


Apabila mempromosikan pelaksanaan kaedah persepsi berasaskan penglihatan, meningkatkan keupayaan generalisasi model adalah asas penting. Latihan/Penyesuaian Masa Ujian (Latihan/Penyesuaian Masa Ujian) membolehkan model menyesuaikan diri dengan pengedaran data domain sasaran yang tidak diketahui dengan melaraskan berat parameter model semasa fasa ujian. Kaedah TTT/TTA sedia ada biasanya menumpukan pada peningkatan prestasi latihan segmen ujian di bawah data domain sasaran dalam persekitaran tertutup Walau bagaimanapun, dalam banyak senario aplikasi, domain sasaran mudah dicemari oleh data luar domain yang kuat (OOD Kuat). contoh, kategori data yang tidak berkaitan secara semantik. Dalam kes ini, juga dikenali sebagai Latihan Segmen Ujian Dunia Terbuka (OWTTT), TTT/TTA sedia ada biasanya mengelaskan secara paksa data luar domain yang kuat ke dalam kategori yang diketahui, akhirnya mengganggu data luar domain yang lemah (OOD yang lemah) seperti Keupayaan pengecaman imej yang terganggu oleh bunyi
Baru-baru ini, Universiti Teknologi China Selatan dan pasukan A*STAR mencadangkan penetapan latihan segmen ujian dunia terbuka buat kali pertama, dan melancarkan kaedah latihan yang sepadan

Kaedah dalam artikel ini mencapai prestasi optimum pada 5 penanda aras OWTTT berbeza, dan menyediakan hala tuju baharu untuk penyelidikan seterusnya tentang TTT untuk meneroka kaedah TTT yang lebih mantap. Penyelidikan telah diterima sebagai kertas Lisan dalam ICCV 2023.
PengenalanLatihan segmen ujian (TTT) hanya boleh mengakses data domain sasaran semasa fasa inferens dan melakukan inferens segera pada data ujian anjakan pengedaran. Kejayaan TTT telah ditunjukkan pada beberapa data domain sasaran yang rosak secara sintetik yang dipilih secara buatan. Walau bagaimanapun, sempadan keupayaan kaedah TTT sedia ada belum diterokai sepenuhnya.
Untuk mempromosikan aplikasi TTT dalam senario terbuka, tumpuan penyelidikan telah beralih kepada menyiasat senario di mana kaedah TTT mungkin gagal. Banyak usaha telah dilakukan untuk membangunkan kaedah TTT yang stabil dan teguh dalam persekitaran dunia terbuka yang lebih realistik. Dalam kerja ini, kami menyelidiki senario dunia terbuka yang biasa tetapi diabaikan, di mana domain sasaran mungkin mengandungi pengedaran data ujian yang diambil daripada persekitaran yang berbeza dengan ketara, seperti kategori semantik yang berbeza daripada domain sumber, atau hanya bunyi rawak.
