


Baru-baru ini, Huawei Lianhe Port Chinese menerbitkan kertas kerja "Progressive-Hint Prompting Improves Reasoning in Large Language Models", mencadangkan Progressive-Hint Prompting (PHP) untuk mensimulasikan proses pengambilan soalan manusia. Di bawah rangka kerja PHP, Model Bahasa Besar (LLM) boleh menggunakan jawapan penaakulan yang dijana beberapa kali sebagai petunjuk untuk penaakulan seterusnya, secara beransur-ansur semakin hampir kepada jawapan yang betul akhir. Untuk menggunakan PHP, anda hanya perlu memenuhi dua keperluan: 1) soalan boleh digabungkan dengan jawapan inferens untuk membentuk soalan baharu 2) model boleh mengendalikan soalan baharu ini dan memberikan jawapan inferens baharu.
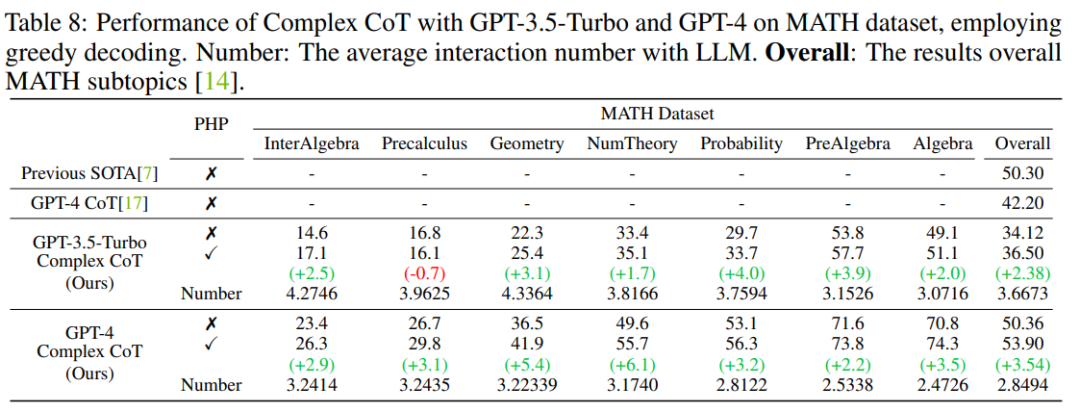
Keputusan menunjukkan bahawa GP-T-4+PHP mencapai hasil SOTA pada berbilang set data, termasuk SVAMP (91.9% ), AQuA (79.9%), GSM8K (95.5%) dan MATH (53.9%). Kaedah ini dengan ketara mengatasi prestasi GPT-4+CoT. Sebagai contoh, pada set data penaakulan matematik yang paling sukar MATH, GPT-4+CoT hanya 42.5%, manakala GPT-4+PHP bertambah baik sebanyak 6.1% pada subset Teori Nember (teori nombor) bagi set data MATH, meningkatkan MATH keseluruhan kepada 53.9%, mencapai SOTA.

Dengan pembangunan LLM, beberapa kerja mengenai dorongan telah muncul, antaranya terdapat dua arah arus perdana:
 Base Prompting harus digunakan apabila berinteraksi dengan LLM buat kali pertama ( Asas gesaan), di mana gesaan (prompt) boleh menjadi gesaan Standard, gesaan CoT atau versi yang lebih baik daripadanya. Dengan Base Prompting, anda boleh melakukan interaksi pertama dan mendapatkan jawapan awal. Dalam interaksi seterusnya, PHP harus digunakan sehingga dua jawapan terkini bersetuju.
Base Prompting harus digunakan apabila berinteraksi dengan LLM buat kali pertama ( Asas gesaan), di mana gesaan (prompt) boleh menjadi gesaan Standard, gesaan CoT atau versi yang lebih baik daripadanya. Dengan Base Prompting, anda boleh melakukan interaksi pertama dan mendapatkan jawapan awal. Dalam interaksi seterusnya, PHP harus digunakan sehingga dua jawapan terkini bersetuju.
