


Pada penghujung Februari, Meta sumber terbuka siri model besar, LLaMA (diterjemahkan secara literal sebagai alpaca), dengan parameter antara 7 bilion hingga 65 bilion, yang dipanggil prototaip versi Meta ChatGPT. Selepas itu, institusi seperti Stanford University dan University of California, Berkeley, menjalankan "inovasi sekunder" berdasarkan LLaMA, dan berturut-turut melancarkan berbilang model besar sumber terbuka seperti Alpaca dan Vicuna Buat seketika, "Alpaca" menjadi model teratas dalam bulatan AI. Model seperti ChatGPT yang dibina oleh komuniti sumber terbuka ini bergerak dengan cepat dan sangat boleh disesuaikan Ia dipanggil penggantian sumber terbuka ChatGPT.
Walau bagaimanapun, sebab ChatGPT boleh menunjukkan keupayaan yang kuat dalam pemahaman teks, penjanaan, penaakulan, dll. adalah kerana OpenAI menggunakan paradigma latihan baharu-RLHF untuk model besar seperti ChatGPT (Pengukuhan Belajar daripada Maklum Balas Manusia), yang menggunakan pembelajaran peneguhan untuk mengoptimumkan model bahasa berdasarkan maklum balas manusia. Menggunakan kaedah RLHF, model bahasa yang besar boleh diselaraskan dengan pilihan manusia, mengikut niat manusia dan meminimumkan output yang tidak membantu, diherotkan atau berat sebelah. Walau bagaimanapun, kaedah RLHF bergantung pada anotasi dan penilaian manual yang meluas, yang selalunya mengambil masa berminggu-minggu dan beribu-ribu ringgit untuk mengumpul maklum balas manusia, yang memerlukan kos yang tinggi.
Kini, Universiti Stanford, yang melancarkan model sumber terbuka Alpaca, telah mencadangkan satu lagi simulator - AlpacaFarm (diterjemah secara literal sebagai ladang alpaca). AlpacaFarm boleh meniru proses RLHF dalam masa 24 jam untuk hanya kira-kira $200, membenarkan model sumber terbuka dengan cepat meningkatkan hasil penilaian manusia, yang boleh dipanggil setara dengan RLHF.

