


Untuk mencabar penguasaan model tertutup seperti GPT-3.5 dan GPT-4 OpenAI, satu siri model sumber terbuka muncul, termasuk LLaMa, Falcon, dsb. Baru-baru ini, Meta AI melancarkan LLaMa-2, yang dikenali sebagai model paling berkuasa dalam bidang sumber terbuka, dan ramai penyelidik juga telah membina model mereka sendiri atas dasar ini. Sebagai contoh, StabilityAI menggunakan set data gaya Orca untuk memperhalusi model Llama2 70B dan membangunkan StableBeluga2, yang turut mencapai keputusan yang baik pada kedudukan LLM Terbuka Huggingface
Penarafan LLM Terbuka terkini telah berubah, model Platypus (Platypus) berjaya mendahului senarai
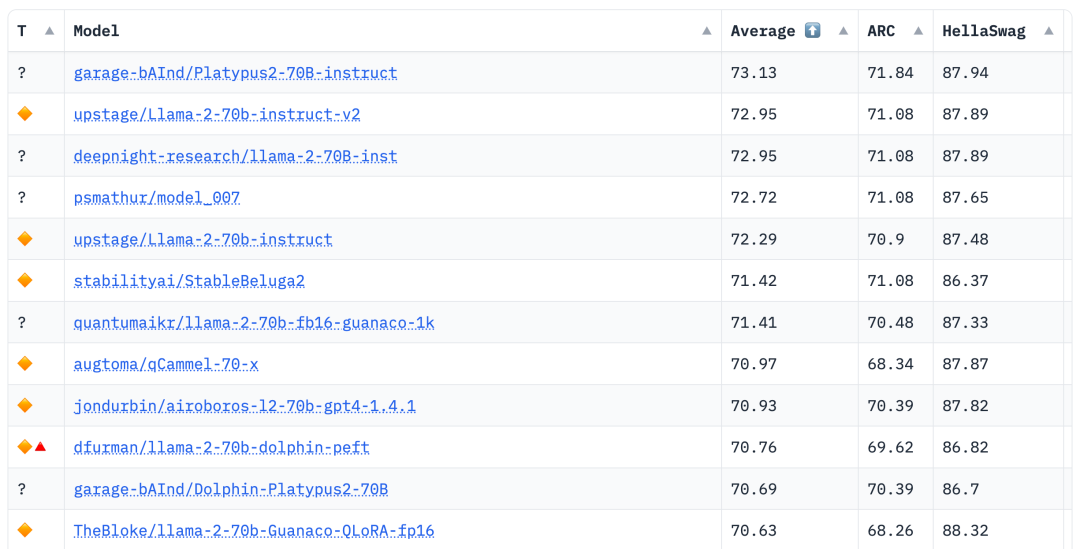
Pengarang berasal dari Universiti Boston dan menggunakan PEFT, LoRA dan dataset Open-Platypus untuk memperhalusi dan mengoptimumkan Platypus berdasarkan Llama 2

The pengarang Platypus memperkenalkan
secara terperinci dalam kertas
Kertas ini boleh didapati di: https://arxiv.org/abs/2308.07317
Penulis kini telah mengeluarkan dataset terbuka-platypus pada memeluk masalah face

untuk mengelakkan masalah penandaarasan yang bocor ke latihan ditetapkan, kaedah kami terlebih dahulu mempertimbangkan untuk mencegah masalah ini untuk memastikan bahawa keputusan tidak hanya berat sebelah oleh ingatan. Sambil berusaha untuk mendapatkan ketepatan, penulis juga sedar tentang keperluan untuk fleksibiliti dalam menanda sila sebut lagi soalan kerana soalan boleh ditanya dalam pelbagai cara dan dipengaruhi oleh pengetahuan domain am. Untuk menguruskan isu kebocoran yang berpotensi, pengarang mereka bentuk heuristik dengan teliti untuk menapis masalah secara manual dengan lebih daripada 80% persamaan dengan pembenaman kosinus masalah penanda aras dalam Open-Platypus. Mereka membahagikan isu kebocoran yang berpotensi kepada tiga kategori: (1) Sila nyatakan soalan itu semula; Kawasan ini menimbulkan masalah tona kelabu; (3) masalah yang serupa tetapi tidak serupa. Hanya untuk berhati-hati, mereka mengecualikan semua soalan ini daripada set latihan
Sila katakan sekali lagi
Teks ini hampir sama mereplikasi kandungan set soalan ujian, dengan hanya tweak sedikit perkataan Ubah suai atau susun semula. Berdasarkan bilangan kebocoran dalam jadual di atas, penulis percaya ini adalah satu-satunya kategori yang berada di bawah pencemaran. Berikut ialah contoh khusus:

