


Artikel ini dicetak semula dengan kebenaran akaun awam Autonomous Driving Heart Sila hubungi sumber untuk mencetak semula. . kerana kebolehtafsiran yang rendah, latihan sukar untuk disatukan, dsb., sesetengah sarjana dalam bidang ini telah mula secara beransur-ansur mengalihkan perhatian mereka kepada kebolehtafsiran hujung ke hujung Hari ini saya akan berkongsi dengan anda karya terkini mengenai kebolehtafsiran hujung ke hujung. ADAPT. Kaedah ini adalah berdasarkan seni bina Transformer dan menggunakan pelbagai tugas Kaedah latihan bersama mengeluarkan penerangan tindakan kenderaan dan penaakulan untuk setiap keputusan hujung ke hujung. Beberapa pendapat penulis tentang ADAPT adalah seperti berikut:
Token
yang diperolehi dengan token imej adalah terlalu banyak, dan mungkin terdapat banyak maklumat yang tidak berguna. Mungkin anda boleh mencuba Token-Learner.Mampu mengeluarkan huraian tindakan kenderaan dan alasan untuk setiap keputusan hujung ke hujung
Kaedah ini berdasarkan struktur rangkaian transformer dan melakukan latihan bersama melalui kaedah pelbagai tugas 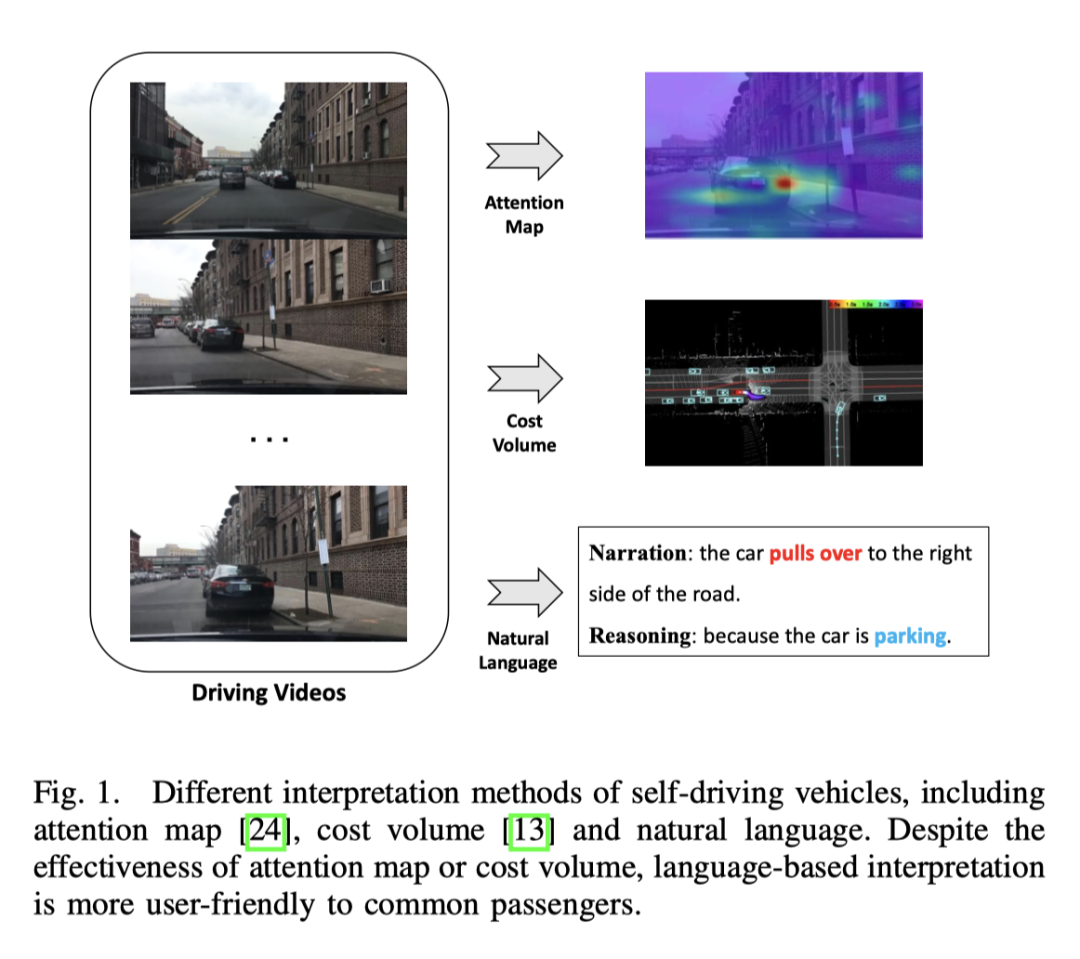
Kapsyen Video
Matlamat utama penerangan video adalah untuk menerangkan objek dan hubungannya dengan video tertentu dalam bahasa semula jadi. Kerja-kerja penyelidikan awal menjana ayat dengan struktur sintaksis tertentu dengan mengisi elemen yang dikenal pasti dalam templat tetap, yang tidak fleksibel dan tidak mempunyai kekayaan.
