


Transformer ialah seni bina seq2seq yang paling berkuasa pada masa ini. Transformer terlatih biasanya mempunyai tetingkap konteks 512 (cth. BERT) atau 1024 (cth. BART), yang cukup panjang untuk kebanyakan set data ringkasan teks semasa (XSum, CNN/DM).
Tetapi 16384 bukanlah had atas panjang konteks yang diperlukan untuk menjana: tugasan yang melibatkan naratif panjang seperti ringkasan buku (Krys-´cinski et al., 2021) atau soalan naratif menjawab (Kociskýet al. ., 2018), biasanya memasukkan lebih daripada 100,000 token. Set cabaran yang dijana daripada artikel Wikipedia (Liu* et al., 2018) mengandungi input lebih daripada 500,000 token. Tugas domain terbuka dalam menjawab soalan generatif boleh mensintesis maklumat daripada input yang lebih besar, seperti menjawab soalan tentang sifat agregat artikel oleh semua pengarang hidup di Wikipedia. Rajah 1 memplotkan saiz beberapa set data ringkasan dan Soal Jawab yang popular terhadap panjang tetingkap konteks biasa, input terpanjang adalah lebih daripada 34 kali lebih panjang daripada tetingkap konteks Longformer.
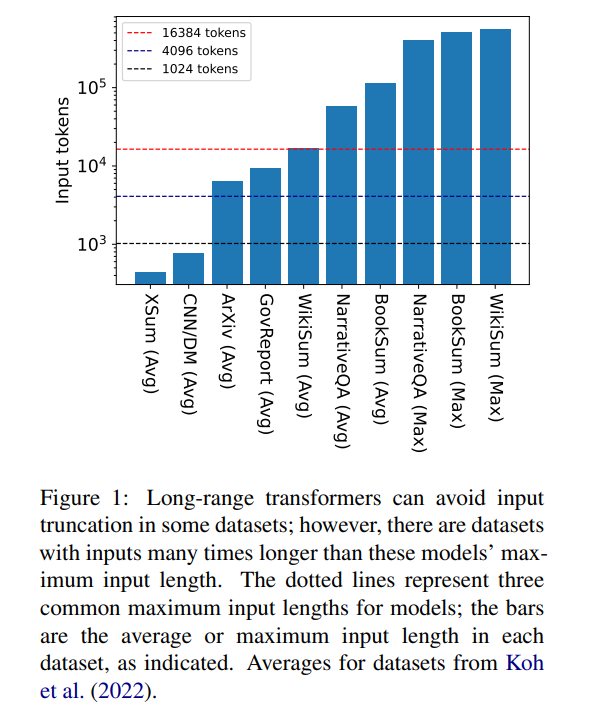
Dalam kes input yang sangat panjang ini, pengubah vanila tidak boleh berskala kerana mekanisme perhatian asli mempunyai kerumitan magnitud kuadratik . Transformer input panjang, walaupun lebih cekap daripada transformer standard, masih memerlukan sumber pengiraan yang ketara yang meningkat apabila saiz tetingkap konteks meningkat. Tambahan pula, meningkatkan tetingkap konteks memerlukan latihan semula model dari awal dengan saiz tetingkap konteks baharu, yang mahal dari segi pengiraan dan alam sekitar.
Dalam artikel "Unlimiformer: Transformer Jarak Jauh dengan Input Panjang Tanpa Had", penyelidik dari Carnegie Mellon University memperkenalkan Unlimiformer. Ini ialah pendekatan berasaskan perolehan yang menambah model bahasa pra-latihan untuk menerima input panjang tak terhingga pada masa ujian.

Pautan kertas: https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer boleh disuntik ke dalam mana-mana pengubah pengekod-penyahkod sedia ada dan boleh mengendalikan input dengan panjang tanpa had. Memandangkan urutan input yang panjang, Unlimiformer boleh membina stor data pada keadaan tersembunyi semua token input. Mekanisme rentas perhatian standard penyahkod kemudiannya dapat menanyakan stor data dan memfokus pada token input k teratas. Stor data boleh disimpan dalam memori GPU atau CPU dan boleh disoal secara sub-linear.
