


Model visual asas berdasarkan Transformer telah menunjukkan prestasi yang sangat berkuasa dalam pelbagai tugas hiliran, seperti segmentasi dan pengesanan, dan model seperti DINO telah muncul dengan atribut segmentasi semantik selepas latihan yang diselia sendiri.
Sungguh pelik bahawa model Transformer visual tidak menunjukkan keupayaan kemunculan yang sama selepas dilatih untuk klasifikasi yang diselia
Baru-baru ini, pasukan Profesor Ma Yi mengkaji model berdasarkan seni bina Transformer untuk meneroka kemunculan Adakah keupayaan segmentasi hasil daripada mekanisme pembelajaran penyeliaan kendiri yang kompleks, atau sama ada kemunculan yang sama boleh dicapai dalam keadaan yang lebih umum dengan mereka bentuk seni bina model yang sesuai

Pautan kod: https://github .com/Ma-Lab -Berkeley/CRATE
Sila klik pautan berikut untuk melihat kertas: https://arxiv.org/abs/2308.16271
Selepas eksperimen yang meluas, penyelidik menunjukkan CRATE menggunakan model Transformer kotak putih. reka bentuknya secara eksplisit memodelkan dan mengejar struktur berdimensi rendah dalam pengedaran data, sifat segmentasi peringkat keseluruhan dan sebahagian muncul dengan rumusan latihan yang diselia secara minima
Melalui analisis berbutir halus hierarki, kami memperoleh Kesimpulan penting: Sifat-sifat yang muncul sangat mengesahkan keupayaan reka bentuk matematik bagi rangkaian kotak putih. Berdasarkan keputusan ini, kami mencadangkan kaedah untuk mereka bentuk model asas kotak putih, yang bukan sahaja berprestasi tinggi, tetapi juga boleh ditafsir secara matematik sepenuhnya
Profesor Ma Yi juga berkata bahawa penyelidikan mengenai pembelajaran mendalam akan berkembang secara beransur-ansur dari Reka bentuk empirikal beralih kepada bimbingan teori.

Keupayaan munculan segmentasi DINO merujuk kepada keupayaan model DINO untuk membahagikan ayat input kepada serpihan yang lebih kecil apabila memproses tugas bahasa, dan melaksanakan analisis serpihan yang bergantung kepada setiap serpihan. . Keupayaan ini membolehkan model DINO memahami dengan lebih baik struktur ayat kompleks dan maklumat semantik, dengan itu meningkatkan prestasinya dalam bidang pemprosesan bahasa semula jadi
Pembelajaran perwakilan dalam sistem pintar bertujuan untuk menyepadukan aspek berdimensi tinggi dan pelbagai dunia Mengubah data deria (imej, bahasa, pertuturan) kepada bentuk yang lebih padat sambil mengekalkan struktur asasnya yang berdimensi rendah, membolehkan pengecaman yang cekap (seperti pengelasan), pengelompokan (seperti pembahagian) dan penjejakan.
