


Arah aliran yang jelas pada masa ini adalah ke arah membina model yang lebih besar dan lebih kompleks dengan puluhan/ratusan bilion parameter yang mampu menjana output bahasa yang mengagumkan
Walau bagaimanapun, model bahasa besar sedia ada Terutamanya tertumpu pada maklumat teks dan tidak dapat memahami maklumat visual.
Jadi kemajuan dalam bidang Multimodal Large Language Models (MLLMs) bertujuan untuk menangani had ini, MLLMs menggabungkan maklumat visual dan tekstual ke dalam satu model berasaskan Transformer, membolehkan model menyesuaikan diri dengan kedua-dua modaliti Belajar dan menjana kandungan.
MLLM menunjukkan potensi dalam pelbagai aplikasi praktikal, termasuk pemahaman imej semula jadi dan pemahaman imej teks. Model ini memanfaatkan pemodelan bahasa sebagai antara muka biasa untuk mengendalikan masalah berbilang modal, membolehkan mereka memproses dan menjana respons berdasarkan input teks dan visual
Walau bagaimanapun, pada masa ini tumpuan utama adalah pada MLLM imej semula jadi dengan resolusi rendah, yang padat untuk teks Terdapat sedikit kajian mengenai imej. Oleh itu, menggunakan sepenuhnya pra-latihan pelbagai mod berskala besar untuk memproses imej teks telah menjadi hala tuju penting penyelidikan MLLM
Dengan memasukkan imej teks ke dalam proses latihan dan membangunkan model berdasarkan maklumat teks dan visual, kami boleh membuka jalan baharu yang melibatkan resolusi tinggi Kemungkinan baharu untuk aplikasi pelbagai mod imej padat teks. . dibangunkan di KOSMOS- Dibangunkan berdasarkan 2, ia menyerlahkan keupayaan membaca dan memahami pelbagai mod imej intensif teks (Model Celik Pelbagai Modal).
Cadangan model ini menyerlahkan prestasi cemerlangnya dalam memahami imej intensif teks, merapatkan jurang antara penglihatan dan teks
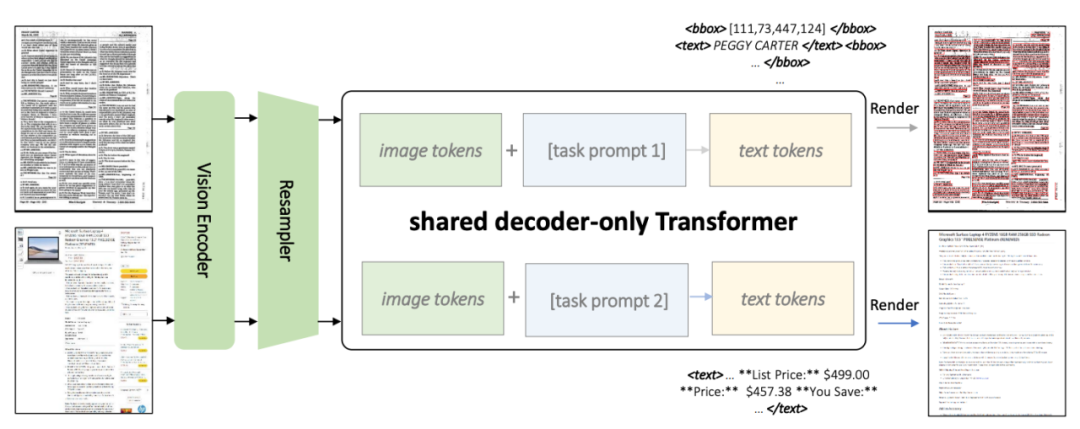
Seperti yang ditunjukkan dalam Rajah 2, kedua-dua tugas menggunakan seni bina pengubah bersama dan petunjuk khusus tugas
 Kosmos-2.5 menggabungkan pengekod visual berdasarkan ViT (Pengubah Penglihatan) dengan penyahkod berdasarkan seni bina Transformer, disambungkan melalui modul pensampelan semula.
Kosmos-2.5 menggabungkan pengekod visual berdasarkan ViT (Pengubah Penglihatan) dengan penyahkod berdasarkan seni bina Transformer, disambungkan melalui modul pensampelan semula.
Untuk melatih model ini, penulis menyediakan set data yang besar dengan saiz 324.4M, seperti ditunjukkan dalam Rajah 3
Rajah 4: Contoh sampel latihan untuk baris teks dengan kotak sempadan
Rajah 5: Contoh sampel latihan dalam format Markdown
