


Alumnus Kelas Tsinghua Yao Chen Danqi memberikan ucapan terbaru di ACL 2023!
Topik ini masih menjadi hala tuju penyelidikan yang sangat hangat baru-baru ini -
seperti GPT-3, PaLM dan lain-lain (besar)model bahasa, adakah mereka perlu bergantung pada pendapatan untuk menebus kekurangan mereka sendiri, supaya dapat melaksanakan aplikasi mereka dengan lebih baik?
Dalam ucapan ini, beliau dan tiga penceramah lain bersama-sama memperkenalkan beberapa hala tuju penyelidikan utama mengenai topik ini, termasuk kaedah latihan, aplikasi dan cabaran. .
 Gambar
Gambar
Adapun kesan khusus ucapan ini? Beberapa netizen secara langsung berkata "recommend" ke ruangan komen.
 Gambar
Gambar
Jadi, apa sebenarnya yang mereka bualkan dalam ucapan selama 3 jam ini? Apakah tempat lain yang patut didengari?
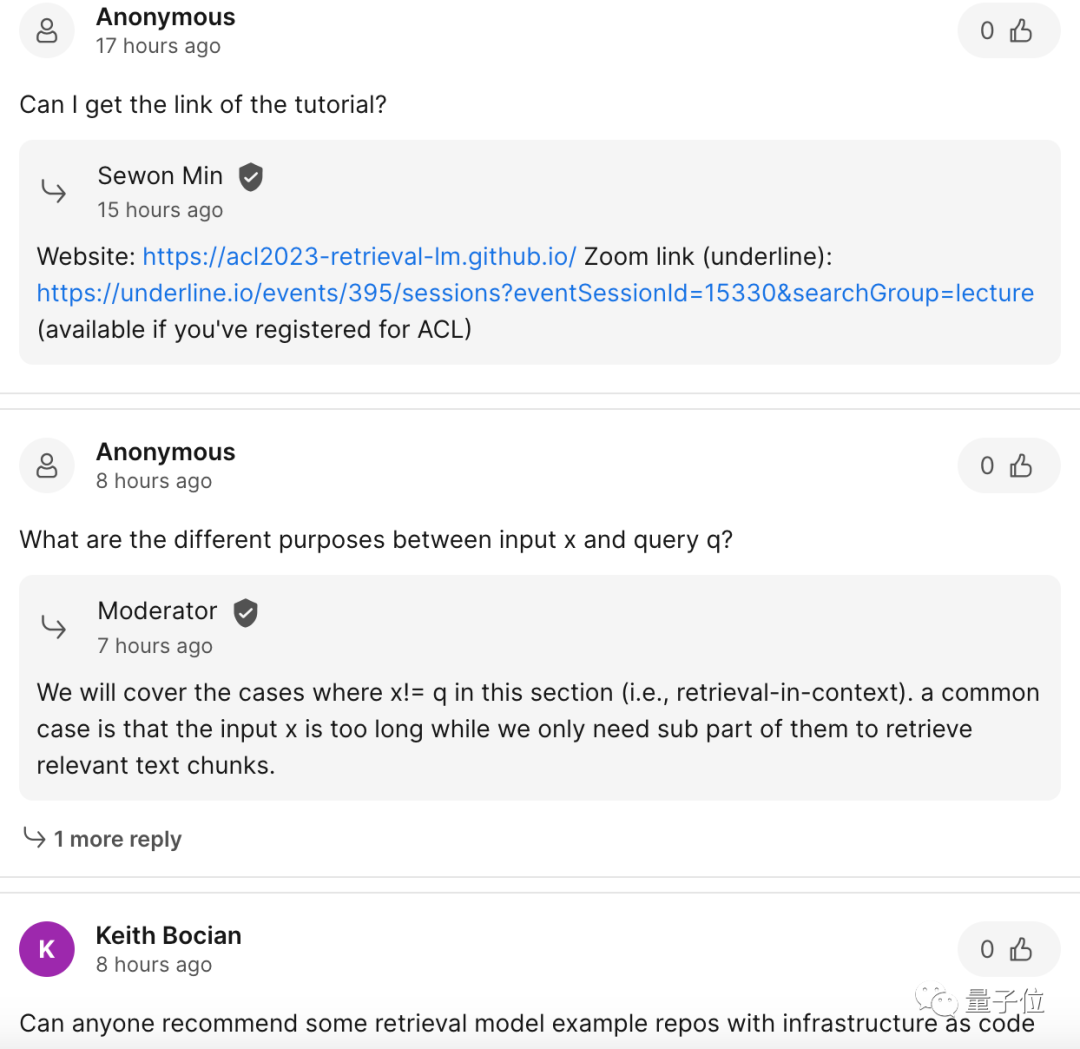
Mengapa model besar memerlukan pangkalan data "plug-in"?  Tema teras ucapan ini ialah "Model Bahasa berasaskan Retrieval", yang merangkumi dua elemen: Retrieval