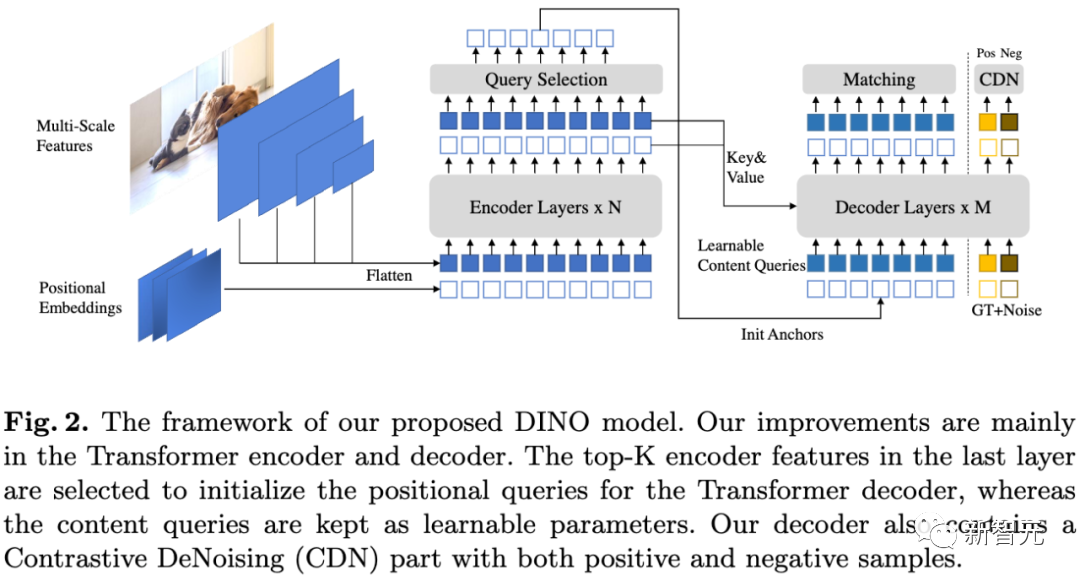
Latihan model pembelajaran mendalam biasanya menggunakan pendekatan dipacu data, dengan memasukkan data berskala besar dan pembelajaran dengan cara yang diselia sendiri
Antara model visual asas, model DINO menunjukkan yang mengejutkan Keupayaan yang muncul, ViT boleh mengenali maklumat pembahagian semantik yang jelas walaupun tanpa latihan pembahagian yang diselia. Model DINO bagi seni bina Transformer yang diselia sendiri telah menunjukkan prestasi yang baik dalam hal ini
Kerja-kerja berikut telah mengkaji cara menggunakan maklumat pembahagian ini dalam model DINO, dan mencapai prestasi terkini dalam tugas hiliran seperti Segmentasi dan pengesanan Terdapat juga kerja yang membuktikan bahawa ciri lapisan terakhir dalam ViT yang dilatih dengan DINO sangat berkait dengan maklumat penting dalam input visual, seperti membezakan sempadan latar depan, latar belakang dan objek, dengan itu meningkatkan prestasi pembahagian imej dan tugasan lain.
Untuk menyerlahkan atribut segmentasi, DINO perlu mahir menggabungkan pembelajaran penyeliaan kendiri, penyulingan pengetahuan dan kaedah purata berat semasa proses latihan
Tidak jelas sama ada setiap komponen yang diperkenalkan dalam DINO berguna untuk segmentasi. Walaupun DINO juga menggunakan seni bina ViT sebagai tulang belakangnya, gelagat kemunculan segmentasi tidak diperhatikan dalam model ViT diselia biasa yang dilatih mengenai tugas klasifikasi.
Kemunculan CRATE
Berdasarkan kejayaan DINO, para penyelidik ingin meneroka sama ada saluran pembelajaran penyeliaan kendiri yang kompleks diperlukan untuk mendapatkan ciri-ciri yang muncul dalam model visual seperti Transformer.
Penyelidik percaya bahawa cara yang menjanjikan untuk mempromosikan sifat segmentasi dalam model Transformer ialah mereka bentuk seni bina model Transformer dengan mengambil kira struktur data input, yang juga mewakili kedalaman pembelajaran perwakilan kaedah klasik dengan Integrasi pembelajaran dipacu data moden rangka kerja.

Berbanding dengan model Transformer arus perdana, kaedah reka bentuk ini juga boleh dipanggil model Transformer kotak putih.
Berdasarkan hasil kerja kumpulan Profesor Ma Yi sebelum ini, penyelidik menjalankan eksperimen yang meluas ke atas model CRATE seni bina kotak putih, membuktikan bahawa reka bentuk kotak putih CRATE adalah sebab kemunculan atribut segmentasi dalam graf perhatian diri.
