Artikel ini mencadangkan kaedah OPRO yang mudah dan berkesan, yang menggunakan model bahasa yang besar sebagai pengoptimum Tugas pengoptimuman boleh diterangkan dalam bahasa semula jadi, yang lebih baik daripada gesaan yang direka oleh manusia.
Pengoptimuman adalah penting dalam semua bidang. Sesetengah pengoptimuman bermula dengan permulaan dan kemudian mengemas kini penyelesaian secara berulang untuk mengoptimumkan fungsi objektif. Algoritma pengoptimuman sedemikian selalunya perlu disesuaikan untuk tugas individu untuk menangani cabaran khusus yang ditimbulkan oleh ruang keputusan, terutamanya untuk pengoptimuman bebas derivatif. Dalam kajian yang akan kami perkenalkan seterusnya, penyelidik mengambil pendekatan berbeza Mereka menggunakan model bahasa besar (LLM) untuk bertindak sebagai pengoptimum dan berprestasi lebih baik daripada petunjuk yang direka oleh manusia pada pelbagai tugas. Penyelidikan ini datang daripada Google DeepMind Mereka mencadangkan kaedah pengoptimuman yang mudah dan berkesan OPRO (Pengoptimuman oleh PROmpting), di mana tugas pengoptimuman boleh diterangkan dalam bahasa semula jadi Sebagai contoh, gesaan LLM boleh menjadi "Ambil nafas panjang, Selesaikan masalah ini langkah demi langkah", atau boleh jadi "Mari kita gabungkan arahan berangka dan pemikiran yang jelas untuk menguraikan jawapan dengan cepat dan tepat" dan sebagainya. Dalam setiap langkah pengoptimuman, LLM menjana penyelesaian baharu berdasarkan pembayang daripada penyelesaian yang dijana sebelum ini dan nilainya, kemudian menilai penyelesaian baharu dan menambahkannya ke langkah pengoptimuman seterusnya Prompt. Akhir sekali, kajian menggunakan kaedah OPRO untuk regresi linear dan masalah jurujual perjalanan (masalah NP yang terkenal), dan kemudian meneruskan pengoptimuman segera, dengan matlamat mencari arahan yang memaksimumkan ketepatan tugas. Kertas kerja ini menjalankan penilaian menyeluruh bagi berbilang LLM, termasuk teks-bison dan Palm 2-L dalam keluarga model PaLM-2, dan gpt-3.5-turbo dan gpt-4 dalam keluarga model GPT. Percubaan mengoptimumkan gesaan pada GSM8K dan Big-Bench Hard Hasilnya menunjukkan bahawa gesaan terbaik yang dioptimumkan oleh OPRO adalah 8% lebih tinggi daripada gesaan yang direka secara manual pada GSM8K dan lebih tinggi daripada gesaan yang direka secara manual pada tugasan Big-Bench. Keluaran sehingga 50%. 
