


Jika anda pernah berinteraksi dengan mana-mana bot AI perbualan, anda akan mengingati beberapa detik yang sangat mengecewakan. Sebagai contoh, perkara penting yang anda nyatakan dalam perbualan sehari sebelumnya telah dilupakan sepenuhnya oleh AI...
Ini kerana kebanyakan LLM semasa hanya boleh mengingati konteks terhad, sama seperti pelajar berdesak-desakan untuk peperiksaan , sedikit silang- peperiksaan akan "mendedahkan kebenaran."
Bukankah patut dicemburui jika pembantu AI boleh merujuk perbualan secara kontekstual dari beberapa minggu atau bulan lalu dalam sembang, atau jika anda boleh meminta pembantu AI untuk meringkaskan laporan yang sepanjang beribu-ribu halaman?
Untuk menjadikan LLM lebih mengingati dan mengingati lebih banyak kandungan, penyelidik telah bekerja keras. Baru-baru ini, penyelidik dari MIT, Meta AI, dan Carnegie Mellon University mencadangkan kaedah yang dipanggil "StreamingLLM" yang membolehkan model bahasa memproses teks tanpa henti dengan lancar

StreamingLLM berfungsi dengan mengenal pasti dan menyimpan niat ” (perhatian tenggelam) yang menambat token awal untuk alasannya. Digabungkan dengan cache rolling token baru-baru ini, StreamingLLM mempercepatkan inferens sebanyak 22x tanpa mengorbankan sebarang ketepatan. Hanya dalam beberapa hari, projek itu telah memperoleh 2.5K bintang pada platform GitHub:
Secara khusus, StreamingLLM ialah model bahasa yang boleh mengingati dengan tepat skor permainan sebelumnya, a kontrak yang panjang, atau kandungan perbahasan. Sama seperti menaik taraf memori pembantu AI, ia boleh mengendalikan lebih banyak beban kerja yang berat dengan sempurna

Mari lihat butiran teknikal seterusnya.
Secara amnya, LLM dihadkan oleh tingkap perhatian semasa pra-latihan. Walaupun terdapat banyak kerja sebelum ini untuk mengembangkan saiz tetingkap ini dan meningkatkan kecekapan latihan dan inferens, panjang jujukan LLM yang boleh diterima masih terhad, yang tidak mesra untuk penggunaan berterusan.
Dalam kertas kerja ini, penyelidik mula-mula memperkenalkan konsep aplikasi penstriman LLM dan menimbulkan persoalan: "Bolehkah LLM digunakan dengan input yang tidak terhingga tanpa mengorbankan kecekapan dan prestasi?"
Apabila menggunakan LLM pada panjang yang tidak terhingga aliran input, anda akan menghadapi dua cabaran utama:
1 Dalam peringkat penyahkodan, LLM berasaskan transformer akan menyimpan status Kunci dan Nilai (KV) bagi semua token sebelumnya, seperti yang ditunjukkan dalam Rajah 1 (Seperti yang ditunjukkan dalam. a), ini boleh membawa kepada penggunaan memori yang berlebihan dan meningkatkan kependaman penyahkodan
2 Model sedia ada mempunyai keupayaan ekstrapolasi panjang yang terhad, iaitu, apabila panjang jujukan melebihi tetingkap perhatian yang ditetapkan semasa pra-latihan, ia terlalu terhad. jam yang besar, prestasinya akan merosot.