Tema teras ucapan ini ialah "Model Bahasa berasaskan Retrieval", yang merangkumi dua elemen: Retrieval
Model Bahasa
. Daripadadefinisi, ia merujuk kepada "memasukkan" pangkalan data perolehan semula data ke model bahasa, mendapatkan semula pangkalan data ini apabila melakukan inferens (dan operasi lain) , dan akhirnya mengeluarkan berdasarkan hasil carian.
Repositori data pemalam jenis ini juga dipanggil model separuh parametrik atau model bukan parametrik. . terdapat tiga masalah utama:1, Bilangan parameter terlalu besar, dan jika latihan semula berdasarkan data baru, kos pengiraan adalah terlalu tinggi;
2,Memori tidak baik
(Menghadapi panjang teks, saya terlupa untuk mengingati yang berikut Di atas), ia akan menyebabkan halusinasi dari semasa ke semasa, dan mudah untuk membocorkan data 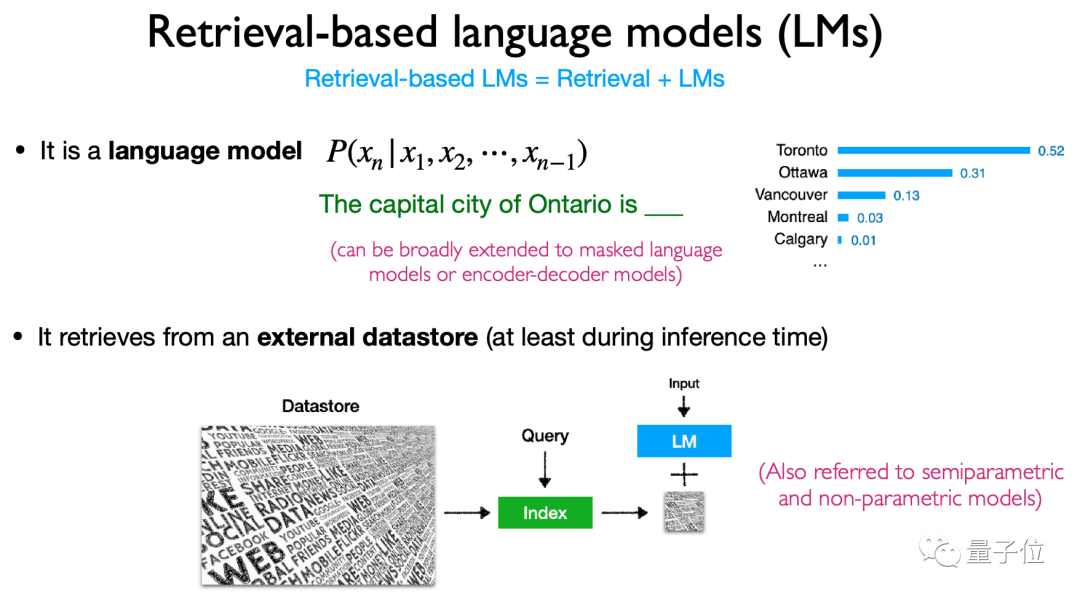 3 Dengan jumlah parameter semasa, adalah mustahil untuk mengingati semua pengetahuan.
