


Konsep pembelajaran mendalam berasal daripada penyelidikan rangkaian saraf tiruan Perceptron berbilang lapisan yang mengandungi berbilang lapisan tersembunyi ialah struktur pembelajaran mendalam. Pembelajaran mendalam menggabungkan ciri peringkat rendah untuk membentuk perwakilan peringkat tinggi yang lebih abstrak untuk mewakili kategori atau ciri data. Ia dapat menemui perwakilan ciri teragih bagi data. Pembelajaran mendalam ialah sejenis pembelajaran mesin, dan pembelajaran mesin ialah satu-satunya cara untuk mencapai kecerdasan buatan.
Jadi, apakah perbezaan antara pelbagai seni bina sistem pembelajaran mendalam?
Rangkaian Terhubung Sepenuhnya (FCN) terdiri daripada satu siri lapisan bersambung sepenuhnya, dengan setiap neuron dalam setiap lapisan disambungkan ke lapisan lain setiap neuron dalam . Kelebihan utamanya ialah ia adalah "struktur agnostik", iaitu tiada andaian khas tentang input diperlukan. Walaupun struktur agnostik ini menjadikan rangkaian bersambung sepenuhnya boleh digunakan secara meluas, rangkaian sedemikian cenderung untuk berprestasi lebih lemah daripada rangkaian khusus yang ditala secara khusus kepada struktur ruang masalah.
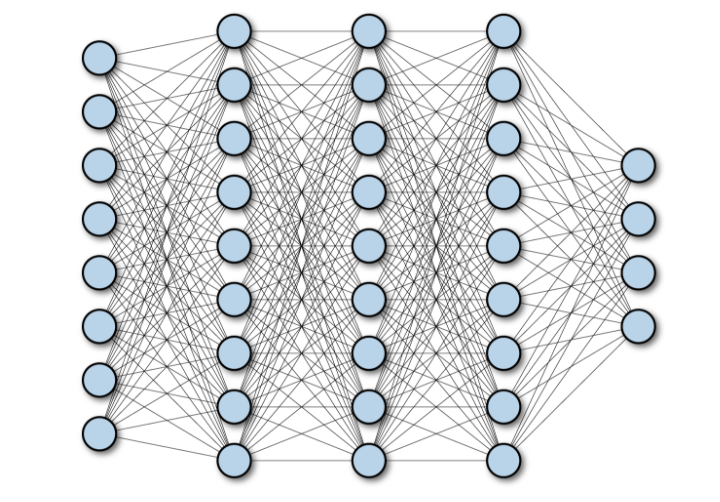
Rajah berikut menunjukkan rangkaian bersambung penuh kedalaman berbilang lapisan:
Convolutional Neural Network (CNN) ialah seni bina rangkaian saraf berbilang lapisan yang digunakan terutamanya dalam aplikasi pemprosesan imej. Seni bina CNN secara eksplisit menganggap bahawa input mempunyai dimensi spatial (dan secara pilihan dimensi kedalaman), seperti imej, yang membenarkan sifat tertentu dikodkan ke dalam seni bina model. Yann LeCun mencipta CNN pertama, seni bina yang pada asalnya digunakan untuk mengenali aksara tulisan tangan.
Pecahkan butiran teknikal model penglihatan komputer menggunakan CNN:
Imej diwakili di sini sebagai grid piksel, iaitu grid integer positif, dengan setiap nombor diberi warna.
Rangkaian neural convolutional ringkas terdiri daripada satu siri lapisan, setiap lapisan mengubah volum pengaktifan kepada perwakilan lain melalui fungsi yang boleh dibezakan. Seni bina rangkaian saraf konvolusi menggunakan tiga jenis lapisan: lapisan konvolusi, lapisan gabungan dan lapisan bersambung sepenuhnya. Imej di bawah menunjukkan bahagian berlainan lapisan rangkaian saraf konvolusi:
Gabungan ketiga-tiga operasi ini membentuk rangkaian konvolusi sepenuhnya.
CNN (Convolutional Neural Network) ialah sejenis rangkaian saraf yang biasa digunakan untuk menyelesaikan masalah yang berkaitan dengan data spatial, biasanya untuk imej (2D CNN) dan audio ( 1D CNN) dan bidang lain. Pelbagai aplikasi CNN termasuk pengecaman muka, analisis perubatan dan klasifikasi, dsb. Melalui CNN, ciri yang lebih terperinci boleh ditangkap dalam imej atau data audio, dengan itu mencapai pengiktirafan dan analisis yang lebih tepat. Selain itu, CNN juga boleh digunakan untuk bidang lain, seperti pemprosesan bahasa semula jadi dan data siri masa. Ringkasnya, CNN boleh membantu kami memahami dan menganalisis pelbagai jenis data dengan lebih baik.
Kebolehlaksanaan perkongsian parameter/pengiraan:
Memandangkan CNN menggunakan perkongsian parameter, bilangan pemberat dalam seni bina CNN dan FCN biasanya berbeza mengikut beberapa pesanan magnitud.
Untuk rangkaian neural yang bersambung sepenuhnya, terdapat input dengan bentuk (Hin×Win×Cin) dan output dengan bentuk (Hout×Wout×Cout). Ini bermakna setiap warna piksel ciri output disambungkan kepada setiap warna piksel ciri input. Bagi setiap piksel imej input dan output, terdapat parameter boleh dipelajari bebas. Oleh itu, bilangan parameter ialah (Hin×Hout×Win×Wout×Cin×Cout).