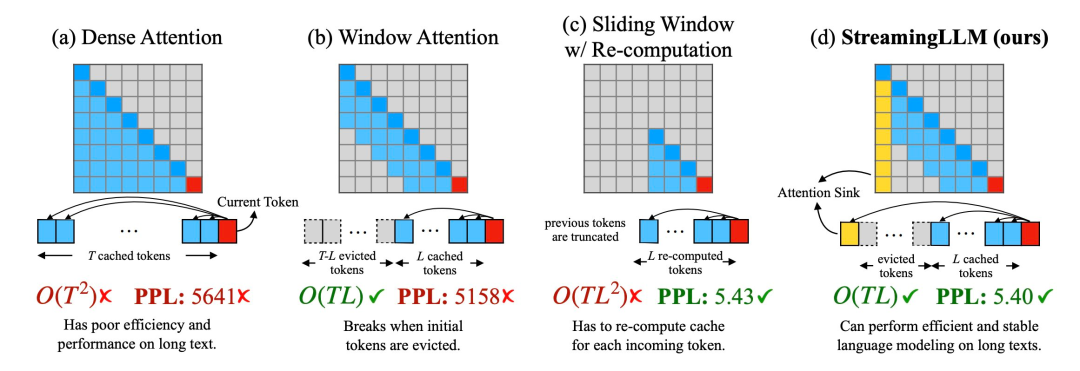
Kaedah intuitif dipanggil Window Attention (Rajah 1 b) Kaedah ini hanya mengekalkan tetingkap gelongsor bersaiz tetap pada status KV token terkini Walaupun ia boleh memastikan penggunaan memori dan penyahkodan yang stabil kelajuan selepas cache diisi, tetapi apabila panjang jujukan melebihi saiz cache, atau malah hanya mengusir KV token pertama, model akan ranap. Kaedah lain ialah mengira semula tetingkap gelongsor (ditunjukkan dalam Rajah 1 c). Kaedah ini membina semula keadaan KV bagi token yang dijana Walaupun prestasinya berkuasa, ia memerlukan pengiraan perhatian sekunder dalam tetingkap hasilnya adalah lebih perlahan, yang tidak sesuai dalam aplikasi penstriman sebenar.
Dalam proses mengkaji kegagalan perhatian tetingkap, penyelidik menemui fenomena menarik: menurut Rajah 2, sejumlah besar skor perhatian diberikan kepada tag awal, tidak kira sama ada tag ini berkaitan dengan tugas pemodelan bahasa
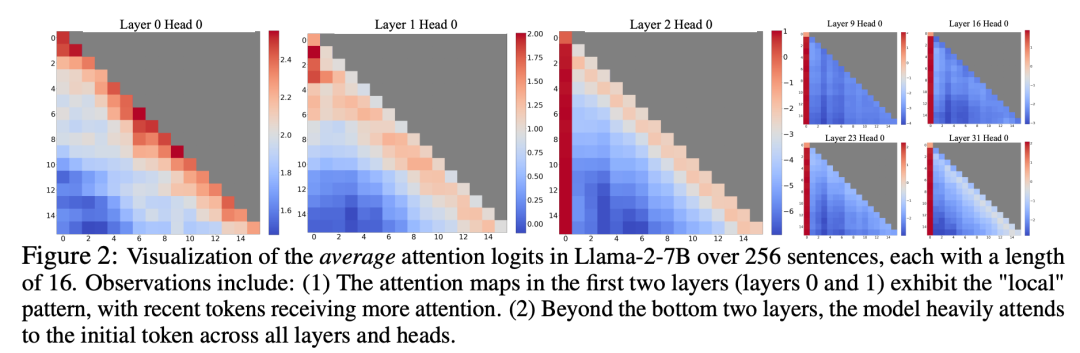
Penyelidik memanggil token ini sebagai "kolam perhatian": walaupun ia tidak mempunyai makna semantik, ia menduduki sejumlah besar skor perhatian. Penyelidik mengaitkan fenomena ini kepada Softmax (yang memerlukan jumlah skor perhatian semua token konteks ialah 1 Walaupun pertanyaan semasa tidak mempunyai padanan yang kukuh antara banyak token sebelumnya, model masih perlu memindahkan perhatian yang tidak diingini ini). . Nilai ditetapkan di suatu tempat supaya jumlahnya menjadi 1. Sebab mengapa token awal menjadi "kolam" adalah intuitif: disebabkan oleh ciri-ciri pemodelan bahasa autoregresif, token awal kelihatan kepada hampir semua token berikutnya, yang menjadikannya lebih mudah untuk dilatih sebagai kumpulan perhatian.
