


Pengarang |. Wan Chen, Li Yuan
Editor |
Pada 28 Jun waktu tempatan, Databricks, platform data Amerika yang terkenal, mengadakan persidangan tahunannya sendiri - Sidang Kemuncak Kepintaran Data dan Buatan. Pada mesyuarat itu, Databricks mengumumkan satu siri produk baharu yang penting seperti LakehouseIQ, Lakehouse AI, Databricks Marketplace dan Lakehouse Apps.Sama ada nama sidang kemuncak atau penamaan produk baharu, dapat dilihat bahawa platform data yang terkenal ini mengambil kesempatan daripada model bahasa besar untuk mempercepatkan transformasi kepada AI.

"Apa yang ingin dicapai oleh Databricks ialah "keterangkuman data" dan keterangkuman AI. Yang pertama membenarkan data menjangkau setiap pekerja, dan yang terakhir membenarkan AI memasuki setiap produk. Ali Ghodsi, Ketua Pegawai Eksekutif Databricks, mengumumkan misi pasukan itu dalam ucapannya.
Sejurus sebelum persidangan bermula, Databricks baru sahaja mengumumkan pengambilalihan MosaicML, kuasa baharu dalam bidang AI, dengan harga AS$1.3 bilion, menetapkan rekod pemerolehan semasa dalam bidang AI, yang menunjukkan kekuatan dan keazaman syarikat dalam transformasi AI.
Pengasas dan Ketua Pegawai Eksekutif PingCAP, Liu Qi, yang menghadiri mesyuarat yang akan datang, memberitahu Geek Park bahawa platform Databricks baru sahaja melancarkan aplikasi AI peringkat perusahaan, dan sudah lebih daripada 1,500 syarikat sedang melatih model mengenainya, dan "jumlahnya melebihi jangkaan. " Pada masa yang sama, beliau percaya bahawa pengumpulan Databricks sebelum ini dalam data + AI membolehkan syarikat menambah produk baharu dengan cepat berdasarkan platform sebelumnya apabila AI menjadi popular, dan dengan cepat menyediakan perkhidmatan yang berkaitan dengan model besar.
"Perkara yang paling kritikal ialah kelajuan." Liu Qi berkata bahawa dalam era model besar, cara mengintegrasikan model besar dengan produk sedia ada dengan lebih pantas dan menyelesaikan masalah pengguna mungkin merupakan cabaran terbesar bagi semua syarikat data pada masa ini, dan ia juga merupakan cabaran terbesar.
Perkataan
Databricks mengeluarkan alat LakehouseIQ baharu pada persidangan itu, yang dianggap sebagai "artifak". LakehouseIQ menjalankan salah satu usaha terbaru Databricks - penyejagatan analisis data Iaitu, orang biasa yang tidak menguasai Python dan SQL dengan mudah boleh mengakses data syarikat dan menjalankan analisis data menggunakan bahasa semula jadi.
Untuk mencapai matlamat ini, LakehouseIQ direka bentuk sebagai koleksi fungsi yang boleh digunakan oleh pengguna akhir biasa dan pembangun, dengan fungsi berbeza direka untuk pengguna yang berbeza.
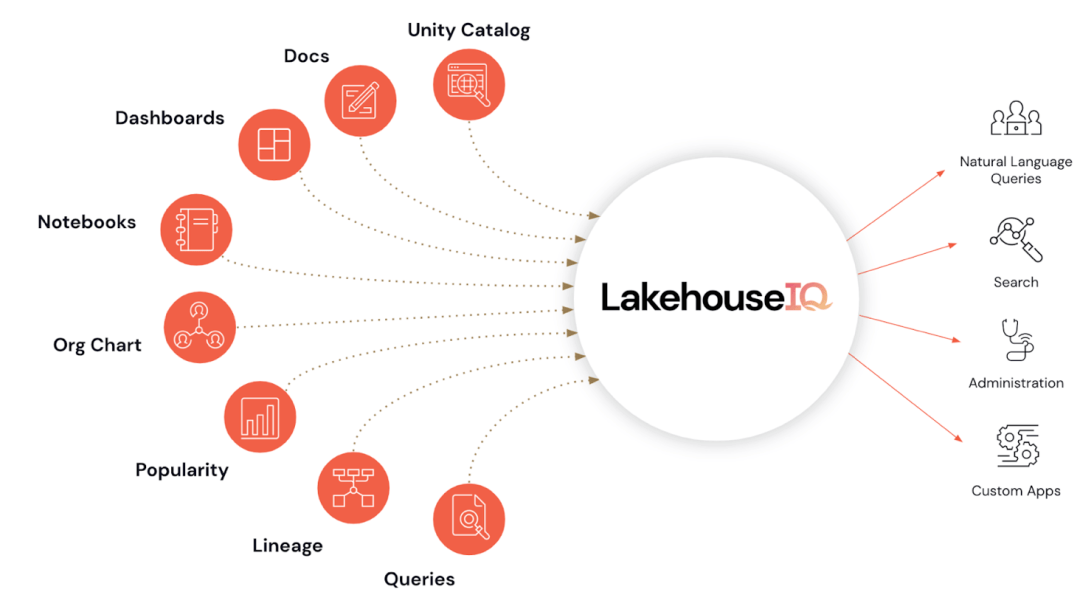
Untuk pembangun, LakehouseIQ dalam Notebooks telah dikeluarkan Dalam ciri ini, LakehouseIQ boleh menggunakan model bahasa yang besar untuk membantu pembangun melengkapkan, menjana dan mentafsir kod, serta melakukan pembaikan kod, penyahpepijatan dan penjanaan laporan.