Dalam lapisan konvolusi, input ialah imej bentuk (Hin, Win, Cin), dan pemberat menganggap saiz kejiranan piksel yang diberikan sebagai K×K. Output ialah jumlah wajaran bagi piksel tertentu dan jirannya. Terdapat kernel yang berasingan untuk setiap pasangan (Cin, Cout) saluran input dan output, tetapi berat kernel adalah tensor bentuk bebas kedudukan (K, K, Cin, Cout). Malah, lapisan ini boleh menerima imej sebarang resolusi, manakala lapisan yang disambungkan sepenuhnya hanya boleh menggunakan resolusi tetap. Akhir sekali, parameter lapisan ialah (K, K, Cin, Cout Untuk kes di mana saiz kernel K jauh lebih kecil daripada resolusi input, bilangan pembolehubah akan dikurangkan dengan ketara.
Sejak AlexNet memenangi pertandingan ImageNet, hakikat bahawa setiap rangkaian neural yang menang telah menggunakan komponen CNN membuktikan bahawa CNN lebih berkesan untuk data imej. Kemungkinan besar anda tidak akan menemui sebarang perbandingan yang bermakna kerana tidak boleh menggunakan hanya lapisan FC untuk memproses data imej, manakala CNN boleh mengendalikan data ini. kenapa?
Bilangan pemberat dengan 1000 neuron dalam lapisan FC adalah lebih kurang 150 juta untuk imej. Ini hanyalah bilangan pemberat untuk satu lapisan. Seni bina CNN moden mempunyai 50-100 lapisan dengan jumlah ratusan ribu parameter (contohnya, ResNet50 mempunyai 23M parameter, Inception V3 mempunyai 21M parameter).
Dari sudut pandangan matematik, membandingkan bilangan pemberat antara CNN dan FCN (dengan 100 unit tersembunyi), jika imej input ialah 500×500×3:
<code>((shape of width of the filter * shape of height of the filter * number of filters in the previous layer+1)*number of filters)( +1 是为了偏置) = (Fw×Fh×D+1)×F=(5×5×3+1)∗2=152</code>
Invarian terjemahan
Invarian merujuk kepada Objek masih boleh dikenal pasti dengan betul walaupun kedudukannya berubah. Ini biasanya merupakan ciri positif kerana ia mengekalkan identiti (atau kategori) objek. "Terjemahan" di sini mempunyai makna khusus dalam geometri. Imej di bawah menunjukkan objek yang sama di lokasi yang berbeza dan disebabkan invarian terjemahan, CNN dapat mengenal pasti dengan betul bahawa kedua-duanya adalah kucing.
RNN ialah salah satu seni bina rangkaian asas di mana seni bina pembelajaran mendalam yang lain dibina. Perbezaan utama ialah tidak seperti rangkaian suapan hadapan biasa, RNN boleh mempunyai sambungan yang menghantar semula ke lapisan sebelumnya atau lapisan yang sama. Dari satu segi, RNN mempunyai "memori" pengiraan sebelumnya dan menggunakan maklumat ini untuk pemprosesan semasa.
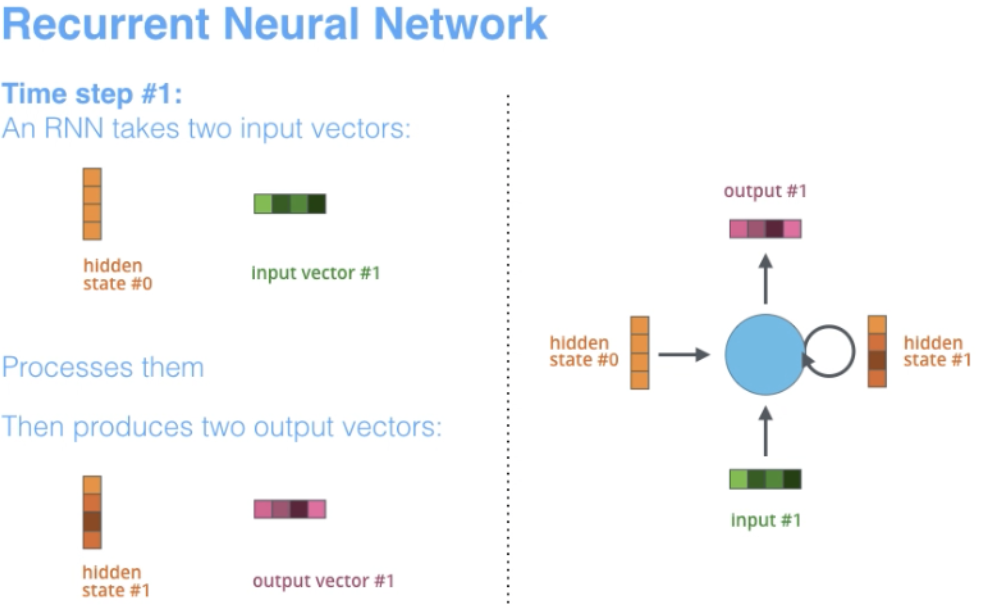
Istilah "Berulang" digunakan untuk rangkaian yang melaksanakan tugas yang sama pada setiap contoh jujukan , jadi output bergantung pada pengiraan dan keputusan sebelumnya.
RNN secara semula jadi sesuai untuk banyak tugasan NLP, seperti pemodelan bahasa. Mereka dapat menangkap perbezaan makna antara "anjing" dan "anjing panas", jadi RNN dibuat khusus untuk memodelkan pergantungan konteks seperti ini dalam bahasa dan tugas pemodelan jujukan yang serupa, yang menjadikan penggunaan RNN di kawasan ini agak daripada Sebab utama untuk CNN. Satu lagi kelebihan RNN ialah saiz model tidak meningkat dengan saiz input, jadi adalah mungkin untuk mengendalikan input dengan panjang sewenang-wenangnya.