Kami memanggil data ujian di atas sebagai data luar pengedaran yang kuat (OOD yang kuat). Apa yang dipanggil data OOD lemah dalam kerja ini ialah data ujian dengan anjakan pengedaran, seperti kerosakan sintetik biasa. Oleh itu, kekurangan kerja sedia ada dalam persekitaran kehidupan sebenar ini mendorong kami untuk meneroka meningkatkan keteguhan Latihan Segmen Ujian Dunia Terbuka (OWTTT), di mana data ujian dicemari oleh sampel OOD yang kuat
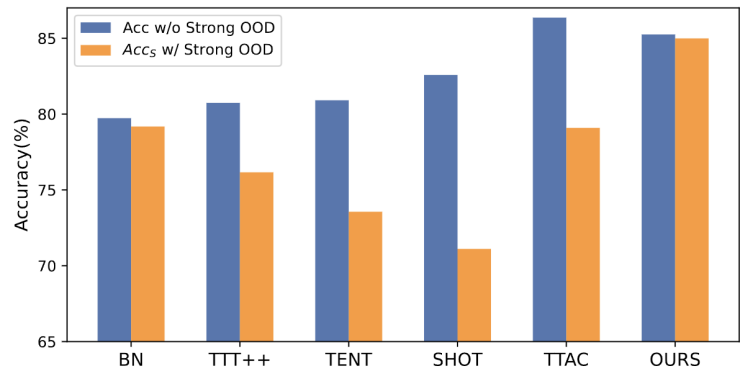
Apa yang perlu ditulis semula Ia adalah: Rajah 1: Hasil penilaian kaedah TTT sedia ada di bawah tetapan OWTTTSeperti yang ditunjukkan dalam Rajah 1, kami mula-mula menilai kaedah TTT sedia ada di bawah tetapan OWTTT dan mendapati bahawa melalui kedua-dua latihan kendiri dan kaedah TTT sejajar pengedaran dipengaruhi oleh sampel OOD yang kuat. Keputusan ini menunjukkan bahawa latihan ujian selamat tidak boleh dicapai dengan menggunakan teknologi TTT sedia ada di dunia terbuka. Kami mengaitkan kegagalan mereka kepada dua sebab berikut
Pertama, kami akan Menubuhkan garis dasar TTT berdasarkan varian, iaitu, gunakan prototaip domain sumber sebagai pusat kluster untuk pengelompokan dalam domain sasaran. Untuk mengurangkan kesan OOD yang kuat pada latihan kendiri daripada label pseudo palsu, kami mencadangkan kaedah bebas hiperparameter untuk menolak sampel OOD yang kuat
Untuk memisahkan lagi ciri sampel OOD yang lemah dan sampel OOD yang kuat, kami membenarkan pengumpulan prototaip untuk asingkan dengan pemilihan Sambungan sampel OOD yang kuat. Oleh itu, latihan kendiri akan membolehkan sampel OOD yang kuat membentuk kelompok yang ketat di sekeliling prototaip OOD kukuh yang baru dikembangkan. Ini akan memudahkan penjajaran pengedaran antara sumber dan domain sasaran. Kami selanjutnya mencadangkan untuk mengatur latihan kendiri melalui penjajaran pengedaran global untuk mengurangkan risiko bias pengesahan
Akhir sekali, untuk mensintesis senario TTT dunia terbuka, kami menggunakan set data CIFAR10-C, CIFAR100-C, ImageNet-C, VisDA-C, ImageNet-R, Tiny-ImageNet, MNIST dan SVHN dan menggunakan data ditetapkan kepada OOD Lemah, yang lain mewujudkan set data penanda aras untuk OOD yang kukuh. Kami merujuk kepada penanda aras ini sebagai Penanda Aras Latihan Segmen Ujian Dunia Terbuka dan berharap ini menggalakkan lebih banyak kerja masa hadapan untuk menumpukan pada keteguhan latihan segmen ujian dalam senario yang lebih realistik.
Kaedah
Kertas dibahagikan kepada empat bahagian untuk memperkenalkan kaedah yang dicadangkan.
1) Gambaran keseluruhan tetapan tugas latihan dalam segmen ujian di dunia terbuka.
2) Memperkenalkan cara menggunakanPengkelompokan prototaip ialah algoritma pembelajaran tanpa pengawasan yang digunakan untuk mengelompokkan sampel dalam set data ke dalam kategori yang berbeza. Dalam pengelompokan prototaip, setiap kategori diwakili oleh satu atau lebih prototaip, yang boleh menjadi sampel dalam set data atau dijana mengikut beberapa peraturan. Matlamat pengelompokan prototaip adalah untuk mencapai pengelompokan dengan meminimumkan jarak antara sampel dan prototaip kategori yang dimilikinya. Algoritma pengelompokan prototaip biasa termasuk pengelompokan K-means dan model campuran Gaussian. Algoritma ini digunakan secara meluas dalam bidang seperti perlombongan data, pengecaman corak dan pemprosesan imej Laksanakan TTT dan cara melanjutkan prototaip untuk latihan masa ujian dunia terbuka.
