


Pada tahun 2017, pasukan Google Brain secara kreatif mencadangkan seni bina Transformer dalam kertas kerjanya "Perhatian Adalah Semua yang Anda Perlukan". bidang hari ini, ia digunakan secara meluas dalam pelbagai tugas bahasa dan telah mencapai banyak keputusan SOTA.
Bukan itu sahaja, Transformer, yang telah menerajui bidang NLP, telah dengan pantas melanda pelbagai bidang seperti penglihatan komputer (CV) dan pengecaman pertuturan, dan telah mencapai prestasi yang baik. menghasilkan tugasan seperti pengelasan imej, pengesanan sasaran dan kesan pengecaman pertuturan.

Alamat kertas: https://arxiv.org/pdf/1706.03762 .pdf
Sejak pelancarannya, Transformer telah menjadi modul teras bagi banyak model, seperti BERT, T5, dsb. Transformer yang biasa digunakan. Malah ChatGPT, yang menjadi popular baru-baru ini, bergantung pada Transformer, yang telah dipatenkan oleh Google.

Sumber imej: https://patentimages.storage.googleapis.com /05/e8/f1/cd8eed389b7687/US10452978.pdf
Selain itu, siri model GPT (Generative Pre-trained Transformer) yang dikeluarkan oleh OpenAI mempunyai Transformer dalam nama , jadi anda boleh melihat Transformer Ia adalah teras siri model GPT.
Pada masa yang sama, pengasas bersama OpenAI Ilya Stutskever baru-baru ini berkata apabila bercakap tentang Transformer bahawa apabila Transformer mula-mula dikeluarkan, ia sebenarnya adalah hari kedua selepas kertas itu dikeluarkan Jangan tunggu untuk menukar penyelidikan saya sebelum ini kepada Transformer, dan kemudian GPT diperkenalkan. Ia dapat dilihat bahawa kepentingan Transformer adalah jelas.
Dalam tempoh 6 tahun, model berasaskan Transformer telah terus berkembang dan berkembang. Kini, bagaimanapun, seseorang telah menemui ralat dalam kertas Transformer asal.
Orang yang menemui ralat itu ialah Sebastian, seorang penyelidik pembelajaran mesin dan AI yang terkenal serta ketua pendidik AI daripada permulaan Lightning AI. Beliau menegaskan bahawa gambar rajah seni bina dalam kertas Transformer asal adalah tidak betul, meletakkan normalisasi lapisan (LN) antara blok baki, yang tidak konsisten dengan kod.
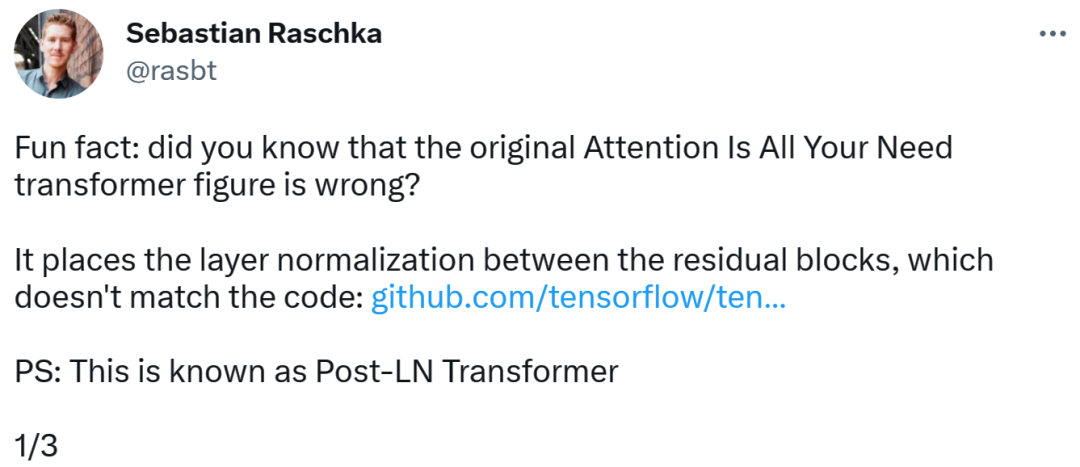
Rajah seni bina Transformer adalah seperti berikut: di sebelah kiri, dan di sebelah kanan ialah lapisan Post-LN Transformer (daripada kertas "On Layer Normalization in the Transformer Architecture" [1]).