Selain itu, tidak seperti CNN, RNN mempunyai langkah pengiraan yang fleksibel, menyediakan keupayaan pemodelan yang lebih baik dan mewujudkan kemungkinan menangkap konteks tanpa had kerana ia mengambil kira maklumat sejarah dan pemberatnya dalam Masa dikongsi. Walau bagaimanapun, rangkaian saraf berulang mengalami masalah kecerunan yang hilang. Kecerunan menjadi sangat kecil, dengan itu menjadikan berat kemas kini perambatan belakang sangat kecil. Disebabkan oleh pemprosesan berurutan yang diperlukan untuk setiap label dan kehadiran kecerunan yang hilang/meletup, latihan RNN adalah perlahan dan kadangkala sukar untuk menumpu.
Gambar di bawah dari Universiti Stanford adalah contoh seni bina RNN.
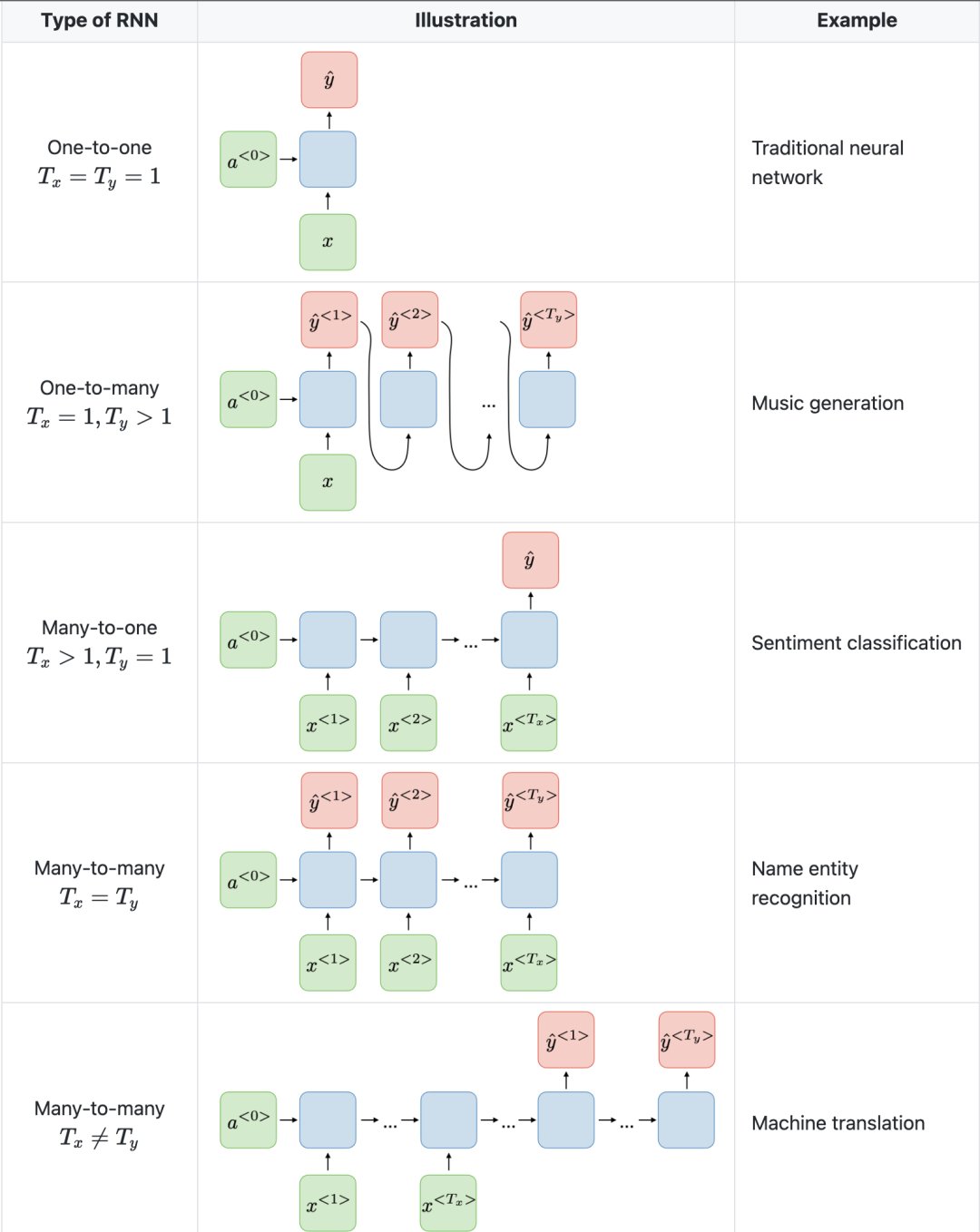
Perkara lain yang perlu diambil perhatian ialah CNN mempunyai seni bina yang berbeza daripada RNN. CNN ialah rangkaian neural suapan ke hadapan yang menggunakan penapis dan lapisan pengumpulan, manakala RNN menyuapkan semula hasil ke dalam rangkaian melalui autoregresi.
RNN ialah rangkaian saraf yang direka khusus untuk menganalisis data siri masa. Antaranya, data siri masa merujuk kepada data yang disusun mengikut urutan masa, seperti teks atau video. RNN mempunyai aplikasi yang luas dalam terjemahan teks, pemprosesan bahasa semula jadi, analisis sentimen dan analisis pertuturan. Sebagai contoh, ia boleh digunakan untuk menganalisis rakaman audio untuk mengenal pasti pertuturan penceramah dan menukarnya kepada teks. Selain itu, RNN juga boleh digunakan untuk penjanaan teks, seperti mencipta teks untuk e-mel atau siaran media sosial.