3) Memperkenalkan cara menggunakan data domain sasaranKandungan yang perlu ditulis semula ialah: sambungan prototaip dinamik .
4) MemperkenalkanPenjajaran Pengedaran dengan Pengkelompokan Prototaip ialah algoritma pembelajaran tanpa pengawasan yang digunakan untuk mengelompokkan sampel dalam set data ke dalam kategori yang berbeza. Dalam pengelompokan prototaip, setiap kategori diwakili oleh satu atau lebih prototaip, yang boleh menjadi sampel dalam set data atau dijana mengikut beberapa peraturan. Matlamat pengelompokan prototaip adalah untuk mencapai pengelompokan dengan meminimumkan jarak antara sampel dan prototaip kategori yang dimilikinya. Algoritma pengelompokan prototaip biasa termasuk pengelompokan K-means dan model campuran Gaussian. Algoritma ini, digunakan secara meluas dalam bidang seperti perlombongan data, pengecaman corak dan pemprosesan imej, digabungkan untuk membolehkan latihan masa ujian dunia terbuka yang berkuasa.
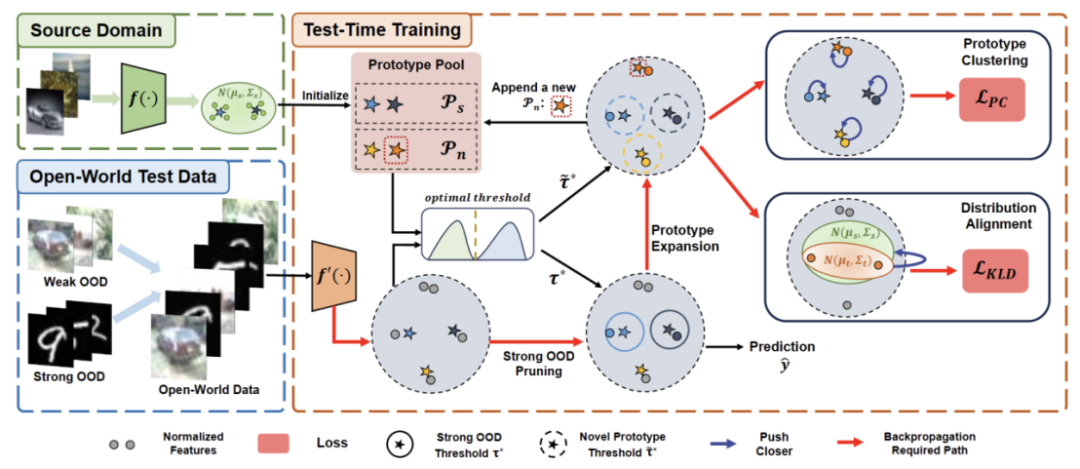
Kandungan yang perlu ditulis semula ialah: Rajah 2: Gambar rajah gambaran keseluruhan kaedah
Tetapan tugas
Matlamat TTT dalam domain yang disasarkan adalah-tra , di mana domain sasaran mungkin agak Terdapat penghijrahan pengedaran dalam domain sumber. Dalam TTT dunia tertutup standard, ruang label bagi domain sumber dan sasaran adalah sama. Walau bagaimanapun, dalam TTT dunia terbuka, ruang label domain sasaran mengandungi ruang sasaran domain sumber, yang bermaksud bahawa domain sasaran mempunyai kategori semantik baharu yang tidak kelihatanUntuk mengelakkan kekeliruan antara definisi TTT, kami menggunakan TTAC [2] Protokol Latihan Masa Ujian Berurutan (sTTT) yang dicadangkan dinilai. Di bawah protokol sTTT, sampel ujian diuji secara berurutan, dan kemas kini model dilakukan selepas memerhati kumpulan kecil sampel ujian. Ramalan bagi mana-mana sampel ujian yang tiba pada cap masa t tidak dipengaruhi oleh mana-mana sampel ujian yang tiba pada t+k (yang k lebih besar daripada 0).Pengkelompokan prototaip ialah algoritma pembelajaran tanpa pengawasan yang digunakan untuk mengelompokkan sampel dalam set data ke dalam kategori yang berbeza. Dalam pengelompokan prototaip, setiap kategori diwakili oleh satu atau lebih prototaip, yang boleh menjadi sampel dalam set data atau dijana mengikut beberapa peraturan. Matlamat pengelompokan prototaip adalah untuk mencapai pengelompokan dengan meminimumkan jarak antara sampel dan prototaip kategori yang dimilikinya. Algoritma pengelompokan prototaip biasa termasuk pengelompokan K-means dan model campuran Gaussian. Algoritma ini digunakan secara meluas dalam bidang seperti perlombongan data, pengecaman corak dan pemprosesan imej