Alamat kertas: https://arxiv.org/pdf/2309.03409.pdfChengrun Yang, pengarang pertama kertas kerja dan saintis penyelidikan di Google DeepMind, berkata: "Untuk melaksanakan pengoptimuman segera, kami bermula dari 'Mari mulakan' Bermula dengan arahan asas seperti "Selesaikan Masalah", atau bahkan rentetan kosong, arahan yang dijana oleh OPRO secara beransur-ansur akan menjadikan prestasi LLM lebih baik secara beransur-ansur Keluk prestasi menaik yang ditunjukkan dalam rajah di bawah kelihatan sama seperti situasi dalam pengoptimuman tradisional! manusia, dan boleh dipindahkan ke tugasan yang serupa. IT dan teks-bison adalah lebih ringkas, manakala arahan GPT Arahannya panjang dan terperinci. Walaupun beberapa arahan peringkat atas mengandungi gesaan "langkah demi langkah", OPRO boleh mencari ungkapan semantik lain dan mencapai ketepatan yang setanding atau lebih baik. Walau bagaimanapun, sesetengah penyelidik berkata: "Tarik nafas dalam-dalam dan ambil satu langkah pada satu masa" Petua ini sangat berkesan pada PaLM-2 Google (kadar ketepatan 80.2). Tetapi kami tidak dapat menjamin bahawa ia berfungsi pada semua model dan dalam semua situasi, jadi kami tidak seharusnya menggunakannya secara membuta tuli di mana-mana sahaja. 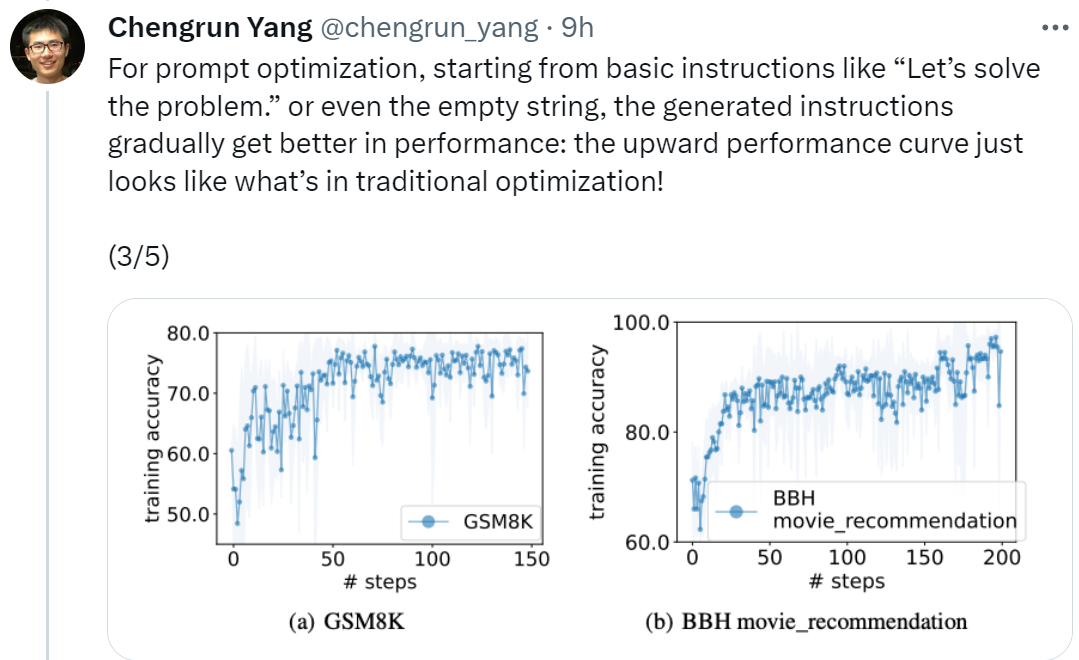
OPRO: LLM sebagai pengoptimumRajah 2 menunjukkan rangka kerja keseluruhan OPRO. Pada setiap langkah pengoptimuman, LLM menjana penyelesaian calon kepada tugas pengoptimuman berdasarkan penerangan masalah pengoptimuman dan penyelesaian yang dinilai sebelum ini dalam meta-prompt (bahagian bawah kanan Rajah 2). Seterusnya, LLM menilai penyelesaian baharu dan menambahkannya pada petua meta untuk proses pengoptimuman seterusnya. Proses pengoptimuman ditamatkan apabila LLM gagal mencadangkan penyelesaian baharu dengan skor pengoptimuman yang lebih baik atau mencapai bilangan maksimum langkah pengoptimuman. 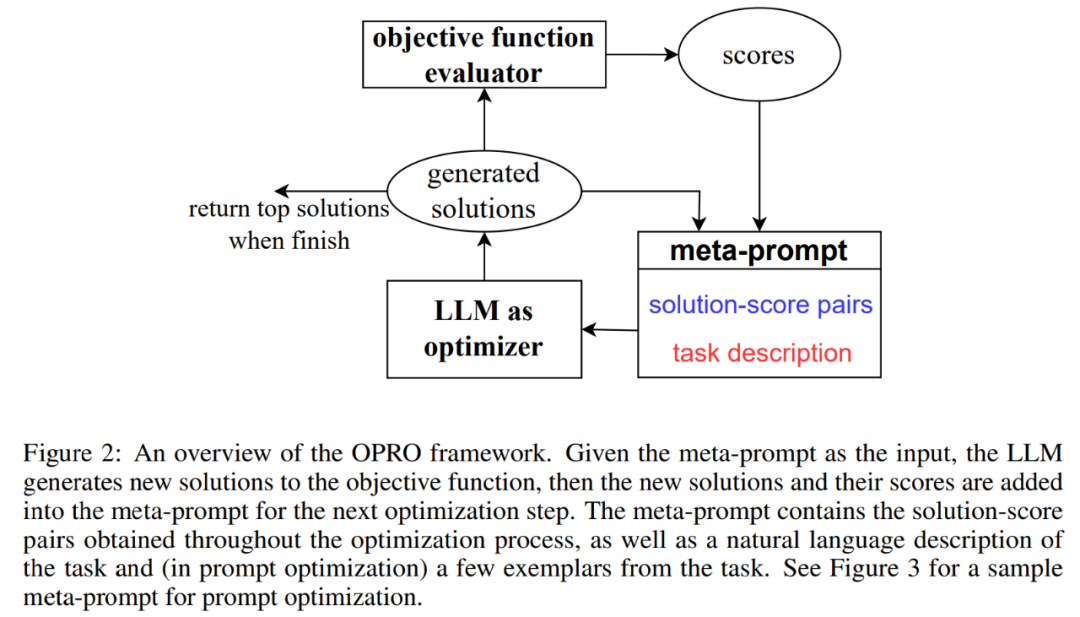
Rajah 3 menunjukkan contoh. Petunjuk meta mengandungi dua kandungan teras, bahagian pertama ialah pembayang yang dijana sebelum ini dan ketepatan latihannya yang sepadan dengan huraian masalah pengoptimuman, termasuk beberapa contoh yang dipilih secara rawak daripada set latihan untuk menjadi contoh tugas yang diminati. 