Berdasarkan pandangan di atas, penyelidik mencadangkan StreamingLLM. Ini ialah rangka kerja yang mudah dan cekap yang membolehkan model perhatian yang dilatih dengan tingkap perhatian terhad untuk mengendalikan teks yang panjang tidak terhingga tanpa penalaan halus
StreamingLLM mengambil kesempatan daripada fakta bahawa kumpulan perhatian mempunyai nilai perhatian yang tinggi Malah, mengekalkan kumpulan perhatian ini boleh jadikan taburan skor perhatian hampir kepada taburan normal. Oleh itu, StreamingLLM hanya perlu mengekalkan nilai KV token pool perhatian (hanya 4 token awal sudah mencukupi) dan nilai KV tetingkap gelongsor untuk menambat pengiraan perhatian dan menstabilkan prestasi model.
Menggunakan StreamingLLM, termasuk Llama-2-[7,13,70] B, MPT-[7,30] B, Falcon-[7,40] B dan Pythia [2.9,6.9,12] B Model boleh mensimulasikan 4 juta token atau lebih dengan pasti.
Berbanding dengan mengira semula tetingkap gelongsor, StreamingLLM adalah 22.2 kali lebih pantas tanpa menjejaskan prestasi
Dalam eksperimen, seperti yang ditunjukkan dalam Rajah 3, perplexiti LL, untuk teks 3M setanding dengan garis dasar Oracle yang mengira semula tetingkap gelongsor. Pada masa yang sama, apabila panjang input melebihi tetingkap pra-latihan, perhatian yang padat gagal, dan apabila panjang input melebihi saiz cache, perhatian tetingkap akan tersekat, menyebabkan tag awal akan disingkirkan
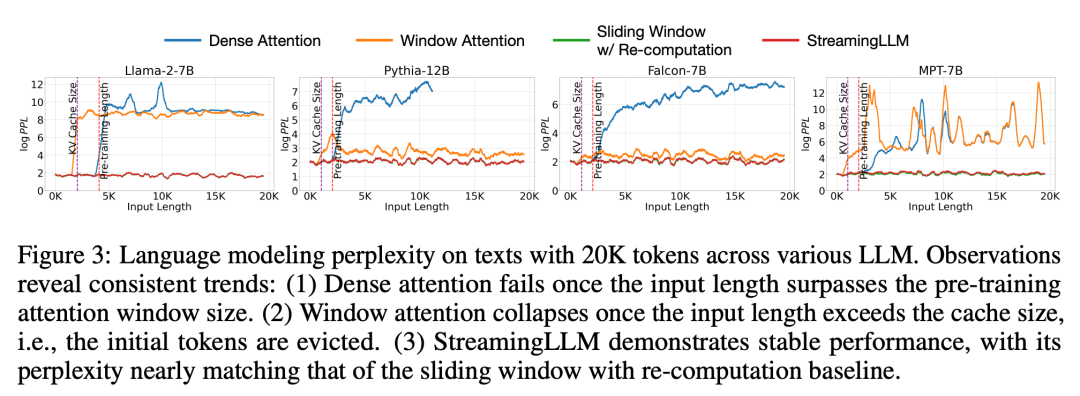
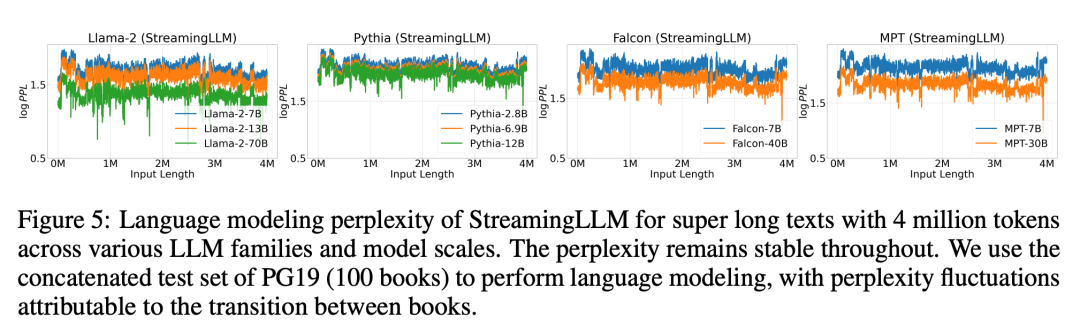
Rajah 5 Selanjutnya Kebolehpercayaan StreamingLLM ditunjukkan dan ia boleh mengendalikan teks dengan saiz luar biasa, termasuk lebih daripada 4 juta token, meliputi pelbagai keluarga dan saiz model. Model ini termasuk Llama-2-[7,13,70] B, Falcon-[7,40] B, Pythia-[2.8,6.9,12] B dan MPT-[7,30] B
Seterusnya, penyelidik mengesahkan hipotesis "kolam perhatian" dan membuktikan bahawa model bahasa boleh dilatih terlebih dahulu dan hanya memerlukan satu token kumpulan perhatian semasa penggunaan penstriman. Khususnya, mereka mencadangkan menambah token boleh dipelajari tambahan pada permulaan semua sampel latihan sebagai kumpulan perhatian yang ditetapkan. Dengan pra-latihan model bahasa dengan 160 juta parameter dari awal, para penyelidik menunjukkan bahawa kaedah kami boleh mengekalkan prestasi model. Ini sangat berbeza dengan model bahasa semasa, yang memerlukan pengenalan semula berbilang token awal sebagai kumpulan perhatian untuk mencapai tahap prestasi yang sama.
