


Selain menyokong: Tambah, Tulis Ganti, ErrorIfExists, Abaikan; ia juga menyokong operasi kemas kini
Spark menyediakan kelas penghitungan untuk menyokong operasi Sumber data dok. mod
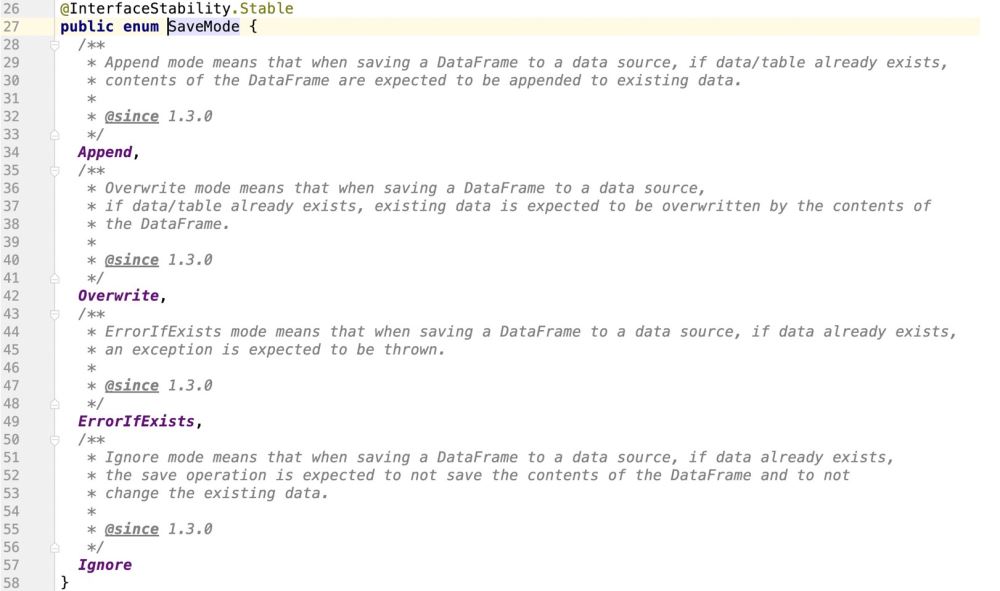
Melihat kod sumber, adalah jelas bahawa percikan tidak menyokong operasi kemas kini
Titik pengetahuan utama ialah:
Apabila kita biasanya menulis data ke mysql dalam sparkSQL:
Anggaran API ialah:
dataframe.write
.format("sql.execution.customDatasource.jdbc")
.option("jdbc.driver", "com.mysql.jdbc.Driver")
.option("jdbc.url", "jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=true&characterEncoding=gbk&autoReconnect=true&failOverReadOnly=false")
.option("jdbc.db", "test")
.save()Kemudian di lapisan bawah, percikan akan Melalui dialek JDBC JdbcDialect, data yang ingin kita masukkan diterjemahkan ke dalam:
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
Kemudian pernyataan sql yang dihuraikan melalui dialek diserahkan kepada mysql melalui PrepareStatement's executeBatch(), dan kemudian data dimasukkan;
Pernyataan sql di atas jelas sekali hanya memasukkan kod, dan tidak mempunyai operasi kemas kini yang kami harapkan, sama seperti:UPDATE table_name SET field1=new-value1, field2=new-value2
INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
INSERT INTO 表名称 (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
3. Sebelum menukar kod sumber, anda perlu memahami keseluruhan reka bentuk kod dan proses pelaksanaan
dataframe.write
Memanggil kaedah tulis adalah untuk mengembalikan a kelas: DataFrameWriter
Terutamanya kerana DataFrameWriter ialah kelas pembawa masukan untuk sparksql untuk menyambung ke sumber data luaran Kandungan berikut ialah maklumat pembawa yang didaftarkan untuk DataFrameWriter
<🎜. > dan kemudian mulakan operasi save() Selepas itu, mulakan menulis data 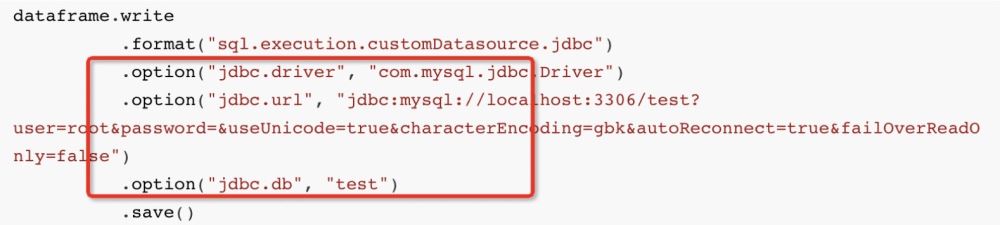
Dalam kod sumber di atas, perkara utama ialah mendaftarkan contoh DataSource, dan kemudian Gunakan kaedah tulis DataSource untuk menulis data 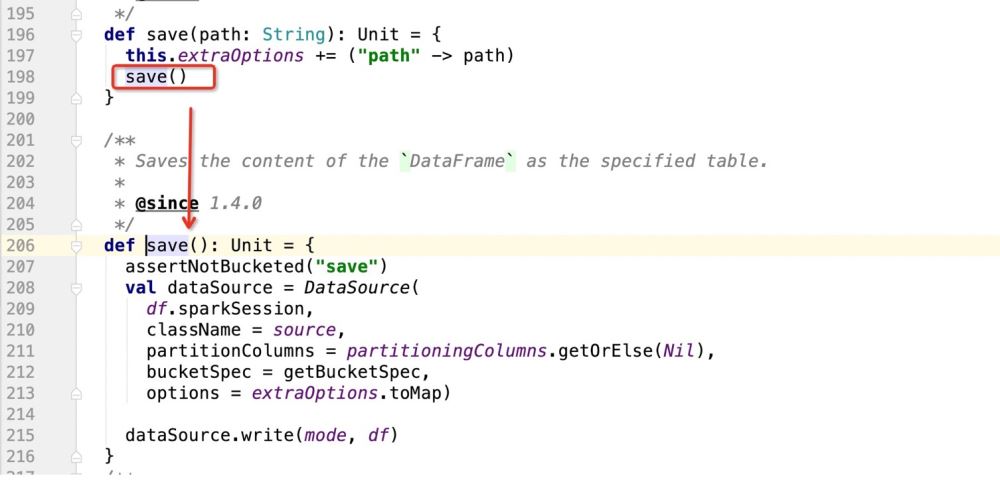
def save(): Unit = {
assertNotBucketed("save")
val dataSource = DataSource(
df.sparkSession,
className = source,//自定义数据源的包路径
partitionColumns = partitioningColumns.getOrElse(Nil),//分区字段
bucketSpec = getBucketSpec,//分桶(用于hive)
options = extraOptions.toMap)//传入的注册信息
//mode:插入数据方式SaveMode , df:要插入的数据