Unlimiformer boleh digunakan terus kepada model terlatih dan boleh menambah baik pusat pemeriksaan sedia ada tanpa sebarang latihan lanjut. Prestasi Unlimiformer akan dipertingkatkan lagi selepas penalaan halus. Makalah ini menunjukkan bahawa Unlimiformer boleh digunakan pada berbilang model asas, seperti BART (Lewis et al., 2020a) atau PRIMERA (Xiao et al., 2022), tanpa menambah pemberat dan latihan semula. Dalam pelbagai set data seq2seq jarak jauh, Unlimiformer bukan sahaja lebih kuat daripada Transformer jarak jauh seperti Longformer (Beltagy et al., 2020b), SLED (Ivgi et al., 2022) dan Transformer Memorizing (Wu et al., 2021). ) pada set data ini Prestasinya lebih baik, dan artikel ini juga mendapati Unlimiform boleh digunakan di atas model pengekod Longformer untuk membuat penambahbaikan selanjutnya.
Memandangkan saiz tetingkap konteks pengekod ditetapkan, panjang input maksimum Transformer adalah terhad. Walau bagaimanapun, semasa penyahkodan, maklumat yang berbeza mungkin relevan tambahan pula, ketua perhatian yang berbeza mungkin menumpukan pada jenis maklumat yang berbeza (Clark et al., 2019). Oleh itu, tetingkap konteks tetap mungkin membazirkan usaha pada token yang perhatiannya kurang tertumpu.
Pada setiap langkah penyahkodan, setiap kepala perhatian dalam Unlimiformer memilih tetingkap konteks yang berasingan daripada keseluruhan input. Ini dicapai dengan menyuntik carian Unlimiformer ke dalam penyahkod: sebelum memasuki modul perhatian silang, model melakukan carian jiran terdekat (kNN) dalam stor data luaran, memilih set setiap kepala perhatian dalam setiap lapisan penyahkod. token untuk mengambil bahagian.
Pengekodan
Untuk mengekod jujukan input lebih panjang daripada panjang tetingkap konteks model, kertas ini mengekodkan blok bertindih input mengikut kaedah Ivgi et al (2022) (Ivgi et al., 2022) , hanya Separuh tengah output untuk setiap bahagian dikekalkan untuk memastikan konteks yang mencukupi sebelum dan selepas proses pengekodan. Akhir sekali, artikel ini menggunakan perpustakaan seperti Faiss (Johnson et al., 2019) untuk mengindeks input yang dikodkan dalam stor data (Johnson et al., 2019).
Dapatkan semula mekanisme perhatian silang yang dipertingkatkan
Dalam mekanisme perhatian silang standard, penyahkod pengubah Fokus pada keadaan tersembunyi terakhir pengekod, pengekod biasanya memotong input dan mengekod hanya token k pertama dalam urutan input.
Artikel ini bukan sahaja menumpukan pada token k pertama input Untuk setiap kepala perhatian silang, ia mendapatkan semula keadaan tersembunyi pertama bagi siri input yang lebih panjang, dan hanya memfokus pada k token pertama ini. Ini membolehkan kata kunci diambil daripada keseluruhan jujukan input dan bukannya memotong kata kunci. Pendekatan kami juga lebih murah dari segi pengiraan dan memori GPU daripada memproses semua token input, sambil lazimnya mengekalkan lebih 99% prestasi perhatian.
