


Dalam era model besar, apakah yang paling penting?
Jawapan yang LeCun pernah berikan ialah: sumber terbuka.
Apabila kod untuk LLaMA Meta dibocorkan pada GitHub, pembangun di seluruh dunia mempunyai akses kepada An LLM yang mencapai Tahap GPT.
Seterusnya, pelbagai LLM memberikan pelbagai sudut kepada sumber terbuka model AI.
LLaMA membuka jalan dan menetapkan pentas untuk model seperti Stanford's Alpac dan Vicuna, menjadikan mereka peneraju dalam sumber terbuka.
Pada masa ini, Falcon "Falcon" keluar dari kepungan semula.
"Falcon" dibangunkan oleh Institut Inovasi Teknologi (TII) di Abu Dhabi, Emiriah Arab Bersatu Dari segi prestasi, Falcon berprestasi lebih baik daripada LLaMA baik.
Pada masa ini, "Falcon" mempunyai tiga versi - 1B, 7B dan 40B.
TII berkata Falcon ialah model bahasa sumber terbuka paling berkuasa setakat ini. Versi terbesarnya, Falcon 40B, mempunyai 40 bilion parameter, yang masih sedikit lebih kecil dalam skala daripada LLaMA, yang mempunyai 65 bilion parameter.
Walaupun skalanya kecil, prestasinya tinggi.
Faisal Al Bannai, Setiausaha Agung Majlis Penyelidikan Teknologi Lanjutan (ATRC), percaya bahawa pengeluaran "Falcon" akan memecahkan jalan untuk mendapatkan LLM dan membolehkan penyelidik dan usahawan mencadangkan penyelesaian terbaik.
Dua versi FalconLM, Falcon 40B Instruct dan Falcon 40B, berada di kedudukan dua teratas dalam ranking OpenLLM Hugging Face, manakala LLaMA Meta berada di tempat ketiga.
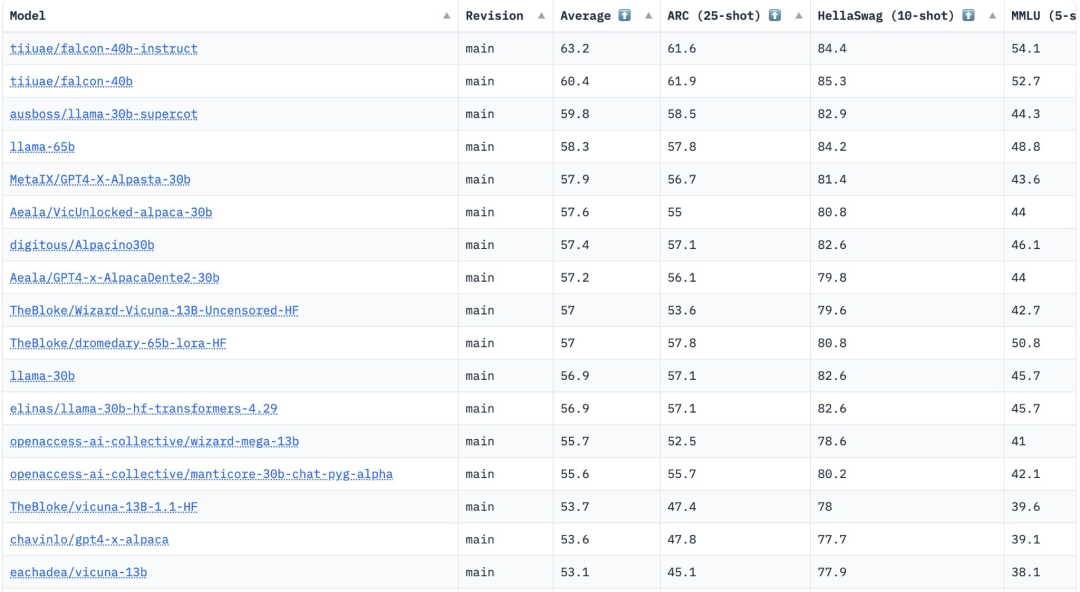
Perlu dinyatakan bahawa Wajah Memeluk adalah berdasarkan empat penanda aras semasa untuk membandingkan manifold - Cabaran Penaakulan AI2, HellaSwag , MMLU dan TruthfulQA digunakan untuk menilai model ini.
Walaupun kertas "Falcon" belum lagi dikeluarkan secara terbuka, Falcon 40B telah dilatih secara meluas mengenai set data rangkaian token 1 trilion yang disaring dengan teliti.
Penyelidik mendedahkan bahawa "Falcon" sangat mementingkan kepentingan mencapai prestasi tinggi pada data berskala besar semasa proses latihan.