Dalam CNN, saiz input dan output ditetapkan. Ini bermakna CNN mengambil imej saiz tetap dan mengeluarkannya ke tahap yang sesuai, bersama-sama dengan keyakinan ramalannya. Walau bagaimanapun, dalam RNN, saiz input dan output mungkin berbeza-beza. Ciri ini berguna untuk aplikasi yang memerlukan input dan output bersaiz berubah-ubah, seperti menjana teks.
Kedua-dua Unit Berulang Berpagar (GRU) dan Unit Memori Jangka Pendek Panjang (LSTM) menyediakan penyelesaian kepada masalah kecerunan yang hilang yang dihadapi oleh Rangkaian Neural Berulang (RNN).
Rangkaian Neural Memori Pendek Panjang (LSTM) ialah sejenis RNN yang istimewa. Ia memudahkan RNN untuk mengekalkan maklumat dalam banyak cap masa dengan mempelajari kebergantungan jangka panjang. Rajah di bawah ialah perwakilan visual seni bina LSTM.
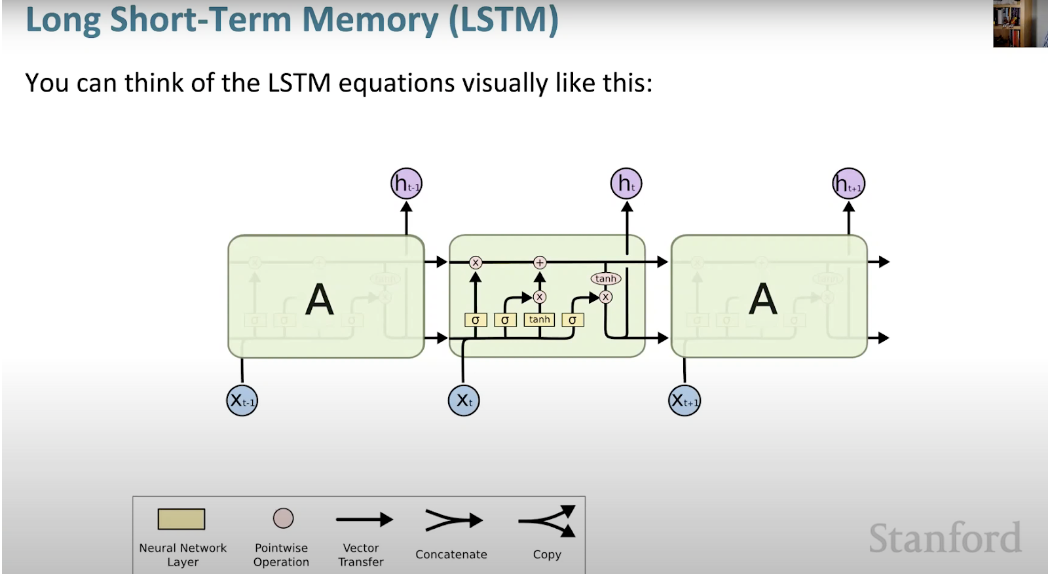
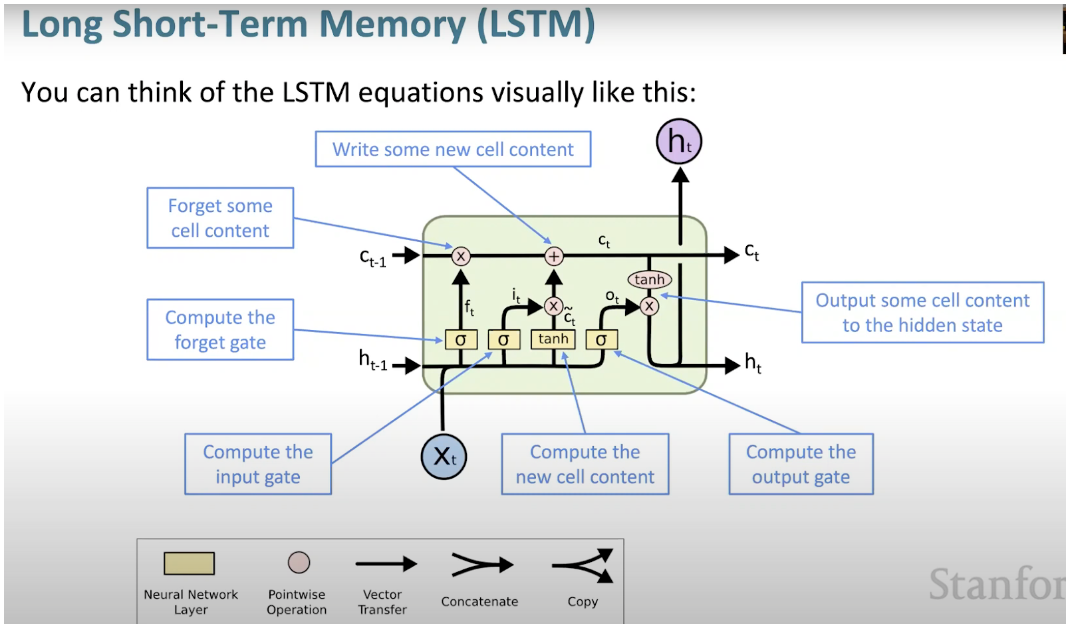
LSTM ada di mana-mana dan boleh didapati dalam banyak aplikasi atau produk, seperti sebagai telefon pintar. Kuasanya terletak pada hakikat bahawa ia bergerak dari seni bina berasaskan neuron biasa dan sebaliknya menggunakan konsep unit memori. Unit memori ini mengekalkan nilainya mengikut fungsi inputnya, dan boleh menyimpan nilainya untuk masa yang singkat atau lama. Ini membolehkan unit mengingati perkara penting, bukan hanya nilai pengiraan terakhir.
Sel memori LSTM mengandungi tiga get yang mengawal aliran maklumat masuk atau keluar dari selnya.
