


在进入正文前,我们先听两段 MusicGen 生成的音乐。我们输入文本描述「a man walks in the rain, come accross a beautiful girl, and they dance happily」
然后尝试输入周杰伦《七里香》歌词中的前两句「窗外的麻雀在电线杆上多嘴,你说这一句 很有夏天的感觉」(支持中文)
试玩地址:https://huggingface.co/spaces/facebook/MusicGen
文本到音乐是指在给定文本描述的情况下生成音乐作品的任务,例如「90 年代吉他即兴摇滚歌曲」。作为一项具有挑战性的任务,生成音乐要对长序列进行建模。与语音不同,音乐需要使用全频谱,这意味着以更高的速率对信号进行采样,即音乐录音的标准采样率为 44.1 kHz 或 48 kHz,而语音的采样率为 16 kHz。
此外,音乐包含不同乐器的和声和旋律,这使音乐有着复杂的结构。但由于人类听众对不和谐十分敏感,因此对生成音乐的旋律不会有太大容错率。当然,以多种方法控制生成过程的能力对音乐创作者来说是必不可少的,如键、乐器、旋律、流派等。
最近自监督音频表示学习、序列建模和音频合成方面的进展,为开发此类模型提供了条件。为了使音频建模更加容易,最近的研究提出将音频信号表示为「表示同一信号」的离散 token 流。这使得高质量的音频生成和有效的音频建模成为可能。然而这需要联合建模几个并行的依赖流。
Kharitonov 等人 [2022]、Kreuk 等人 [2022] 提出采用延迟方法并行建模语音 token 的多流,即在不同流之间引入偏移量。Agostinelli 等人 [2023] 提出使用不同粒度的多个离散标记序列来表示音乐片段,并使用自回归模型的层次结构对其进行建模。同时,Donahue 等人 [2023] 采用了类似的方法,但针对的是演唱到伴奏生成的任务。最近,Wang 等人 [2023] 提出分两个阶段解决这个问题:限制对第一个 token 流建模。然后应用 post-network 以非自回归的方式联合建模其余的流。
本文中,Meta AI 的研究者提出了 MUSICGEN,这是一种简单、可控的音乐生成模型,能在给定文本描述的情况下生成高质量的音乐。

论文地址:https://arxiv.org/pdf/2306.05284.pdf
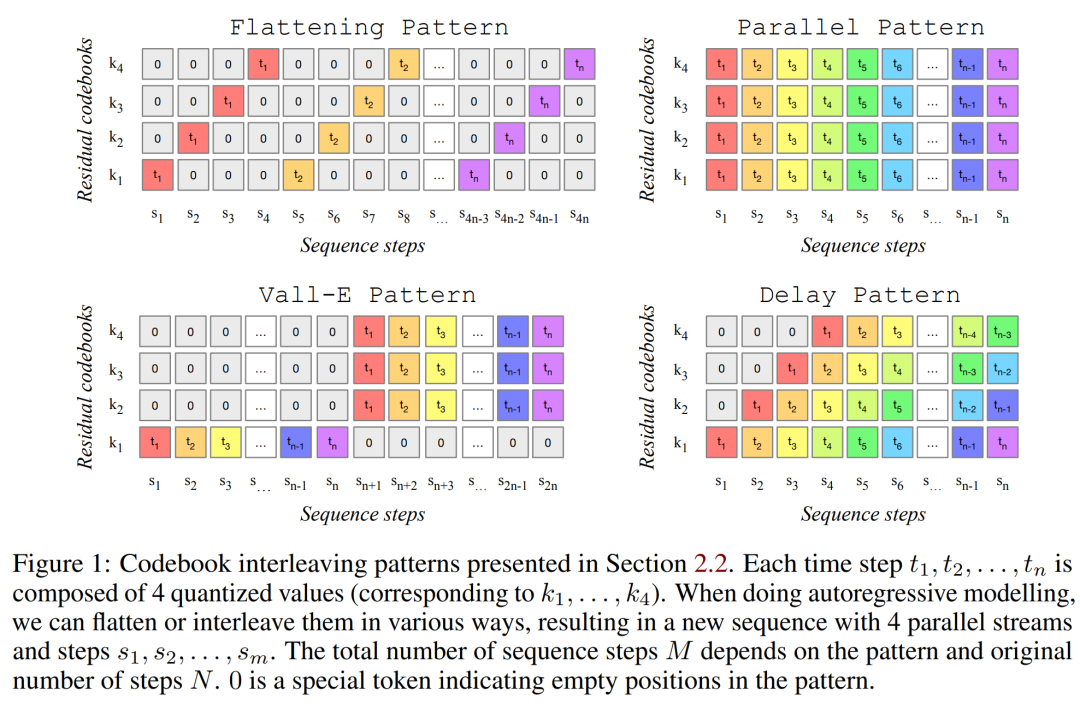
研究者提出一个对多个并行声学 token 流进行建模的通用框架,作为以前研究的概括 (见下图 1)。为提高生成样本的可控性,本文还引入了无监督旋律条件,使模型能够根据给定和声和旋律生成结构匹配的音乐。本文对 MUSICGEN 进行了广泛的评估,所提出的方法在很大程度上优于评估基线:MUSICGEN 的主观评分为 84.8 (满分 100 分),而最佳基线为 80.5。此外,本文还提供一项消融研究,阐明了每个组件对整体模型性能的重要性。