dataSource.write(mode, df)
}Lakukan padanan corak berdasarkan provideClass.newInstance(), dan kemudian laksanakan kod di mana-mana sahaja ia sepadan; >
Kemudian lihat apa itu providingClass:
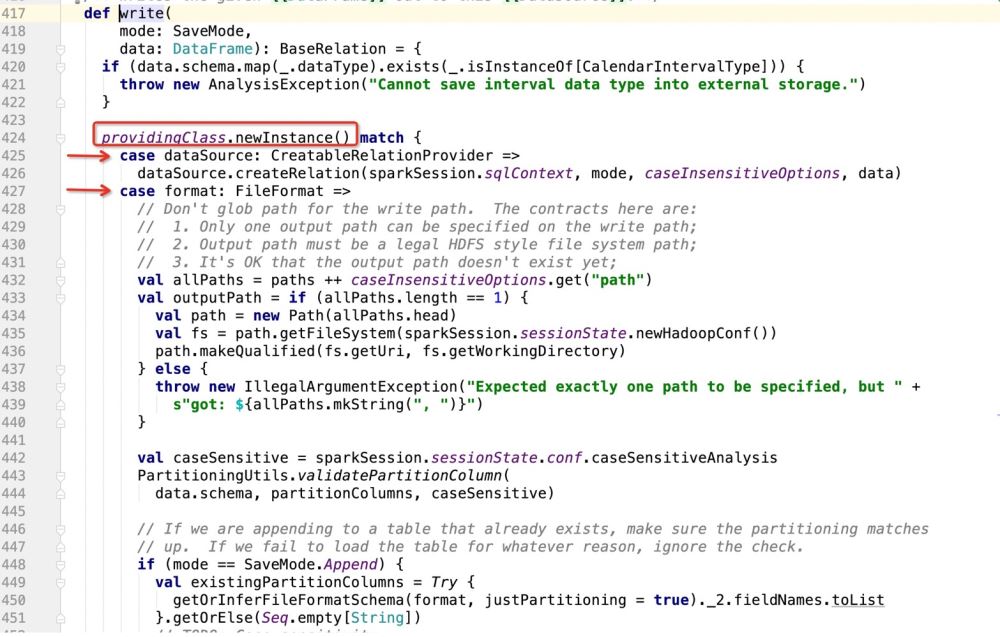
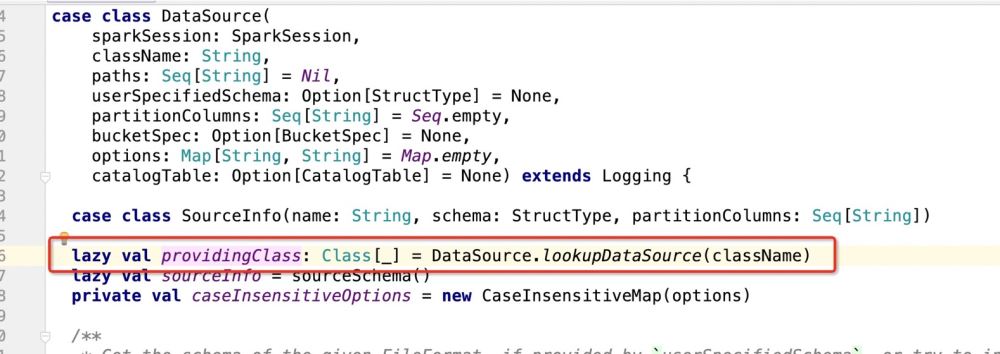
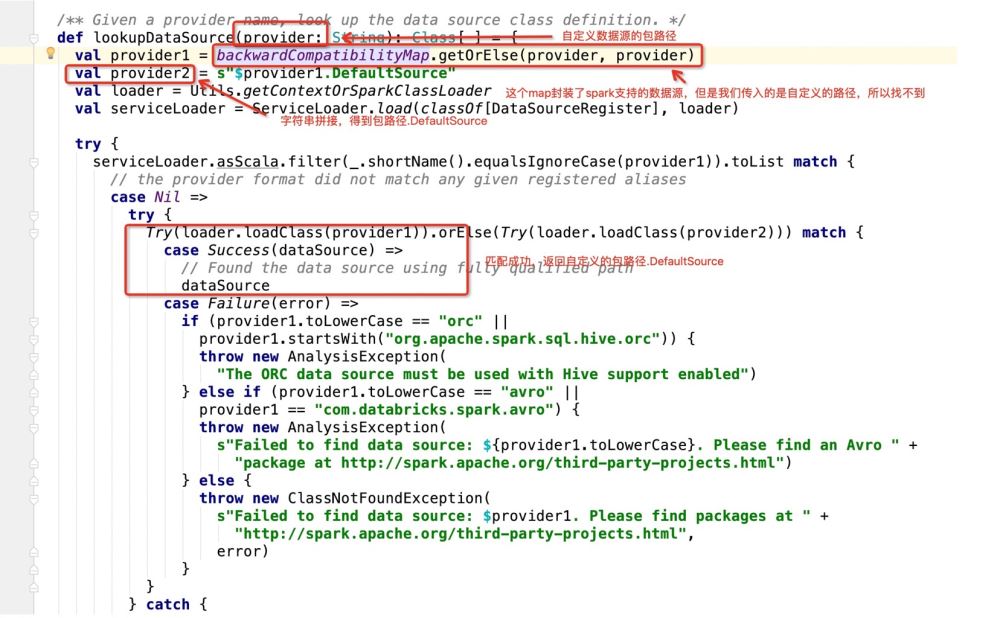 Kemudian jika ia adalah Jika pangkalan data digunakan sebagai sasaran penulisan, ia akan pergi: dataSource.createRelation, dan terus ikuti kod sumber:
Kemudian jika ia adalah Jika pangkalan data digunakan sebagai sasaran penulisan, ia akan pergi: dataSource.createRelation, dan terus ikuti kod sumber:
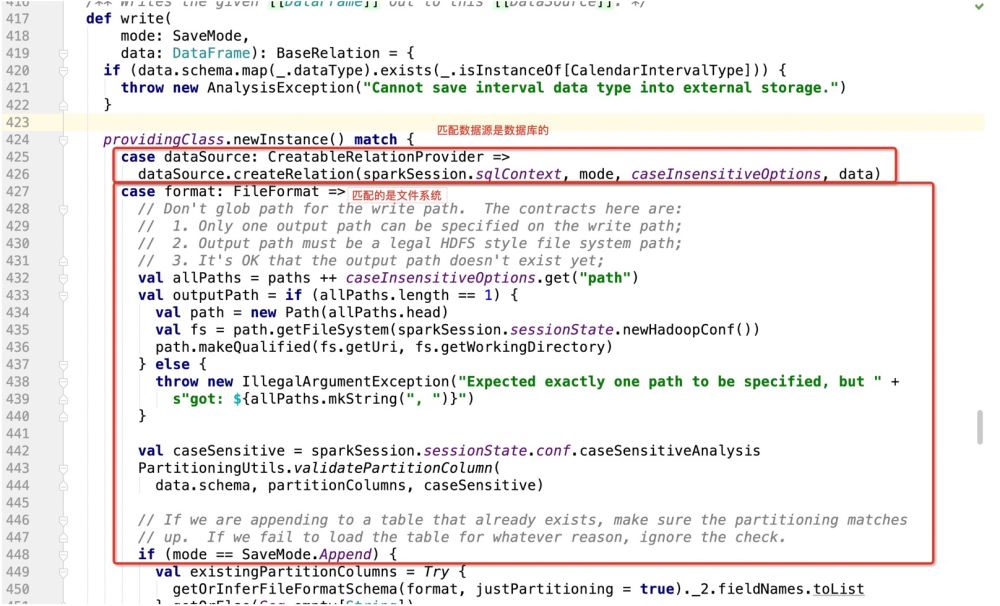 jelas merupakan sifat, jadi di mana sahaja sifat itu dilaksanakan, program akan pergi Di mana ia
jelas merupakan sifat, jadi di mana sahaja sifat itu dilaksanakan, program akan pergi Di mana ia
Tempat untuk melaksanakan ciri ini ialah: laluan pakej.DefaultSource, dan kemudian melaksanakan pemasukan data; dan kemas kini operasi sokongan di sini;
4 Ubah kod sumber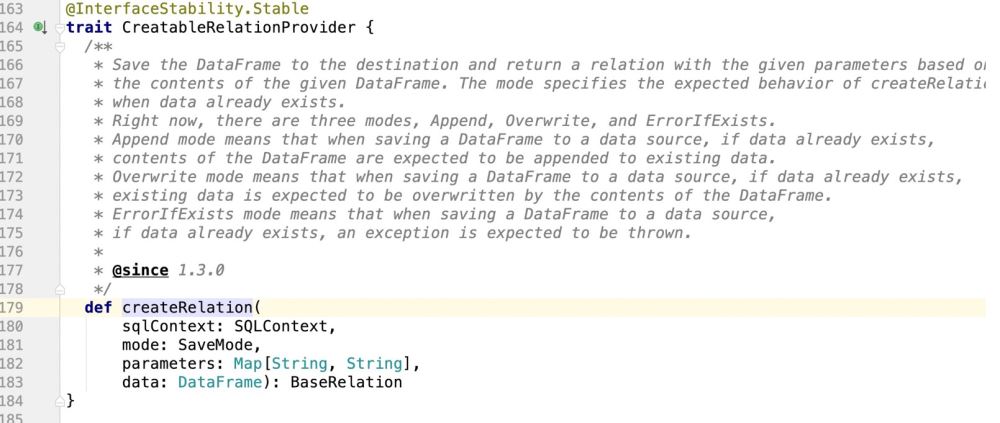
if(isUpdate){
sql语句:INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
}else{