Artikel ini mula-mula menunjukkan potensi LLM sebagai pengoptimum "pengoptimuman matematik". Keputusan dalam masalah regresi linear ditunjukkan dalam Jadual 2: 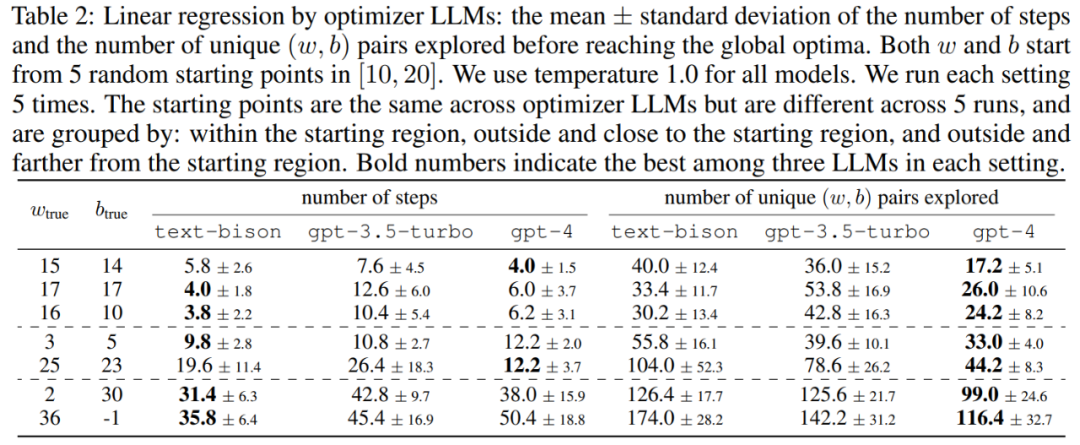
Seterusnya, kertas kerja juga meneroka keputusan OPRO mengenai masalah jurujual kembara (TSP) Secara khusus, TSP merujuk kepada set yang diberikan daripada n nod dan koordinatnya, tugas TSP adalah untuk mencari laluan terpendek bermula dari nod permulaan, merentasi semua nod dan akhirnya kembali ke nod permulaan. 