Kandungan yang perlu dinyatakan semula ialah: Penilaian kualitatif
#🎜🎜🎜🎜 # Para penyelidik menggunakan kaedah peta perhatian berdasarkan token [CLS] untuk mentafsir dan menggambarkan model dan mendapati bahawa matriks nilai kunci pertanyaan dalam CRATE semuanya sama#🎜 🎜## 🎜🎜#
Dapat diperhatikan bahawa peta perhatian kendiri model CRATE boleh sepadan dengan semantik imej input Rangkaian dalaman model melakukan segmentasi semantik yang jelas pada setiap satu imej. , mencapai kesan yang serupa dengan model DINO. 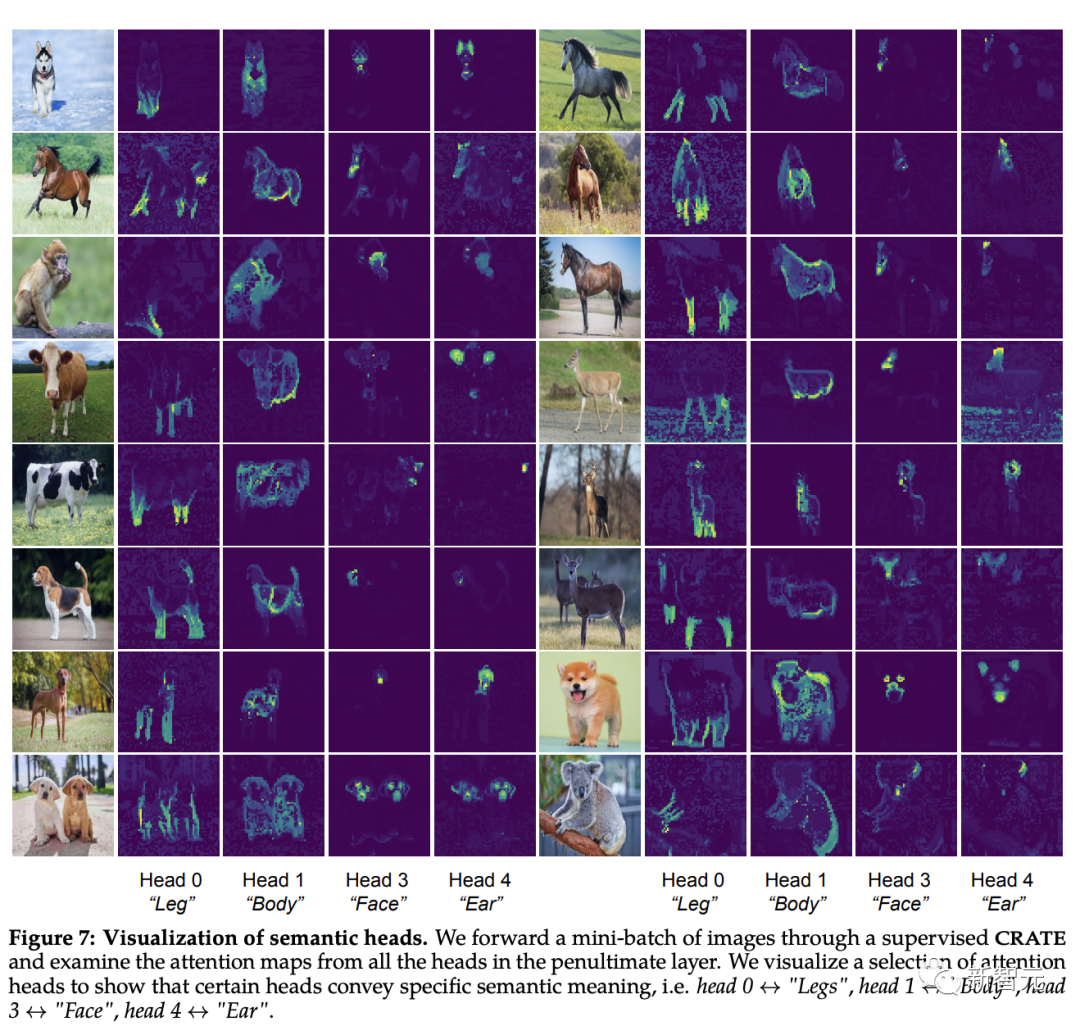
ViT Biasa tidak menunjukkan sifat segmentasi yang serupa apabila dilatih mengenai tugas pengelasan yang diselia
#🎜 #🎜🎜 🎜🎜 🎜🎜 Berdasarkan penyelidikan terdahulu mengenai pembelajaran imej visual ciri kedalaman blok demi blok, penyelidik menjalankan kajian analisis komponen utama (PCA) mengenai perwakilan token dalam model CRATE dan ViT#🎜🎜 #

Dapat didapati bahawa CRATE masih boleh menangkap sempadan objek dalam imej tanpa latihan penyeliaan segmentasi.