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
}Tiada logik penghakiman, ia adalah yang terakhir dijana:
INSERT INTO TABLE (字段1 , 字段2....) VALUES (? , ? ...)
Jadi tugas pertama ialah bagaimana untuk membuat sokongan kod semasa: ON DUPLICATE KEY UPDATE
Anda boleh membuat reka bentuk yang berani, iaitu, buat pertimbangan berikut dalam kaedah insertStatement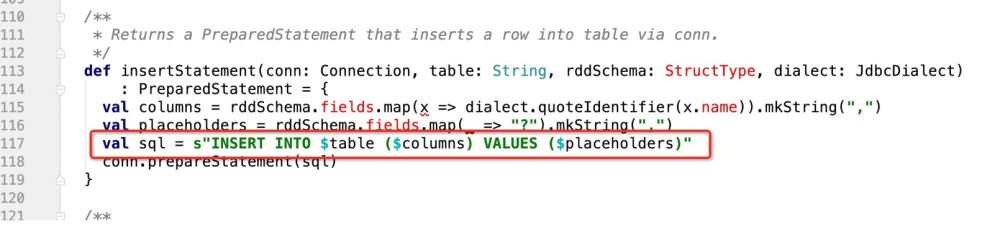
def insertStatement(conn: Connection, savemode:CustomSaveMode , table: String, rddSchema: StructType, dialect: JdbcDialect)
: PreparedStatement = {
val columns = rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",")
val placeholders = rddSchema.fields.map(_ => "?").mkString(",")
if(savemode == CustomSaveMode.update){
//TODO 如果是update,就组装成ON DUPLICATE KEY UPDATE的模式处理
s"INSERT INTO $table ($columns) VALUES ($placeholders) ON DUPLICATE KEY UPDATE $duplicateSetting"
}esle{
val sql = s"INSERT INTO $table ($columns) VALUES ($placeholders)"
conn.prepareStatement(sql)
}
}Dengan cara ini kita mendapat pernyataan sql yang sepadan;
Tetapi hanya Penyataan SQL ini masih tidak akan berfungsi, kerana operasi jdbc prepareStatement akan dilaksanakan dalam percikan, yang akan melibatkan kursor.