最后,人工评估表明,MUSICGEN 产生了高质量的样本,这些样本在符合文本描述,在旋律上也更好地与给定的和声结构对齐。
本文的主要贡献有如下几点:
MUSICGEN 包含一个基于自回归 transformer 的解码器,并以文本或旋律表示为条件。该(语言)模型基于 EnCodec 音频 tokenizer 的量化单元,它从低帧离散表示中提供高保真重建效果。此外部署残差向量量化(RVQ)的压缩模型会产生多个并行流。在此设置下,每个流都由来自不同学得码本的离散 token 组成。
以往的工作提出了一些建模策略来解决这一问题。研究者提出了一种新颖的建模框架,它可以泛化到各种码本交错模式。该框架还有几种变体。基于模式,他们可以充分利用量化音频 token 的内部结构。最后 MUSICGEN 支持基于文本或旋律的条件生成。
音频 tokenization
研究者使用了 EnCodec,它是一种卷积自编码器,具有使用 RVQ 量化的潜在空间和对抗重建损失。给定一个参考音频随机变量 X ∈ R^d・f_s,其中 d 表示音频持续时间,f_s 表示采样率。EnCodec 将该变量编码为帧率为 f_r ≪ f_s 的连续张量,然后该表示被量化为 Q ∈ {1, . . . , N}^K×d・f_r,其中 K 表示 RVQ 中使用的码本数量,N 表示码本大小。
码本交错模式
精确扁平化自回归分解。自回归模型需要一个离散随机序列 U ∈ {1, . . . , N}^S 和序列长度 S。按照惯例,研究者将采用 U_0 = 0,这是一个确定性的特殊 token,表示序列的开始。然后他们可以对分布进行建模。
不精确的自回归分解。另一种可能是考虑自回归分解,其中一些码本需要进行并行预测。比如定义另一个序列,V_0 = 0,并且 t∈ {1, . . . , N}, k ∈ {1, . . . , K}, V_t,k = Q_t,k。当删除码本索引 k 时(如 V_t),这代表了时间为 t 时所有码本的串联。
任意码本交错模式。为了试验此类分解,并准确测量使用不精确分解的影响,研究者引入了码本交错模式。首先考虑Ω = {(t, k) : {1, . . . , d・f_r}, k ∈ {1, . . . , K}},它是所有时间步和码本索引对的集合。码本模式是序列 P=(P_0, P_1, P_2, . . . , P_S),其中 P_0 = ∅,,并且 0 < i ≤ S, P_i ⊂ Ω,这样 P 是Ω的分区。研究者通过并行地预测 P_t 中的所有位置来建模 Q,并以 P_0, P_1, . . . , P_T 中的所有位置为条件。同时考虑到实际效率,他们只选择了「每个码本在任何 P_s 中最多出现一次」的模式。
模型条件化
文本条件化。给定与输入音频 X 匹配的文本描述,研究者计算条件张量 C ∈ R^T_C ×D,其中 D 是自回归模型中使用的内部维数。