AlpacaFarm cuba membangunkan kaedah pembelajaran daripada maklum balas manusia dengan cepat dan kos efektif. Untuk melakukan ini, pasukan penyelidik Stanford mula-mula mengenal pasti tiga kesukaran utama dalam mengkaji kaedah RLHF: kos tinggi data keutamaan manusia, kekurangan penilaian yang boleh dipercayai dan kekurangan pelaksanaan rujukan.
Untuk menyelesaikan ketiga-tiga masalah ini, AlpacaFarm membina pelaksanaan konkrit anotasi simulasi, penilaian automatik dan kaedah SOTA. Pada masa ini, kod projek AlpacaFarm adalah sumber terbuka.
Seperti yang ditunjukkan dalam rajah di bawah, penyelidik boleh menggunakan simulator AlpacaFarm untuk membangunkan kaedah baharu pembelajaran dengan cepat daripada data maklum balas manusia, dan juga boleh memindahkan kaedah SOTA sedia ada kepada data keutamaan manusia.
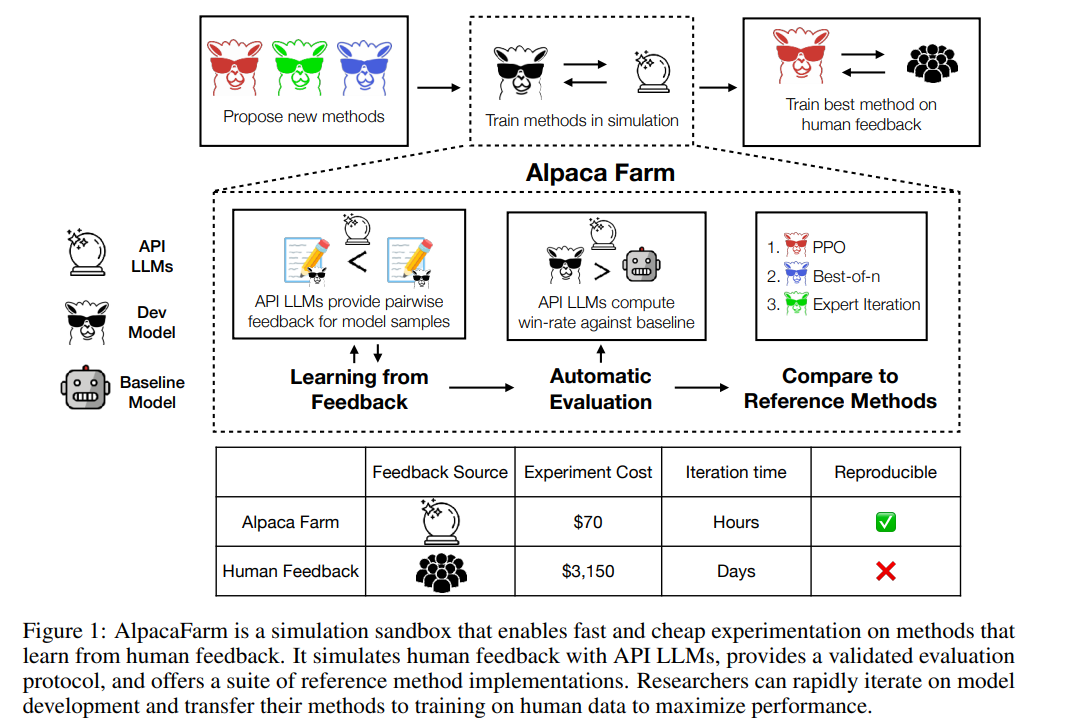
Arahan 52k AlpacaFarm berdasarkan Alpaca dataset Build, yang mana 10k arahan digunakan untuk memperhalusi arahan asas mengikut model, baki 42k arahan digunakan untuk mempelajari keutamaan dan penilaian manusia, dan kebanyakannya digunakan untuk belajar daripada anotasi simulasi. Kajian ini menangani tiga cabaran utama kos anotasi, penilaian dan pelaksanaan pengesahan kaedah RLHF, dan mencadangkan penyelesaian satu demi satu.
Pertama, untuk mengurangkan kos anotasi, kajian ini mencipta gesaan untuk LLM dengan API boleh diakses (seperti GPT-4, ChatGPT), membolehkan AlpacaFarm mensimulasikan maklum balas manusia pada kos hanya Kaedah RLHF 1/45 daripada data yang dikumpul. Kajian ini mereka bentuk skema anotasi rawak dan bising menggunakan 13 gesaan berbeza untuk mengekstrak pilihan manusia yang berbeza daripada berbilang LLM. Skim anotasi ini bertujuan untuk menangkap pelbagai aspek maklum balas manusia, seperti pertimbangan kualiti, kebolehubahan antara anotasi dan pilihan gaya.
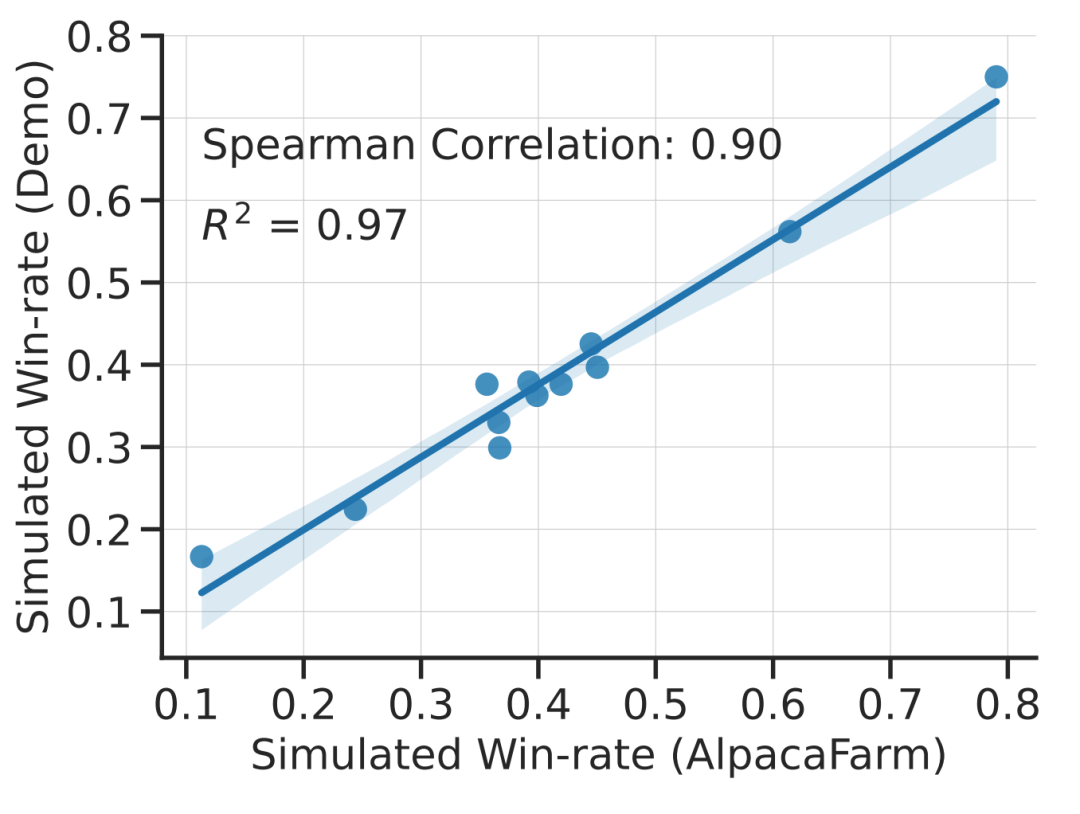