 Selain itu, komponen utama juga menunjukkan penjajaran ciri bahagian yang serupa antara token dan objek, seperti saluran merah yang sepadan dengan kaki kuda
Selain itu, komponen utama juga menunjukkan penjajaran ciri bahagian yang serupa antara token dan objek, seperti saluran merah yang sepadan dengan kaki kuda
Tahap struktur visualisasi PCA model ViT yang diselia adalah agak rendah.
Penilaian kuantitatif
Penilaian kuantitatif
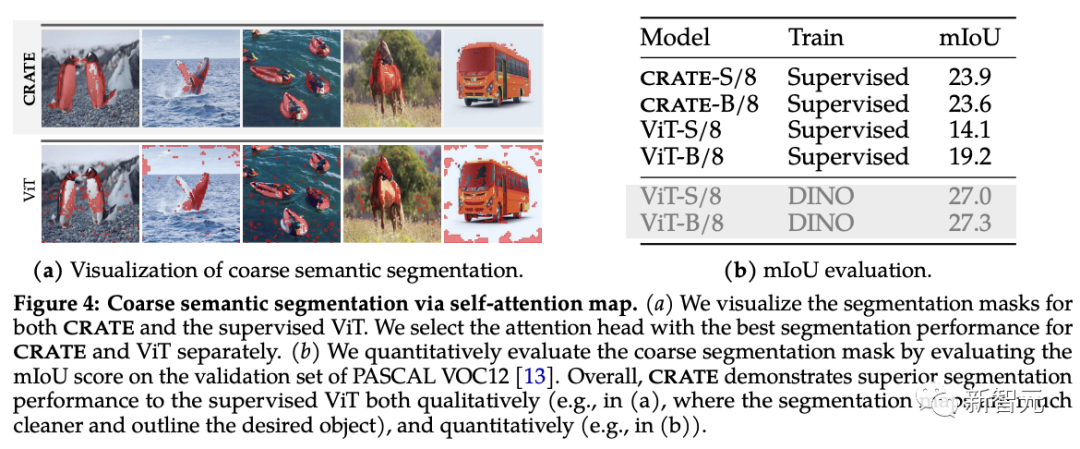
#🎜🎜 ##🎜🎜 segmen penggabungan hartanah CR ##🎜 Teknik segmentasi dan pengesanan objek sedia ada digunakan untuk penilaian Bagi mengukur kualiti segmentasi secara kuantitatif, penyelidik menggunakan peta perhatian kendiri untuk menjana topeng segmentasi dan membandingkannya dengan mIoU standard (min nisbah persilangan atas kesatuan) antara mereka dan topeng sebenar.
Ia boleh dilihat daripada keputusan eksperimen bahawa CRATE jauh lebih baik daripada ViT dari segi skor visual dan mIOU , yang menunjukkan bahawa CRATE Perwakilan dalaman adalah lebih cekap untuk tugas menjana topeng segmentasi 🎜🎜#
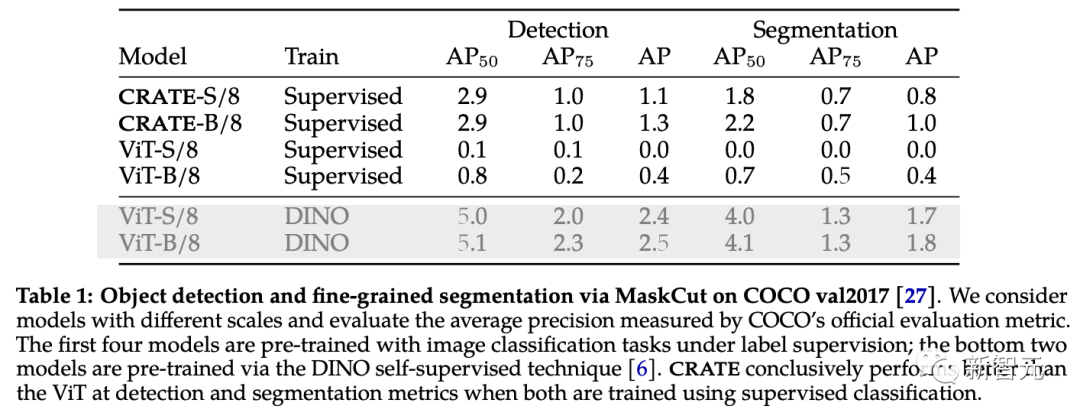
Untuk mengesahkan dan menilai maklumat semantik kaya yang ditangkap oleh CRATE, para penyelidik menggunakan MaskCut, pengesanan dan segmentasi objek yang cekap kaedah, untuk mendapatkan model penilaian automatik tanpa anotasi manual, yang boleh berdasarkan apa yang dipelajari oleh CRATE. Perwakilan Token mengekstrak segmentasi yang lebih halus daripada imej.