旋律条件化。虽然文本是当今条件生成模型的主要方法,但更自然的音乐方法是以来自另一个音轨甚至口哨或哼唱的旋律结构为条件。这种方法还允许对模型输出进行迭代优化。为了支持这一点,研究者尝试通过联合调节输入的色谱图和文本描述来控制旋律结构。再最初的试验中,他们观察到以原始色谱图为条件通常会重建原始样本,导致过拟合。为此,研究者在每个时间步中选择主要的时频 bin 来引入信息瓶颈。
模型架构
码本投影和位置嵌入。给定一个码本模式,在每个模式步 P_s 中只有一些码本的存在。研究者从 Q 中检索出对应 P_s 中索引的值。每个码本在 P_s 中最多出现一次或根本不存在。
Transformer 解码器。输入被馈入到具有 L 层和 D 维的 transformer 中,每一层都由一个因果自注意力块组成。然后使用一个跨注意力块,该块由条件化信号 C 提供。当使用旋律调节时,研究者将条件化张量 C 作为 transformer 输入的前缀。
Logits 预测。在模式步 P_s 中,transformer 解码器的输出被转换为 Q 值的 Logits 预测。每个码本在 P_s+1 中最多出现一次。如果码本存在,则从 D 通道到 N 应用特定于码本的线性层来获得 Logits 预测。
音频 tokenization 模型。研究对 32 kHz 单声道音频使用非因果五层 EnCodec 模型,其步幅为 640,帧率为 50 Hz,初始隐藏大小为 64,在模型的五层中每层都增加一倍。
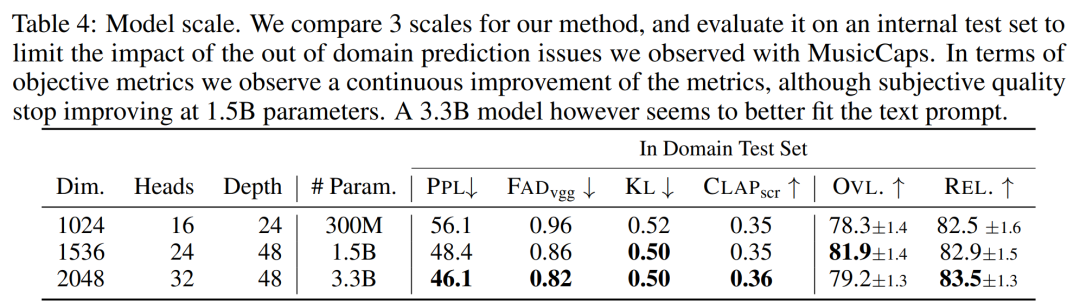
变压器模型,研究训练了不同大小的自回归 Transformer 模型:300M, 1.5B, 3.3B 参数。
训练数据集。研究使用 2 万小时的授权音乐来训练 MUSICGEN。详细来说,研究使用了一个包含 10K 个高质量曲目的内部数据集,以及分别包含 25K 和 365K 只有乐器曲目的 ShutterStock 和 Pond5 音乐数据集。
评估数据集。研究在 MusicCaps 基准上对所提出的方法进行了评估,并与之前的工作进行了比较。MusicCaps 是由专家音乐家准备的 5.5K 样本 (10 秒长) 和跨流派平衡的 1K 子集组成的。
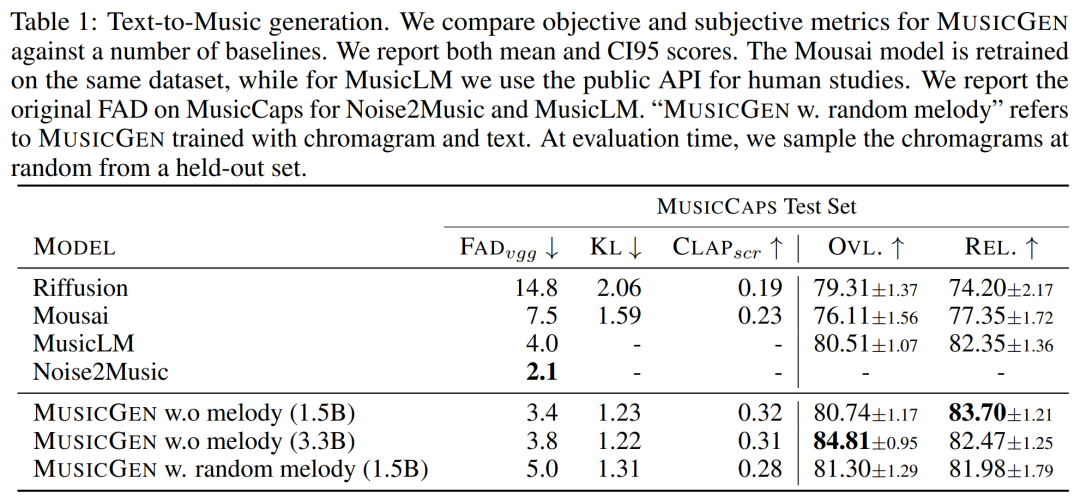
下表 1 给出了所提方法与 Mousai、Riffusion、MusicLM 和 Noise2Music 的比较。结果表明,在音频质量和对提供的文本描述的一致性方面,MUSICGEN 的表现优于人类听众的评估基线。Noise2Music 在 MusicCaps 上的 FAD 方面表现最好,其次是经过文本条件训练的 MUSICGEN。有趣的是,添加旋律条件会降低客观指标,但是并不会显著影响人类评分,且仍然优于评估的基线。
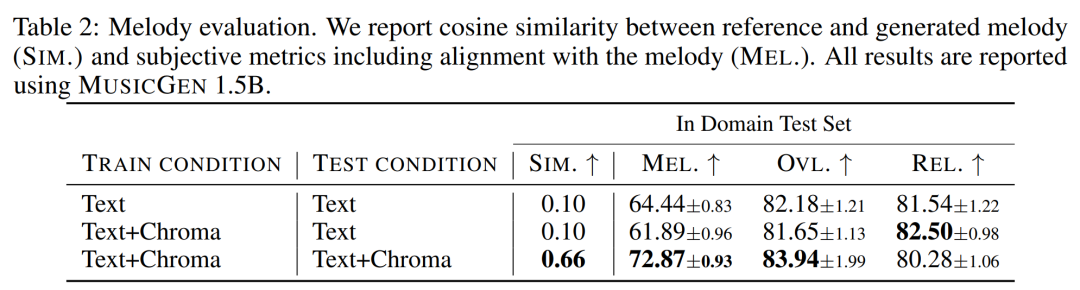
研究者在给出的评估集上使用客观和主观度量,在文本和旋律表示的共同条件下评估 MUSICGEN,结果见下表 2。结果表明,用色谱图条件化训练的 MUSICGEN 成功地生成了遵循给定旋律的音乐,从而可以更好地控制生成的输出。MUSICGEN 对于在推理时使用 OVL 和 REL 丢掉色度具有鲁棒性。