Untuk bukan pengaturcara biasa, Databricks menyediakan antara muka yang boleh berinteraksi secara langsung dengan bahasa semula jadi Ia didorong oleh model bahasa yang besar dan boleh terus menggunakan bahasa semula jadi untuk mencari dan bertanya data. Pada masa yang sama, ciri ini disepadukan dengan Katalog Perpaduan, membenarkan syarikat mengawal akses kepada carian dan pertanyaan data, dan hanya mengembalikan data yang dibenarkan untuk dilihat oleh penyoal.
Sejak pelancaran model besar, menggunakan bahasa semula jadi untuk bertanya dan menganalisis data sebenarnya telah menjadi topik hangat ke arah analisis data, dan banyak syarikat telah membuat rancangan ke arah ini. Termasuk Snowflake saingan lama Databricks, ciri AI Dokumen yang baru diumumkan turut memfokuskan pada arah ini.
Walau bagaimanapun, Databricks mendakwa bahawa LakehouseIQ berfungsi dengan lebih baik. Ia menunjukkan bahawa model bahasa besar tujuan umum mempunyai had dalam memahami data pelanggan tertentu, istilah dalaman dan corak penggunaan. Teknologi Databricks memanfaatkan skema, dokumen, pertanyaan, populariti, urutan, buku nota dan papan pemuka risikan perniagaan pelanggan sendiri untuk mendapatkan kecerdasan dan menjawab lebih banyak pertanyaan.
Terdapat satu lagi perbezaan antara fungsi Databricks dan Snowflake Fungsi AI Document platform Snowflake terhad kepada pertanyaan data tidak berstruktur dalam dokumen, manakala LakehouseIQ sesuai untuk data dan kod Lakehouse berstruktur.
02
Daripada pembelajaran mesin kepada AI
Persamaan antara Databricks dan Snowflake pada pelancaran tidak berakhir di situ.
Dalam persidangan ini, Databricks mengeluarkan Databricks Marketplace dan Lakehouse AI, yang benar-benar konsisten dengan fokus persidangan dua hari Snowflake, kedua-duanya memfokuskan pada penggunaan model bahasa yang besar ke dalam persekitaran pangkalan data.
Dalam visi Databricks, Databricks bukan sahaja boleh membantu pelanggan dalam menggunakan model besar pada masa hadapan, tetapi juga menyediakan alatan model besar siap.
Databricks pernah mempunyai jenama Pembelajaran Mesin Databricks Pada sidang akhbar ini, Databricks mengubah kedudukan sepenuhnya jenamanya dan menaik tarafnya kepada Lakehouse AI, memfokuskan pada membantu pelanggan menggunakan model besar.
Databricks Marketplace kini tersedia di Databricks. Dalam Pasaran Databricks, pengguna boleh mengakses koleksi besar model bahasa sumber terbuka yang disaring, termasuk MPT-7B, Falcon-7B dan Stable Diffusion, dan juga boleh menemui dan mendapatkan set data dan aset data. Lakehouse AI juga menyediakan beberapa fungsi operasi model bahasa besar (LLMOps).