Diilhamkan oleh kerja menggunakan pengelompokan dalam tugas penyesuaian domain [3,4], kami menganggap latihan segmen ujian sebagai menemui kelompok dalam struktur data domain sasaran . Dengan mengenal pasti prototaip wakil sebagai pusat kluster, struktur kluster dikenal pasti dalam domain sasaran dan sampel ujian digalakkan untuk membenamkan berhampiran salah satu prototaip. Pengelompokan prototaip ialah algoritma pembelajaran tanpa pengawasan yang digunakan untuk mengelompokkan sampel dalam set data ke dalam kategori yang berbeza. Dalam pengelompokan prototaip, setiap kategori diwakili oleh satu atau lebih prototaip, yang boleh menjadi sampel dalam set data atau dijana mengikut beberapa peraturan. Matlamat pengelompokan prototaip adalah untuk mencapai pengelompokan dengan meminimumkan jarak antara sampel dan prototaip kategori yang dimilikinya. Algoritma pengelompokan prototaip biasa termasuk pengelompokan K-means dan model campuran Gaussian. Matlamat algoritma ini, yang digunakan secara meluas dalam bidang seperti perlombongan data, pengecaman corak dan pemprosesan imej, ditakrifkan sebagai meminimumkan kehilangan kemungkinan log negatif persamaan kosinus antara sampel dan pusat kluster, seperti yang ditunjukkan dalam persamaan berikut.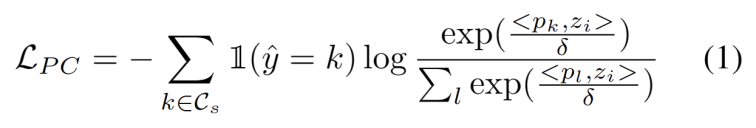
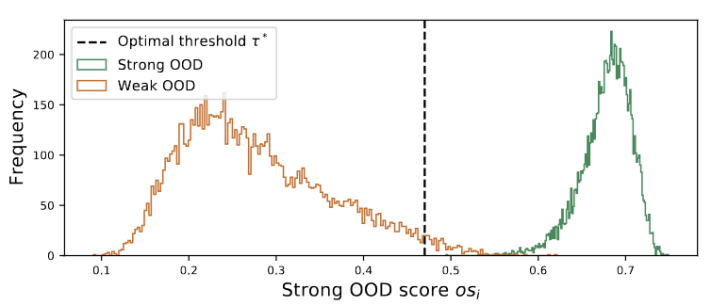
Rajah 3 Nilai kumpulan diedarkan dalam puncak berganda 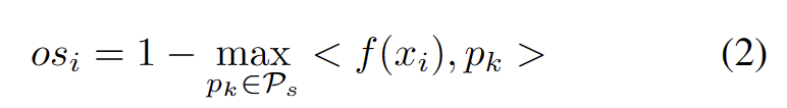
Apa yang perlu ditulis semula ialah: Sambungan prototaip dinamik
Meluaskan kumpulan prototaip OOD yang kukuh perlu mempertimbangkan kedua-dua domain sumber dan prototaip OOD yang kukuh untuk menilai sampel ujian. Untuk menganggarkan bilangan kelompok daripada data secara dinamik, kajian terdahulu telah menyiasat masalah yang sama. Algoritma pengelompokan keras deterministik DP-means [5] dibangunkan dengan mengukur jarak titik data ke pusat gugusan yang diketahui, dan gugusan baharu dimulakan apabila jaraknya melebihi ambang. DP-means ditunjukkan sebagai setara dengan mengoptimumkan objektif K-means, tetapi dengan penalti tambahan pada bilangan kluster, memberikan penyelesaian yang boleh dilaksanakan untuk sambungan prototaip dinamik yang memerlukan penulisan semula.