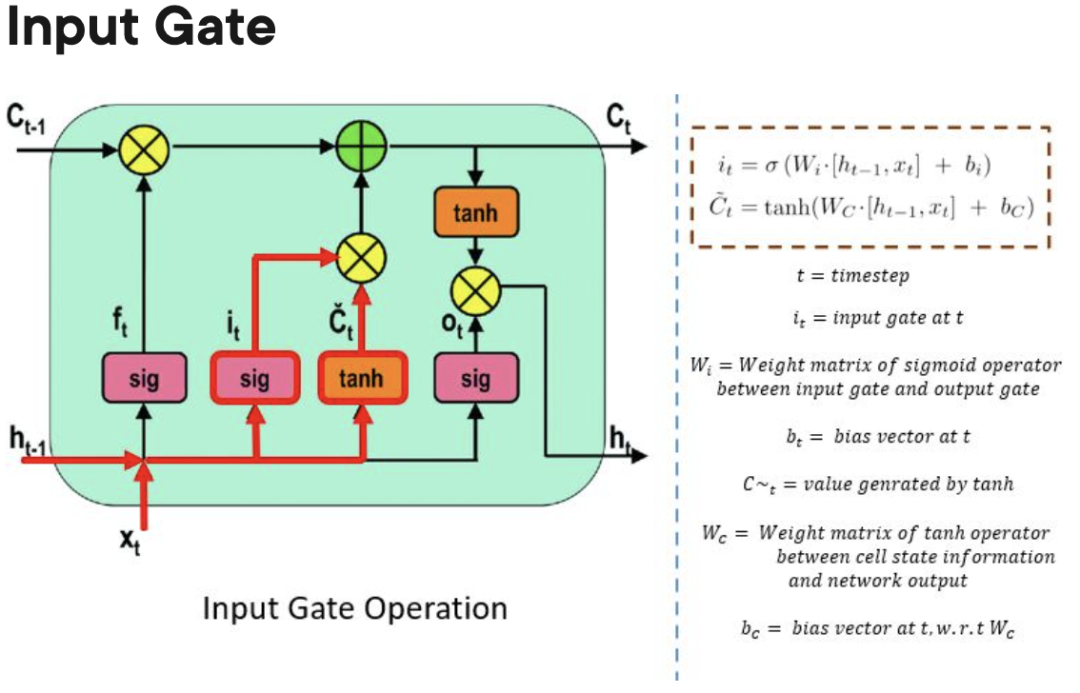
Forgetting Gate: Bertanggungjawab untuk mengesan maklumat yang boleh "dilupakan" untuk memberi ruang kepada unit pemprosesan mengingati data baharu.
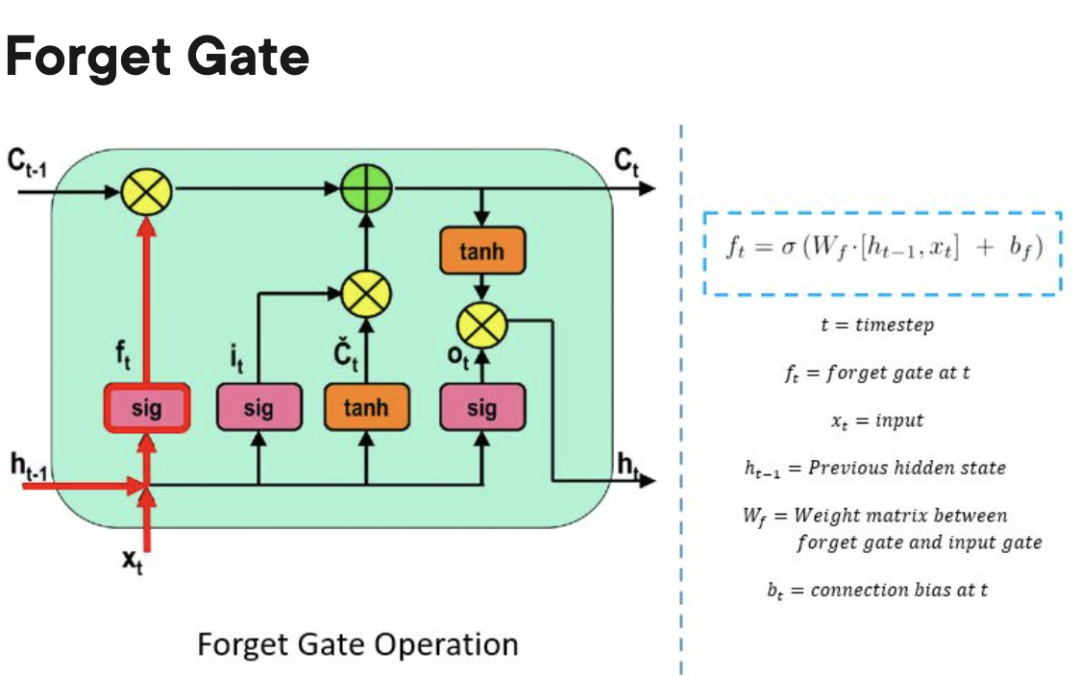
Ger Keluar: Menentukan apabila maklumat yang disimpan dalam unit pemprosesan boleh digunakan sebagai output sel.
