


Semalam, latihan penalaan halus selama 220 jam telah selesai. Tugas utama adalah untuk memperhalusi model dialog pada CHATGLM-6B yang boleh mendiagnosis maklumat ralat pangkalan data dengan lebih tepat.
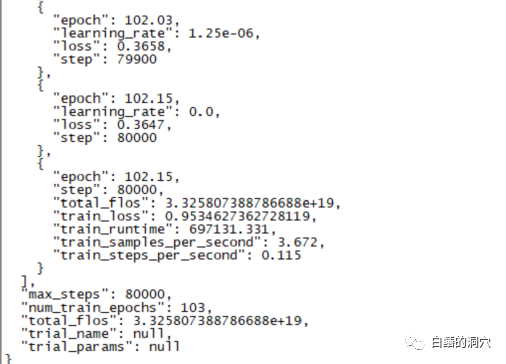
Namun, keputusan akhir latihan selama hampir sepuluh hari ini mengecewakan latihan sebelum ini saya lakukan dengan liputan sampel yang lebih kecil, perbezaannya masih agak besar.
Hasil ini masih agak mengecewakan pada asasnya . Nampaknya parameter dan set latihan perlu diselaraskan semula dan latihan dilakukan semula. Latihan model bahasa besar adalah perlumbaan senjata, dan adalah mustahil untuk bermain tanpa peralatan yang baik. Nampaknya kita juga mesti menaik taraf peralatan makmal, jika tidak akan ada beberapa sepuluh hari untuk dibazirkan.
Berdasarkan latihan penalaan halus yang gagal baru-baru ini, latihan penalaan halus bukanlah jalan yang mudah untuk diselesaikan. Objektif tugas yang berbeza digabungkan bersama untuk latihan Objektif tugas yang berbeza mungkin memerlukan parameter latihan yang berbeza, menjadikan set latihan akhir tidak dapat memenuhi keperluan tugasan tertentu. Oleh itu, PTUNING hanya sesuai untuk tugasan yang sangat tertentu, dan tidak semestinya sesuai untuk tugas bercampur Model yang bertujuan untuk tugasan bercampur mungkin perlu menggunakan FINETUNE. Ini sama dengan apa yang dikatakan oleh semua orang semasa saya berkomunikasi dengan rakan beberapa hari lalu.
Malah, kerana melatih model itu sukar, sesetengah orang telah berhenti melatih model itu sendiri, dan sebaliknya mengvektorkan pangkalan pengetahuan tempatan untuk mendapatkan semula yang lebih tepat, dan kemudian menggunakan AUTOPROMPT untuk dapatkan semula model Hasil akhir menjana gesaan automatik untuk bertanya model pertuturan. Matlamat ini mudah dicapai menggunakan langchain.
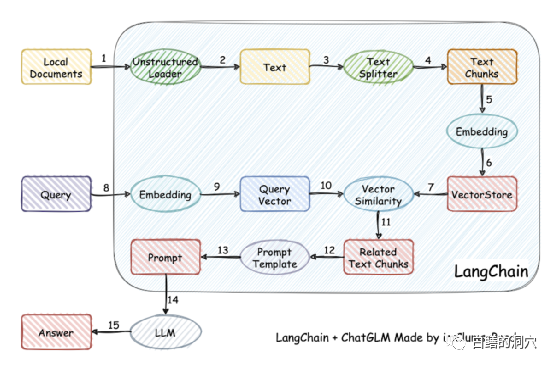
Prinsip kerjanya ialah memuatkan dokumen tempatan sebagai teks melalui pemuat, dan kemudian Teks dibahagikan kepada serpihan teks strok, dan selepas pengekodan, ia ditulis ke dalam storan vektor untuk digunakan dalam pertanyaan. Selepas keputusan pertanyaan keluar, gesaan untuk bertanya soalan dibentuk secara automatik melalui Templat Gesaan untuk bertanya kepada LLM, dan LLM menjana jawapan akhir.
Ada satu lagi perkara penting dalam kerja ini Satu lagi adalah untuk mencari pengetahuan dengan lebih tepat dalam pangkalan pengetahuan tempatan. Ini dicapai dengan penyimpanan vektor pada masa ini di Cina dan Inggeris tempatan Terdapat banyak penyelesaian untuk vektorisasi dan pencarian pangkalan pengetahuan Anda boleh memilih penyelesaian yang lebih mesra kepada pangkalan pengetahuan anda.
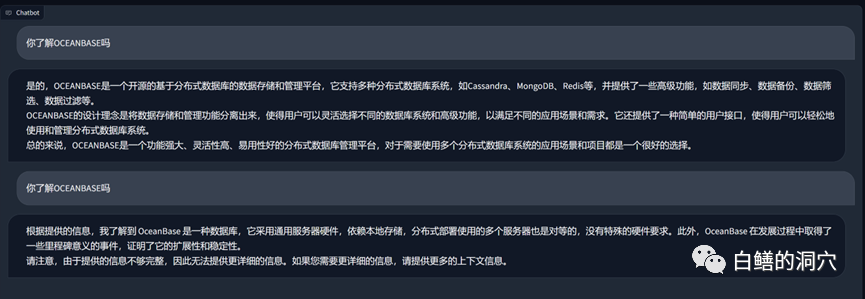
Di atas ialah pangkalan pengetahuan tentang OB yang diturunkan pada vicuna-13b Untuk Soal Jawab, di atas adalah jawapan menggunakan keupayaan LLM tanpa menggunakan pangkalan pengetahuan tempatan. Berikut adalah jawapan selepas memuatkan pangkalan pengetahuan tempatan. Ia boleh dilihat bahawa peningkatan prestasi agak ketara.
