


Pengesanan sasaran ialah tugas asas yang sangat penting dalam penglihatan komputer Berbeza daripada tugas pengelasan/pengiktirafan imej biasa, pengesanan sasaran memerlukan model untuk memberikan lokasi dan lokasi sasaran di atas kategori yang diberikan. sasaran. Maklumat saiz memainkan peranan penting dalam tiga tugas utama CV (pengenalpastian, pengesanan dan segmentasi).
GPT-4 berbilang mod yang popular pada masa ini hanya mempunyai keupayaan pengecaman sasaran dari segi keupayaan visual, dan belum lagi dapat menyelesaikan tugas pengesanan sasaran yang lebih sukar. Menyedari kategori, lokasi dan maklumat saiz objek dalam imej atau video ialah kunci kepada banyak aplikasi kecerdasan buatan dalam pengeluaran sebenar, seperti pengecaman pejalan kaki dan kenderaan dalam pemanduan autonomi, penguncian muka dalam aplikasi pemantauan keselamatan dan analisis imej perubatan , dsb.
Kaedah pengesanan sasaran sedia ada seperti siri YOLO, siri R-CNN dan algoritma pengesanan sasaran lain telah mencapai ketepatan dan kecekapan pengesanan sasaran yang tinggi kerana usaha berterusan penyelidik saintifik kepada Kaedah sedia ada perlu menentukan set sasaran untuk dikesan (set tertutup) sebelum latihan model, menjadikan mereka tidak dapat mengesan sasaran di luar set latihan Sebagai contoh, model yang dilatih untuk mengesan muka tidak boleh digunakan untuk mengesan kenderaan , kaedah sedia ada sangat bergantung pada data yang dilabel secara manual Apabila kategori sasaran yang ingin dikesan perlu ditambah atau diubah suai, di satu pihak, data latihan perlu dilabel semula, dan sebaliknya, model itu perlu. dilatih semula, yang memakan masa dan susah payah.
Penyelesaian yang boleh dilakukan ialah mengumpul imej besar-besaran dan melabelkan maklumat Kotak dan maklumat semantik secara manual, tetapi ini memerlukan kos pelabelan yang sangat tinggi dan menggunakan data besar-besaran untuk menguji model tersebut cabaran kepada penyelidik saintifik Faktor seperti pengedaran data berekor panjang dan kualiti anotasi manual yang tidak stabil akan menjejaskan prestasi model pengesanan.
Artikel OVR-CNN [1] yang diterbitkan dalam CVPR 2021 mencadangkan paradigma pengesanan sasaran baharu: Pengesanan Perbendaharaan Kata Terbuka (OVD, juga dikenali sebagai pengesanan sasaran dunia Terbuka) untuk menangani masalah masalah yang dinyatakan di atas, iaitu, senario pengesanan untuk objek yang tidak diketahui di dunia terbuka.
OVD telah menarik perhatian berterusan daripada ahli akademik dan industri sejak ia dicadangkan kerana keupayaannya untuk mengenal pasti dan mengesan sebarang nombor dan kategori sasaran tanpa mengembangkan jumlah data beranotasi secara manual membawa tenaga baharu dan cabaran baharu kepada tugas pengesanan sasaran klasik, dan dijangka menjadi paradigma baharu untuk pengesanan sasaran pada masa hadapan.
Secara khusus, teknologi OVD tidak memerlukan anotasi manual bagi imej besar-besaran untuk meningkatkan keupayaan pengesanan model pengesanan bagi kategori yang tidak diketahui, tetapi dengan menukar pengesan wilayah bebas kelas (agnostik kelas) digabungkan dengan model rentas mod yang dilatih pada data besar yang tidak berlabel untuk mengembangkan keupayaan model pengesanan sasaran memahami sasaran dunia terbuka melalui penjajaran rentas mod ciri rantau imej dan teks deskriptif sasaran yang akan dikesan.
Pembangunan kerja model besar silang-modal dan multi-modal baru-baru ini sangat pesat, seperti CLIP [2], ALIGN [3] dan R2D2 [4], dsb., dan pembangunan mereka juga Ia menggalakkan kelahiran OVD dan lelaran pantas dan evolusi kerja berkaitan dalam bidang OVD.
