulan pelbagai langkah merujuk kepada kesilapan yang berlaku semasa penaakulan pelbagai langkah
Manusia memantau rantaian penaakulan mereka sendiri dan mengubah suai langkah awal apabila perlu. Walau bagaimanapun, kesilapan yang dilakukan oleh LLM pada peringkat awal penaakulan akan diperkuatkan kerana ia akan membawa penaakulan seterusnya ke arah yang salah Kelemahan di atas secara serius menghalang LLM daripada menangani masalah kompleks yang memerlukan pengoptimuman global atau perancangan jangka panjang .
Penyelidik telah mencadangkan satu penyelesaian serba baharu untuk masalah ini, iaitu penyebaran pemikiran
Rangka kerja TP
untuk menggunakan semula cerapan daripada menyelesaikan masalah yang serupa, dan ralat terkumpul dalam peringkat penaakulan pertengahan.
Dan "Thought Spread" boleh meneroka masalah yang sama berkaitan dengan masalah input dan mendapat inspirasi daripada penyelesaian kepada masalah yang serupa.
Rajah di bawah menunjukkan perbandingan antara "Penyebaran Pemikiran" (TP) dan teknologi perwakilan lain. Untuk masalah input p, IO, CoT dan ToT semua perlu membuat alasan dari awal untuk mencapai penyelesaian s
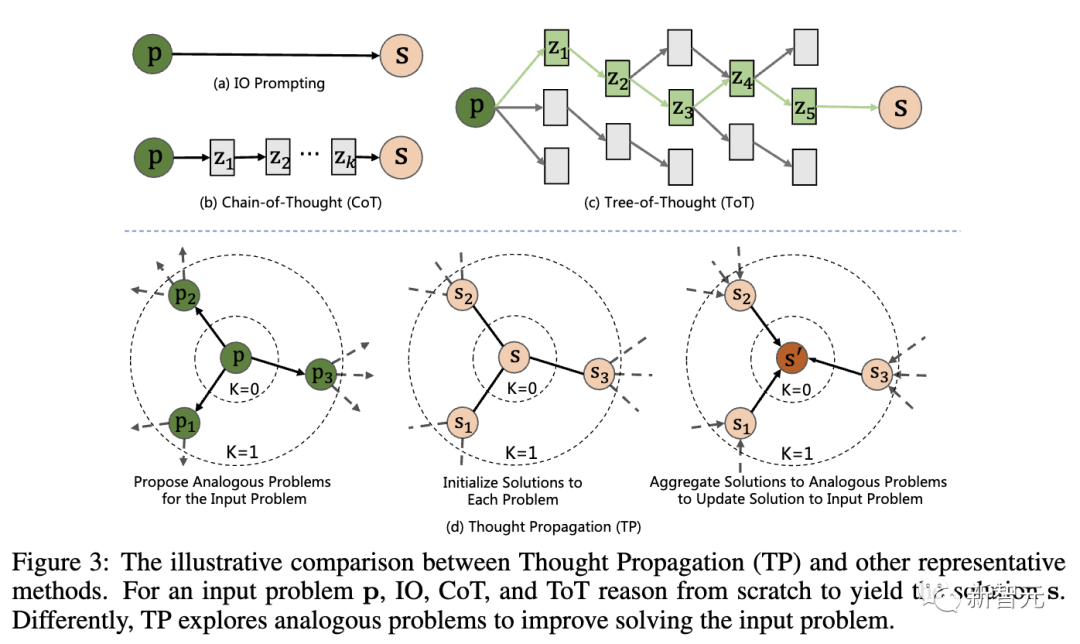
Secara khusus, TP merangkumi tiga peringkat:
1 LLM menjana satu set soalan yang serupa melalui gesaan yang mempunyai persamaan dengan soalan input. Ini akan membimbing model untuk mendapatkan semula pengalaman terdahulu yang berpotensi berkaitan.
2. Selesaikan masalah yang serupa: Biarkan LLM menyelesaikan setiap masalah yang serupa melalui teknologi dorongan sedia ada, seperti CoT.
3. Penyelesaian ringkasan: Terdapat 2 cara berbeza - membuat kesimpulan secara langsung penyelesaian baharu kepada masalah input berdasarkan penyelesaian yang serupa;
Dengan cara ini, model besar boleh memanfaatkan pengalaman dan heuristik terdahulu, dan penaakulan awal mereka boleh disemak silang dengan penyelesaian analog untuk memperhalusi lagi penyelesaian tersebut
Perlu disebut , "Penyebaran pemikiran" tiada kaitan dengan model, dan boleh melakukan satu langkah penyelesaian masalah berdasarkan mana-mana kaedah segera
Keunikan kaedah ini adalah untuk merangsang pemikiran analogi LLM, dengan itu membimbing proses penaakulan yang kompleks
"Berfikir "Komunikasi" boleh menjadikan LLM lebih seperti manusia, tetapi keputusan sebenar perlu bercakap untuk diri mereka sendiri.