Dalam percubaan, artikel ini menggunakan PaLM 2-L yang telah terlatih, PaLM 2-L yang diperhalusi arahan, bison teks, gpt-3.5-turbo, gpt-3.5 dan gpt-4 sebagai LLM Optimizer; PaLM 2-L terlatih dan bison teks sebagai LLM penjaring. Tanda aras penilaian GSM8K adalah mengenai matematik sekolah rendah, dengan 7473 sampel latihan dan 1319 sampel ujian penanda aras Big-Bench Hard (BBH) merangkumi pelbagai topik di luar penaakulan aritmetik, termasuk operasi penaakulan simbolik dan akal; . Rajah 1 (a) menunjukkan keluk pengoptimuman segera menggunakan PaLM 2-L terlatih sebagai penjaring dan PaLM 2-L-IT yang dioptimumkan sebagai pengoptimuman lengkung menunjukkan aliran menaik secara keseluruhan, dengan beberapa lonjakan berlaku sepanjang proses pengoptimuman: 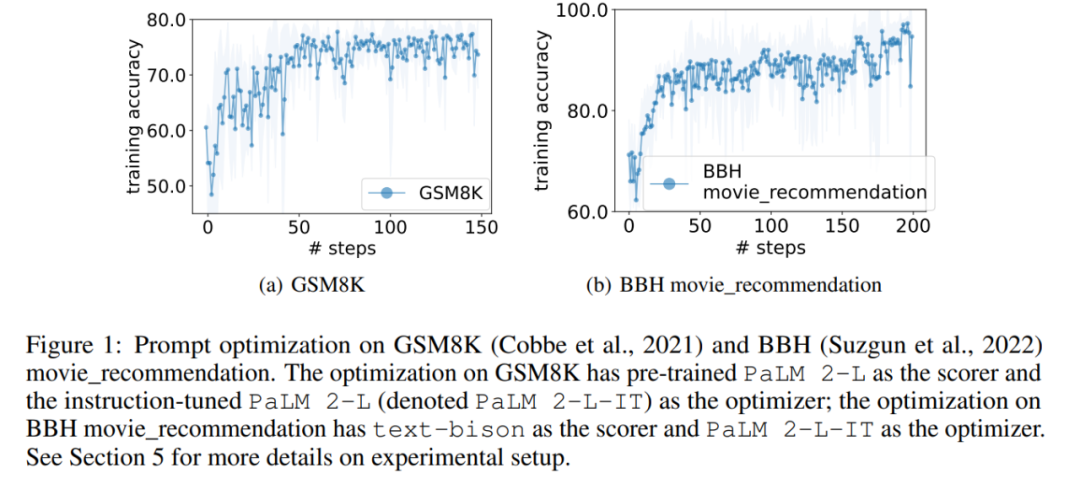
Seterusnya, artikel ini menunjukkan hasil penggunaan penjaring bison teks dan pengoptimum PaLM 2-L-IT untuk menjana arahan Q_begin. Artikel ini Bermula dari arahan kosong, ketepatan latihan pada masa ini ialah 57.1, dan kemudian ketepatan latihan mula meningkat. Keluk pengoptimuman dalam Rajah 4 (a) menunjukkan arah aliran menaik yang serupa, di mana terdapat beberapa lonjakan dalam ketepatan latihan: 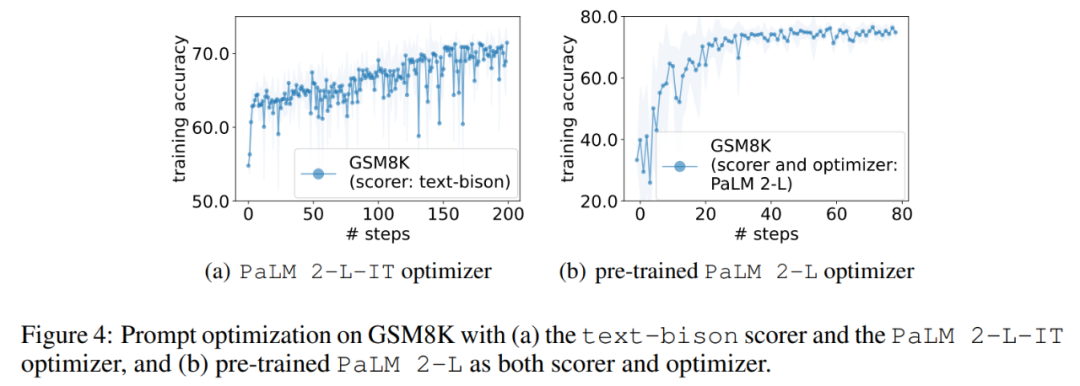