Gesaan PHP diubah suai berdasarkan Gesaan Asas. Diberikan Base Prompt, gesaan PHP yang sepadan boleh diperolehi melalui prinsip reka bentuk gesaan PHP yang dirumuskan. Khususnya seperti yang ditunjukkan dalam rajah di bawah:
 Pengarang berharap agar PHP prompt dapat membenarkan model besar mempelajari dua mod pemetaan :
Pengarang berharap agar PHP prompt dapat membenarkan model besar mempelajari dua mod pemetaan :
1) Jika Petunjuk yang diberikan adalah jawapan yang betul, jawapan yang dikembalikan mestilah masih merupakan jawapan yang betul (khususnya seperti yang ditunjukkan dalam rajah di atas "Petunjuk ialah jawapan yang betul");
2) Jika Petunjuk yang diberikan adalah jawapan yang salah, maka LLM mesti menggunakan penaakulan untuk melompat keluar daripada Petunjuk jawapan yang salah dan mengembalikan jawapan yang betul (khususnya seperti yang ditunjukkan dalam rajah di atas "Petunjuk ialah jawapan yang salah").
Mengikut peraturan reka bentuk gesaan PHP ini, memandangkan sebarang Prompt Asas sedia ada, pengarang boleh menetapkan Prompt PHP yang sepadan.
Pengarang menggunakan tujuh set data, termasuk AddSub, MultiArith, SingleEQ, SVAMP, GSM8K, AQuA dan MATH. Pada masa yang sama, penulis menggunakan sejumlah empat model untuk mengesahkan idea pengarang, termasuk text-davinci-002, text-davinci-003, GPT-3.5-Turbo dan GPT-4.
Hasil utama
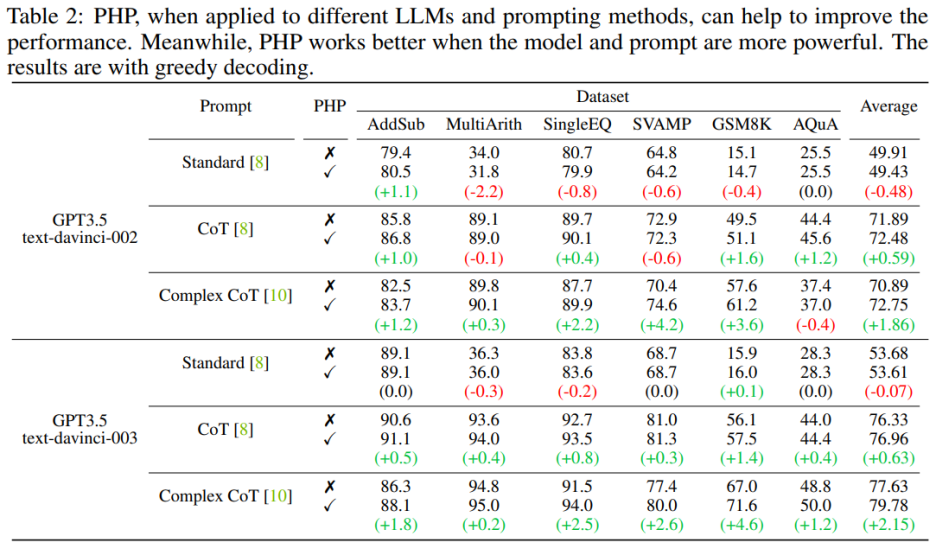
Apabila model bahasa PHP berfungsi lebih baik apabila ia lebih berkuasa dan menggesa dengan lebih berkesan. Gesaan CoT yang kompleks menunjukkan peningkatan prestasi yang ketara berbanding dengan Gesaan Standard dan Gesaan CoT. Analisis juga menunjukkan bahawa model bahasa teks-davinci-003 yang diperhalusi menggunakan pembelajaran pengukuhan berprestasi lebih baik daripada model teks-davinci-002 yang diperhalusi menggunakan arahan yang diselia, meningkatkan prestasi dokumen. Peningkatan prestasi text-davinci-003 dikaitkan dengan keupayaannya yang dipertingkat untuk memahami dan menggunakan gesaan yang diberikan dengan lebih baik. Pada masa yang sama, jika anda hanya menggunakan gesaan Standard, peningkatan yang dibawa oleh PHP tidak jelas. Jika PHP perlu berkesan, sekurang-kurangnya CoT diperlukan untuk merangsang keupayaan penaakulan model.