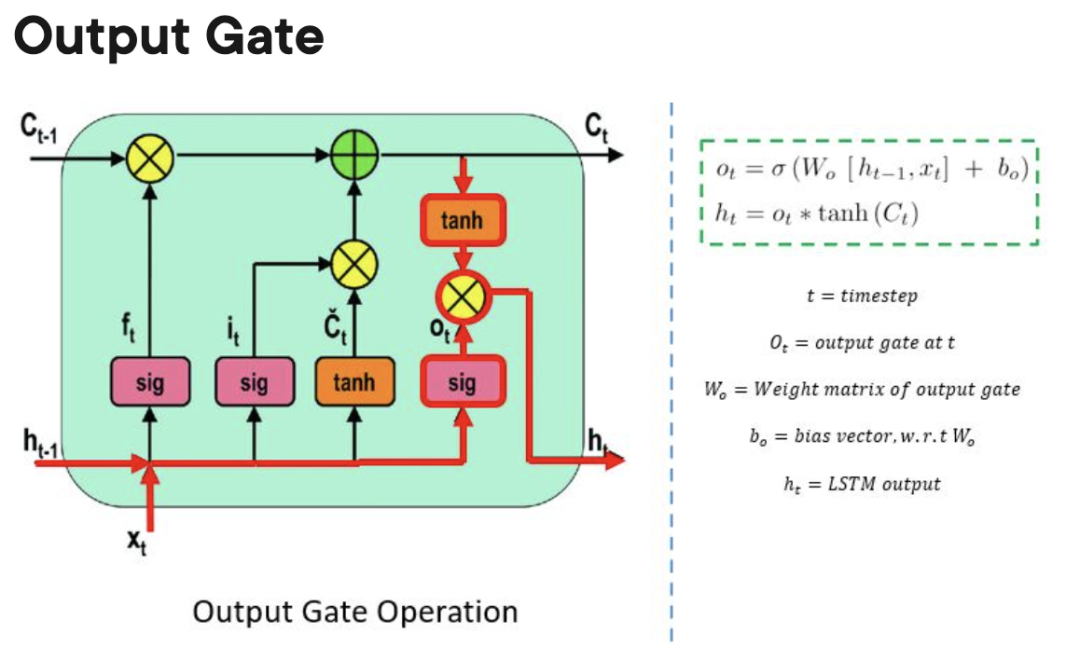
Berbanding GRU dan Terutamanya RNN, LSTM boleh mempelajari kebergantungan jangka panjang. Oleh kerana terdapat tiga get (dua dalam GRU dan sifar dalam RNN), LSTM mempunyai lebih banyak parameter berbanding RNN dan GRU. Parameter tambahan ini membolehkan model LSTM mengendalikan data jujukan kompleks dengan lebih baik, seperti bahasa semula jadi atau data siri masa. Tambahan pula, LSTM juga boleh mengendalikan urutan input panjang berubah kerana struktur get mereka membolehkan mereka mengabaikan input yang tidak perlu. Akibatnya, LSTM berprestasi baik dalam banyak aplikasi, termasuk pengecaman pertuturan, terjemahan mesin dan ramalan pasaran saham.
GRU mempunyai dua get: get kemas kini dan get set semula (pada asasnya dua vektor) untuk memutuskan maklumat yang perlu dihantar kepada output .
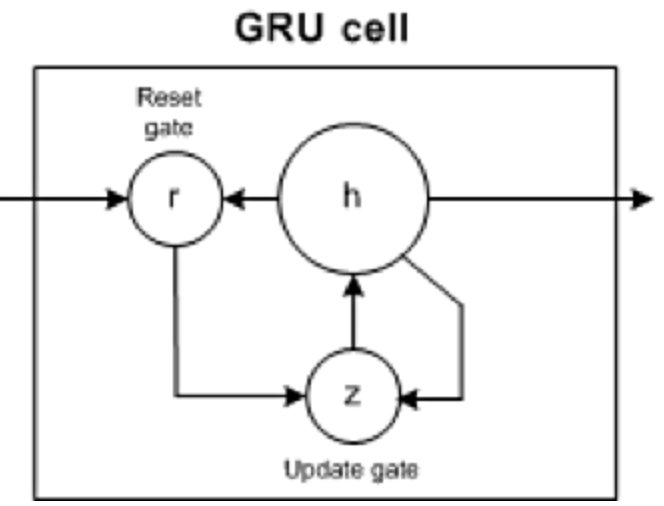
Serupa dengan RNN, GRU juga merupakan rangkaian saraf berulang yang boleh mengekalkan maklumat dengan berkesan untuk masa yang lama dan menangkap lebih lama daripada Ketergantungan RNN . Walau bagaimanapun, GRU adalah lebih mudah dan cepat untuk dilatih berbanding LSTM.
Walaupun GRU lebih kompleks dalam pelaksanaan daripada RNN, kerana ia hanya mengandungi dua mekanisme gating, ia mempunyai bilangan parameter yang lebih kecil dan secara amnya tidak dapat menangkap kebergantungan julat yang lebih panjang seperti LSTM. Oleh itu, GRU mungkin memerlukan lebih banyak data latihan dalam beberapa kes untuk mencapai tahap prestasi yang sama seperti LSTM.
Selain itu, kerana GRU agak mudah dan kos pengiraannya rendah, mungkin lebih sesuai untuk menggunakan GRU dalam persekitaran terhad sumber, seperti peranti mudah alih atau sistem terbenam. Sebaliknya, jika ketepatan model adalah penting untuk aplikasi, LSTM mungkin merupakan pilihan yang lebih baik.
Kertas mengenai Transformers "Attention is All You Need" hampir merupakan kertas nombor satu yang pernah ada di Arxiv. Transformer ialah model penyahkod pengekod besar yang mampu memproses keseluruhan jujukan menggunakan mekanisme perhatian yang kompleks.