Teknologi OVD melibatkan penyelesaian dua isu utama: 1) Bagaimana untuk menambah baik penyesuaian antara maklumat rantau dan model besar merentas mod 2) Bagaimana untuk meningkatkan sasaran pan-kategori Pengesan keupayaan untuk membuat generalisasi kepada kategori baharu. Daripada kedua-dua perspektif ini, beberapa kerja berkaitan dalam bidang OVD akan diperkenalkan secara terperinci di bawah.
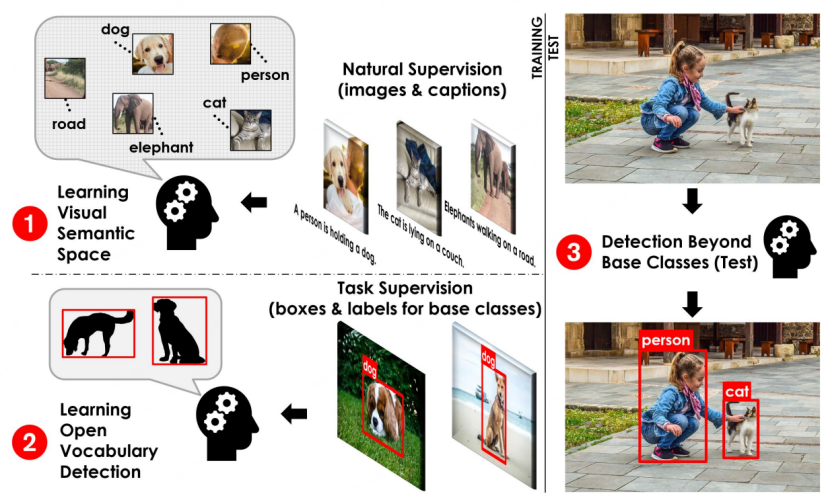
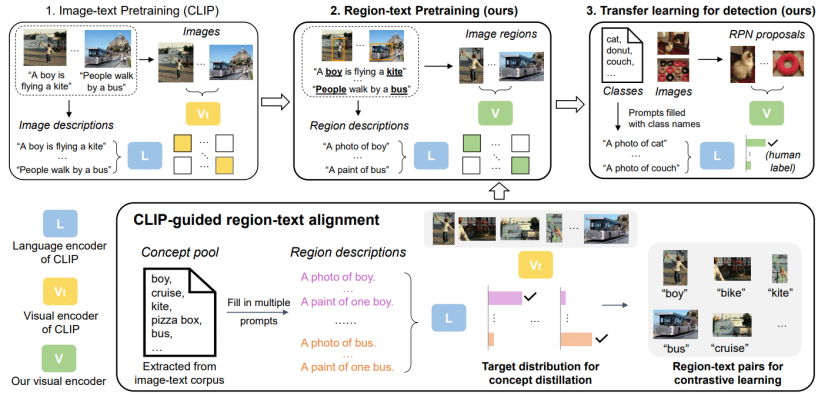
Rajah proses asas OVD[1]
Konsep asas OVD: Penggunaan OVD terutamanya melibatkan dua senario utama: beberapa pukulan dan pukulan sifar merujuk kepada kategori sasaran dengan sejumlah kecil sampel latihan yang dilabel secara manual, dan zero-shot Ia merujuk kepada kategori sasaran yang tidak mempunyai sebarang sampel latihan yang dilabel secara manual. Dalam set data penilaian akademik yang biasa digunakan COCO dan LVIS, set data dibahagikan kepada kelas Asas dan kelas Novel, di mana kelas Asas sepadan dengan senario beberapa pukulan dan kelas Novel sepadan dengan senario pukulan sifar. Sebagai contoh, set data COCO mengandungi 65 kategori, dan tetapan penilaian biasa ialah set Pangkalan mengandungi 48 kategori, dan hanya 48 kategori ini digunakan dalam latihan beberapa pukulan. Set Novel mengandungi 17 kategori, yang tidak dapat dilihat sepenuhnya semasa latihan. Penunjuk ujian terutamanya merujuk kepada nilai AP50 kelas Novel untuk perbandingan.