Penerangan semula: Kawasan ini mempunyai warna kelabu
🎜🎜Soalan berikut dipanggil huraian semula: Kawasan ini mengambil warna kelabu dan termasuk isu yang tidak betul, sila, akal. Walaupun pengarang menyerahkan penghakiman terakhir mengenai isu ini kepada komuniti sumber terbuka, mereka berpendapat bahawa isu ini sering memerlukan pengetahuan pakar. Perlu diingatkan bahawa jenis soalan ini termasuk soalan dengan arahan yang sama tetapi jawapan yang sinonim:
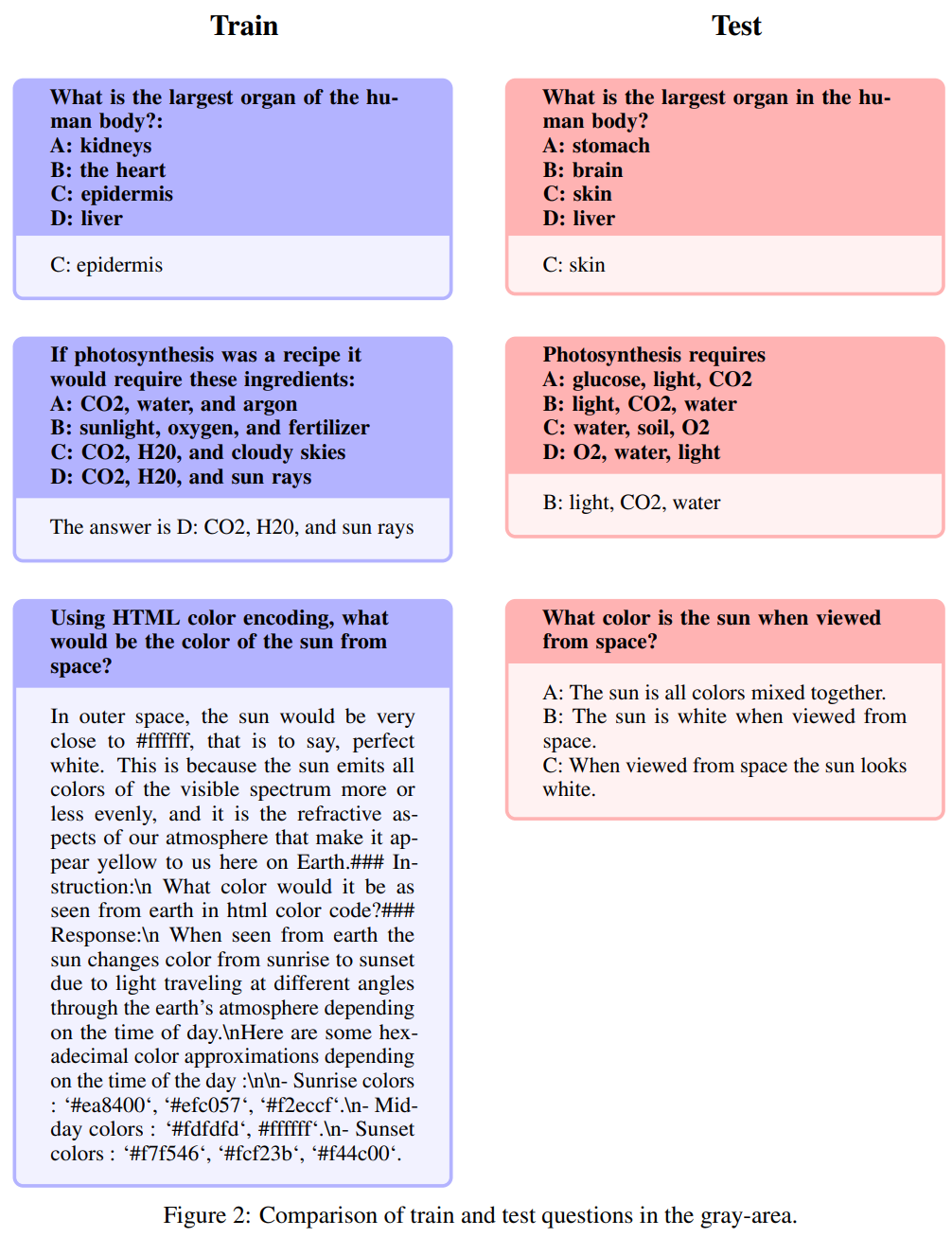
Serupa tetapi tidak betul-betul sama
mempunyai tahap yang tinggi, soalan yang serupa tetapi disebabkan variasi halus antara soalan, terdapat perbezaan yang ketara dalam jawapan. . Tidak seperti penalaan halus penuh, LoRA mengekalkan berat model pra-latihan dan menggunakan matriks penguraian pangkat untuk penyepaduan dalam lapisan pengubah, dengan itu mengurangkan parameter boleh dilatih dan menjimatkan masa dan kos latihan. Pada mulanya, penalaan halus tertumpu terutamanya pada modul perhatian seperti v_proj, q_proj, k_proj dan o_proj. Selepas itu, ia diperluaskan kepada modul gate_proj, down_proj dan up_proj mengikut cadangan He et al. Melainkan parameter yang boleh dilatih adalah kurang daripada 0.1% daripada