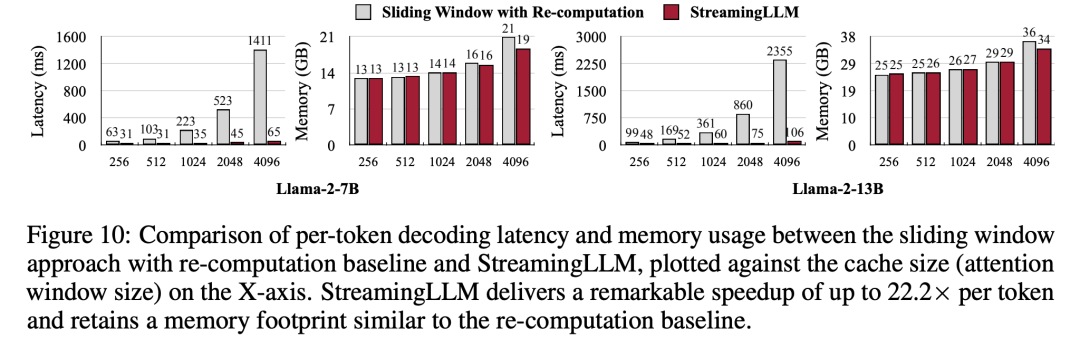
Akhir sekali, penyelidik membandingkan kependaman penyahkodan dan penggunaan memori StreamingLLM dengan tetingkap gelongsor yang dikira semula dan mengujinya menggunakan model Llama-2-7B dan Llama-2-13B pada GPU NVIDIA A6000 tunggal. Menurut keputusan dalam Rajah 10, apabila saiz cache meningkat, kelajuan penyahkodan StreamingLLM meningkat secara linear, manakala kelewatan penyahkodan meningkat secara kuadratik. Eksperimen telah membuktikan bahawa StreamingLLM mencapai kelajuan yang mengagumkan, dengan kelajuan setiap token meningkat sehingga 22.2 kali ganda
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
🎜Atas ialah kandungan terperinci Dengan sehingga 4 juta konteks token dan inferens 22 kali lebih pantas, StreamingLLM telah menjadi popular dan telah menerima 2.5K bintang di GitHub.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Cara memintas panggilan mengganggu
Cara memintas panggilan mengganggu
 data jadual jelas oracle
data jadual jelas oracle
 Teknik yang biasa digunakan untuk perangkak web
Teknik yang biasa digunakan untuk perangkak web
 Gambar rajah topologi rangkaian
Gambar rajah topologi rangkaian
 Sistem oa mana yang lebih baik?
Sistem oa mana yang lebih baik?
 Apakah yang perlu saya lakukan jika iPad saya tidak boleh dicas?
Apakah yang perlu saya lakukan jika iPad saya tidak boleh dicas?
 Kelebihan pycharm
Kelebihan pycharm
 Bagaimana untuk menyelesaikan javascriptvoid(o)
Bagaimana untuk menyelesaikan javascriptvoid(o)








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