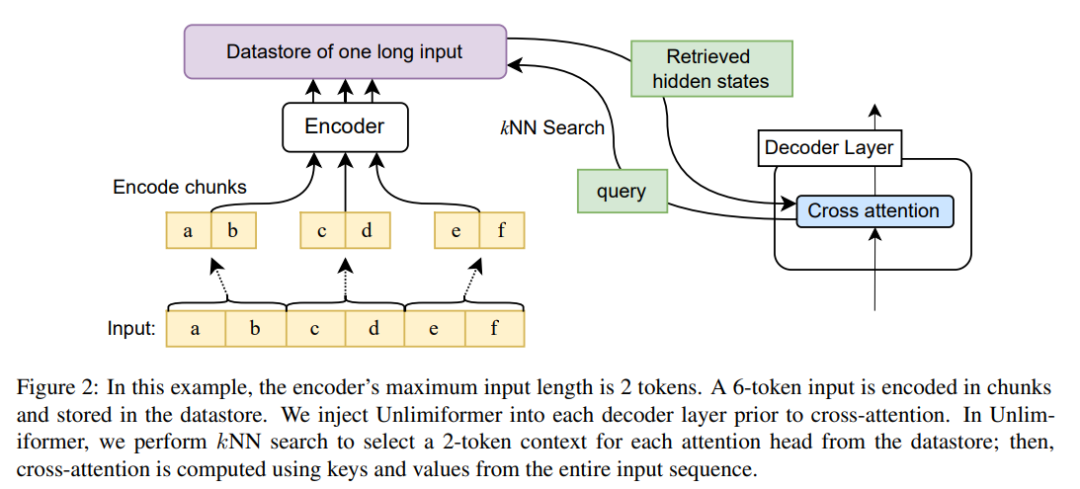
Rajah 2 menunjukkan perubahan artikel ini kepada seni bina pengubah seq2seq. Input lengkap dikodkan blok menggunakan pengekod dan disimpan dalam stor data keadaan terpendam yang dikodkan kemudiannya disoal semasa penyahkodan. Carian kNN adalah bukan parametrik dan boleh disuntik ke dalam mana-mana pengubah seq2seq yang telah dilatih, seperti yang diperincikan di bawah.
Ringkasan dokumen yang panjang
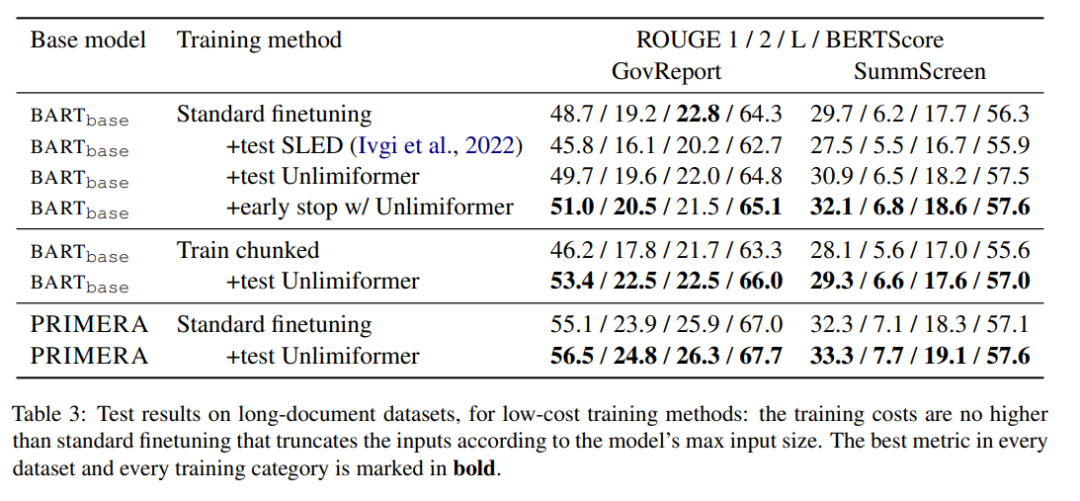
Jadual 3 menunjukkan keputusan dalam set data ringkasan teks panjang (4k dan 16k input token).
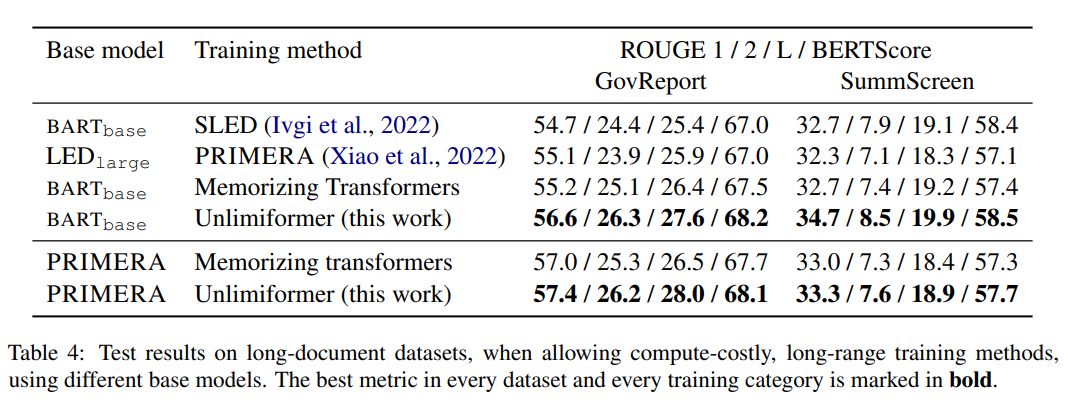
Antara kaedah latihan dalam Jadual 4, Unlimiformer boleh mencapai prestasi optimum dalam pelbagai penunjuk.