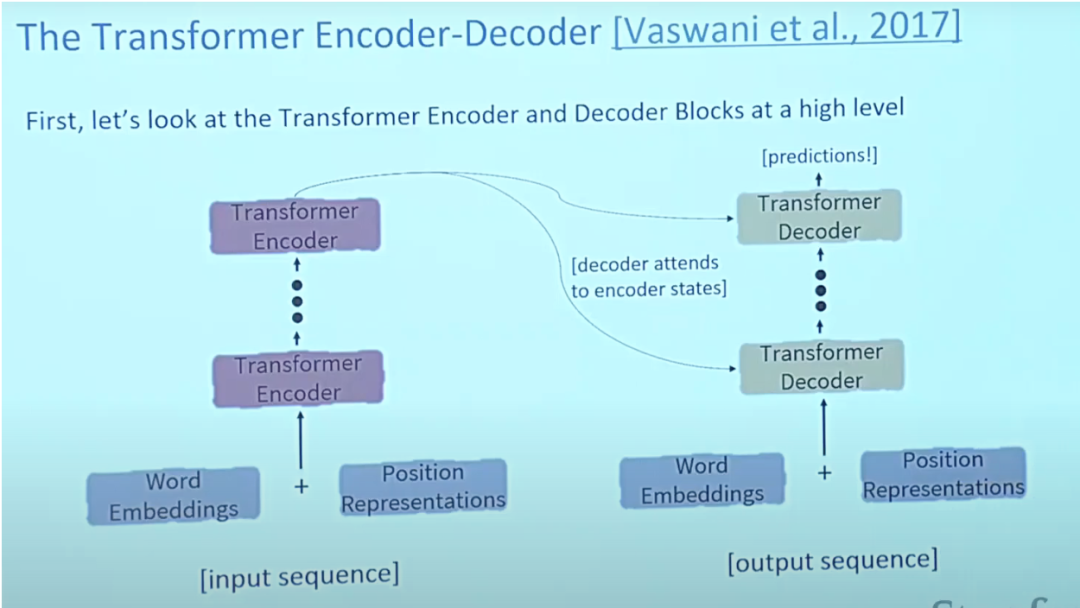
Lazimnya, dalam aplikasi pemprosesan bahasa semula jadi, setiap perkataan input terlebih dahulu ditukar kepada vektor menggunakan algoritma pembenaman. Pembenaman hanya berlaku dalam pengekod tahap terendah. Abstraksi yang dikongsi oleh semua pengekod ialah mereka menerima senarai vektor bersaiz 512, yang akan menjadi perkataan embeddings, tetapi dalam pengekod lain ia akan berada terus di bawah output pengekod.
Perhatian memberikan penyelesaian kepada masalah kesesakan. Untuk jenis model ini, vektor konteks menjadi hambatan, menjadikannya sukar untuk model mengendalikan ayat yang panjang. Perhatian membolehkan model memfokus pada bahagian yang berkaitan dalam urutan input seperti yang diperlukan dan menganggap perwakilan setiap perkataan sebagai pertanyaan untuk mengakses dan menggabungkan maklumat daripada satu set nilai.
Secara amnya, dalam seni bina Transformer, pengekod dapat menghantar semua keadaan tersembunyi kepada penyahkod. Walau bagaimanapun, penyahkod menggunakan perhatian untuk melakukan langkah tambahan sebelum menjana output. Penyahkod mendarab setiap keadaan tersembunyi dengan skor softmaxnya, sekali gus menguatkan keadaan tersembunyi skor lebih tinggi dan membanjiri keadaan tersembunyi yang lain. Ini membolehkan model memfokus pada bahagian input yang berkaitan dengan output.
Perhatian kendiri terletak dalam pengekod, langkah pertama ialah mencipta 3 vektor daripada setiap vektor input pengekod (pembenaman setiap perkataan): Vektor Kunci, Pertanyaan dan Nilai, vektor ini diperoleh dengan menukar pembenaman Dicipta dengan mendarab 3 matriks yang dilatih semasa latihan. Dimensi K, V, Q ialah 64, manakala vektor input/output pembenaman dan pengekod mempunyai dimensi 512. Gambar di bawah adalah dari Transformer Bergambar Jay Alammar, yang mungkin merupakan tafsiran visual terbaik di Internet.
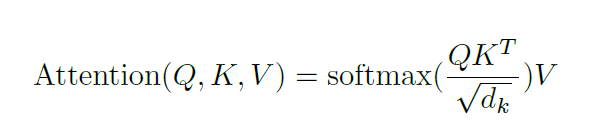
Saiz senarai ini ialah hiperparameter yang boleh ditetapkan dan pada asasnya akan menjadi panjang ayat terpanjang dalam set data latihan.