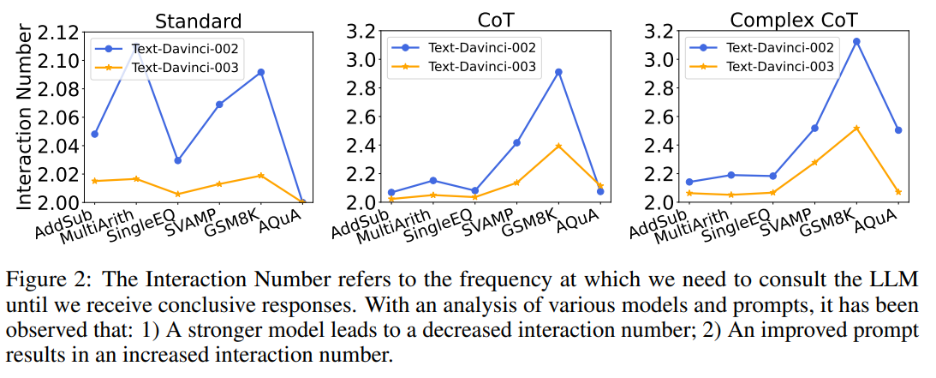
Pada masa yang sama, pengarang juga meneroka hubungan antara bilangan interaksi dan model serta gesaan. Apabila model bahasa lebih kuat dan isyarat lebih lemah, bilangan interaksi berkurangan. Bilangan interaksi merujuk kepada bilangan kali ejen berinteraksi dengan LLM. Apabila jawapan pertama diterima, bilangan interaksi ialah 1 apabila jawapan kedua diterima, bilangan interaksi meningkat kepada 2. Dalam Rajah 2, pengarang menunjukkan bilangan interaksi untuk pelbagai model dan gesaan. Hasil penyelidikan pengarang menunjukkan:
1) Memandangkan gesaan yang sama, bilangan interaksi text-davinci-003 secara amnya lebih rendah berbanding text-davinci-002. Ini disebabkan terutamanya oleh ketepatan teks-davinci-003 yang lebih tinggi, yang menghasilkan ketepatan yang lebih tinggi bagi jawapan asas dan jawapan seterusnya, justeru memerlukan kurang interaksi untuk mendapatkan jawapan yang betul akhir; >2) Apabila menggunakan model yang sama, bilangan interaksi biasanya meningkat apabila gesaan menjadi lebih berkuasa. Ini kerana apabila gesaan menjadi lebih berkesan, kebolehan penaakulan LLM digunakan dengan lebih baik, membolehkan mereka menggunakan gesaan untuk melompat ke jawapan yang salah, akhirnya mengakibatkan bilangan interaksi yang lebih tinggi diperlukan untuk mencapai jawapan akhir, yang meningkatkan bilangan interaksi.