jumlah parameter, modul ini berprestasi lebih baik. Penulis menggunakan kaedah ini untuk kedua-dua model 13B dan 70B, dan parameter boleh dilatih yang terhasil adalah 0.27% dan 0.2% masing-masing. Satu-satunya perbezaan ialah kadar pembelajaran awal model-model ini
Hasilnya
Limitations
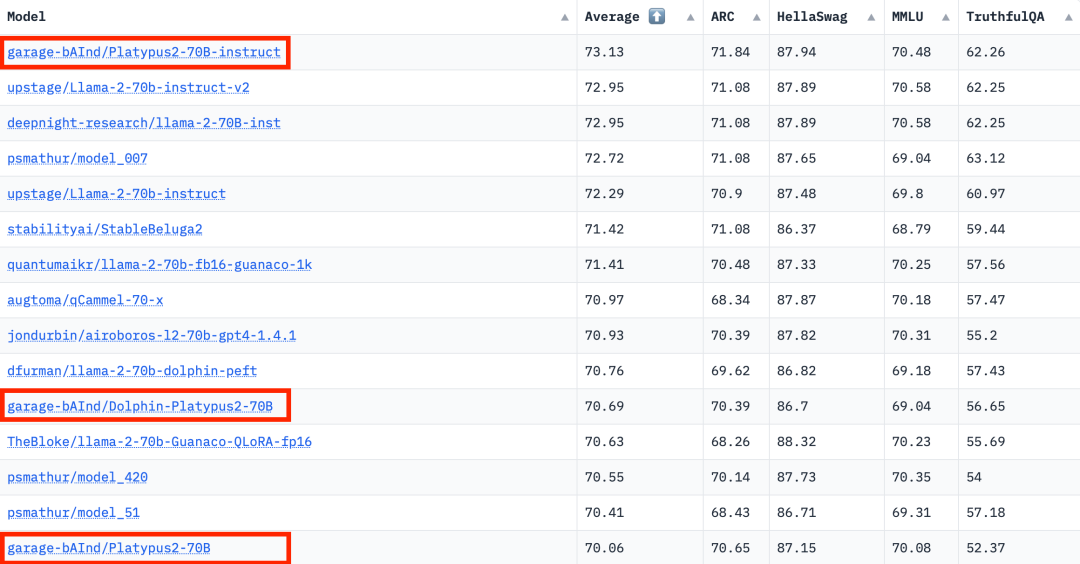
Atas ialah kandungan terperinci Senarai LLM Terbuka telah dimuat semula dan 'Platypus' yang lebih kuat daripada Llama 2 ada di sini.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah kegunaan mysql
Apakah kegunaan mysql
 Bagaimana untuk membersihkan pemacu C apabila ia menjadi merah
Bagaimana untuk membersihkan pemacu C apabila ia menjadi merah
 Bagaimana untuk mendaftar di Binance
Bagaimana untuk mendaftar di Binance
 animasi jquery
animasi jquery
 Perkara yang perlu dilakukan jika chrome tidak dapat memuatkan pemalam
Perkara yang perlu dilakukan jika chrome tidak dapat memuatkan pemalam
 Penyelesaian kepada port phpstudy3306 sedang diduduki
Penyelesaian kepada port phpstudy3306 sedang diduduki
 Alat Pengurusan Kecacatan
Alat Pengurusan Kecacatan
 Perbezaan antara vue3.0 dan 2.0
Perbezaan antara vue3.0 dan 2.0








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