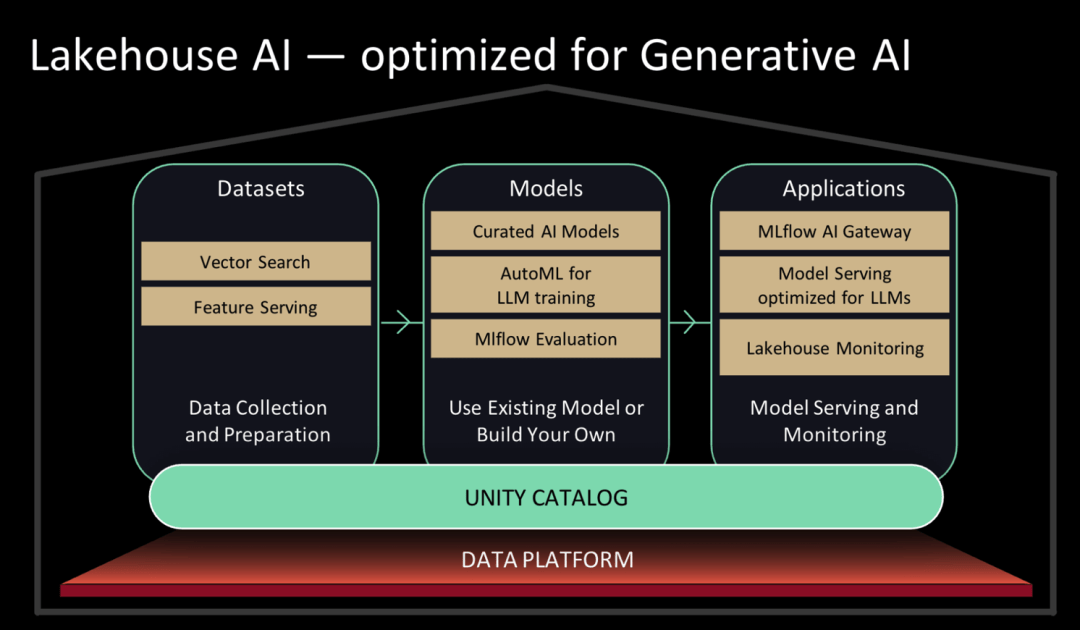
Rajah Seni Bina AI Lakehouse|Databricks
Snowflake juga sedang aktif menggunakan ini, dengan keupayaan serupa yang disediakan oleh Nvidia NeMo, Nvidia AI Enterprise, Dataiku dan John Snow Labs (kerjasama dengan Nvidia ialah salah satu acara utama persidangan Snowflake, lihat laporan Geek Park).
Snowflake dan Databricks mempunyai perbezaan dalam membantu pelanggan menggunakan model besar. Snowflake telah memilih untuk terlibat secara aktif dengan rakan kongsi, manakala Databricks telah berusaha untuk menambah fungsi sebagai ciri asli platform terasnya.
Dari segi penyediaan alatan siap, Databricks mengumumkan bahawa Databricks Marketplace juga akan menyediakan Aplikasi Lakehouse pada masa hadapan. Lakehouse Apps akan dijalankan terus pada contoh Databricks pelanggan, di mana mereka boleh menyepadukan dengan data pelanggan, menggunakan dan melanjutkan perkhidmatan Databricks, dan membolehkan pengguna berinteraksi melalui pengalaman log masuk tunggal. Data tidak perlu meninggalkan contoh pelanggan, dan tiada pergerakan data dan isu keselamatan/akses.
Ini benar-benar konsisten dengan produk Snowflake dari segi penamaan dan fungsi. Snowflake Marketplace dan Aplikasi Asli Snowflake yang serupa sudah pun dalam talian dan merupakan salah satu sorotan pelancarannya. Bloomberg mengumumkan APP Data License Plus (DL+) yang disediakan oleh Bloomberg pada persidangan Snowflake, yang membolehkan pelanggan mengkonfigurasi persekitaran sedia untuk digunakan dalam awan dalam beberapa minit, dengan data langganan Bloomberg yang dimodelkan sepenuhnya dan kandungan ESG daripada berbilang vendor.
03
Platform data membawa perubahan baharu
Pada ucaptama pembukaan, Databricks mengumumkan beberapa: Dalam 30 hari yang lalu, lebih 1,500 pelanggan telah melatih model Transformer pada platform Databricks.
Apabila bercakap tentang nombor yang mengagumkan ini, PingCAP Liu Qi percaya bahawa ini menunjukkan bahawa perusahaan menggunakan AI lebih cepat daripada yang dijangkakan “Tidak perlu melatih model untuk menggunakan model, jadi jika terdapat 1,500 Home terlatih, aplikasi itu mesti. menjadi lebih besar daripada (nombor) ini.”
Sudut pandangan lain ialah ini menunjukkan bahawa susun atur strategik Databricks dalam bidang AI adalah agak menyeluruh. Ia kini lebih daripada sekadar gudang data atau tasik data. Kini ia turut menyediakan: latihan AI, servis AI, pengurusan model, dsb. "

Ali Ghodsi menggunakan revolusi pengkomputeran dan Internet untuk membandingkan transformasi model besar dalam pembelajaran mesin|Databricks
Dalam erti kata lain, model asas boleh dilatih pada platform Databricks, dan model tahap terendah boleh dilatih dengan hanya melaraskan parameter. Untuk perkhidmatan AI yang diperlukan di atas model ini, Databricks juga telah menyediakan infrastruktur yang sepadan - hari ini ia mengeluarkan carian vektor dan kedai ciri.