Penyelidik dari Chinese Academy of Sciences dan Yale menilai dalam 3 tugasan:
- Penaakulan laluan terpendek: Perlu mencari laluan terbaik antara nod dalam perancangan dan graf global yang memerlukan. Walaupun pada graf mudah, teknik standard gagal.
- Penulisan Kreatif: Menjana cerita yang koheren dan kreatif ialah cabaran yang terbuka. Apabila diberikan gesaan garis besar peringkat tinggi, LLM sering kehilangan konsistensi atau logik.
- Perancangan Ejen LLM: Ejen LLM yang berinteraksi dengan persekitaran teks bergelut dengan strategi jangka panjang. Rancangan mereka sering "hanyut" atau terperangkap dalam kitaran.
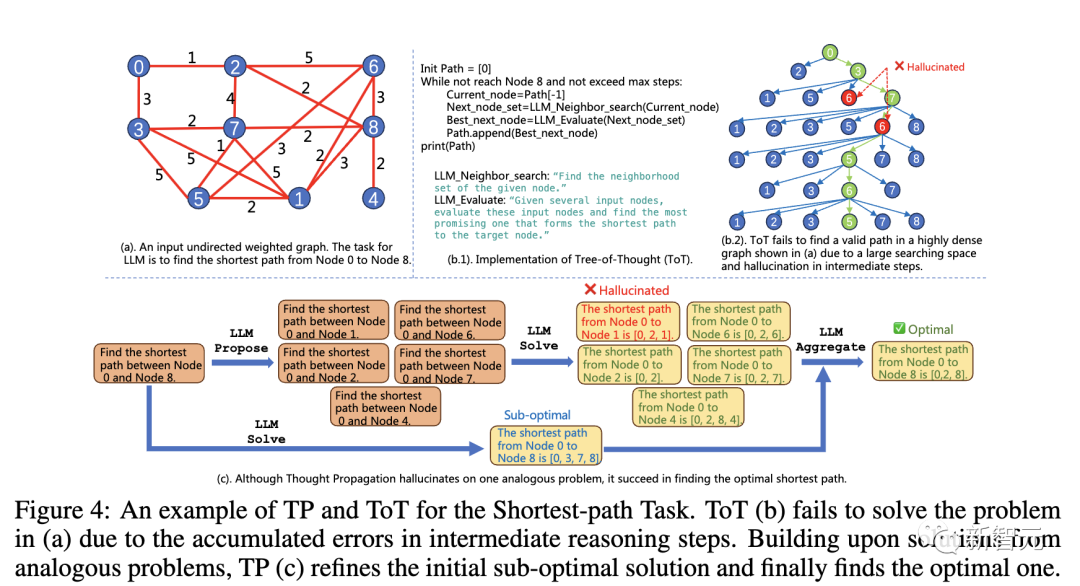
Dalam tugasan inferens laluan terpendek, kaedah sedia ada menghadapi masalah yang tidak dapat diselesaikan
Walaupun graf dalam (a) adalah sangat mudah, kerana inferens ini bermula dari 0 sahaja, benarkan LLM mencari penyelesaian suboptimum (b,c), atau malah berulang kali melawati nod perantaraan (d)

Berikut ialah contoh yang menggabungkan penggunaan TP dan ToT
Disebabkan perantaraan langkah inferens Ralat terkumpul dan ToT (b) gagal menyelesaikan masalah di (a). Berdasarkan penyelesaian kepada masalah yang serupa, TP (c) memperhalusi penyelesaian suboptimum awal dan akhirnya mencari penyelesaian optimum.
Berbanding dengan garis dasar, prestasi TP dalam memproses tugas laluan terpendek telah dipertingkatkan dengan ketara sebanyak 12%, menjana laluan terpendek yang optimum dan berkesan.