Kertas 1: Pengesanan Objek Perbendaharaan Kata Terbuka Menggunakan Kapsyen

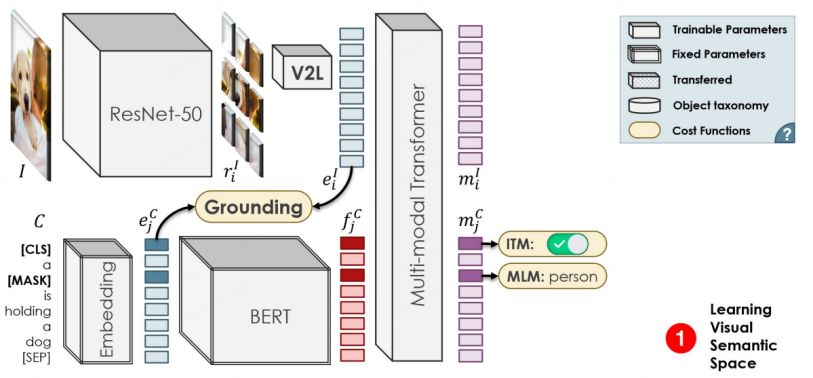
OVR-CNN ialah Kertas Lisan CVPR 2021 dan kerja perintis dalam bidang OVD. Paradigma latihan dua peringkatnya telah mempengaruhi banyak kerja OVD berikutnya. Seperti yang ditunjukkan dalam rajah di bawah, peringkat pertama terutamanya menggunakan pasangan kapsyen imej untuk pra-melatih pengekod visual, di mana BERT (parameter tetap) digunakan untuk menjana topeng perkataan, dan Pemadanan Grounding yang diselia dengan lemah dilakukan dengan ResNet50 yang dimuatkan dengan ImageNet pemberat pra-latihan , penulis percaya bahawa penyeliaan yang lemah akan menyebabkan pemadanan jatuh ke dalam optimum tempatan, jadi Transformer berbilang modal ditambah untuk ramalan topeng perkataan untuk meningkatkan keteguhan.
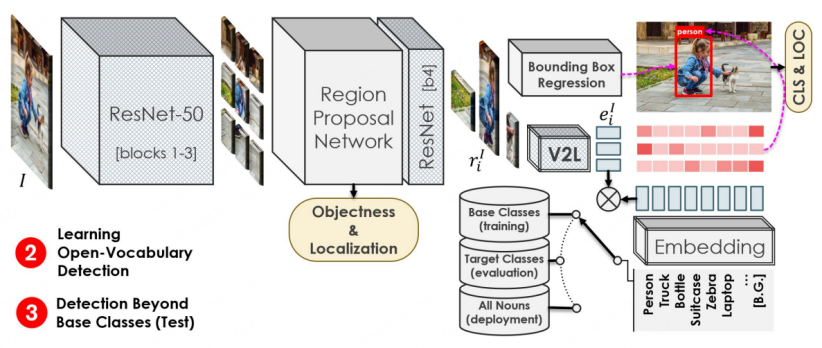
Proses latihan peringkat kedua adalah serupa dengan Faster-RCNN Perbezaannya ialah Tulang Belakang pengekstrakan ciri berasal dari peringkat kedua. 1-3 lapisan ResNet50 yang diperoleh pada peringkat pertama pra-latihan masih digunakan untuk pemprosesan ciri selepas RPN, dan ciri-ciri tersebut kemudiannya digunakan untuk regresi Kotak dan ramalan klasifikasi. Ramalan klasifikasi ialah tanda utama bahawa tugas OVD berbeza daripada pengesanan konvensional Dalam OVR-CNN, ciri-ciri dimasukkan ke dalam modul V2L (vektor graf ke modul vektor perkataan dengan parameter tetap) yang diperolehi melalui latihan satu peringkat untuk mendapatkan gambar. dan vektor teks, yang kemudiannya digabungkan dengan vektor perkataan label Padankan dan ramalkan kategori. Dalam latihan peringkat kedua, kelas Asas digunakan terutamanya untuk melaksanakan latihan regresi kotak dan latihan pemadanan kategori pada model pengesan. Memandangkan modul V2L sentiasa tetap, ia bekerjasama dengan keupayaan kedudukan model pengesanan sasaran untuk berhijrah ke kategori baharu, membolehkan model pengesanan mengenal pasti dan mengesan sasaran bagi kategori baharu.