Pemacuan autonomi berasaskan pembelajaran ialah bidang penyelidikan yang aktif. UniAD kertas terbaik CVPR2023 baru-baru ini, termasuk FusionAD seterusnya, dan karya Wayve berdasarkan model Dunia MILE semuanya berfungsi ke arah ini. Format output termasuk titik trajektori, seperti UniAD, dan tindakan kenderaan secara langsung, seperti MILE.
Selain itu, beberapa kaedah memodelkan tingkah laku masa hadapan peserta trafik seperti kenderaan, penunggang basikal atau pejalan kaki untuk meramalkan titik laluan kenderaan, manakala kaedah lain meramalkan isyarat kawalan kenderaan secara langsung berdasarkan input sensor, serupa dengan subtugas ramalan isyarat kawalan dalam ini kerja
Dalam bidang pemanduan autonomi, kebanyakan kaedah kebolehtafsiran adalah berdasarkan penglihatan, dan ada yang berdasarkan kerja LiDAR. Sesetengah kaedah menggunakan peta perhatian untuk menapis kawasan imej yang tidak penting, menjadikan gelagat kenderaan autonomi kelihatan munasabah dan boleh dijelaskan. Walau bagaimanapun, peta perhatian mungkin mengandungi beberapa kawasan yang kurang penting. Terdapat juga kaedah yang menggunakan peta lidar dan berketepatan tinggi sebagai input, meramalkan kotak sempadan peserta trafik lain, dan menggunakan ontologi untuk menerangkan proses penaakulan membuat keputusan. Selain itu, terdapat cara untuk membina peta dalam talian melalui pembahagian untuk mengurangkan pergantungan pada peta HD. Walaupun kaedah berasaskan penglihatan atau lidar boleh memberikan hasil yang baik, kekurangan penjelasan lisan menjadikan keseluruhan sistem kelihatan rumit dan sukar untuk difahami. Satu kajian meneroka kemungkinan tafsiran teks untuk kenderaan autonomi buat kali pertama, dengan mengekstrak ciri video di luar talian untuk meramal isyarat kawalan dan melaksanakan tugas penerangan video
Rangka kerja hujung ke hujung ini menggunakan pembelajaran berbilang tugas untuk bersama-sama melatih model menggunakan dua tugas penjanaan teks dan isyarat kawalan ramalan. Pembelajaran pelbagai tugas digunakan secara meluas dalam pemanduan autonomi. Oleh kerana penggunaan data yang lebih baik dan ciri yang dikongsi, latihan bersama tugas yang berbeza meningkatkan prestasi setiap tugasan Oleh itu, dalam kerja ini, latihan bersama dua tugas ramalan isyarat kawalan dan penjanaan teks digunakan.