Kajian ini secara eksperimen menunjukkan bahawa simulasi AlpacaFarm adalah tepat. Apabila pasukan penyelidik menggunakan AlpacaFarm untuk melatih dan membangunkan kaedah, kaedah tersebut dinilai sangat konsisten dengan kaedah yang sama yang dilatih dan dibangunkan menggunakan maklum balas manusia sebenar. Rajah di bawah menunjukkan korelasi yang tinggi dalam kedudukan antara kaedah yang terhasil daripada aliran kerja simulasi AlpacaFarm dan aliran kerja maklum balas manusia. Sifat ini penting kerana ia menunjukkan bahawa kesimpulan eksperimen yang dibuat daripada simulasi berkemungkinan berlaku dalam situasi sebenar.
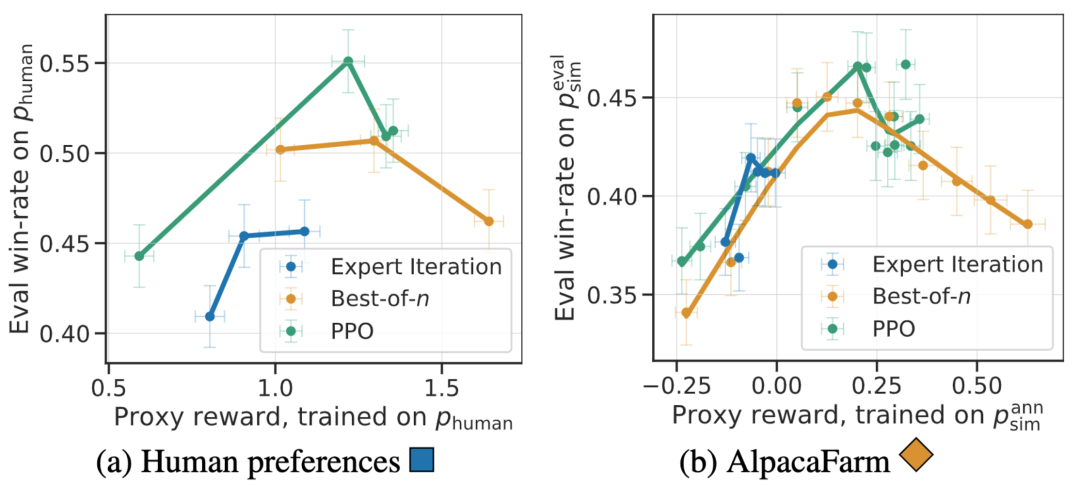
Selain korelasi peringkat kaedah, simulator AlpacaFarm juga boleh meniru fenomena kualitatif seperti pengoptimuman model ganjaran yang berlebihan, tetapi latihan RLHF berterusan untuk ganjaran pengganti boleh merosakkan prestasi Model. Rajah di bawah menunjukkan fenomena ini dalam kes maklum balas manusia (kiri) dan AlpacaFarm (kanan).
Dari segi penilaian, pasukan penyelidik menggunakan Alpaca Interaksi pengguna masa nyata 7B sebagai panduan dan mensimulasikan pengedaran arahan dengan menggabungkan beberapa set data awam sedia ada, termasuk set data arahan kendiri, set data bantuan antropopik dan set penilaian Open Assistant, Koala dan Vicuna. Menggunakan arahan penilaian ini, kajian membandingkan tindak balas model RLHF kepada model Davinci003 dan menggunakan skor untuk mengukur bilangan kali model RLHF bertindak balas dengan lebih baik, memanggil skor ini sebagai kadar kemenangan. Seperti yang ditunjukkan dalam rajah di bawah, penilaian kuantitatif kedudukan sistem pada data penilaian kajian menunjukkan bahawa kedudukan sistem dan arahan pengguna masa nyata sangat berkorelasi. Keputusan ini menunjukkan bahawa mengagregatkan data awam sedia ada boleh mencapai prestasi yang serupa dengan arahan sebenar yang mudah.