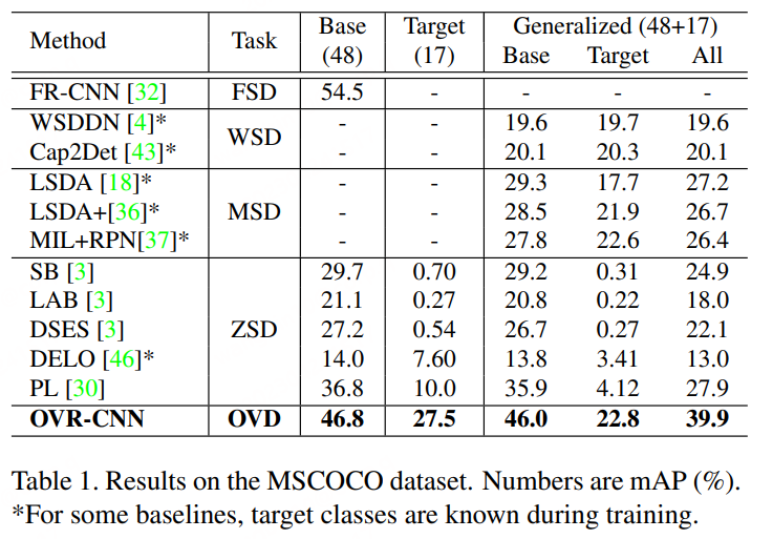
Seperti yang ditunjukkan dalam rajah di bawah, prestasi OVR-CNN pada dataset COCO jauh melebihi Zero- sebelumnya. algoritma pengesanan sasaran tembakan.
Kertas 2: RegionCLIP: Pralatihan Imej Bahasa Berasaskan Wilayah

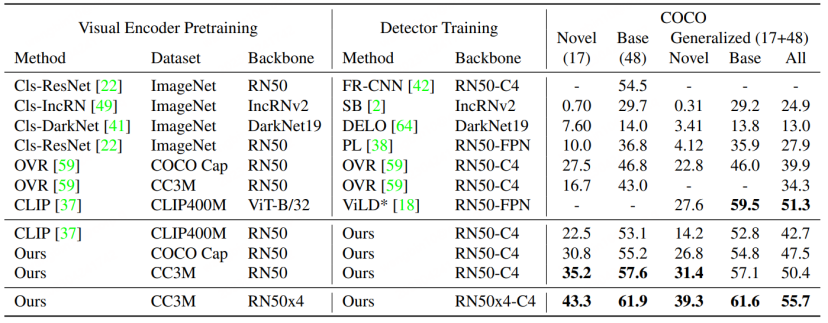
Menggunakan BERT dan pelbagai fungsi dalam OVR -CNN Modal Transfomer melakukan pra-latihan pasangan teks iamge, tetapi dengan peningkatan penyelidikan model besar rentas-modal, penyelidik saintifik telah mula menggunakan model besar rentas-modal yang lebih berkuasa seperti CLIP dan ALIGN untuk melatih tugas OVD. Model pengesan itu sendiri terutamanya bertujuan untuk mengklasifikasikan dan mengenal pasti Cadangan, iaitu maklumat serantau RegionCLIP [5] yang diterbitkan dalam CVPR 2022 mendapati bahawa keupayaan pengelasan model besar sedia ada, seperti CLIP, untuk kawasan yang dipangkas adalah jauh lebih rendah daripada. pengelasan imej asal itu sendiri, untuk menambah baik ini, RegionCLIP mencadangkan skim OVD dua peringkat baharu.

Pada peringkat pertama, set data terutamanya menggunakan CC3M, COCO-caption dan set data padanan imej dan teks yang lain untuk pra-latihan Penyulingan peringkat wilayah. Khususnya:
1 Ekstrak perkataan yang asalnya wujud dalam teks panjang untuk membentuk Kumpulan Konsep, dan seterusnya membentuk satu set penerangan ringkas tentang Wilayah untuk latihan.