Berikut ialah gambar rajah struktur rangkaian:
#🎜#🎜##🎜#🎜##🎜 #🎜 🎜#Keseluruhan struktur dibahagikan kepada dua tugas: 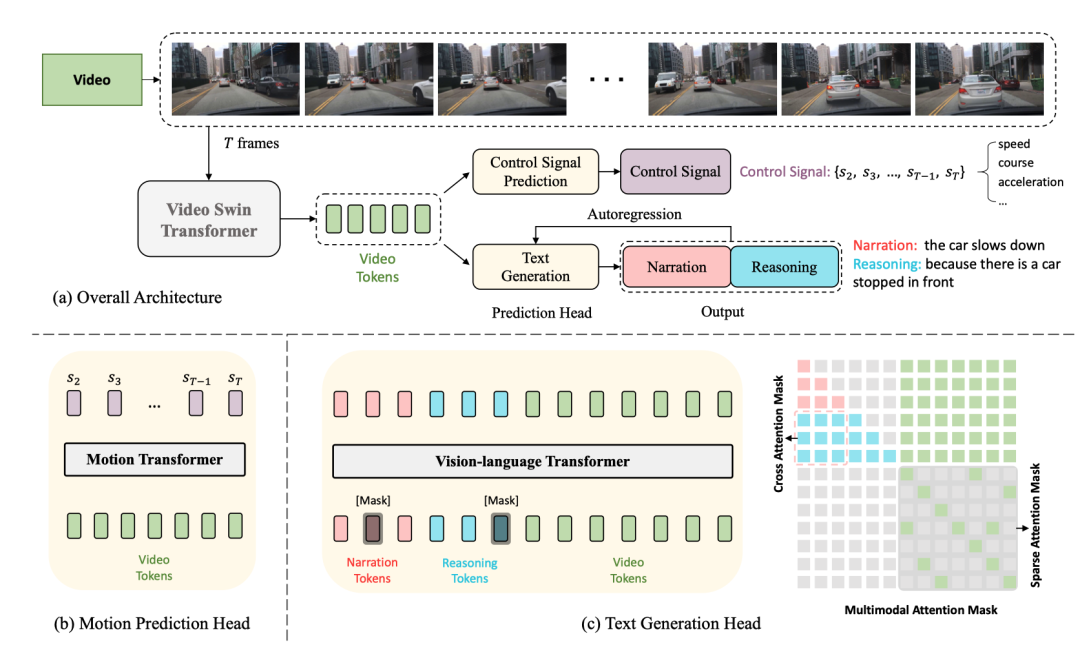
Driving Caption Generation (DCG): video input, output dua ayat, ayat pertama menerangkan aksi kereta, ayat kedua Huraikan alasan untuk mengambil tindakan ini, seperti "Kereta itu memecut, kerana lampu isyarat bertukar hijau." isyarat kawalan, seperti kelajuan , arah, pecutan.
Pengekod Video
#🎜#🎜##🎜 di sini Video Swin Transformer digunakan untuk menukar bingkai video input kepada token ciri video. Input#🎜🎜 inilah #🎜 🎜#
ialah dimensi saluran 🎜#Ciri di atas ditandakan untuk mendapatkan token video. 🎜🎜# , dan kemudian dilaraskan oleh MLP Dimensi diselaraskan dengan pembenaman token teks, dan kemudian token teks dan token video disalurkan kepada pengekod pengubah bahasa penglihatan bersama-sama untuk menjana penerangan dan penaakulan tindakan. Kepala Ramalan Isyarat Kawalan
Sepatutnya. ambil perhatian bahawa , bingkai pertama tidak disertakan di sini kerana bingkai pertama memberikan terlalu sedikit maklumat dinamikLatihan Bersama
Perlu diingat bahawa walaupun ia adalah tempat latihan bersama, semasa inferens , tetapi boleh dilaksanakan secara bebas Tugasan CSP mudah difahami Hanya masukkan video secara terus mengikut carta alir dan keluarkan isyarat kawalan Untuk tugasan DCG, teruskan input video dan huraian dan penaakulan masa berdasarkan kaedah autoregresif Penjanaan perkataan bermula dari [CLS] dan berakhir dengan [SEP] atau mencapai ambang panjang.
Set data yang digunakan ialah BDD-X ini mengandungi 7000 video berpasangan dan isyarat kawalan. Setiap video berdurasi kira-kira 40 saat, saiz imej ialah , dan kekerapannya ialah FPS Setiap video mempunyai 1 hingga 5 gelagat kenderaan, seperti memecut, membelok ke kanan dan bergabung. Semua tindakan ini dianotasi dengan teks, termasuk naratif tindakan (cth., "Kereta berhenti") dan penaakulan (cth., "Kerana lampu isyarat merah"). Terdapat kira-kira 29,000 pasangan anotasi tingkah laku secara keseluruhan.
