


Bayangkan anda mempunyai masalah besar untuk diselesaikan dan anda bersendirian. Anda perlu mengira punca kuasa dua bagi lapan nombor yang berbeza. awak buat apa? Anda tidak mempunyai banyak pilihan. Mulakan dengan nombor pertama dan hitung hasilnya. Kemudian anda beralih kepada orang lain.
Bagaimana jika anda mempunyai tiga rakan yang mahir dalam matematik dan ingin membantu anda? Setiap daripada mereka akan mengira punca kuasa dua dua nombor, dan tugas anda akan menjadi lebih mudah kerana beban kerja diagihkan sama rata di kalangan rakan anda. Ini bermakna isu anda akan diselesaikan dengan lebih cepat.
Baiklah, adakah semuanya jelas? Dalam contoh ini, setiap rakan mewakili teras CPU. Dalam contoh pertama, keseluruhan tugas diselesaikan oleh anda secara berurutan. Ini dipanggil Pengiraan Bersiri. Dalam contoh kedua, memandangkan anda menggunakan sejumlah empat teras, anda menggunakan pengkomputeran selari. Pengkomputeran selari melibatkan penggunaan proses selari atau proses yang dibahagikan antara berbilang teras pemproses.
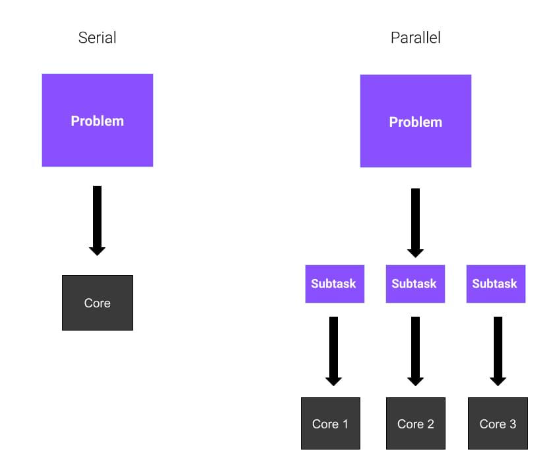
Kami telah menetapkan apakah pengaturcaraan selari, tetapi bagaimana kami menggunakannya? Kami berkata sebelum ini bahawa pengkomputeran selari melibatkan pelaksanaan berbilang tugas merentas berbilang teras pemproses, bermakna tugas ini dilaksanakan serentak. Sebelum meneruskan penyejajaran, anda harus mempertimbangkan beberapa isu. Sebagai contoh, adakah terdapat pengoptimuman lain yang boleh mempercepatkan pengiraan kami?
Sekarang, mari kita ambil mudah bahawa penyejajaran adalah penyelesaian yang paling sesuai. Terdapat tiga mod utama pengkomputeran selari:
Sejajar sepenuhnya . Tugasan boleh berjalan secara bebas dan tidak perlu berkomunikasi antara satu sama lain.
Persamaan memori dikongsi. Proses (atau rangkaian) perlu berkomunikasi, jadi mereka berkongsi ruang alamat global.
Pemesejan. Proses perlu berkongsi mesej apabila diperlukan.
Dalam artikel ini, kami akan menerangkan model pertama, yang juga paling mudah.
Salah satu cara untuk mencapai keselarian dalam Python ialah menggunakan modul pemprosesan berbilang. multiprocessingModul membolehkan anda mencipta berbilang proses, setiap satu dengan penterjemah Python sendiri. Oleh itu, Python multiprocessing melaksanakan selari berasaskan proses.
Anda mungkin pernah mendengar tentang perpustakaan lain, seperti threading, yang juga terbina dalam Python, tetapi terdapat perbezaan penting antara perpustakaan tersebut. multiprocessing modul mencipta proses baharu, manakala threading mencipta urutan baharu.
Anda mungkin bertanya, "Mengapa memilih berbilang proses boleh meningkatkan kecekapan program dengan ketara dengan menjalankan berbilang tugas secara selari dan bukannya secara berurutan . Istilah yang sama ialah multithreading, tetapi ia berbeza.
Proses ialah atur cara yang dimuatkan ke dalam memori untuk dijalankan dan tidak berkongsi ingatannya dengan proses lain. Benang ialah unit pelaksanaan dalam proses. Berbilang benang berjalan dalam satu proses dan berkongsi ruang memori proses antara satu sama lain.