2. Gunakan RPN berdasarkan pra-latihan LVIS untuk mengekstrak Wilayah Cadangan, dan gunakan CLIP asal untuk memadankan dan mengelaskan Wilayah berbeza yang diekstrak dengan penerangan yang disediakan, dan seterusnya menyusunnya ke dalam label semantik palsu.
3. Lakukan pembelajaran perbandingan teks Wilayah pada model CLIP baharu dengan Kawasan Cadangan dan label semantik yang disediakan, dan kemudian dapatkan model CLIP yang mengkhusus dalam maklumat Wilayah.
4 Dalam pra-latihan, model CLIP baharu juga akan mempelajari keupayaan pengelasan CLIP asal melalui strategi penyulingan, dan melaksanakan pembelajaran perbandingan teks imej pada tahap imej penuh. untuk mengekalkan model baru CLIP mempunyai keupayaan untuk mengekspresikan imej yang lengkap.
Pada peringkat kedua, model pra-latihan yang diperolehi dipindahkan ke model pengesanan untuk pembelajaran pemindahan.
RegionCLIP memperluaskan lagi keupayaan perwakilan model silang mod besar sedia ada pada model pengesanan konvensional, dengan itu mencapai prestasi yang lebih baik, seperti yang ditunjukkan dalam rajah di bawah, RegionCLIP telah mencapai peningkatan yang lebih besar dalam kategori Novel berbanding OVR-CNN. RegionCLIP secara berkesan meningkatkan kebolehsuaian antara maklumat rantau dan model besar berbilang modal melalui satu peringkat pra-latihan Walau bagaimanapun, CORA percaya bahawa apabila ia menggunakan model besar silang-modal yang lebih besar dengan skala parameter yang lebih besar untuk latihan satu peringkat, kos latihan akan. menjadi sangat tinggi.
Kertas 3: CORA: Menyesuaikan KLIP untuk Pengesanan Perbendaharaan Kata Terbuka dengan Pemadanan Wilayah dan Pra-Padanan Anchor

CORA [6] telah dimasukkan dalam CVPR 2023. Untuk mengatasi dua halangan yang dihadapi oleh tugas OVD semasa yang dicadangkan olehnya, model OVD seperti DETR direka bentuk. Seperti yang ditunjukkan dalam tajuk artikel, model terutamanya merangkumi dua strategi: Penggerak Wilayah dan Pra-Padanan Anchor. Yang pertama menggunakan teknologi Prompt untuk mengoptimumkan ciri serantau yang diekstrak oleh pengelas serantau berasaskan CLIP, sekali gus mengurangkan jurang pengedaran antara keseluruhan dan wilayah yang terakhir menggunakan strategi pra-padanan titik utama dalam kaedah pengesanan DETR untuk menambah baik OVD keupayaan model untuk meletakkan jenis objek baru.
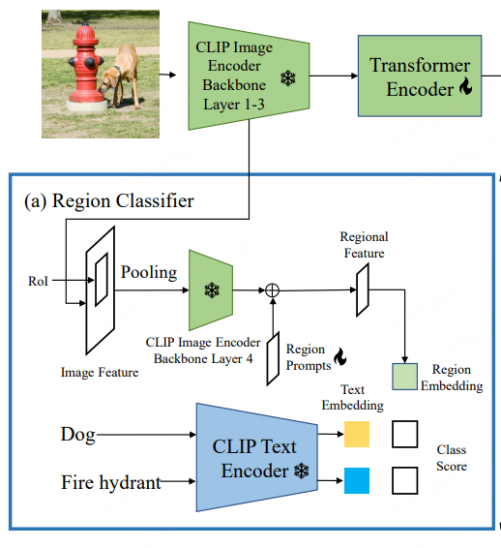
KLIP Terdapat jurang pengedaran antara ciri imej keseluruhan dan ciri serantau pengekod visual asal, yang seterusnya menyebabkan pengesan kepada Ketepatan pengelasan adalah rendah (ini serupa dengan titik permulaan RegionCLIP). Oleh itu, CORA mencadangkan Region Prompting untuk menyesuaikan diri dengan pengekod imej CLIP dan meningkatkan prestasi klasifikasi maklumat serantau. Khususnya, keseluruhan imej mula-mula dikodkan ke dalam peta ciri melalui 3 lapisan pertama pengekod CLIP, dan kemudian kotak sauh atau kotak ramalan dijana oleh Jajaran RoI dan digabungkan menjadi ciri serantau. Ini kemudiannya dikodkan oleh lapisan keempat pengekod imej CLIP. Untuk mengurangkan jurang pengedaran antara peta ciri imej penuh dan ciri serantau pengekod imej CLIP, Gesaan Wilayah yang boleh dipelajari disediakan dan digabungkan dengan output ciri oleh lapisan keempat untuk menjana ciri serantau terakhir untuk digunakan dengan ciri teks .