Iaitu, apabila jdbc melintasi sql ini, kod sumber akan melakukan ini: 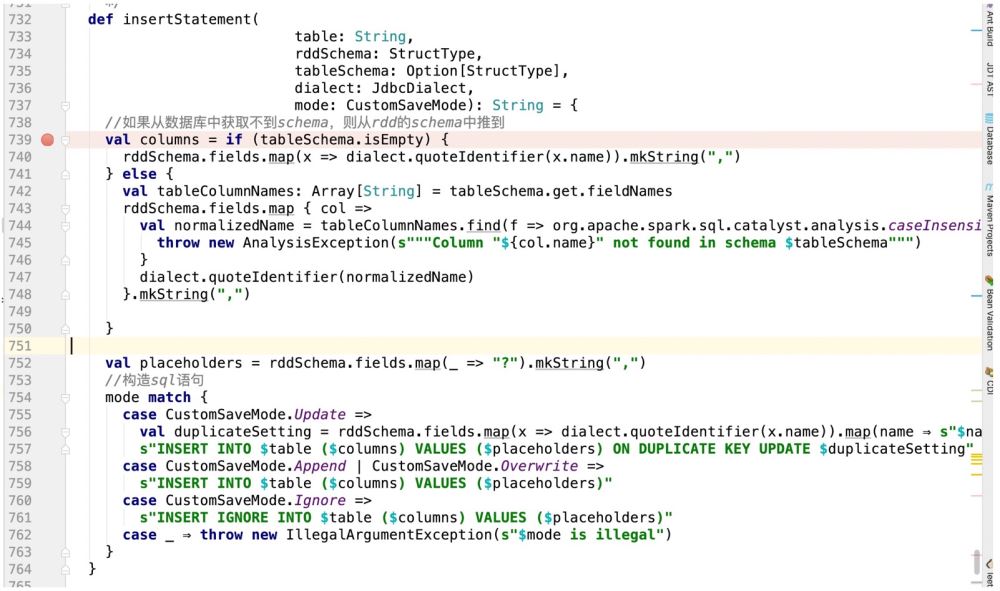
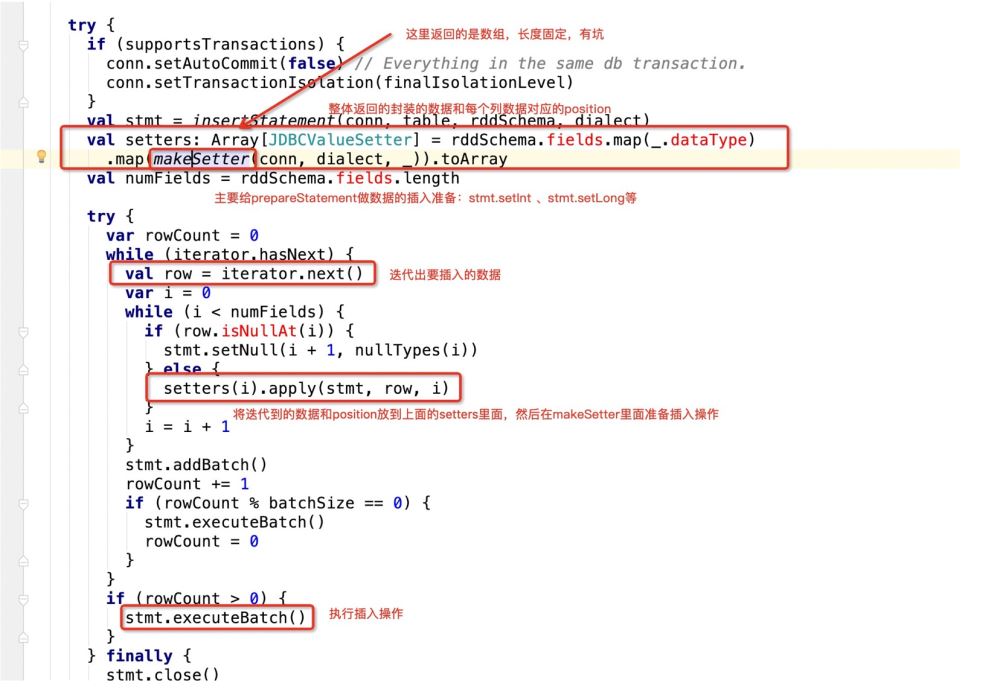
看下makeSetter:

所谓有坑就是:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?)