Petunjuk Kesan Kualiti
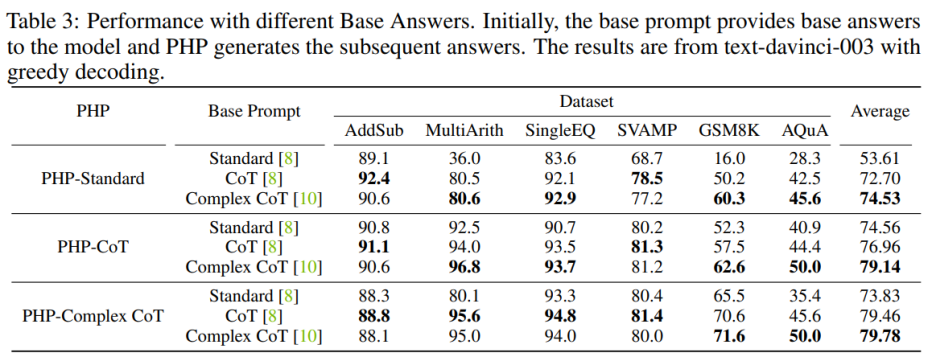 Untuk Untuk meningkatkan prestasi PHP-Standard, menggantikan Base Prompt Standard dengan Complex CoT atau CoT boleh meningkatkan prestasi akhir dengan ketara. Untuk PHP-Standard, penulis memerhatikan bahawa prestasi GSM8K meningkat daripada 16.0% di bawah Standard Prompt Base kepada 50.2% di bawah Base Prompt CoT kepada 60.3% di bawah Base Prompt Complex CoT. Sebaliknya, jika anda menggantikan Base Prompt Complex CoT dengan Standard, anda akan mendapat prestasi yang lebih rendah. Contohnya, selepas menggantikan kompleks CoT gesaan asas dengan Standard, prestasi PHP-Complex CoT menurun daripada 71.6% kepada 65.5% pada set data GSM8K.
Untuk Untuk meningkatkan prestasi PHP-Standard, menggantikan Base Prompt Standard dengan Complex CoT atau CoT boleh meningkatkan prestasi akhir dengan ketara. Untuk PHP-Standard, penulis memerhatikan bahawa prestasi GSM8K meningkat daripada 16.0% di bawah Standard Prompt Base kepada 50.2% di bawah Base Prompt CoT kepada 60.3% di bawah Base Prompt Complex CoT. Sebaliknya, jika anda menggantikan Base Prompt Complex CoT dengan Standard, anda akan mendapat prestasi yang lebih rendah. Contohnya, selepas menggantikan kompleks CoT gesaan asas dengan Standard, prestasi PHP-Complex CoT menurun daripada 71.6% kepada 65.5% pada set data GSM8K.
Jika PHP tidak direka bentuk berdasarkan Prompt Asas yang sepadan, kesannya boleh dipertingkatkan lagi. PHP-CoT menggunakan Base Prompt Complex CoT berprestasi lebih baik daripada PHP-CoT menggunakan CoT dalam empat daripada enam set data. Begitu juga, PHP-Complex CoT menggunakan Base Prompt CoT berprestasi lebih baik daripada PHP-Complex CoT menggunakan Base Prompt Complex CoT dalam empat daripada enam set data. Penulis membuat spekulasi bahawa ini adalah kerana dua sebab: 1) pada kesemua enam set data, prestasi CoT dan Complex CoT adalah serupa 2) kerana Jawapan Asas disediakan oleh CoT (atau Complex CoT), dan jawapan seterusnya adalah berdasarkan PHP-Complex CoT (atau PHP-CoT), yang setara dengan dua orang yang bekerja bersama untuk menyelesaikan masalah. Oleh itu, dalam kes ini, prestasi sistem boleh dipertingkatkan lagi.