Kunci Jurubahasa Global (GIL) Python hanya membenarkan satu utas dijalankan pada satu masa di bawah jurubahasa, yang bermaksud bahawa jika anda memerlukan jurubahasa Python, anda tidak akan menikmati faedah prestasi pelbagai benang. Inilah sebabnya mengapa pemprosesan berbilang lebih berfaedah daripada threading dalam Python. Pelbagai proses boleh berjalan selari kerana setiap proses mempunyai penterjemah sendiri yang melaksanakan arahan yang diberikan kepadanya. Selain itu, sistem pengendalian akan melihat program anda dalam berbilang proses dan menjadualkannya secara berasingan, iaitu, program anda akan mempunyai bahagian yang lebih besar daripada jumlah sumber komputer. Oleh itu, pemprosesan berbilang lebih pantas apabila program terikat kepada CPU. Dalam situasi di mana terdapat banyak I/O dalam program, benang mungkin lebih cekap kerana kebanyakan masa, program sedang menunggu I/O selesai. Walau bagaimanapun, pelbagai proses biasanya lebih cekap kerana ia berjalan serentak.
Berikut ialah beberapa faedah pemprosesan berbilang:
Penggunaan CPU yang lebih baik apabila mengendalikan tugas intensif CPU yang tinggi
Lagi kawalan ke atas benang kanak-kanak daripada benang
Mudah dikodkan
Kelebihan pertama adalah berkaitan dengan prestasi. Memandangkan pemproses berbilang menghasilkan proses baharu, anda boleh menggunakan kuasa pengkomputeran CPU dengan lebih baik dengan membahagikan tugas antara teras lain. Kebanyakan pemproses hari ini adalah berbilang teras, dan jika anda mengoptimumkan kod anda, anda boleh menjimatkan masa melalui pengkomputeran selari.
Kelebihan kedua ialah alternatif kepada multi-threading. Benang bukan proses, dan ini mempunyai akibatnya. Jika anda mencipta utas, adalah berbahaya untuk menamatkannya seperti proses biasa atau mengganggunya. Memandangkan perbandingan antara multi-processing dan multi-threading adalah di luar skop artikel ini, saya akan menulis artikel yang berasingan kemudian untuk membincangkan perbezaan antara multi-processing dan multi-threading.
Kelebihan ketiga multiprocessing ialah ia mudah dilaksanakan kerana tugasan yang anda cuba kendalikan sesuai untuk pengaturcaraan selari.
Kami akhirnya bersedia untuk menulis beberapa kod Python!
Kami akan bermula dengan contoh yang sangat asas yang akan kami gunakan untuk menggambarkan aspek teras pemproses berbilang Python. Dalam contoh ini, kita akan mempunyai dua proses:
parentselalunya. Hanya terdapat satu proses induk dan ia boleh mempunyai berbilang proses anak.
childProses. Ini dihasilkan oleh proses induk. Setiap proses kanak-kanak juga boleh mempunyai proses anak baharu.
Kami akan menggunakan prosedur child ini untuk melaksanakan fungsi. Dengan cara ini, parent boleh meneruskan pelaksanaan.
Ini ialah kod yang akan kami gunakan untuk contoh ini:
from multiprocessing import Process
def bubble_sort(array):
check = True
while check == True:
check = False
for i in range(0, len(array)-1):
if array[i] > array[i+1]:
check = True
temp = array[i]
array[i] = array[i+1]
array[i+1] = temp
print("Array sorted: ", array)
if __name__ == '__main__':
p = Process(target=bubble_sort, args=([1,9,4,5,2,6,8,4],))
p.start()
p.join()Dalam coretan ini kami mentakrifkan fungsi bernama bubble_sort(array). Fungsi ini ialah pelaksanaan algoritma isihan gelembung yang sangat mudah. Jika anda tidak tahu apa itu, jangan risau kerana ia tidak penting. Perkara utama yang perlu diketahui ialah ia adalah fungsi yang melakukan sesuatu.
Dari multiprocessing, kami mengimport kelas Process. Kelas ini mewakili aktiviti yang akan dijalankan dalam proses yang berasingan. Malah, anda dapat melihat bahawa kami telah melepasi beberapa parameter:
target=bubble_sort, bermakna proses baharu kami akan menjalankan fungsi bubble_sort
args=([1,9,4,52,6,8,4],), iaitu tatasusunan yang diluluskan sebagai hujah kepada fungsi sasaran
Setelah kami mencipta contoh kelas Proses, kami hanya perlu memulakan proses. Ini dilakukan dengan menulis p.start(). Pada ketika ini, proses bermula.
Kita perlu menunggu proses kanak-kanak menyelesaikan pengiraannya sebelum kita keluar. Kaedah join() menunggu sehingga proses ditamatkan.
Dalam contoh ini, kami hanya mencipta satu proses anak. Seperti yang anda fikirkan, kami boleh mencipta lebih banyak proses anak dengan mencipta lebih banyak kejadian dalam kelas Process.