那么当前在源码中返回的数组长度应该是3:
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray但是如果我们此时支持了update操作,既:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?) ON DUPLICATE KEY UPDATE 字段1 = ?,字段2 = ?,字段3=?;
那么很明显,上面的sql语句提供了6个? , 但在规定字段长度的时候只有3
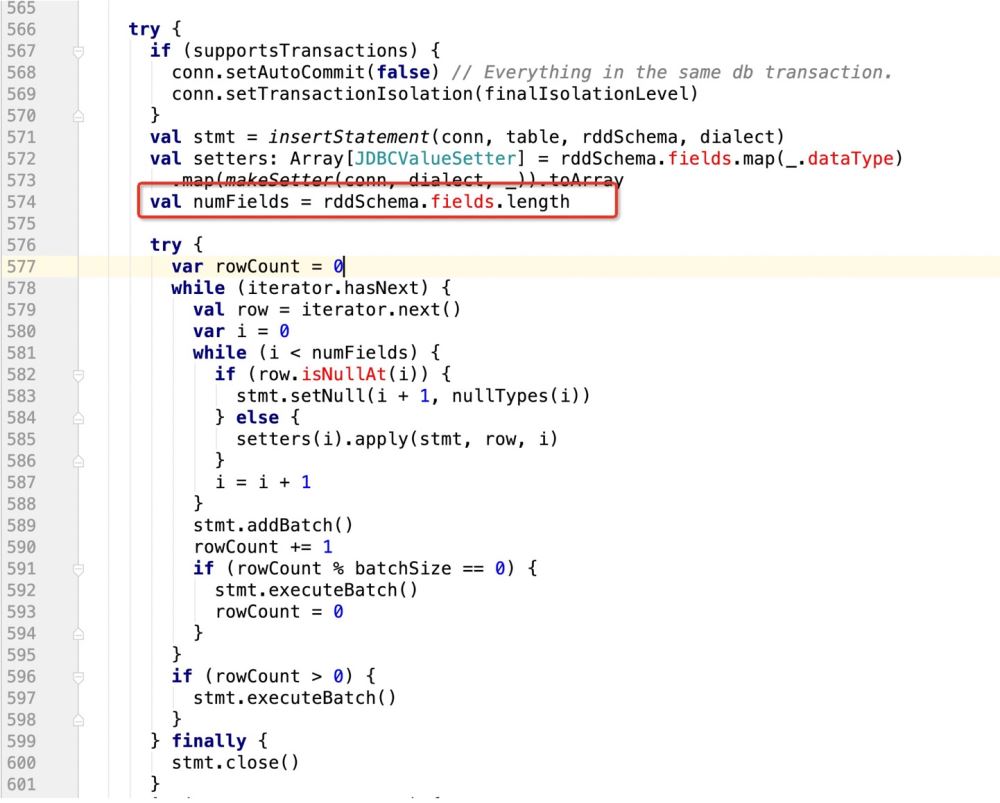
这样的话,后面的update操作就无法执行,程序报错!
所以我们需要有一个 识别机制,既:
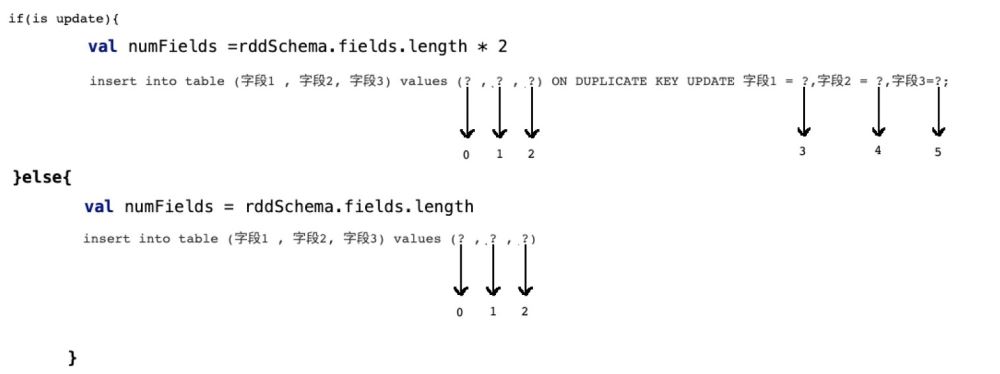
if(isupdate){
val numFields = rddSchema.fields.length * 2
}else{
val numFields = rddSchema.fields.length
}
row[1,2,3] setter(0,1) //index of setter , index of row setter(1,2) setter(2,3) setter(3,1) setter(4,2) setter(5,3)
所以在prepareStatment中的占位符应该是row的两倍,而且应该是类似这样的一个逻辑
因此,代码改造前样子:
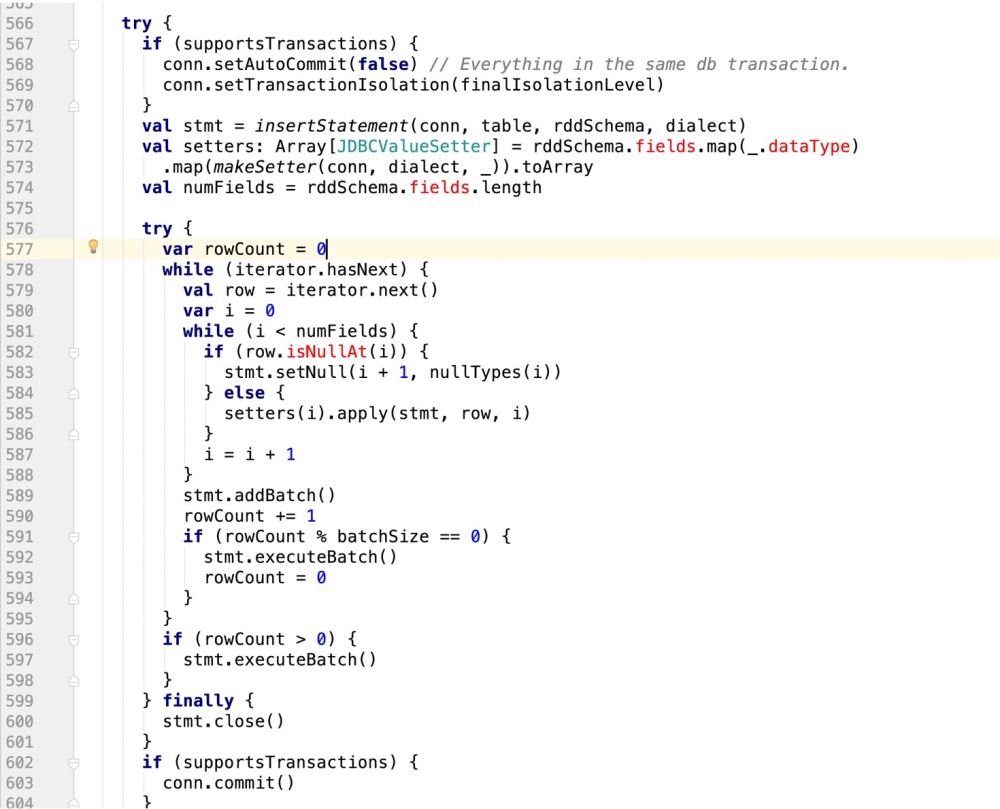
改造后的样子:
try {
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
// val stmt = insertStatement(conn, table, rddSchema, dialect)
//此处采用最新自己的sql语句,封装成prepareStatement
val stmt = conn.prepareStatement(sqlStmt)
println(sqlStmt)
/**
* 在mysql中有这样的操作:
* INSERT INTO user_admin_t (_id,password) VALUES ('1','第一次插入的密码')
* INSERT INTO user_admin_t (_id,password)VALUES ('1','第一次插入的密码') ON DUPLICATE KEY UPDATE _id = 'UpId',password = 'upPassword';
* 如果是下面的ON DUPLICATE KEY操作,那么在prepareStatement中的游标会扩增一倍
* 并且如果没有update操作,那么他的游标是从0开始计数的
* 如果是update操作,要算上之前的insert操作
* */
//makeSetter也要适配update操作,即游标问题
val isUpdate = saveMode == CustomSaveMode.Update
val setters: Array[JDBCValueSetter] = isUpdate match {
case true =>
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
Array.fill(2)(setters).flatten
case _ =>
rddSchema.fields.map(_.dataType)
val numFieldsLength = rddSchema.fields.length
val numFields = isUpdate match{