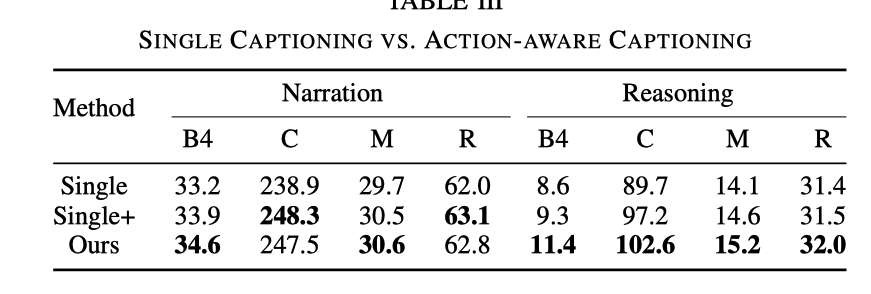
Tiga eksperimen dibandingkan di sini untuk menggambarkan keberkesanan latihan bersama tugasan masih belum wujud, tetapi apabila memasukkan modul DCG, selain tag video, tag isyarat kawalan juga perlu dimasukkan
boleh difahami sebagai ketepatan, khususnya ia akan Isyarat kawalan yang diramalkan dipotong, dan formulanya adalah seperti berikut

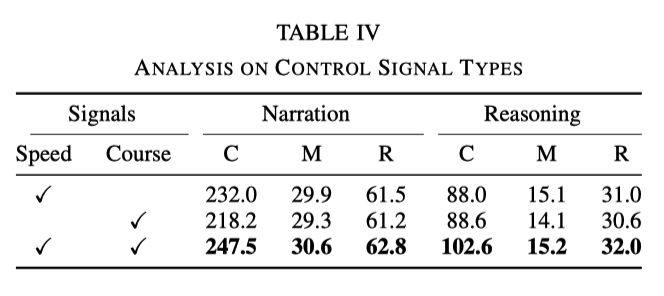
Pengaruh pelbagai jenis isyarat kawalan
Dalam eksperimen, isyarat asas yang digunakan ialah kelajuan dan tajuk. Walau bagaimanapun, eksperimen mendapati bahawa apabila hanya satu daripada isyarat digunakan, kesannya tidak sebaik menggunakan kedua-dua isyarat pada masa yang sama Data khusus ditunjukkan dalam jadual berikut: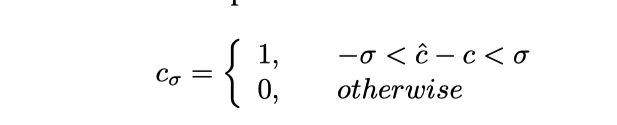
Interaksi antara huraian tindakan dan penaakulan
 Berbanding dengan tugasan penerangan umum, penjanaan tugas huraian memandu ialah dua ayat iaitu huraian tindakan dan penaakulan. Ia boleh didapati daripada jadual berikut:
Berbanding dengan tugasan penerangan umum, penjanaan tugas huraian memandu ialah dua ayat iaitu huraian tindakan dan penaakulan. Ia boleh didapati daripada jadual berikut:
Atas ialah kandungan terperinci Tajuk baharu: ADAPT: Penerokaan awal kebolehjelasan pemanduan autonomi hujung-ke-hujung. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
 Apakah maksud chrome?
Apakah maksud chrome?
 Apakah alamat e-mel dan bagaimana untuk mengisinya?
Apakah alamat e-mel dan bagaimana untuk mengisinya?
 Akhiran nama fail pengubahsuaian kelompok Linux
Akhiran nama fail pengubahsuaian kelompok Linux
 Tujuan arahan rm-rf dalam linux
Tujuan arahan rm-rf dalam linux
 java mengkonfigurasi pembolehubah persekitaran jdk
java mengkonfigurasi pembolehubah persekitaran jdk
 Penggunaan ModifyMenu
Penggunaan ModifyMenu
 Perisian sistem pengurusan erp percuma
Perisian sistem pengurusan erp percuma








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