ini mengandungi pelbagai jenis imej padat teks tersebut dengan baris Teks dengan kotak sempadan dan teks biasa dalam format Markdown Rajah 4 dan 5 adalah contoh visualisasi latihan. Kaedah latihan pelbagai tugas ini meningkatkan keupayaan pelbagai mod keseluruhan KOSMOS-2.5 keupayaan yang menjanjikan dalam kedua-dua senario pembelajaran beberapa pukulan dan pembelajaran sifar pukulan, menjadikannya alat serba boleh untuk aplikasi praktikal dalam memproses imej kaya teks. Ia boleh dianggap sebagai alat serba boleh yang boleh mengendalikan imej kaya teks dengan berkesan dan menunjukkan keupayaan yang menjanjikan dalam kes pembelajaran beberapa pukulan dan pembelajaran sifar pukulan Pengarang menunjukkan bahawa penalaan halus arahan adalah sangat menjanjikan. Kaedah prospek boleh mencapai keupayaan aplikasi yang lebih luas bagi model. Dalam bidang penyelidikan yang lebih luas, hala tuju penting terletak pada mengembangkan lagi keupayaan untuk mengembangkan parameter model. Memandangkan skop dan kerumitan tugas terus berkembang, model penskalaan untuk mengendalikan jumlah data yang lebih besar adalah penting untuk pembangunan model berbilang modal intensif teks. Matlamat utama adalah untuk membangunkan model yang boleh mentafsir data visual dan teks dengan berkesan dan berjaya membuat generalisasi kepada tugasan pelbagai mod yang lebih intensif teks. Apabila menulis semula kandungan, ia perlu ditulis semula ke dalam bahasa Cina, dan ayat asal tidak perlu muncul https://arxiv.org/abs/2309.11419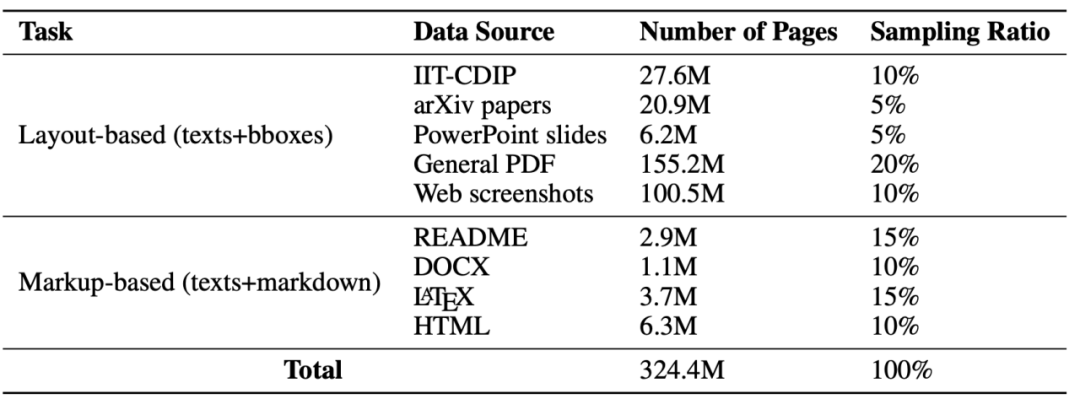 . 2.5 Ia dinilai berdasarkan dua tugas: pengecaman teks peringkat dokumen hujung ke hujung dan penjanaan teks berformat Markdown daripada imej.
. 2.5 Ia dinilai berdasarkan dua tugas: pengecaman teks peringkat dokumen hujung ke hujung dan penjanaan teks berformat Markdown daripada imej.  KOSMOS-2.5 berfungsi dengan baik dalam memproses tugasan imej intensif teks, dan keputusan percubaan menunjukkan perkara ini
KOSMOS-2.5 berfungsi dengan baik dalam memproses tugasan imej intensif teks, dan keputusan percubaan menunjukkan perkara ini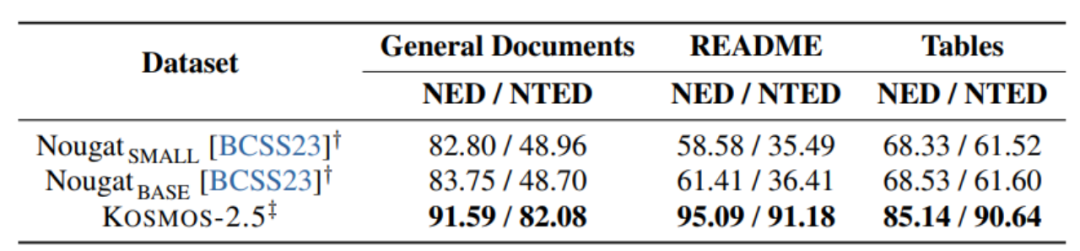

Atas ialah kandungan terperinci Lebih banyak perkataan dalam dokumen, lebih teruja model itu! KOSMOS-2.5: Model bahasa besar berbilang modal untuk membaca 'imej padat teks'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pertanyaan blockchain pelayar Ethereum
Pertanyaan blockchain pelayar Ethereum
 Perkara yang perlu dilakukan jika ikon desktop komputer tidak boleh dibuka
Perkara yang perlu dilakukan jika ikon desktop komputer tidak boleh dibuka
 Apakah perbezaan antara paparan pangkalan data dan jadual
Apakah perbezaan antara paparan pangkalan data dan jadual
 Bagaimana untuk menggunakan python untuk gelung
Bagaimana untuk menggunakan python untuk gelung
 Apakah mata wang yang dimiliki oleh USDT?
Apakah mata wang yang dimiliki oleh USDT?
 Bagaimana untuk mematikan muat turun automatik WeChat
Bagaimana untuk mematikan muat turun automatik WeChat
 Tutorial input simbol lebar penuh
Tutorial input simbol lebar penuh
 Bina pelayan Internet
Bina pelayan Internet








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