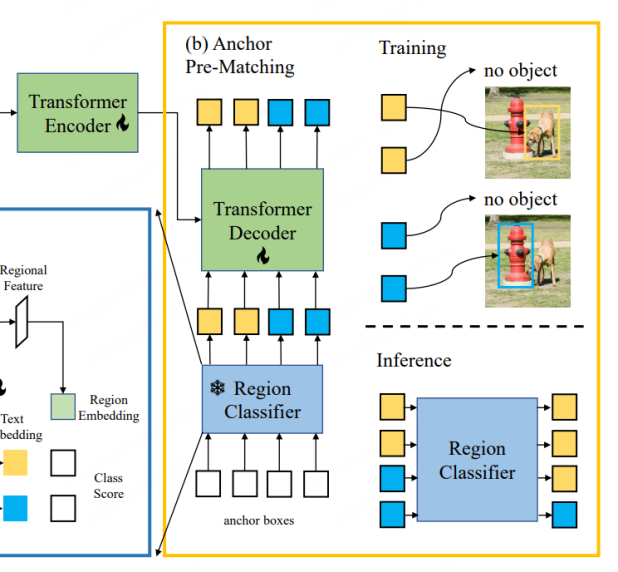
CORA ialah model pengesan seperti DETR, serupa dengan DETR, yang juga menggunakan strategi pra-padanan utama untuk menjana kotak calon lebih awal untuk latihan regresi kotak. Khususnya, pra-padanan sauh memadankan setiap kotak label dengan set kotak sauh terdekat untuk menentukan kotak sauh yang harus dianggap sebagai sampel positif dan yang harus dianggap sebagai sampel negatif. Proses pemadanan ini biasanya berdasarkan IoU (nisbah persilangan atas kesatuan). Jika IoU antara kotak sauh dan kotak label melebihi ambang yang telah ditetapkan, ia dianggap sebagai sampel positif, jika tidak, ia dianggap sebagai sampel negatif. CORA menunjukkan bahawa strategi ini secara berkesan dapat meningkatkan generalisasi keupayaan penyetempatan kepada kategori baharu.
Walau bagaimanapun, menggunakan mekanisme pra-padanan sauh juga akan membawa beberapa masalah Sebagai contoh, latihan hanya boleh dilakukan secara normal apabila sekurang-kurangnya satu kotak sauh sepadan dengan kotak label. Jika tidak, kotak label akan diabaikan, menghalang penumpuan model. Tambahan pula, walaupun kotak label memperoleh kotak titik sauh yang lebih tepat, disebabkan ketepatan pengecaman terhad Pengelas Wilayah, kotak label mungkin masih diabaikan, iaitu maklumat kategori yang sepadan dengan kotak label tidak sejajar dengan Pengelas Wilayah berdasarkan latihan CLIP. Oleh itu, CORA menggunakan teknologi CLIP-Aligned untuk memanfaatkan keupayaan pengecaman semantik CLIP dan keupayaan kedudukan ROI pra-latihan untuk melabel semula imej dalam set data latihan dengan kurang tenaga manusia Menggunakan teknologi ini, model boleh dilatih semasa latihan Padankan lebih banyak kotak tag.