Ringkasan Buku
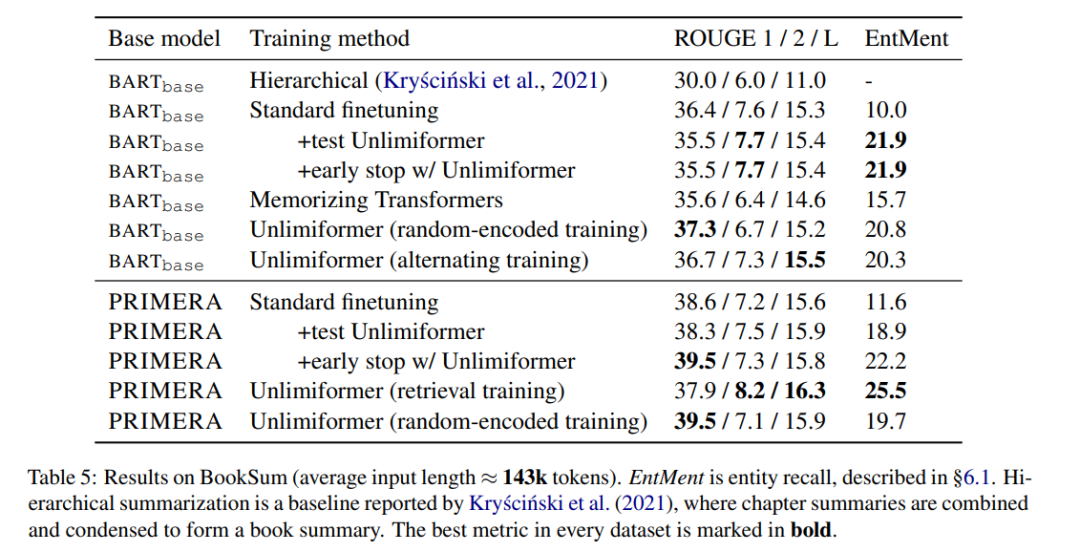
Pertunjukan Jadual 5 Keputusan pada abstrak buku. Dapat dilihat bahawa berdasarkan BARTbase dan PRIMERA, menggunakan Unlimiformer boleh mencapai hasil peningkatan tertentu.
Atas ialah kandungan terperinci Kotak input 32k GPT-4 masih tidak mencukupi? Unlimiformer memanjangkan panjang konteks kepada panjang tak terhingga. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Cara menggunakan editor atom
Cara menggunakan editor atom
 penggunaan fungsi sampel semula
penggunaan fungsi sampel semula
 Cara menggunakan fungsi pilih
Cara menggunakan fungsi pilih
 Bagaimana untuk membuat wifi maya dalam win7
Bagaimana untuk membuat wifi maya dalam win7
 Bagaimana untuk menyelesaikan masalah bahawa pengurus peranti tidak boleh dibuka
Bagaimana untuk menyelesaikan masalah bahawa pengurus peranti tidak boleh dibuka
 Bagaimana untuk menggunakan fungsi panjang dalam Matlab
Bagaimana untuk menggunakan fungsi panjang dalam Matlab
 Apakah maksud kadar bingkai?
Apakah maksud kadar bingkai?
 Perbezaan antara kabel konsol dan kabel rangkaian
Perbezaan antara kabel konsol dan kabel rangkaian








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