Di samping itu, disebabkan nilai penulisan semula dalam talian (OLR) yang paling rendah, laluan berkesan (TP) yang dijana adalah paling hampir dengan laluan optimum berbanding garis dasar
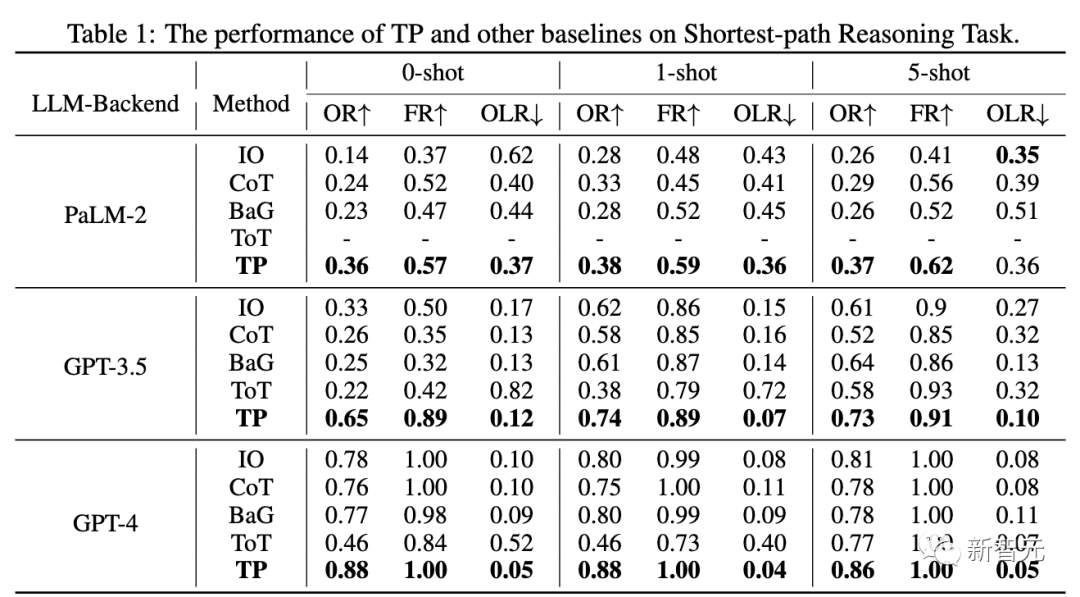
Selain itu, penyelidik juga melakukan Beberapa kajian lanjut telah dijalankan ke atas kerumitan dan prestasi tugas laluan terpendek
Di bawah tetapan berbeza, kos token lapisan 1 TP adalah serupa dengan ToT. Walau bagaimanapun, Lapisan 1 TP telah mencapai prestasi yang sangat kompetitif dalam mencari laluan terpendek yang optimum.
Selain itu, berbanding dengan lapisan 0 TP (IO), peningkatan prestasi lapisan 1 TP juga sangat ketara. Rajah 5(a) menunjukkan peningkatan kos token untuk lapisan 2 TP.
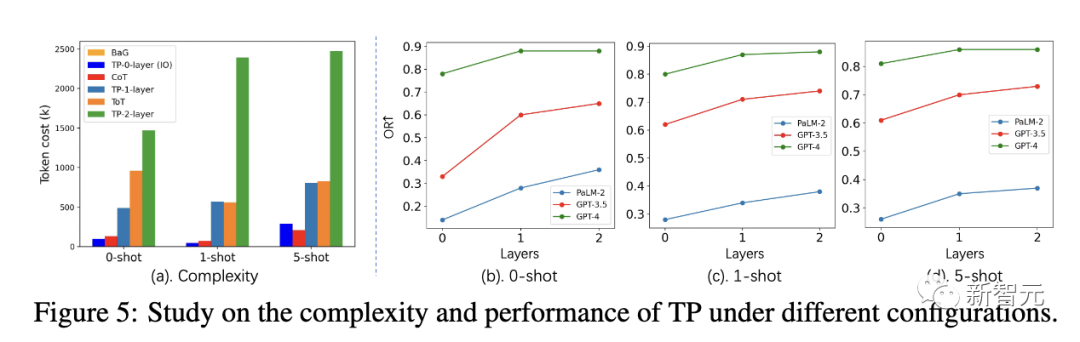
Jadual 2 di bawah menunjukkan prestasi TP dan garis dasar dalam GPT-3.5 dan GPT-4. Dari segi konsistensi, TP melebihi garis dasar. Selain itu, dalam kajian pengguna, TP meningkatkan keutamaan manusia dalam penulisan kreatif sebanyak 13%.
Dalam penilaian tugasan ketiga, para penyelidik menggunakan suite permainan ALFWorld untuk melaksanakan tugas perancangan ejen LLM dalam 134 persekitaran.
TP meningkatkan kadar penyiapan tugas sebanyak 15% dalam perancangan ejen LLM. Ini menunjukkan keunggulan TP reflektif untuk perancangan yang berjaya apabila menyelesaikan tugasan yang serupa.

Menurut keputusan eksperimen di atas, ditunjukkan bahawa "Penyebaran Berfikir" boleh digunakan untuk pelbagai tugas penaakulan yang berbeza dan berfungsi dengan baik dalam semua tugasan ini
"Berfikir Model "propagasi" menyediakan teknologi baharu untuk inferens LLM yang kompleks.