Rajah 23 perbezaan visual menunjukkan perbezaan secara visual bagi setiap rajah 23 tugasan berbanding arahan "Mari fikir langkah demi langkah" antara tugasan BBH. Menunjukkan bahawa OPRO mencari arahan lebih baik daripada "mari kita fikir langkah demi langkah". Terdapat kelebihan besar pada hampir semua tugasan: arahan yang terdapat dalam kertas ini mengatasinya dengan lebih daripada 5% pada tugasan 19/23 menggunakan penggred PaLM 2-L dan pada tugasan 15/23 menggunakan penggred teks-bison. 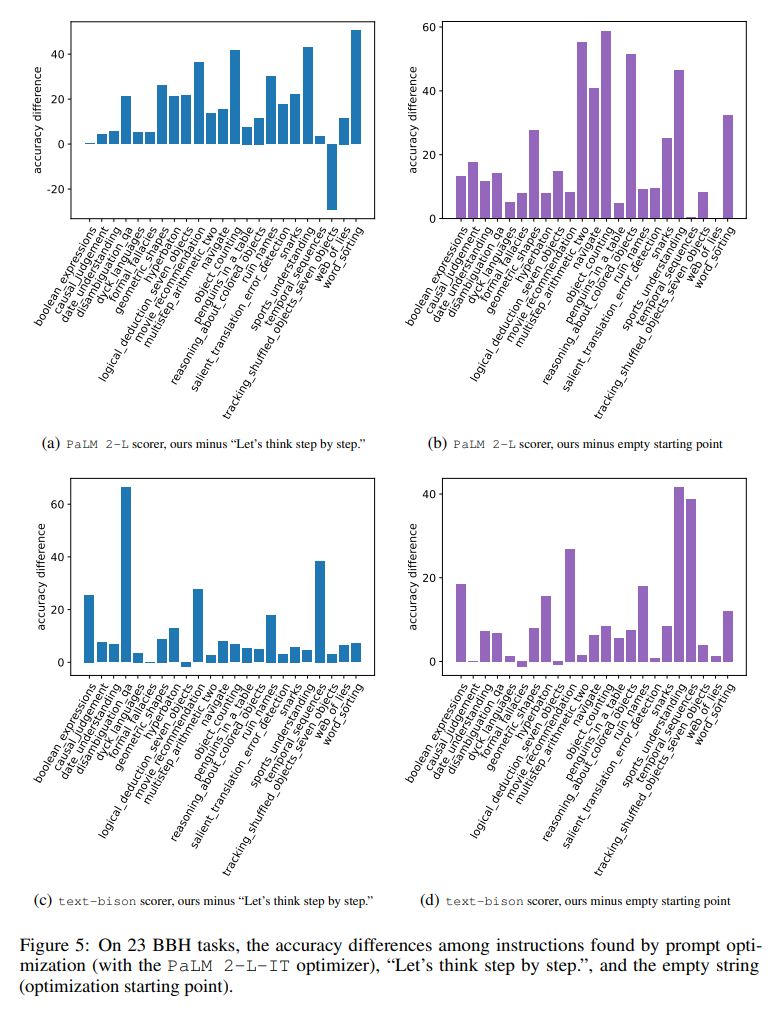
Sama seperti GSM8K, kertas kerja ini memerhatikan bahawa keluk pengoptimuman hampir semua tugasan BBH menunjukkan arah aliran menaik, seperti ditunjukkan dalam Rajah 6. 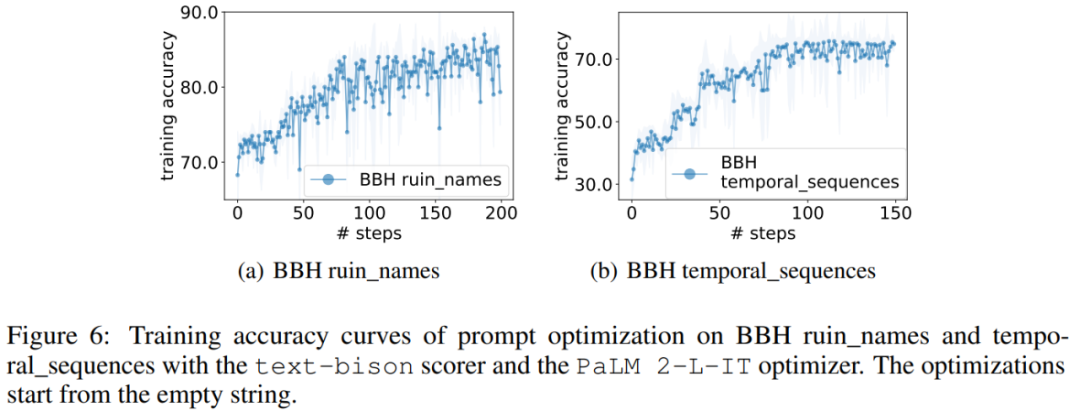
Atas ialah kandungan terperinci DeepMind mendapati bahawa kaedah segera untuk menyampaikan 'tarik nafas dalam-dalam dan ambil satu langkah pada satu masa' kepada model besar adalah amat berkesan.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



