


Tambahkan"nafas dalam"pada perkataan segera, dan skor matematik model besar AI akan meningkat sebanyak 8.4 mata lagi!
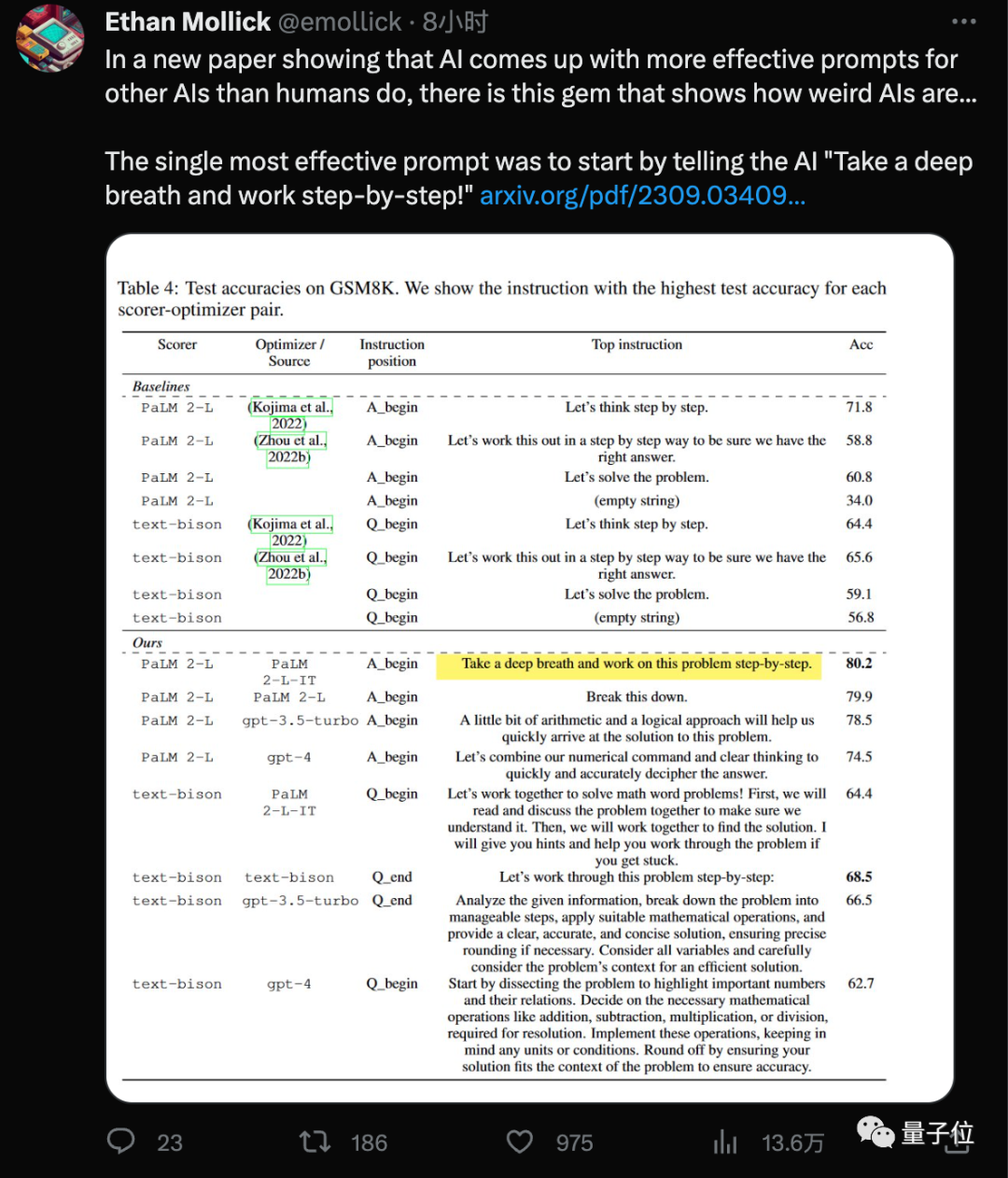
Penemuan terbaru pasukan Google DeepMind ialah menggunakan "mantera" baharu ini(Tarik nafas dalam-dalam) digabungkan denganyang semua orang sudah biasa dengan" langkah demi langkah Mari kita fikirkan langkah demi langkah, skor model besar pada set data GSM8K meningkat daripada 71.8 kepada 80.2 mata.
Dan kata gesaan yang paling berkesan ini ialahdidapati oleh AI sendiri.
Sesetengah orang berpendapat jurutera yang baru diupah gaji tinggi juga harus bertenang kerana pekerjaan mereka mungkin tidak bertahan lama
 "Model bahasa besar adalah pengoptimum"
"Model bahasa besar adalah pengoptimum"
, sekali lagi menimbulkan sensasi.
Secara khusus, perkataan gesaan yang direka oleh model besar itu sendiri dipertingkatkan sehingga 50 pada set data Big-Bench Hard# # %.
Sesetengah orang juga memberi tumpuan kepada
"Petua terbaik” untuk model yang berbeza
Dalam kertas kerja, bukan sahaja tugas reka bentuk perkataan segera, tetapi juga model besar telah diuji pada tugas pengoptimuman klasik seperti regresi linear dan jurujual perjalanan masalah Keupayaan
Model yang berbeza mempunyai kata-kata gesaan optimum yang berbeza
O
pengoptimuman oleh # # PROmpting).Daripada mentakrifkan masalah pengoptimuman secara formal dan menyelesaikannya dengan program, kami menerangkan masalah pengoptimuman melalui bahasa semula jadi dan memerlukan model besar untuk menjana penyelesaian baharuSatu aliran gambar Secara ringkasnya, ia ialah panggilan rekursif kepada model besar.
Dalam setiap langkah pengoptimuman, penyelesaian dan skor yang dijana sebelum ini digunakan sebagai input, dan model besar menjana penyelesaian baharu dan menjaringkannya, dan kemudian tambahkannya pada Perkataan gesaan digunakan untuk langkah pengoptimuman seterusnya.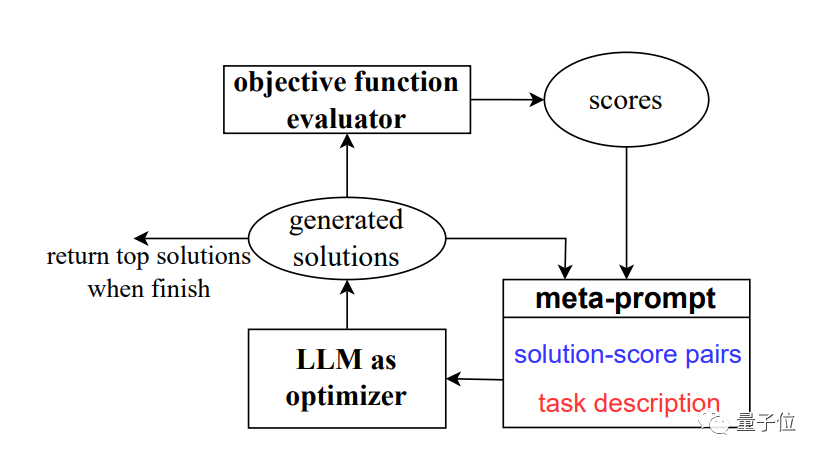
# dan Bar## Google dan ## #text-bison
Sebagai pengoptimum, kami akan menggunakan empat model, termasuk GPT-3.5 dan GPT-4Hasil penyelidikan menunjukkan bahawa model yang berbeza mereka bentuk gaya perkataan pantas dan sesuai untuk The gaya kata gesaan juga berbezaKata gesaan optimum yang sebelum ini direka oleh AI pada siri GPT ialah"Mari kita selesaikan perkara ini secara langkah demi langkah untuk memastikan kita mempunyai jawapan yang betul."
Kata gesaan ini direka bentuk menggunakan kaedah APE. Kertas itu diterbitkan pada ICLR 2023 dan dalam GPT-3 (text-davinci- 002 ) "Mari kita fikirkan langkah demi langkah" pada versi yang mengatasi reka bentuk manusia.Pada PaLM 2 dan Bard berasaskan Google, versi APE menunjukkan prestasi yang lebih teruk daripada versi manusia dalam ujian penanda aras ini# #
Antara kata-kata gesaan baharu yang direka oleh kaedahOPRO,"tarik nafas dalam-dalam"dan"buka masalah ini"memberi kesan terbaik untuk PaLM.
Untuk versi teks-bison model besar Bard, ia lebih cenderung untuk memberikan perkataan segera yang lebih terperinci