Apa yang kita semua tahu ialah LLM sangat sensitif terhadap kualiti data latihan, itulah sebabnya penyelidik menghabiskan banyak usaha untuk membina satu yang boleh melakukan pemprosesan yang cekap pada puluhan ribu Saluran paip data teras CPU.
Tujuannya adalah untuk mengekstrak kandungan berkualiti tinggi daripada Internet berdasarkan penapisan dan penyahduplikasian.
Pada masa ini, TII telah mengeluarkan set data rangkaian yang diperhalusi, iaitu set data yang ditapis dan dinyahduplikasi dengan teliti. Amalan telah membuktikan bahawa ia sangat berkesan.
Model yang dilatih menggunakan set data ini sahaja boleh setanding dengan LLM lain, atau bahkan mengatasinya dalam prestasi. Ini menunjukkan kualiti dan pengaruh "Falcon" yang sangat baik.

Selain itu, model Falcon juga mempunyai keupayaan berbilang bahasa.
Ia memahami bahasa Inggeris, Jerman, Sepanyol dan Perancis, dan beberapa bahasa Eropah kecil seperti Belanda, Itali, Romania, Portugis, Czech, Poland dan Sweden yang saya juga tahu banyak tentang ia.
Falcon 40B juga merupakan model sumber terbuka kedua selepas keluaran model H2O.ai. Walau bagaimanapun, memandangkan H2O.ai belum ditanda aras dengan model lain dalam ranking ini, kedua-dua model ini masih belum memasuki gelanggang.
Melihat kembali LLaMA, walaupun kodnya tersedia di GitHub, pemberatnya tidak pernah menjadi sumber terbuka.
Ini bermakna penggunaan komersial model ini tertakluk kepada sekatan tertentu.
Selain itu, semua versi LLaMA bergantung pada lesen LLaMA asal, yang menjadikan LLaMA tidak sesuai untuk aplikasi komersial berskala kecil.
Pada ketika ini, “Falcon” muncul di atas sekali lagi.
Falcon kini merupakan satu-satunya model sumber terbuka yang boleh digunakan secara komersil secara percuma.
Pada awalnya, TII menghendaki bahawa jika Falcon digunakan untuk tujuan komersial dan menjana lebih daripada $1 juta dalam pendapatan boleh diagihkan, 10% "cukai penggunaan" akan dikenakan.
Tetapi tidak mengambil masa lama untuk taikun Timur Tengah yang kaya untuk menarik balik sekatan ini.
Sekurang-kurangnya buat masa ini, semua penggunaan komersial dan penalaan halus Falcon adalah percuma.
Orang kaya berkata bahawa mereka tidak perlu membuat wang melalui model ini buat masa ini.
Selain itu, TII juga meminta rancangan pengkomersilan dari seluruh dunia.
Untuk penyelesaian penyelidikan saintifik dan pengkomersilan yang berpotensi, mereka juga akan menyediakan lebih banyak "sokongan kuasa pengkomputeran latihan" atau menyediakan peluang pengkomersilan selanjutnya.

E-mel penyerahan projek: Submissions.falconllm@tii.ae
Ini hanya mengatakan: selagi projek itu bagus, model itu percuma! Kuasa pengkomputeran yang mencukupi! Jika anda tidak mempunyai wang yang mencukupi, kami masih boleh mengumpulnya untuk anda!
Untuk pemula, ini hanyalah "penyelesaian sehenti untuk keusahawanan model besar AI" daripada taikun Timur Tengah.
Menurut pasukan pembangunan, aspek penting kelebihan daya saing FalconLM ialah pemilihan data latihan.
Pasukan penyelidik membangunkan proses untuk mengekstrak data berkualiti tinggi daripada set data rangkak awam dan mengalih keluar data pendua.
Selepas pembersihan menyeluruh kandungan berlebihan dan pendua, 5 trilion token telah dikekalkan - cukup untuk melatih model bahasa yang berkuasa.
40B Falcon LM menggunakan 1 trilion token untuk latihan, dan versi 7B model menggunakan 1.5 trilion token untuk latihan.