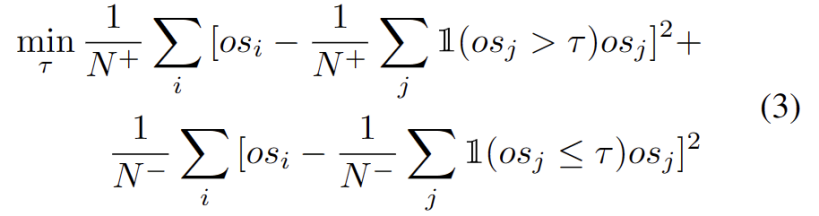
Dengan prototaip OOD lain yang kukuh dikenal pasti, kami menentukan prototaip untuk menguji sampel ialah algoritma pembelajaran tanpa pengawasan yang digunakan untuk mengelompokkan sampel dalam set data ke dalam kategori yang berbeza. Dalam pengelompokan prototaip, setiap kategori diwakili oleh satu atau lebih prototaip, yang boleh menjadi sampel dalam set data atau dijana mengikut beberapa peraturan. Matlamat pengelompokan prototaip adalah untuk mencapai pengelompokan dengan meminimumkan jarak antara sampel dan prototaip kategori yang dimilikinya. Algoritma pengelompokan prototaip biasa termasuk pengelompokan K-means dan model campuran Gaussian. Algoritma ini digunakan secara meluas dalam bidang seperti perlombongan data, pengecaman corak dan pemprosesan imej mengambil kira dua faktor. Pertama, sampel ujian yang diklasifikasikan ke dalam kelas yang diketahui harus dibenamkan lebih dekat dengan prototaip dan lebih jauh daripada prototaip lain, yang mentakrifkan tugas pengelasan kelas K. Kedua, sampel ujian yang diklasifikasikan sebagai prototaip OOD yang kuat harus berada jauh dari mana-mana prototaip domain sumber, yang mentakrifkan tugas pengelasan kelas K+1. Dengan mengambil kira matlamat ini, kami mengelompokkan prototaip, algoritma pembelajaran tanpa pengawasan yang digunakan untuk mengelompokkan sampel dalam set data ke dalam kategori yang berbeza. Dalam pengelompokan prototaip, setiap kategori diwakili oleh satu atau lebih prototaip, yang boleh menjadi sampel dalam set data atau dijana mengikut beberapa peraturan. Matlamat pengelompokan prototaip adalah untuk mencapai pengelompokan dengan meminimumkan jarak antara sampel dan prototaip kategori yang dimilikinya. Algoritma pengelompokan prototaip biasa termasuk pengelompokan K-means dan model campuran Gaussian. Algoritma ini digunakan secara meluas dalam bidang seperti perlombongan data, pengecaman corak dan pemprosesan imej Kerugian ditakrifkan sebagai formula berikut.
Kekangan Penjajaran Pengedaran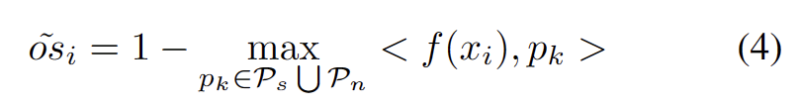
Adalah diketahui umum bahawa latihan kendiri terdedah kepada label pseudo yang salah. Keadaan bertambah buruk apabila domain sasaran terdiri daripada sampel OOD. Untuk mengurangkan risiko kegagalan, kami selanjutnya menggunakan penjajaran pengedaran [1] sebagai regularisasi untuk latihan kendiri, seperti berikut.