Bagaimana jika kita perlu mencipta berbilang proses untuk mengendalikan lebih banyak tugasan yang memerlukan CPU? Adakah kita sentiasa perlu memulakan secara eksplisit dan menunggu penamatan? Penyelesaian di sini ialah menggunakan kelas Pool. Kelas
Pool membolehkan anda mencipta kumpulan proses pekerja, dalam contoh berikut kita akan melihat cara menggunakannya. Berikut ialah contoh baharu kami:
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
with Pool() as pool:
result = pool.map(cube, range(10,N))
print("Program finished!")Dalam coretan kod ini, kami mempunyai fungsi cube(x) yang hanya mengambil integer dan mengembalikan punca kuasa duanya. Cukup mudah, bukan?
Kemudian, kami mencipta contoh kelas Pool tanpa menyatakan sebarang sifat. Secara lalai, kelas Pool mencipta satu proses bagi setiap teras CPU. Seterusnya, kami menjalankan kaedah map dengan beberapa parameter. Kaedah
map menggunakan fungsi cube pada setiap elemen boleh lelar yang kami sediakan - dalam kes ini, ini ialah senarai setiap nombor daripada 10 hingga N .
Kelebihan terbesar ini ialah pengiraan dalam senarai dilakukan secara selari! Pakej
joblib ialah satu set alatan yang memudahkan pengkomputeran selari. Ia adalah perpustakaan pihak ketiga tujuan umum untuk pelbagai proses. Ia juga menyediakan keupayaan caching dan serialisasi. Untuk memasang pakej joblib, gunakan arahan berikut dalam terminal:
pip install joblib
Kita boleh menukar contoh sebelumnya kepada contoh berikut untuk digunakan joblib:
from joblib import Parallel, delayed
def cube(x):
return x**3
start_time = time.perf_counter()
result = Parallel(n_jobs=3)(delayed(cube)(i) for i in range(1,1000))
finish_time = time.perf_counter()
print(f"Program finished in {finish_time-start_time} seconds")
print(result)Malah, intuitif untuk melihat kesannya. delayed()Fungsi ialah pembalut di sekeliling fungsi lain yang menjana versi "tertunda" bagi panggilan fungsi. Ini bermakna ia tidak melaksanakan fungsi dengan segera apabila dipanggil.
然后,我们多次调用delayed函数,并传递不同的参数集。例如,当我们将整数1赋予cube函数的延迟版本时,我们不计算结果,而是分别为函数对象、位置参数和关键字参数生成元组(cube, (1,), {})。
我们使用Parallel()创建了引擎实例。当它像一个以元组列表作为参数的函数一样被调用时,它将实际并行执行每个元组指定的作业,并在所有作业完成后收集结果作为列表。在这里,我们创建了n_jobs=3的Parallel()实例,因此将有三个进程并行运行。
我们也可以直接编写元组。因此,上面的代码可以重写为:
result = Parallel(n_jobs=3)((cube, (i,), {}) for i in range(1,1000))使用joblib的好处是,我们可以通过简单地添加一个附加参数在多线程中运行代码:
result = Parallel(n_jobs=3, prefer="threads")(delayed(cube)(i) for i in range(1,1000))
这隐藏了并行运行函数的所有细节。我们只是使用与普通列表理解没有太大区别的语法。
创建多个进程并进行并行计算不一定比串行计算更有效。对于 CPU 密集度较低的任务,串行计算比并行计算快。因此,了解何时应该使用多进程非常重要——这取决于你正在执行的任务。
为了让你相信这一点,让我们看一个简单的例子:
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
# first way, using multiprocessing
start_time = time.perf_counter()
with Pool() as pool:
result = pool.map(cube, range(10,N))
finish_time = time.perf_counter()
print("Program finished in {} seconds - using multiprocessing".format(finish_time-start_time))
print("---")
# second way, serial computation
start_time = time.perf_counter()
result = []
for x in range(10,N):
result.append(cube(x))
finish_time = time.perf_counter()
print("Program finished in {} seconds".format(finish_time-start_time))此代码段基于前面的示例。我们正在解决同样的问题,即计算N个数的平方根,但有两种方法。第一个涉及 Python 进程的使用,而第二个不涉及。我们使用time库中的perf_counter()方法来测量时间性能。
在我的电脑上,我得到了这个结果:
> python code.py Program finished in 1.6385094 seconds - using multiprocessing --- Program finished in 2.7373942999999996 seconds
如你所见,相差不止一秒。所以在这种情况下,多进程更好。
让我们更改代码中的某些内容,例如N的值。 让我们把它降低到N=10000,看看会发生什么。
这就是我现在得到的:
> python code.py Program finished in 0.3756742 seconds - using multiprocessing --- Program finished in 0.005098400000000003 seconds
发生了什么?现在看来,多进程是一个糟糕的选择。为什么?
与解决的任务相比,在进程之间拆分计算所带来的开销太大了。你可以看到在时间性能方面有多大差异。
Atas ialah kandungan terperinci Bagaimana untuk menggunakan pelbagai proses Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