Pemikiran analogi adalah tanda keupayaan manusia menyelesaikan masalah Ia boleh membawa satu siri kelebihan sistematik, seperti pencarian dan pembetulan ralat yang lebih cekap
Dalam situasi yang sama, LLM juga boleh mendorong pemikiran analogi untuk mengatasi dengan lebih baik. kelemahan mereka sendiri, seperti kekurangan pengetahuan yang boleh diguna semula dan ralat tempatan yang melata, dsb.
Walau bagaimanapun, penemuan ini mempunyai beberapa batasan
Jana soalan analogi yang berguna dan pastikan laluan penaakulan mudah dan Tidak mudah. Selain itu, laluan penaakulan analogi berantai yang lebih panjang boleh menjadi panjang dan sukar untuk diikuti. Pada masa yang sama, mengawal dan menyelaras rantaian penaakulan pelbagai langkah juga merupakan tugas yang agak sukar
Walau bagaimanapun, "penyebaran pemikiran" masih memberikan kita kaedah yang menarik dengan menyelesaikan kelemahan penaakulan LLM secara kreatif.
Dengan perkembangan selanjutnya, pemikiran analogi mungkin menjadikan keupayaan penaakulan LLM lebih berkuasa. Ini juga menunjukkan cara untuk mencapai matlamat yang lebih dekat dengan penaakulan manusia dalam model bahasa yang besar

pengkaji dalam corak kebangsaan. di Institut Automasi, Akademi Sains Cina Seorang profesor di makmal dan Akademi Sains Universiti Cina, beliau juga merupakan Felo IAPR dan ahli kanan IEEE
Beliau sebelum ini menerima ijazah sarjana muda dan sarjana dari Dalian Universiti Teknologi dan PhD beliau daripada Institut Automasi, Akademi Sains China pada tahun 2009
Arahan penyelidikannya ialah algoritma biometrik (pengecaman muka dan sintesis, pengecaman iris, pengenalan semula orang), pembelajaran perwakilan (menggunakan lemah/diri sendiri -pembelajaran diselia atau pemindahan rangkaian pra-latihan), pembelajaran generatif (model generatif, penjanaan imej, terjemahan imej).
Beliau telah menerbitkan lebih daripada 200 kertas kerja dalam jurnal dan persidangan antarabangsa, termasuk jurnal antarabangsa terkenal seperti IEEE TPAMI, TIP IEEE, IEEE TIFS, IEEE TNN, IEEE TCSVT, dan jurnal antarabangsa terkemuka seperti CVPR, ICCV, Persidangan ECCV, NeurIPS, dsb. ICPR dan IJCAI

Yu Junchi ialah pelajar kedoktoran tahun empat di Institut Automasi, Akademi Sains China Penyelianya ialah Profesor Heran
Beliau. pernah bekerja di Tencent Artificial Intelligence Experiment Saya telah menjalani latihan di makmal dan bekerja dengan Dr. Tingyang Xu, Dr. Yu Rong, Dr. Yatao Bian dan Profesor Junzhou Huang. Kini, beliau adalah pelajar pertukaran di Jabatan Sains Komputer di Universiti Yale, belajar di bawah Profesor Rex Ying
Matlamatnya adalah untuk membangunkan sistem dengan kebolehtafsiran dan mudah alih yang baik Kaedah Pembelajaran Graf yang Boleh Dipercayai (TwGL) dan teroka aplikasinya dalam bidang biokimia
Atas ialah kandungan terperinci Keupayaan penaakulan seperti manusia GPT-4 telah bertambah baik! Akademi Sains China mencadangkan 'komunikasi berfikir', pemikiran analogi melangkaui CoT dan boleh digunakan serta-merta. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Lapan fungsi yang paling biasa digunakan dalam excel
Lapan fungsi yang paling biasa digunakan dalam excel
 Bagaimana untuk membulatkan dalam Matlab
Bagaimana untuk membulatkan dalam Matlab
 Apakah pelayan web?
Apakah pelayan web?
 Perbezaan antara halaman web statik dan halaman web dinamik
Perbezaan antara halaman web statik dan halaman web dinamik
 Apakah peranan pelayan sip
Apakah peranan pelayan sip
 Bagaimana untuk menyelesaikan masalah yang document.cookie tidak boleh diperolehi
Bagaimana untuk menyelesaikan masalah yang document.cookie tidak boleh diperolehi
 Bagaimana untuk membuka fail iso
Bagaimana untuk membuka fail iso
 Bagaimana untuk mengulas kod dalam html
Bagaimana untuk mengulas kod dalam html








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