keputusan pengelasan CO7 boleh dilihat di CO7 dalam 1CO7 🎜# hasil segmentasi Seperti yang dapat dilihat, perwakilan dalaman CRATE adalah lebih baik daripada ViT yang diselia dalam kedua-dua penunjuk pengesanan dan pembahagian MaskCut dengan ciri ViT yang diselia bahkan tidak dapat menghasilkan topeng pembahagian sama sekali dalam beberapa kes.
Analisis kotak putih tentang keupayaan segmentasi KRAT
Peranan kedalaman dalam KRAT#🎜 🎜 🎜#
 Setiap lapisan CRATE direka bentuk untuk mengikut tujuan konsep yang sama: untuk mengoptimumkan pengurangan kadar jarang dan mengubah pengedaran token kepada bentuk yang padat dan berstruktur.
Selepas menulis semula: Reka bentuk setiap peringkat CRATE mengikut konsep yang sama: mengoptimumkan pengurangan kadar jarang dan mengubah pengedaran token ke dalam bentuk yang padat dan berstruktur
Setiap lapisan CRATE direka bentuk untuk mengikut tujuan konsep yang sama: untuk mengoptimumkan pengurangan kadar jarang dan mengubah pengedaran token kepada bentuk yang padat dan berstruktur.
Selepas menulis semula: Reka bentuk setiap peringkat CRATE mengikut konsep yang sama: mengoptimumkan pengurangan kadar jarang dan mengubah pengedaran token ke dalam bentuk yang padat dan berstruktur
 #🎜 🎜# Andaikan bahawa kemunculan keupayaan pembahagian semantik dalam CRATE adalah serupa dengan "mewakili kelompok token yang tergolong dalam kategori semantik yang serupa dalam Z", prestasi pembahagian CRATE dijangka boleh bertambah baik dengan kedalaman yang semakin meningkat.
#🎜 🎜# Andaikan bahawa kemunculan keupayaan pembahagian semantik dalam CRATE adalah serupa dengan "mewakili kelompok token yang tergolong dalam kategori semantik yang serupa dalam Z", prestasi pembahagian CRATE dijangka boleh bertambah baik dengan kedalaman yang semakin meningkat.
Untuk menguji ini, para penyelidik menggunakan saluran paip MaskCut untuk menilai secara kuantitatif prestasi segmentasi merentas perwakilan dalaman merentas lapisan yang berbeza sambil menggunakan visualisasi PCA untuk memahami cara segmentasi berubah dengan Mendalami dan muncul.
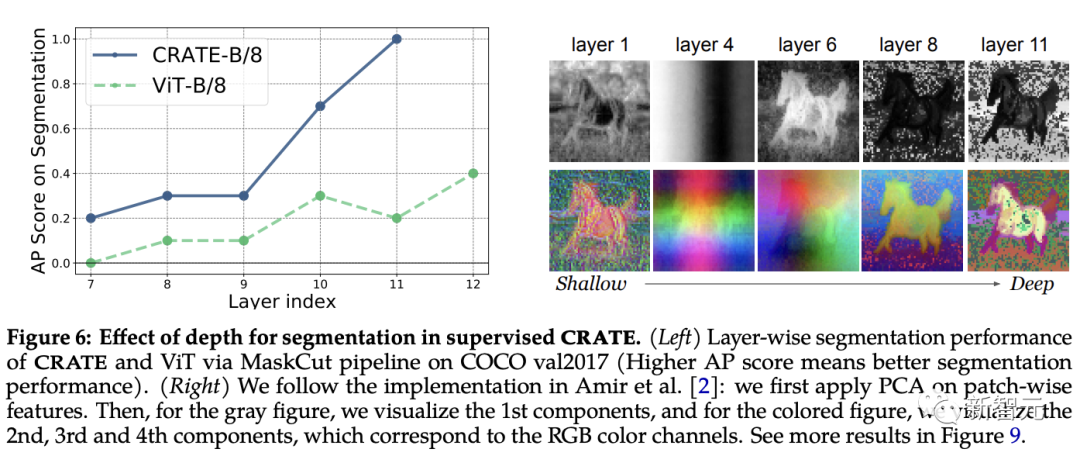
Ia boleh diperhatikan daripada keputusan percubaan bahawa skor segmentasi bertambah baik apabila menggunakan perwakilan daripada lapisan yang lebih dalam, yang sangat konsisten dengan reka bentuk pengoptimuman tambahan CRATE.