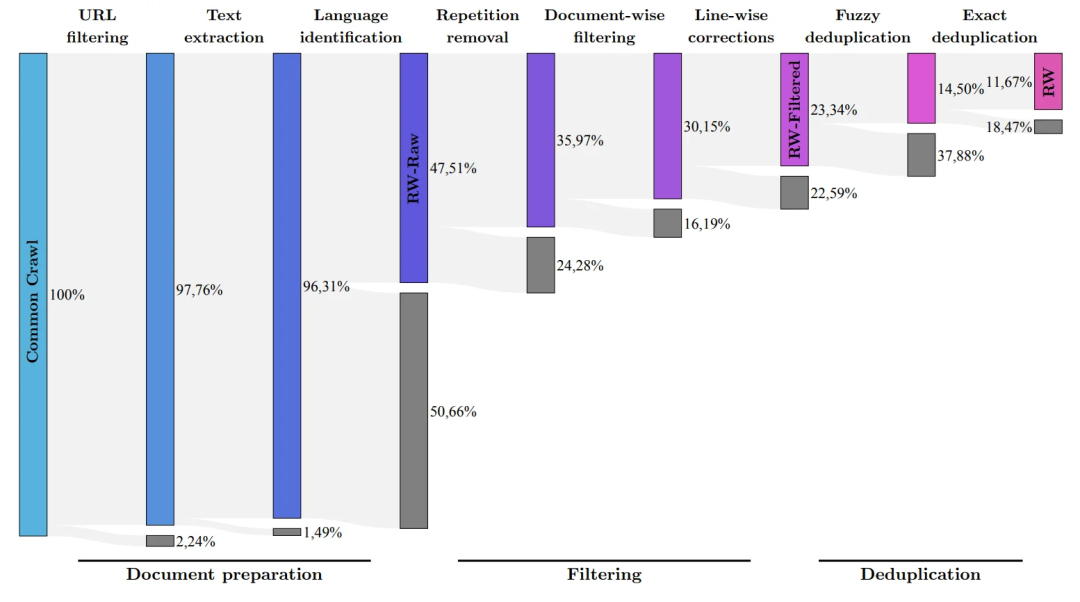
(Pasukan penyelidik bertujuan untuk menapis hanya data mentah berkualiti tinggi daripada Common Crawl menggunakan set data RefinedWeb)
TII berkata berbanding dengan GPT-3, Falcon mencapai keputusan yang sama sambil menggunakan hanya 75% daripada belanjawan pengkomputeran latihan .
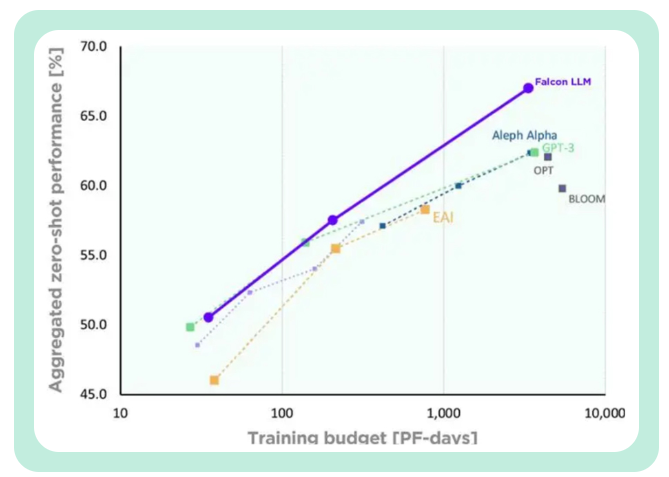
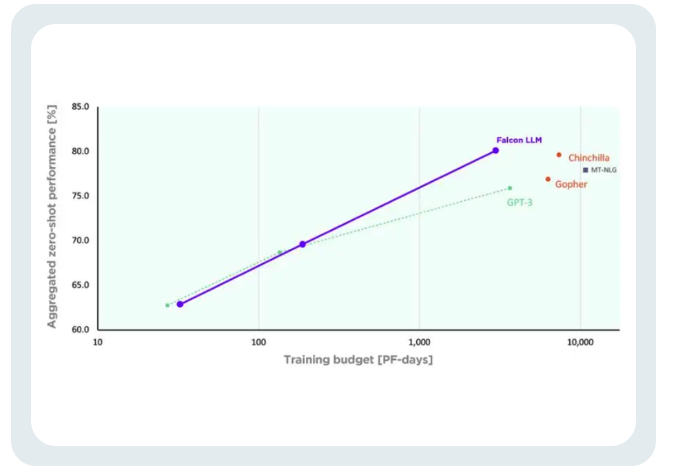
Dan hanya apabila membuat kesimpulan Ia hanya mengambil masa 20 % daripada masa pengiraan.
Kos latihan Falcon hanya bersamaan dengan 40% daripada Chinchilla dan 80% daripada PaLM-62B.
Berjaya mencapai penggunaan sumber pengkomputeran yang cekap.
Atas ialah kandungan terperinci Menghancurkan LLaMA, 'Falcon' adalah sumber terbuka sepenuhnya! 40 bilion parameter, trilion latihan token, menguasai Wajah Memeluk. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