case true => numFieldsLength *2
case _ => numFieldsLength
val cursorBegin = numFields / 2
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if(isUpdate){
//需要判断当前游标是否走到了ON DUPLICATE KEY UPDATE
i < cursorBegin match{
//说明还没走到update阶段
case true =>
//row.isNullAt 判空,则设置空值
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
//说明走到了update阶段
case false =>
if (row.isNullAt(i - cursorBegin)) {
//pos - offset
stmt.setNull(i + 1, nullTypes(i - cursorBegin))
setters(i).apply(stmt, row, i, cursorBegin)
}
}else{
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i ,0)
}
//滚动游标
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
if (rowCount > 0) {
stmt.executeBatch()
} finally {
stmt.close()
conn.commit()
committed = true
Iterator.empty
} catch {
case e: SQLException =>
val cause = e.getNextException
if (cause != null && e.getCause != cause) {
if (e.getCause == null) {
e.initCause(cause)
} else {
e.addSuppressed(cause)
throw e
} finally {
if (!committed) {
// The stage must fail. We got here through an exception path, so
// let the exception through unless rollback() or close() want to
// tell the user about another problem.
if (supportsTransactions) {
conn.rollback()
conn.close()
} else {
// The stage must succeed. We cannot propagate any exception close() might throw.
try {
conn.close()
} catch {
case e: Exception => logWarning("Transaction succeeded, but closing failed", e)// A `JDBCValueSetter` is responsible for setting a value from `Row` into a field for
// `PreparedStatement`. The last argument `Int` means the index for the value to be set
// in the SQL statement and also used for the value in `Row`.