Sebaliknya, walaupun prestasi ViT-B/8 bertambah baik sedikit pada lapisan kemudian, skor pembahagiannya jauh lebih rendah daripada CRATE, dan keputusan PCA menunjukkan bahawa perwakilan yang diekstrak daripada lapisan dalam CRATE secara beransur-ansur memberi lebih perhatian kepada objek latar depan , dan dapat menangkap butiran tahap tekstur.
Eksperimen Peleburan KRAT
Blok perhatian (MSSA) dan blok MLP (ISTA) dalam KRAT adalah berbeza daripada blok perhatian dalam ViT
untuk setiap komponen kajian daripada sifat pembahagian CRATE yang muncul, penyelidik memilih tiga varian CRATE: CRATE, CRATE-MHSA dan CRATE-MLP. Varian ini mewakili blok perhatian (MHSA) dan blok MLP dalam ViT masing-masing
Para penyelidik menggunakan tetapan pra-latihan yang sama pada dataset ImageNet-21k, dan kemudian menggunakan penilaian segmentasi kasar dan penilaian segmentasi topeng untuk membandingkan Prestasi secara kuantitatif daripada model yang berbeza.
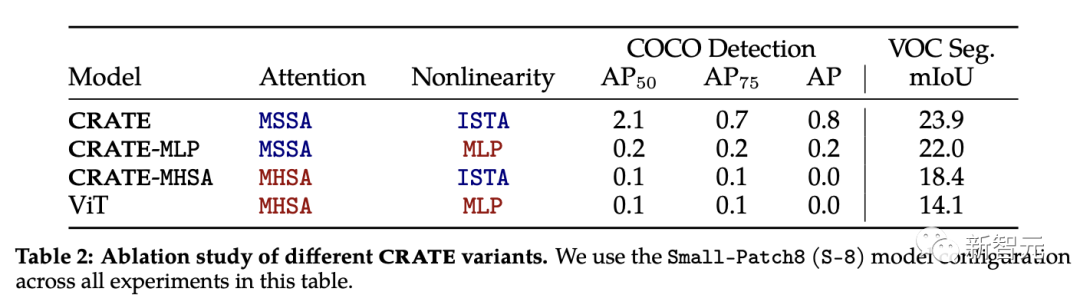
Menurut keputusan percubaan, CRATE mengatasi prestasi seni bina model lain dengan ketara dalam semua tugas. Perlu diingat bahawa walaupun perbezaan seni bina antara MHSA dan MSSA adalah kecil, hanya menggantikan MHSA dalam ViT dengan MSSA dalam CRATE boleh meningkatkan prestasi pembahagian kasar ViT (iaitu Prestasi VOC Seg). Ini membuktikan lagi keberkesanan reka bentuk kotak putih
Kandungan yang perlu ditulis semula ialah: pengenalpastian sifat semantik pengepala perhatian
[CLS] Peta perhatian diri antara token dan token blok imej boleh dilihat Untuk topeng segmentasi yang jelas, secara intuitif, setiap ketua perhatian sepatutnya dapat menangkap beberapa ciri data.
Para penyelidik mula-mula memasukkan imej ke dalam model CRATE, dan kemudian meminta manusia memeriksa dan memilih empat kepala perhatian yang nampaknya mempunyai makna semantik; mereka kemudiannya melakukan visualisasi peta perhatian kendiri pada kepala perhatian ini pada imej input lain.