Untuk cabaran ketiga - tiada rujukan Pelaksanaan, Pasukan penyelidik melaksanakan dan menguji beberapa algoritma pembelajaran yang popular (seperti PPO, lelaran pakar, terbaik-of-n, pensampelan). Pasukan penyelidik mendapati bahawa kaedah yang lebih mudah yang berfungsi dalam domain lain tidak lebih baik daripada model SFT asal kajian, menunjukkan bahawa adalah penting untuk menguji algoritma ini dalam persekitaran mengikut arahan sebenar.
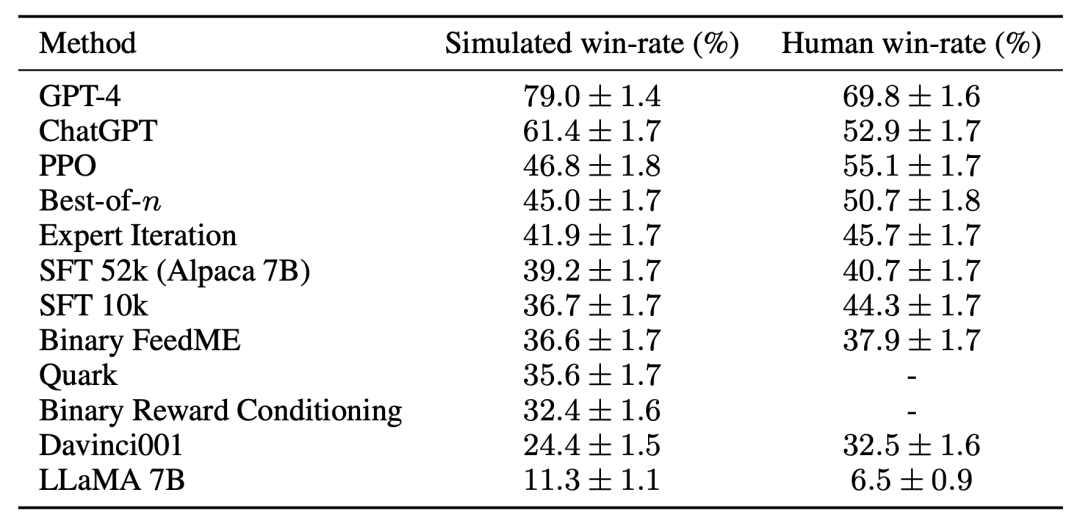
Menurut penilaian manusia, algoritma PPO terbukti paling berkesan, menggabungkan model dengan Kadar kemenangan berbanding Davinci003 meningkat daripada 44% kepada 55%, malah mengatasi ChatGPT.
Keputusan ini menunjukkan bahawa algoritma PPO sangat berkesan dalam mengoptimumkan kadar kemenangan untuk model tersebut. Adalah penting untuk ambil perhatian bahawa keputusan ini adalah khusus untuk data penilaian dan anotasi kajian ini. Walaupun arahan penilaian kajian mewakili arahan pengguna masa nyata, arahan itu mungkin tidak meliputi masalah yang lebih mencabar, dan tidak pasti berapa banyak peningkatan dalam kadar kemenangan datang daripada mengeksploitasi keutamaan gaya dan bukannya fakta atau ketepatan. Sebagai contoh, kajian mendapati bahawa model PPO menghasilkan output yang lebih panjang dan sering memberikan penjelasan yang lebih terperinci untuk jawapan, seperti yang ditunjukkan di bawah:

Atas ialah kandungan terperinci Dalam masa 24 jam dan $200 untuk menyalin proses RLHF, Stanford mendapatkan sumber terbuka 'Ladang Alpaca'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah jenis pemilih css yang ada?
Apakah jenis pemilih css yang ada? Adakah Bitcoin sah di China?
Adakah Bitcoin sah di China? Bagaimana untuk menyelesaikan 404 tidak dijumpai
Bagaimana untuk menyelesaikan 404 tidak dijumpai Kaedah Window.setInterval().
Kaedah Window.setInterval(). bagaimana untuk membuka fail php
bagaimana untuk membuka fail php Bagaimana untuk membatalkan pembaharuan automatik Kad Simpanan Wang Taobao
Bagaimana untuk membatalkan pembaharuan automatik Kad Simpanan Wang Taobao Terdapat beberapa jenis kernel pelayar
Terdapat beberapa jenis kernel pelayar Bagaimana untuk menyelesaikan pengecualian membaca fail besar Java
Bagaimana untuk menyelesaikan pengecualian membaca fail besar Java




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