Eksperimen Ablasi
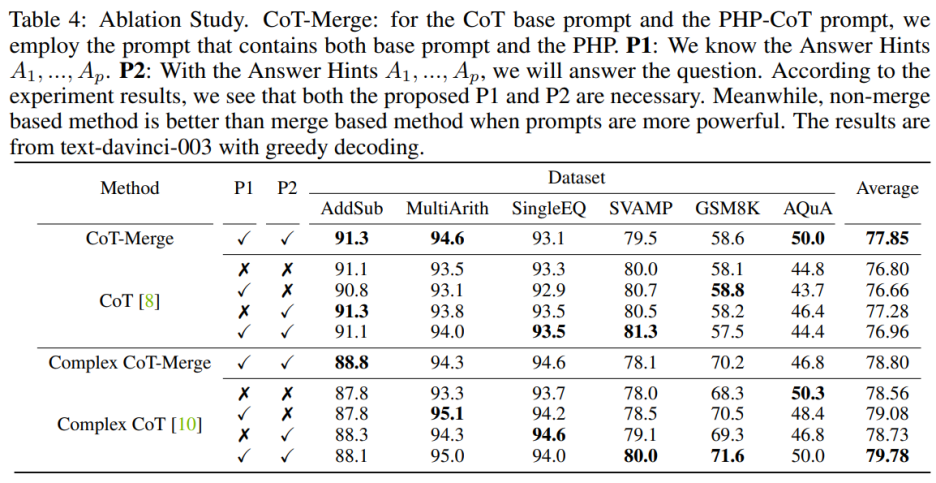
Menggabungkan ayat P1 dan P2 ke dalam model boleh meningkatkan prestasi CoT pada tiga set data, tetapi apabila menggunakan kaedah Complex CoT, ini dua Kepentingan ayat ini amat jelas. Selepas menambah P1 dan P2, prestasi kaedah dipertingkatkan dalam lima daripada enam set data. Sebagai contoh, prestasi Complex CoT bertambah baik daripada 78.0% kepada 80.0% pada set data SVAMP dan daripada 68.3% kepada 71.6% pada set data GSM8K. Ini menunjukkan, terutamanya apabila keupayaan logik model lebih kuat, kesan ayat P1 dan P2 adalah lebih ketara.
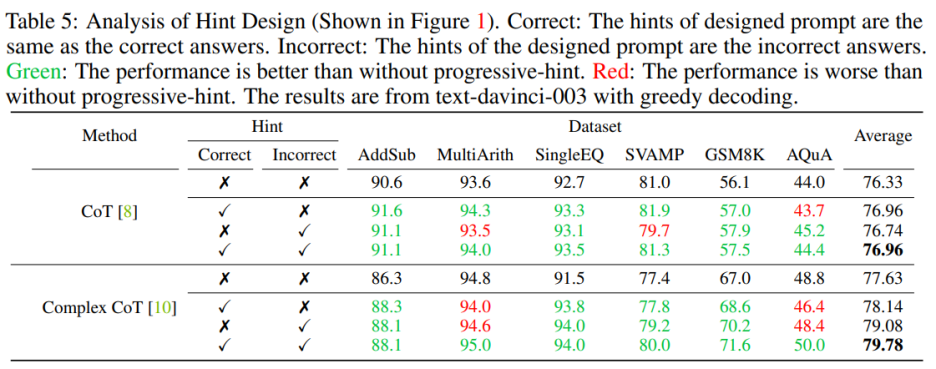
Anda perlu memasukkan kedua-dua gesaan yang betul dan salah semasa mereka bentuknya. Apabila mereka bentuk pembayang yang mengandungi pembayang yang betul dan salah, menggunakan PHP adalah lebih baik daripada tidak menggunakan PHP. Khususnya, memberikan pembayang yang betul dalam gesaan memudahkan penjanaan jawapan yang konsisten dengan pembayang yang diberikan. Sebaliknya, memberikan petunjuk palsu dalam gesaan menggalakkan penjanaan jawapan alternatif dengan gesaan yang diberikan