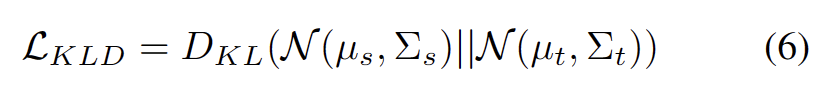

 #🎜#🎜🎜🎜🎜
#🎜#🎜🎜🎜🎜 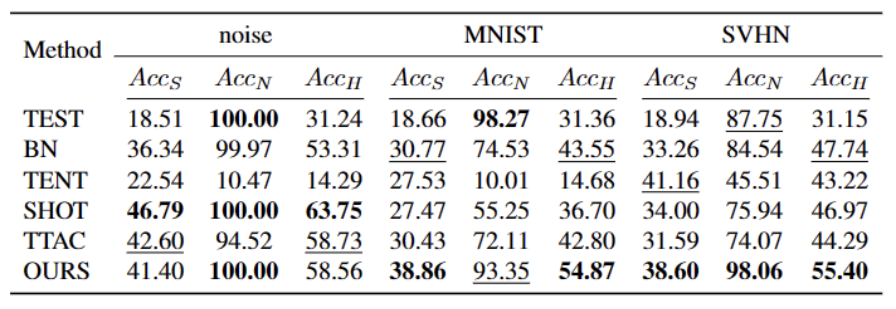 Apabila meringkaskan kandungan, anda perlu mengekalkan maksud asal tidak berubah dan menulis semula bahasa ke dalam bahasa Cina
Apabila meringkaskan kandungan, anda perlu mengekalkan maksud asal tidak berubah dan menulis semula bahasa ke dalam bahasa Cina 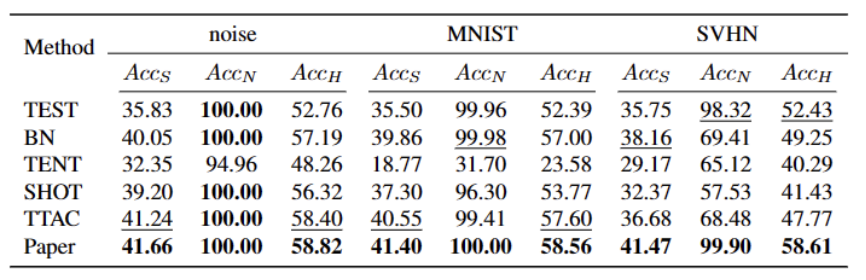
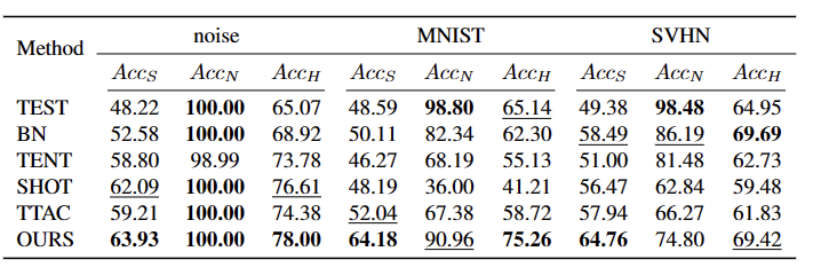
Atas ialah kandungan terperinci ICCV 2023 Oral |. Bagaimana untuk menjalankan latihan segmen ujian di dunia terbuka? Kaedah latihan kendiri berdasarkan pengembangan prototaip dinamik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!











![Bermula dengan Pembangunan Praktikal PHP: Penciptaan PHP Pantas [Forum Perniagaan Kecil]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)





![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