3 Dengan jumlah parameter semasa, adalah mustahil untuk mengingati semua pengetahuan.
Dalam kes ini, korpus pengambilan luaran telah dicadangkan, iaitu untuk "memasang" pangkalan data untuk model bahasa besar, supaya ia boleh menjawab soalan dengan mencari maklumat pada bila-bila masa, dan kerana pangkalan data ini boleh dikemas kini pada bila-bila masa, tidak perlu risau tentang isu kos latihan semula. Selepas memperkenalkan definisi dan latar belakang, tiba masanya untuk membincangkan
seni bina, latihan, pelbagai mod, aplikasi dan cabaran khusus arah penyelidikan ini. Dalam
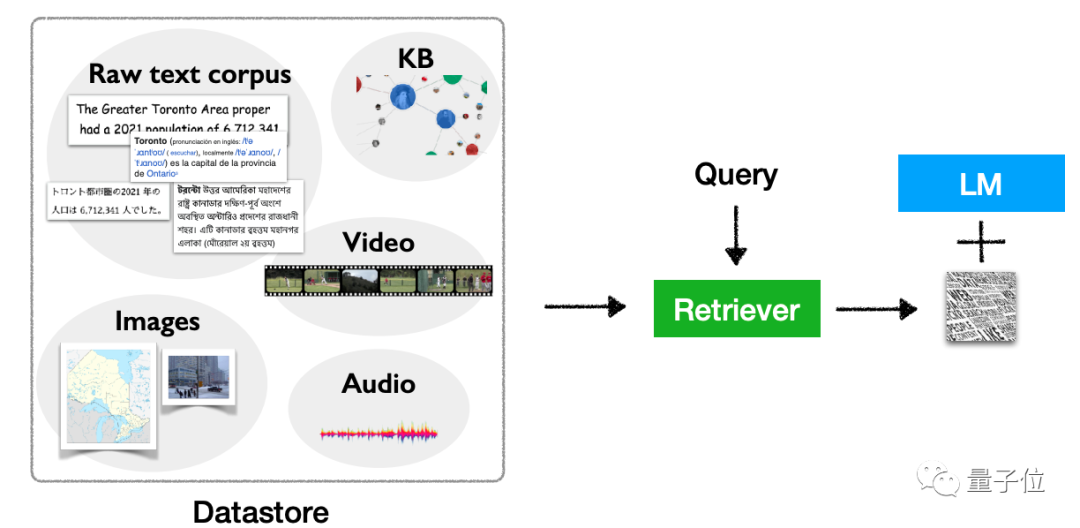
architecture, ia terutamanya memperkenalkan kandungan, kaedah pengambilan dan "masa" pengambilan berdasarkan pengambilan model bahasa. Secara khusus, model jenis ini terutamanya mendapatkan semula token, blok teks dan perkataan entiti(sebutan entiti)
Kaedah dan masa penggunaan perolehan juga sangat pelbagai, menjadikannya seni bina model yang sangat fleksibel. . pembelajaran( latihan bersama) dan kaedah lain.
Gambar
Bagiaplikasi, model jenis ini melibatkan banyak perkara bukan sahaja dalam penjanaan kod, pengelasan, NLP intensif pengetahuan dan tugasan lain, tetapi juga melalui penalaan halus, pengukuhan. pembelajaran, berdasarkan Kaedah seperti kata gesaan carian boleh digunakan.
Senario aplikasi juga sangat fleksibel, termasuk senario long-tail, senario yang memerlukan kemas kini pengetahuan, dan senario yang melibatkan privasi dan keselamatan, dll. Model jenis ini mempunyai tempat untuk digunakan.Sudah tentu, ia bukan hanya tentang teks. Model jenis ini juga mempunyai potensi untuk pengembangan multimodal, membolehkan ia digunakan untuk tugas selain teks.
 Gambar
Gambar
Nampaknya model jenis ini mempunyai banyak kelebihan, tetapi terdapat juga beberapa cabaran berdasarkan model bahasa berasaskan pencarian semula.
Dalam ucapan "pengakhiran" terakhirnya, Chen Danqi menekankan beberapa masalah utama yang perlu diselesaikan dalam arah penyelidikan ini.