PHP+Konsistensi Diri
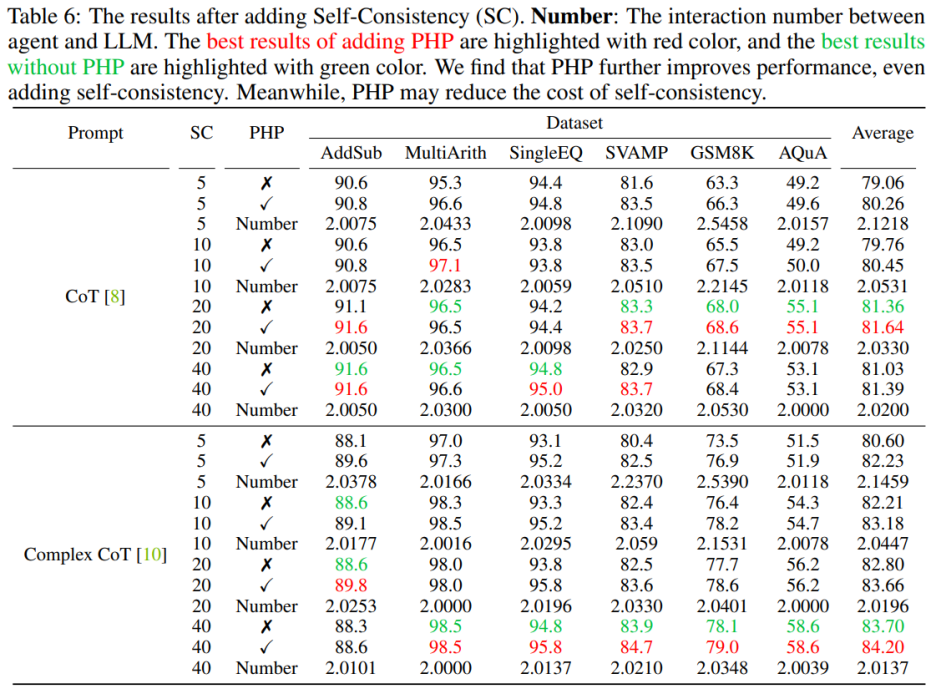
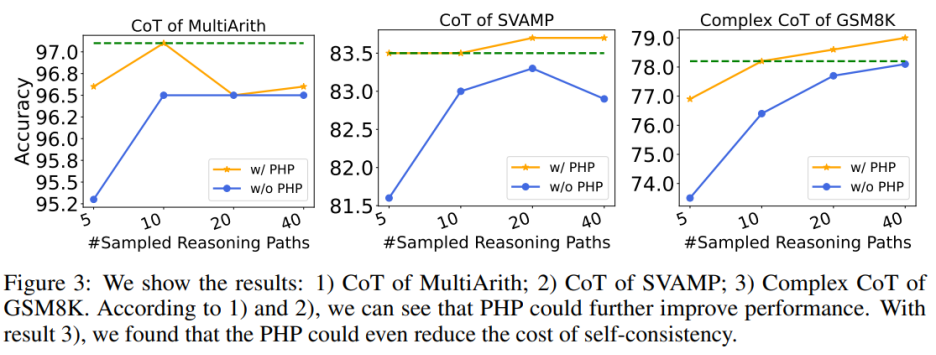
Menggunakan PHP boleh meningkatkan lagi prestasi. Dengan menggunakan petunjuk dan bilangan laluan sampel yang serupa, penulis mendapati bahawa dalam Jadual 6 dan Rajah 3, PHP-CoT dan PHP-Complex CoT yang dicadangkan oleh penulis sentiasa menunjukkan prestasi yang lebih baik daripada CoT dan Complex CoT. Contohnya, CoT+SC mampu mencapai ketepatan 96.5% pada dataset MultiArith dengan laluan sampel 10, 20 dan 40. Oleh itu, boleh disimpulkan bahawa prestasi terbaik CoT+SC ialah 96.5% menggunakan text-davinci-003. Walau bagaimanapun, selepas melaksanakan PHP, prestasi meningkat kepada 97.1%. Begitu juga, pengarang juga memerhatikan bahawa pada set data SVAMP, ketepatan terbaik CoT+SC ialah 83.3%, yang bertambah baik kepada 83.7% selepas melaksanakan PHP. Ini menunjukkan bahawa PHP boleh memecahkan kesesakan prestasi dan meningkatkan lagi prestasi.