Bahagian kod yang tidak konsisten adalah seperti berikut. Baris 82 menulis urutan pelaksanaan "layer_postprocess_sequence="dan"", yang bermaksud bahawa pasca pemprosesan melaksanakan keciciran, residual_add dan layer_norm dalam urutan. Jika add&norm di bahagian tengah kiri gambar di atas difahami sebagai: tambah adalah di atas norma, iaitu norma dahulu dan kemudian tambah, maka kod itu memang tidak konsisten dengan gambar.
Alamat kod:
https://github.com/tensorflow/tensor2tensor/commit/ f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef16871bdbf46bf04dfe7f1477bafb884748f08197c9 Seterusnya, Sebastian berkata bahawa kertas kerja "On Layer Normalization in the Transformer Architecture" percaya bahawa Pra-LN berprestasi lebih baik dan boleh menyelesaikan masalah kecerunan . Inilah yang dilakukan oleh kebanyakan atau kebanyakan seni bina dalam amalan, tetapi ia boleh membawa kepada rasuah perwakilan.
Kecerunan yang lebih baik dicapai apabila penormalan lapisan diletakkan dalam sambungan baki sebelum perhatian dan lapisan bersambung sepenuhnya.
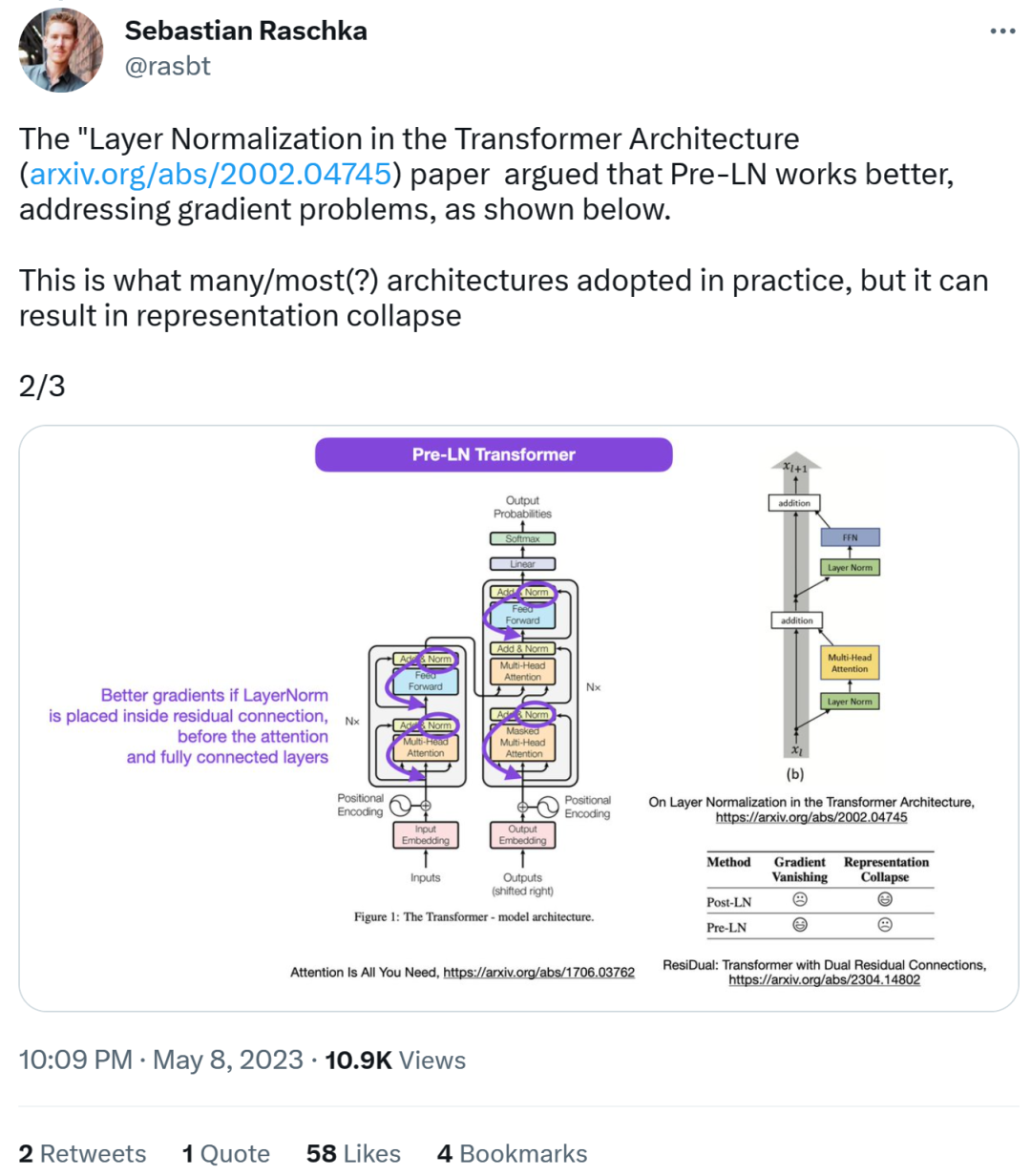
Jadi sementara perbahasan mengenai Pasca-LN atau Pra-LN diteruskan, kertas lain menggabungkan Kedua-dua perkara ini ditangani dalam "ResiDual: Transformer dengan Dual Residual Connections"[2].
Mengenai penemuan Sebastian, sesetengah orang berpendapat bahawa kita sering menemui kertas yang tidak konsisten dengan kod atau keputusan. Kebanyakannya jujur, tetapi kadang-kadang ia pelik. Memandangkan populariti kertas Transformer, ketidakkonsistenan ini sepatutnya disebut seribu kali.