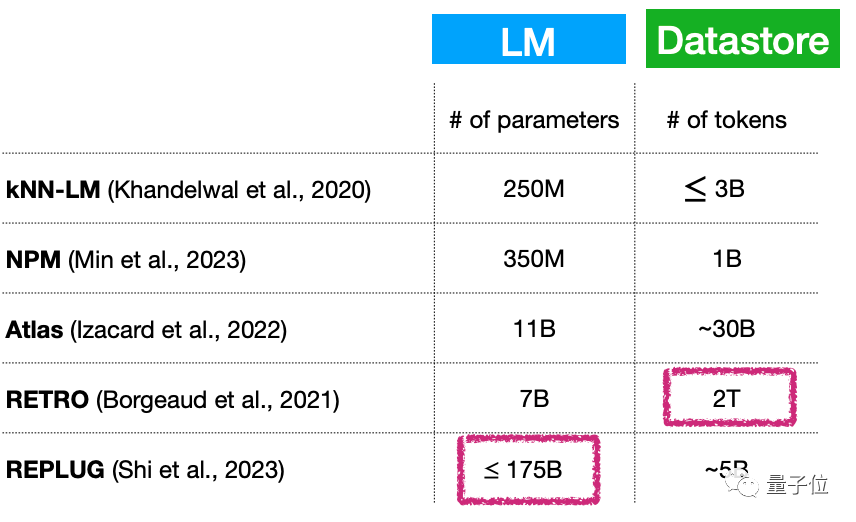
Pertama, model bahasa kecil + (berkembang secara berterusan) pangkalan data yang besar, adakah ini bermakna bilangan parameter model bahasa masih sangat besar? Bagaimana untuk menyelesaikan masalah ini?
Sebagai contoh, walaupun bilangan parameter model jenis ini boleh menjadi sangat kecil, hanya 7 bilion parameter, pangkalan data plug-in boleh mencapai 2T...
 Gambar
Gambar
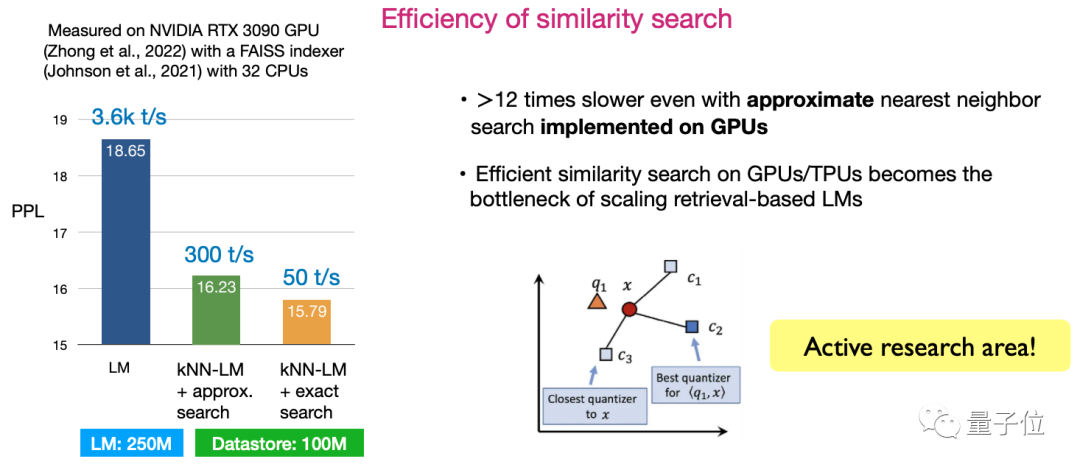
Kedua, kecekapan persamaan cari. Cara mereka bentuk algoritma untuk memaksimumkan kecekapan carian kini merupakan hala tuju penyelidikan yang sangat aktif.
 Gambar
Gambar
Ketiga, selesaikan tugasan bahasa yang kompleks. Termasuk tugas penjanaan teks terbuka dan tugas penaakulan teks yang kompleks, cara menggunakan model bahasa berasaskan perolehan untuk menyelesaikan tugasan ini juga merupakan arah yang memerlukan penerokaan berterusan.