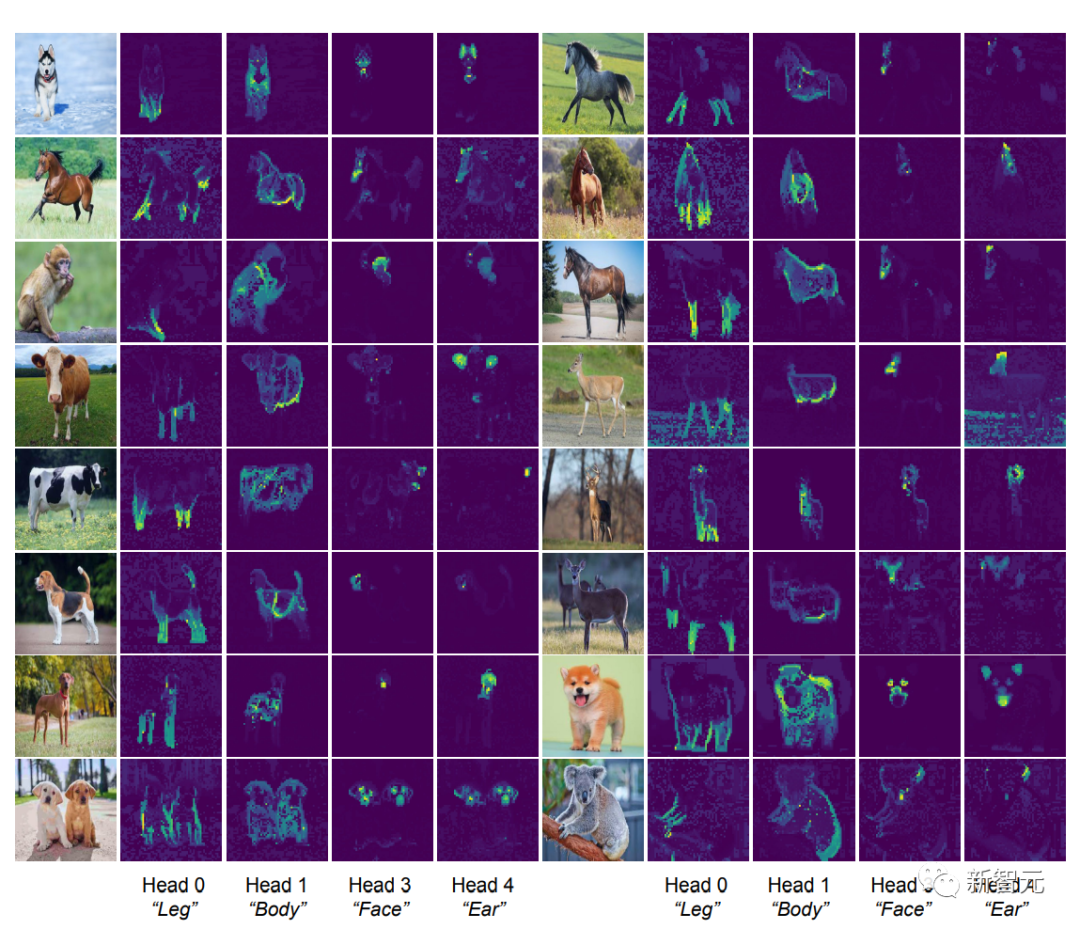
Pemerhatian menunjukkan bahawa setiap kepala perhatian boleh menangkap bahagian objek yang berbeza, malah semantik yang berbeza. Contohnya, kepala perhatian dalam lajur pertama boleh menangkap kaki haiwan yang berbeza, manakala kepala perhatian dalam lajur terakhir boleh menangkap telinga dan kepala
Sejak model bahagian boleh ubah bentuk dan Keupayaan ini untuk menghuraikan input visual kepada sebahagian -seluruh hierarki telah menjadi matlamat seni bina pengiktirafan sejak keluaran rangkaian kapsul, dan model CRATE yang direka bentuk kotak putih juga mempunyai keupayaan ini.
Atas ialah kandungan terperinci Karya baharu Profesor Ma Yi: White-box ViT berjaya mencapai 'kemunculan terbahagi', adakah era pembelajaran mendalam empirikal akan berakhir?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