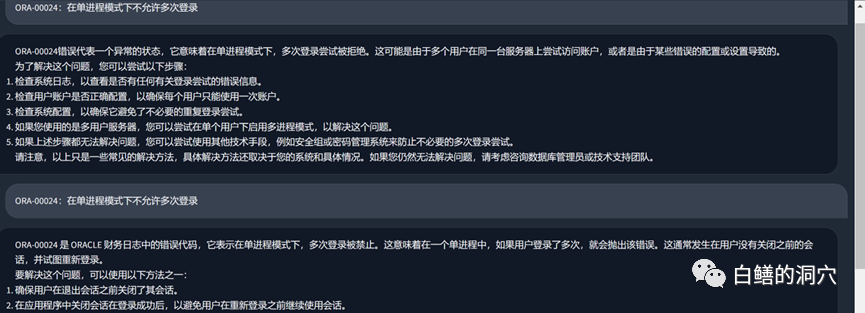
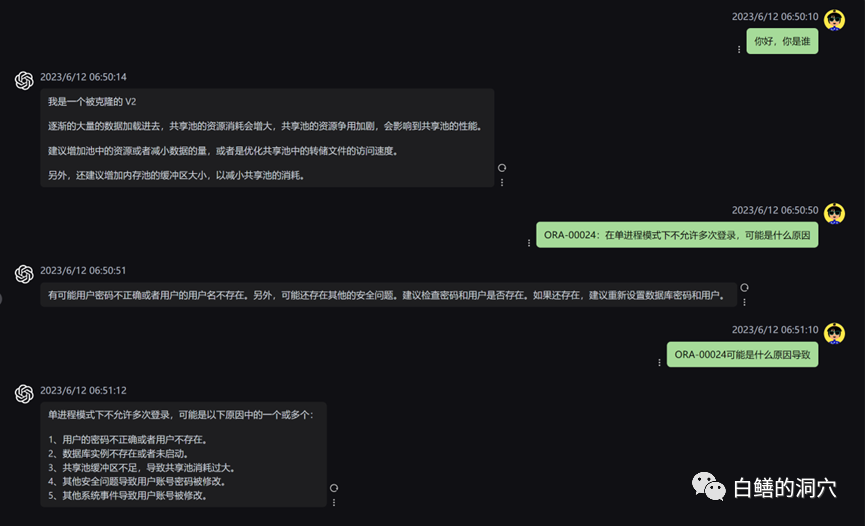
Mari kita lihat masalah ralat ORA tadi Sebelum menggunakan pangkalan pengetahuan tempatan, LLM pada asasnya Ia mengarut, tetapi selepas memuatkan pangkalan pengetahuan tempatan, jawapan ini masih memuaskan kesilapan dalam artikel juga adalah kesilapan dalam pangkalan pengetahuan kami. Malah, set latihan yang digunakan oleh PTUNING juga dijana melalui pangkalan pengetahuan tempatan ini.
Kita boleh menimba pengalaman daripada perangkap yang telah kita lalui baru-baru ini. Pertama sekali, kesukaran ptuning adalah jauh lebih tinggi daripada yang kita fikirkan Walaupun ptuning memerlukan peralatan yang lebih rendah daripada finetune, kesukaran latihan tidak rendah sama sekali. Kedua, adalah baik untuk menggunakan pangkalan pengetahuan tempatan melalui Langchain dan autoprompt untuk meningkatkan keupayaan LLM Untuk kebanyakan aplikasi perusahaan, selagi pangkalan pengetahuan tempatan diselesaikan dan penyelesaian vektorisasi yang sesuai dipilih, anda seharusnya boleh mendapatkan hasil yang. tidak lebih teruk daripada PTUNING/FINETUNE Effect. Ketiga, dan sekali lagi seperti yang dinyatakan kali lepas, keupayaan LLM adalah penting. LLM yang berkuasa mesti dipilih sebagai model asas untuk digunakan. Mana-mana model terbenam hanya boleh meningkatkan sebahagian keupayaan dan tidak boleh memainkan peranan yang menentukan. Keempat, untuk pengetahuan berkaitan pangkalan data, vicuna-13b mempunyai kebolehan yang sangat baik.
Saya perlu pergi ke klien untuk berkomunikasi awal pagi ini, jadi saya hanya akan menulis beberapa ayat. Apa pendapat anda tentang perkara ini? Anda dialu-alukan untuk meninggalkan mesej untuk perbincangan (perbincangan hanya dapat dilihat oleh anda dan saya sendiri di jalan ini.
Atas ialah kandungan terperinci Artikel tentang cara mengoptimumkan prestasi LLM menggunakan pangkalan pengetahuan tempatan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 apa itu pengoptimuman
apa itu pengoptimuman
 Perisian pengoptimuman kata kunci Baidu
Perisian pengoptimuman kata kunci Baidu
 Kaedah pengoptimuman kedudukan kata kunci SEO Baidu
Kaedah pengoptimuman kedudukan kata kunci SEO Baidu
 Bagaimanakah prestasi php8?
Bagaimanakah prestasi php8?
 Bagaimanakah prestasi thinkphp?
Bagaimanakah prestasi thinkphp?
 Bagaimana untuk memasukkan keistimewaan root dalam linux
Bagaimana untuk memasukkan keistimewaan root dalam linux
 Komponen induk Vue memanggil kaedah komponen anak
Komponen induk Vue memanggil kaedah komponen anak
 Bagaimana untuk mendayakan fungsi bandar yang sama pada Douyin
Bagaimana untuk mendayakan fungsi bandar yang sama pada Douyin








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