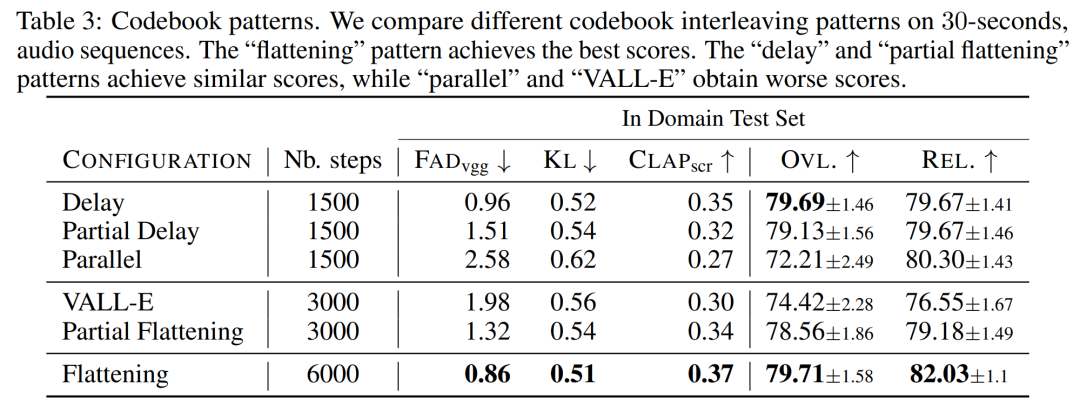
码本交错模式的影响。研究者使用 2.2 节中的框架评估了各种码本模式,K = 4,由音频 tokenization 模型给出。本文在下表 3 中报告了客观和主观评价。虽然扁平化改善了生成效果,但它的计算成本很高。使用简单的延迟方法,只需花费一小部分成本就能得到类似的性能。
模型大小的影响。下表 4 报告了不同模型大小的结果,即 300M、1.5B 和 3.3B 参数模型。正如预期的那样,扩大模型大小可以得到更好的分数,但前提是需要更长的训练和推理时间。主观评价方面,在 1.5B 时整体质量是最优的,但更大的模型可以更好地理解文本提示。
Atas ialah kandungan terperinci Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membaca lajur dalam excel dalam python
Bagaimana untuk membaca lajur dalam excel dalam python Apakah pernyataan kawalan aliran java?
Apakah pernyataan kawalan aliran java? Kaedah pelaksanaan fungsi halaman seterusnya VUE
Kaedah pelaksanaan fungsi halaman seterusnya VUE Apakah kelebihan rangka kerja Spring Boot?
Apakah kelebihan rangka kerja Spring Boot? Kedudukan terkini pertukaran mata wang digital
Kedudukan terkini pertukaran mata wang digital Apakah yang termasuk storan penyulitan data?
Apakah yang termasuk storan penyulitan data? Bagaimana untuk mendapatkan Bitcoin
Bagaimana untuk mendapatkan Bitcoin Apakah yang perlu saya lakukan jika komputer saya dimulakan dan skrin menunjukkan skrin hitam tanpa isyarat?
Apakah yang perlu saya lakukan jika komputer saya dimulakan dan skrin menunjukkan skrin hitam tanpa isyarat?




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