 Gambar
Gambar
Sudah tentu, Chen Danqi juga menyebut bahawa topik ini bukan sahaja cabaran, tetapi juga peluang penyelidikan. Kawan-kawan yang masih tercari-cari topik tesis, boleh pertimbangkan sama ada nak tambah dalam senarai kajian~
Perlu disebut bahawa ucapan ini bukanlah topik "out of thin air". laman web Pautan kepada kertas kerja yang dirujuk dalam ucapan telah dikeluarkan.
Dari seni bina model, kaedah latihan, aplikasi, pelbagai mod hingga cabaran, jika anda berminat dalam mana-mana bahagian topik ini, anda boleh pergi ke laman web rasmi untuk mencari kertas klasik yang sepadan:
 Gambar
Gambar
Untuk ucapan bermaklumat seperti itu, empat penceramah utama bukan tanpa latar belakang semasa ucapan itu, mereka juga sabar menjawab soalan yang dikemukakan oleh penonton.
Mari kita bincang dahulu siapa penceramah di Kangkang.
Yang pertama ialah Chen Danqi, Penolong Profesor Sains Komputer di Princeton University yang mengetuai ucapan ini.
 Pictures
Pictures
Beliau adalah salah seorang sarjana muda Cina paling popular dalam bidang sains komputer baru-baru ini dan juga merupakan alumni Kelas Tsinghua Yao pada tahun 2008.
Dalam bulatan pertandingan informatika, dia agak legenda - Algoritma bahagi dan takluk CDQ dinamakan sempena namanya. Pada 2008, dia memenangi pingat emas IOI bagi pihak pasukan China.
Dan tesis kedoktorannya setebal 156 halaman "Neural Reading Comprehension and Beyond" pernah menjadi sangat popular Bukan sahaja memenangi Anugerah Tesis Kedoktoran Terbaik Stanford pada tahun itu, ia juga menjadi topik paling popular di Universiti Stanford dalam sepuluh tahun yang lalu. .
Kini, selain menjadi penolong profesor sains komputer di Universiti Princeton, Chen Danqi juga merupakan ketua bersama pasukan NLP sekolah dan ahli pasukan AIML.
Arah penyelidikannya tertumpu terutamanya pada pemprosesan bahasa semula jadi dan pembelajaran mesin, dan dia berminat dengan kaedah mudah dan boleh dipercayai yang boleh dilaksanakan, berskala dan boleh digeneralisasikan dalam masalah praktikal.
Juga dari Universiti Princeton, terdapat perantis Chen Danqi Zhong Zexuan(Zexuan Zhong).
 Pictures
Pictures
Zhong Zexuan ialah pelajar kedoktoran tahun empat di Princeton University. Saya lulus dari Universiti Illinois di Urbana-Champaign dengan ijazah sarjana di bawah penyeliaan Xie Tao Saya lulus dari Jabatan Sains Komputer di Universiti Peking dengan ijazah sarjana muda dan bekerja sebagai pelatih di Microsoft Research Asia di bawah penyeliaan; Nie Zaiqing.
Penyelidikan terbaharunya memfokuskan pada mengekstrak maklumat berstruktur daripada teks tidak berstruktur, mengekstrak maklumat fakta daripada model bahasa pra-latihan, menganalisis keupayaan generalisasi model perolehan padat dan membangunkan latihan untuk teknologi model bahasa berasaskan perolehan.
Selain itu, penceramah utama termasuk Akari Asai dan Sewon Min dari Washington University.
 Pictures
Pictures
Akari Asai ialah pelajar kedoktoran tahun empat di Universiti Washington dalam jurusan pemprosesan bahasa semula jadi Dia lulus dari Universiti Tokyo di Jepun dengan ijazah sarjananya.
Dia terutamanya berminat untuk membangunkan sistem pemprosesan bahasa semula jadi yang boleh dipercayai dan boleh disesuaikan untuk meningkatkan keupayaan pemerolehan maklumat.
Baru-baru ini, penyelidikannya tertumpu terutamanya pada sistem perolehan pengetahuan am, model NLP adaptif yang cekap dan bidang lain.