Databricks dinaik taraf sepenuhnya kepada model besar.
Pada masa lalu, Databricks telah mengumpulkan banyak pengalaman dalam AI, seperti menggunakan model kecil untuk meningkatkan kecekapan dan mengurangkan kependaman dalam membina indeks, menanya data dan meramalkan beban kerja. Walau bagaimanapun, keupayaan untuk membuat model besar pada kadar yang begitu pantas masih mengejutkan ramai orang.
Sebelum susun atur AI dipaparkan sepenuhnya pada sidang kemuncak hari ini, Databricks memperoleh Okera (tadbir urus data AI), melancarkan model besar sumber terbukanya sendiri Dolly 2.0, dan memperoleh MosaicML untuk AS$1.3 bilion Satu siri tindakan telah diselesaikan sekali gus.
Dalam hal ini, Howie, seorang guru dari Silicon Valley, percaya bahawa ia dapat dilihat dengan jelas daripada dua persidangan Databricks dan Snowflake: pengasas kedua-dua syarikat percaya bahawa tindakan yang telah mereka ambil berdasarkan pangkalan data dan tasik data akan dihadapi masalah asas pada masa hadapan. Cara mereka melakukannya setahun yang lalu tidak akan berkesan dalam beberapa tahun akan datang.
Sejajar dengan itu, keupayaan untuk menyiapkan model besar dengan cepat juga bermakna pasaran tambahan yang dibawa oleh model besar boleh diperolehi.
Liu Qi percaya bahawa kemunculan model besar telah mencetuskan banyak keperluan baru yang tidak wujud sebelum model besar. Tanpa sokongan data, model tidak akan dapat berfungsi, terutamanya dari segi pembezaan. Jika semua orang adalah model besar, maka mungkin tidak ada perbezaan antara anda dan orang lain. "
Tetapi berbanding model besar, penonton di sidang kemuncak nampaknya lebih memberi perhatian kepada model kecil kerana beberapa kelebihan model kecil: kelajuan, kos dan keselamatan. Liu Qi berkata berdasarkan data uniknya sendiri, dia boleh membuat model yang berbeza Model itu mestilah cukup kecil untuk memenuhi tiga keperluan ini: cukup murah, cukup pantas dan cukup selamat.
Perlu diingat bahawa kedua-dua Databricks dan Snowflake baru-baru ini mengumumkan data hasil mereka, dan pertumbuhan hasil tahunan platform adalah lebih daripada 60%. Kadar pertumbuhan ini dicerminkan dalam tumpuan yang semakin meningkat pada data dengan latar belakang kelembapan dalam perbelanjaan perisian di seluruh pasaran. Dengan kemunculan model berskala besar, nilai data telah diserlahkan pada Sidang Kemuncak Databricks ini dengan tema data ditambah AI.
Dengan pengenalan model berskala besar, penjanaan data automatik menjadi mungkin, dan jumlah data dijangka meningkat secara eksponen. Cara mengakses data dengan mudah, cara menyokong format data yang berbeza, dan cara melombong nilai di sebalik data akan menjadi keperluan yang semakin kerap.
Sebaliknya, banyak syarikat hari ini masih meneroka dan menunggu untuk menyepadukan model besar ke dalam perisian perusahaan Namun, mengambil kira keselamatan, privasi dan kos, hanya sedikit yang berani menggunakannya secara langsung. Sebaik sahaja model besar digunakan terus ke data perusahaan tanpa memindahkan data, ambang untuk menggunakan model besar akan terus diturunkan dan jumlah serta kelajuan penggunaan data akan dikeluarkan lagi.
Atas ialah kandungan terperinci Gergasi data AS$38 bilion mahu melancarkan revolusi 'AI' dalam perusahaan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apa yang salah dengan telefon bimbit saya yang boleh membuat panggilan tetapi tidak melayari Internet?
Apa yang salah dengan telefon bimbit saya yang boleh membuat panggilan tetapi tidak melayari Internet?
 Bagaimana untuk memulihkan data pelayan
Bagaimana untuk memulihkan data pelayan
 Gaya bar skrol CSS
Gaya bar skrol CSS
 Bagaimana pula dengan Ouyi Exchange?
Bagaimana pula dengan Ouyi Exchange?
 Apakah sistem pengurusan biasa?
Apakah sistem pengurusan biasa?
 Bagaimana untuk mencari lokasi telefon bimbit orang lain
Bagaimana untuk mencari lokasi telefon bimbit orang lain
 Penggunaan getproperty
Penggunaan getproperty
 Apakah maksud kod sumber terbuka?
Apakah maksud kod sumber terbuka?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