Menggunakan PHP boleh mengurangkan kos SC Seperti yang kita sedia maklum, SC melibatkan lebih banyak laluan penaakulan, mengakibatkan kos yang lebih tinggi. Jadual 6 menggambarkan bahawa PHP boleh menjadi cara yang berkesan untuk mengurangkan kos sambil mengekalkan peningkatan prestasi. Seperti yang ditunjukkan dalam Rajah 3, menggunakan SC+Complex CoT, 40 laluan sampel boleh digunakan untuk mencapai ketepatan 78.1%, sambil menambah PHP mengurangkan laluan inferens purata yang diperlukan kepada 10×2.1531=21.531 laluan, dan hasilnya lebih baik dan lebih banyak. tepat Kadar mencapai 78.2%.
GPT-3.5-Turbo dan GPT-4
Pengarang mengikuti tetapan kerja sebelumnya dan menggunakan model penjanaan teks Menjalankan eksperimen. Dengan keluaran API GPT-3.5-Turbo dan GPT-4, pengarang mengesahkan prestasi Complex CoT dengan PHP pada enam set data yang sama. Penulis menggunakan penyahkodan tamak (iaitu suhu = 0) dan CoT Kompleks sebagai petunjuk untuk kedua-dua model.
Seperti yang ditunjukkan dalam Jadual 7, PHP yang dicadangkan meningkatkan prestasi sebanyak 2.3% pada GSM8K dan 3.2% pada AQuA. Walau bagaimanapun, GPT-3.5-Turbo menunjukkan pengurangan keupayaan untuk mematuhi isyarat berbanding teks-davinci-003. Pengarang memberikan dua contoh untuk menggambarkan perkara ini: a) Dalam kes petunjuk yang hilang, GPT-3.5-Turbo tidak dapat menjawab soalan dan menjawab sesuatu seperti "Saya tidak dapat menjawab soalan ini kerana pembayang jawapan tiada. Sila berikan pembayang jawapan untuk Meneruskan" kenyataan. Sebaliknya, text-davinci-003 secara autonomi menjana dan mengisi petunjuk jawapan yang hilang sebelum menjawab soalan b) apabila lebih daripada sepuluh petunjuk disediakan, GPT-3.5-Turbo boleh membalas "Disebabkan beberapa jawapan diberikan Petunjuk, saya tidak pasti jawapan yang betul Sila berikan pembayang jawapan untuk soalan. Selepas menggunakan model GPT-4, pengarang dapat mencapai prestasi SOTA baharu pada penanda aras SVAMP, GSM8K, AQuA dan MATH. Kaedah PHP yang dicadangkan oleh penulis secara berterusan meningkatkan prestasi GPT-4. Tambahan pula, pengarang mendapati bahawa GPT-4 memerlukan interaksi yang lebih sedikit berbanding model GPT-3.5-Turbo, selaras dengan penemuan bahawa bilangan interaksi berkurangan apabila model itu lebih berkuasa. Artikel ini memperkenalkan kaedah baharu untuk PHP berinteraksi dengan LLM, yang mempunyai pelbagai kelebihan: 1) PHP mencapai peningkatan prestasi yang ketara pada tugasan penaakulan matematik , menerajui hasil terkini pada pelbagai penanda aras inferens 2) PHP boleh memanfaatkan LLM dengan lebih baik menggunakan model dan petunjuk yang lebih berkuasa 3) PHP boleh digabungkan dengan mudah dengan CoT dan SC untuk meningkatkan lagi prestasi. Untuk meningkatkan kaedah PHP dengan lebih baik, penyelidikan masa depan boleh menumpukan pada penambahbaikan reka bentuk gesaan manual dalam peringkat soalan dan ayat gesaan dalam bahagian jawapan. Tambahan pula, selain menganggap jawapan sebagai pembayang, pembayang baharu boleh dikenal pasti dan diekstrak yang membantu LLM mempertimbangkan semula masalah tersebut. Ringkasan
Atas ialah kandungan terperinci GPT-4 memenangi SOTA baharu bagi set data penaakulan matematik yang paling sukar, dan Prompting baharu sangat meningkatkan keupayaan penaakulan model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