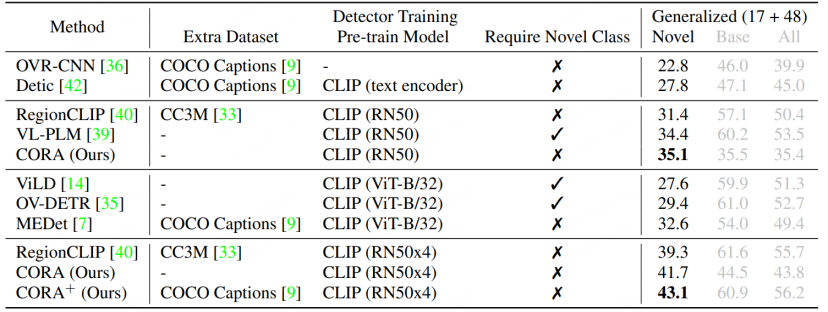
Berbanding dengan RegionCLIP, CORA meningkatkan lagi nilai AP50 sebanyak 2.4 pada set data COCO.
Teknologi OVD bukan sahaja berkait rapat dengan pembangunan model besar silang/berbilang modal yang popular pada masa ini, tetapi juga mewarisi matlamat masa lalu penyelidik saintifik Pengumpulan teknologi dalam bidang pengesanan adalah hubungan yang berjaya antara teknologi AI tradisional dan penyelidikan tentang keupayaan AI umum. OVD ialah teknologi pengesanan sasaran baharu yang menghadapi masa hadapan. Boleh dijangkakan bahawa keupayaan OVD untuk mengesan dan mengesan sebarang sasaran seterusnya akan menggalakkan pembangunan selanjutnya model besar berbilang modal, dan dijangka menjadi asas penting AGI berbilang modal. dalam pembangunan. Pada masa ini, sumber data latihan model besar berbilang modal ialah sejumlah besar pasangan maklumat kasar di Internet, iaitu pasangan teks-imej atau pasangan teks-ucapan. Jika teknologi OVD digunakan untuk mengesan maklumat imej kasar asal dengan tepat dan membantu dalam meramalkan maklumat semantik imej untuk menapis korpus, kualiti data pra-latihan model besar akan dipertingkatkan lagi, dengan itu mengoptimumkan keupayaan perwakilan dan pemahaman daripada model besar.
Contoh yang baik ialah SAM (Segmen Apa-apa sahaja)[7]. Perlu diingat bahawa teknologi OVD boleh disambungkan dengan baik kepada SAM untuk meningkatkan keupayaan pemahaman semantik SAM dan secara automatik menjana maklumat kotak yang diperlukan oleh SAM, seterusnya membebaskan tenaga manusia. Begitu juga untuk AIGC (kandungan hasil kecerdasan buatan), teknologi OVD juga boleh meningkatkan keupayaan untuk berinteraksi dengan pengguna Contohnya, apabila pengguna perlu menentukan sasaran tertentu dalam gambar untuk menukar, atau menjana penerangan sasaran, mereka boleh. Gunakan keupayaan pemahaman bahasa OVD dan keupayaan OVD untuk mengesan sasaran yang tidak diketahui untuk mengesan objek yang diterangkan oleh pengguna dengan tepat, dengan itu mencapai penjanaan kandungan berkualiti tinggi. Penyelidikan yang berkaitan dalam bidang OVD sedang berkembang pesat, dan perubahan yang boleh dibawa oleh teknologi OVD kepada model besar AI am masa hadapan patut ditunggu-tunggu.
Atas ialah kandungan terperinci Tanpa perlu melabelkan data besar-besaran, paradigma baharu pengesanan sasaran OVD membawa AGI berbilang modal selangkah lagi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP? Apakah perbezaan antara paparan pangkalan data dan jadual
Apakah perbezaan antara paparan pangkalan data dan jadual Bagaimana untuk mencari lokasi telefon bimbit orang lain
Bagaimana untuk mencari lokasi telefon bimbit orang lain Pengenalan kepada hubungan antara php dan front-end
Pengenalan kepada hubungan antara php dan front-end Pengenalan kepada ciri-ciri ruang maya
Pengenalan kepada ciri-ciri ruang maya Apakah maksud rakaman skrin?
Apakah maksud rakaman skrin? Cara menggunakan fungsi Cari
Cara menggunakan fungsi Cari




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