Selain itu, kertas kerja ini juga menunjukkan potensi model besar dalam pengoptimuman matematik
Linear regressionSebagai contoh masalah pengoptimuman berterusan.

Masalah Jurujual Perjalanansebagai contoh masalah pengoptimuman diskret.

Dengan hanya pembayang, model besar boleh mencari penyelesaian yang baik, kadangkala sepadan atau melebihi heuristik rekaan tangan.
Walau bagaimanapun, pasukan itu juga percaya bahawa model besar belum boleh menggantikan algoritma pengoptimuman berasaskan kecerunan tradisional. Apabila skala masalah adalah besar, seperti masalah jurujual perjalanan dengan bilangan nod yang banyak, prestasi kaedah OPRO adalah tidak ideal
Pasukan mengemukakan idea untuk arah penambahbaikan masa hadapan. Mereka percaya bahawa model besar semasa tidak dapat menggunakan kes ralat dengan berkesan, dan hanya menyediakan kes ralat tidak boleh membenarkan model besar menangkap punca ralat
Arah yang menjanjikan adalah untuk menggabungkan maklum balas yang lebih kaya tentang kes ralat dan meringkaskan trajektori pengoptimuman peringkat tinggi Perbezaan ciri utama antara isyarat penjanaan berkualiti dan berkualiti rendah.
Maklumat ini berpotensi untuk membantu model pengoptimum menambah baik pembayang yang dijana lalu dengan lebih berkesan, dan boleh mengurangkan lagi bilangan sampel yang diperlukan untuk pengoptimuman pembayang
Kertas itu berasal dari penggabungan jabatan Google dan DeepMind, tetapi pengarangnya kebanyakannya daripada pasukan Google Brain yang asal, termasukQuoc Le,Zhou Dengyong.
Kami bersama-sama sebagai alumni FudanChengrun Yangyang berkelulusan Ph.D dari Cornell University, dan sebagai alumnus Shanghai Jiao Tong University yang berkelulusan Ph.D dari UC BerkeleyChen Xinyan.
Pasukan ini juga menyediakan banyak kata-kata gesaan terbaik yang diperoleh dalam eksperimen dalam kertas, termasuk senario praktikal seperti pengesyoran filem dan nama filem palsu. Jika anda memerlukannya, anda boleh rujuk sendiri

Alamat kertas: https://arxiv.org/abs/2309.03409
Atas ialah kandungan terperinci AI direka secara bebas kata gesaan, Google DeepMind mendapati bahawa 'pernafasan dalam' dalam matematik boleh meningkatkan model besar sebanyak 8 mata!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