//PreparedStatement, Row, position , cursor
private type JDBCValueSetter = (PreparedStatement, Row, Int , Int) => Unit
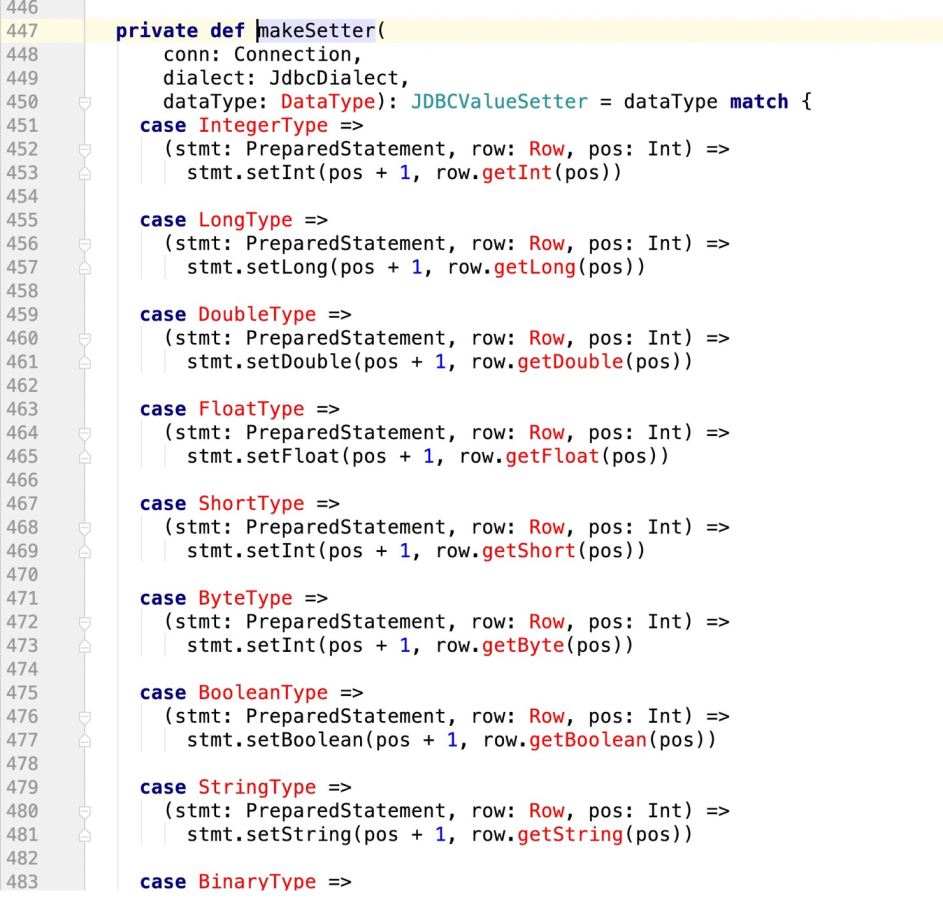
private def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int,cursor:Int) =>
stmt.setInt(pos + 1, row.getInt(pos - cursor))
case LongType =>
stmt.setLong(pos + 1, row.getLong(pos - cursor))
case DoubleType =>
stmt.setDouble(pos + 1, row.getDouble(pos - cursor))
case FloatType =>
stmt.setFloat(pos + 1, row.getFloat(pos - cursor))
case ShortType =>
stmt.setInt(pos + 1, row.getShort(pos - cursor))
case ByteType =>
stmt.setInt(pos + 1, row.getByte(pos - cursor))
case BooleanType =>
stmt.setBoolean(pos + 1, row.getBoolean(pos - cursor))
case StringType =>
// println(row.getString(pos))
stmt.setString(pos + 1, row.getString(pos - cursor))
case BinaryType =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - cursor))
case TimestampType =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - cursor))
case DateType =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - cursor))
case t: DecimalType =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos - cursor))
case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase.split("\\(")(0)
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos - cursor).toArray)
stmt.setArray(pos + 1, array)
case _ =>
(_: PreparedStatement, _: Row, pos: Int,cursor:Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}Atas ialah kandungan terperinci Bagaimana untuk membuat operasi kemas kini sokongan spark sql semasa menulis mysql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