Sebastian menjawab bahawa untuk bersikap adil, kod "paling asli" memang konsisten dengan gambar rajah seni bina, tetapi versi kod yang diserahkan pada 2017 telah diubah suai dan gambar rajah seni bina tidak dikemas kini. Jadi, ini benar-benar mengelirukan.
Seperti seorang netizen berkata, "Perkara yang paling teruk tentang membaca kod ialah anda akan Anda sering menemui perubahan kecil seperti ini, dan anda tidak tahu sama ada ia disengajakan atau tidak anda tidak boleh mengujinya kerana anda tidak mempunyai kuasa pengkomputeran yang mencukupi untuk melatih model tersebut.”
Saya tertanya-tanya apa yang akan Google lakukan seterusnya sama ada untuk mengemas kini kod atau gambar rajah seni bina, kami akan tunggu dan lihat!
Atas ialah kandungan terperinci Gambar itu tidak konsisten dengan kod yang ditemui dalam kertas Transformer: Ia sepatutnya ditunjukkan 1,000 kali.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pengenalan kepada penggunaan kod keseluruhan vbs
Pengenalan kepada penggunaan kod keseluruhan vbs
 Apakah sistem pengurusan biasa?
Apakah sistem pengurusan biasa?
 Urutan keutamaan pengendali dalam bahasa c
Urutan keutamaan pengendali dalam bahasa c
 Bagaimana untuk melaraskan kecerahan skrin komputer
Bagaimana untuk melaraskan kecerahan skrin komputer
 Harga terkini Dogecoin hari ini
Harga terkini Dogecoin hari ini
 Bagaimana untuk menyelesaikan ranap permulaan tomcat
Bagaimana untuk menyelesaikan ranap permulaan tomcat
 penggunaan operator shift js
penggunaan operator shift js
 Bagaimana untuk mengoptimumkan satu halaman
Bagaimana untuk mengoptimumkan satu halaman








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