 Pictures
Pictures
Sewon Min ialah calon kedoktoran dalam Kumpulan Pemprosesan Bahasa Semulajadi Universiti Washington Semasa pengajian kedoktorannya, beliau bekerja sambilan sebagai penyelidik di Meta AI selama empat tahun dari Universiti Kebangsaan Seoul dengan ijazah sarjana muda.
Baru-baru ini, dia tertumpu terutamanya pada pemodelan bahasa, pencarian semula dan persilangan kedua-duanya.
Semasa ucapan, para hadirin juga dengan penuh semangat bertanyakan banyak soalan, seperti mengapa kebingungan(perplexity) digunakan sebagai penunjuk utama ucapan.
 Gambar
Gambar
Penceramah memberikan jawapan yang teliti:
Apabila membandingkan model bahasa parameter, kebingungan (PPL) sering digunakan. Tetapi sama ada penambahbaikan dalam kebingungan boleh diterjemahkan ke dalam aplikasi hiliran kekal sebagai persoalan kajian.
Penyelidikan kini telah menunjukkan bahawa kebingungan berkorelasi baik dengan tugas hiliran (terutamanya tugas penjanaan) dan kebingungan itu sering memberikan hasil yang sangat stabil, dan ia boleh dinilai pada data penilaian berskala besar (Data penilaian tidak dilabelkan berbanding dengan tugas hiliran , yang mungkin dipengaruhi oleh sensitiviti isyarat dan kekurangan data berlabel berskala besar, yang membawa kepada keputusan yang tidak stabil) .
 Gambar
Gambar
Sesetengah netizen mengemukakan soalan ini:
Berkenaan kenyataan bahawa "kos latihan model bahasa adalah tinggi, dan memperkenalkan pengambilan semula mungkin menyelesaikan masalah ini", anda hanya menggantikan kerumitan masa dengan ruang Adakah kerumitan masa kerumitan (storan data) ?

Jawapan yang diberikan oleh penceramah ialah Mak Cik Jiang:
Tumpuan perbincangan kami ialah cara mengurangkan model bahasa kepada saiz yang lebih kecil, sekali gus mengurangkan keperluan masa dan ruang. Walau bagaimanapun, storan data juga sebenarnya menambah overhed tambahan, yang perlu ditimbang dan dikaji dengan teliti, dan kami percaya ini adalah cabaran semasa.
Berbanding dengan melatih model bahasa dengan lebih daripada 10 bilion parameter, saya rasa perkara paling penting pada masa ini ialah mengurangkan kos latihan.
 Gambar
Gambar
Jika anda ingin mencari PPT ucapan ini, atau menonton main semula tertentu, anda boleh pergi ke laman web rasmi~
Tapak web rasmi: https://acl2023-ret lm.github.io /
Atas ialah kandungan terperinci Laporan akademik ACL Chen Danqi ada di sini! Penjelasan terperinci tentang 7 arah utama dan 3 cabaran utama pangkalan data 'plug-in' model besar, 3 jam penuh dengan maklumat berguna. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pangkalan data tiga paradigma
Pangkalan data tiga paradigma
 Bagaimana untuk memadam pangkalan data
Bagaimana untuk memadam pangkalan data
 Bagaimana untuk menyambung ke pangkalan data dalam vb
Bagaimana untuk menyambung ke pangkalan data dalam vb
 pangkalan data pemulihan MySQL
pangkalan data pemulihan MySQL
 Bagaimana untuk menyambung ke pangkalan data dalam vb
Bagaimana untuk menyambung ke pangkalan data dalam vb
 Bagaimana untuk menyelesaikan masalah nama objek pangkalan data tidak sah
Bagaimana untuk menyelesaikan masalah nama objek pangkalan data tidak sah
 Bagaimana untuk menyambung vb untuk mengakses pangkalan data
Bagaimana untuk menyambung vb untuk mengakses pangkalan data
 Bagaimana untuk menyambung ke pangkalan data menggunakan vb
Bagaimana untuk menyambung ke pangkalan data menggunakan vb








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