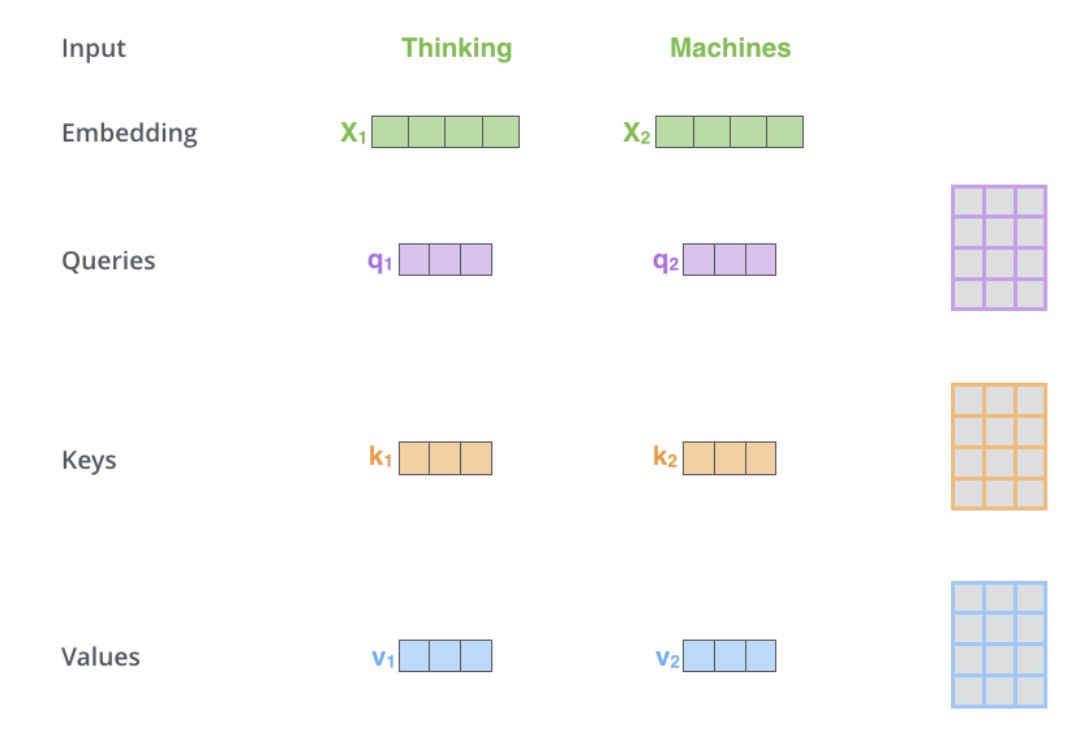
Apakah pertanyaan, kunci dan vektor nilai? Ia adalah konsep abstrak yang berguna apabila mengira dan memikirkan perhatian. Pengiraan perhatian silang dalam penyahkod adalah sama seperti pengiraan perhatian kendiri kecuali input. Perhatian silang secara asimetri menggabungkan dua jujukan benam bebas dari dimensi yang sama, manakala input perhatian kendiri ialah jujukan benam tunggal.
Untuk membincangkan Transformer, perlu juga membincangkan dua model pra-latihan iaitu BERT dan GPT kerana ia membawa kepada kejayaan Transformer.
Penyahkod pra-latihan GPT mempunyai 12 lapisan, termasuk keadaan tersembunyi 768 dimensi, lapisan tersembunyi suapan ke hadapan 3072 dimensi dan dikodkan dengan 40,000 pasangan bait bercantum. Ia digunakan terutamanya dalam penaakulan bahasa semula jadi untuk menandakan pasangan ayat sebagai entailment, percanggahan, atau neutral.
BERT ialah pengekod pra-latihan yang menggunakan pemodelan bahasa bertopeng untuk menggantikan sebahagian daripada perkataan dalam input dengan token [MASK] khas dan kemudian cuba meramalkan perkataan tersebut. Oleh itu, kerugian hanya perlu dikira pada perkataan bertopeng yang diramalkan. Kedua-dua saiz model BERT mempunyai sejumlah besar lapisan pengekod (dipanggil blok Transformer dalam kertas) - 12 dalam versi Base dan 24 dalam versi Besar. Ini juga mempunyai rangkaian suapan hadapan yang lebih besar (masing-masing 768 dan 1024 unit tersembunyi) dan lebih daripada konfigurasi lalai dalam pelaksanaan rujukan Transformer dalam kertas awal (6 lapisan pengekod, 512 unit tersembunyi dan 8 kepala perhatian) kepala perhatian (masing-masing 12 dan 16 ). Model BERT mudah diperhalusi dan biasanya boleh dilakukan pada satu GPU. BERT boleh digunakan untuk terjemahan dalam NLP, terutamanya terjemahan bahasa sumber rendah.
Satu kelemahan prestasi Transformers ialah masa pengiraan mereka dalam perhatian kendiri adalah kuadratik, manakala RNN hanya berkembang secara linear.
Dalam model bahasa tradisional, perkataan bersebelahan terlebih dahulu dikumpulkan bersama, manakala Transformer boleh disejajarkan Pemprosesan supaya setiap elemen dalam data input disambungkan kepada atau diperhatikan kepada setiap elemen lain. Ini dipanggil "perhatian diri sendiri." Ini bermakna Transformer boleh melihat kandungan keseluruhan set data sebaik sahaja ia memulakan latihan.
Sebelum kemunculan Transformer, kemajuan tugas bahasa AI agak ketinggalan daripada pembangunan bidang lain. Malah, dalam revolusi pembelajaran mendalam sejak 10 tahun yang lalu atau lebih, pemprosesan bahasa semula jadi adalah lambat, dan NLP sedikit ketinggalan di belakang penglihatan komputer. Walau bagaimanapun, dengan kemunculan Transformers, bidang NLP telah menerima rangsangan yang besar dan satu siri model telah dilancarkan yang mencapai keputusan yang baik dalam pelbagai tugas NLP.
Contohnya, untuk memahami perbezaan antara model bahasa tradisional (berdasarkan seni bina rekursif seperti RNN, LSTM atau GRU) dan Transformers, kita boleh memberi contoh: "Burung hantu mengintip seekor tupai. Ia mencuba untuk menangkapnya dengan cakarnya tetapi hanya mendapat hujung ekornya." Struktur ayat kedua mengelirukan: apakah maksud "ia" itu? Model bahasa tradisional yang hanya menumpukan pada perkataan yang mengelilingi "ia" akan mengalami kesukaran, tetapi Transformer yang menghubungkan setiap perkataan kepada setiap perkataan lain boleh memberitahu bahawa burung hantu menangkap tupai, dan tupai kehilangan sebahagian daripada ekornya.
Dalam CNN, kami bermula dari tempatan dan secara beransur-ansur memperoleh perspektif global. CNN mengecam imej piksel demi piksel dengan membina ciri dari setempat ke global untuk mengenal pasti ciri seperti bucu atau garisan. Walau bagaimanapun, dalam pengubah, melalui perhatian kendiri, sambungan antara lokasi imej jauh diwujudkan walaupun pada peringkat pertama pemprosesan maklumat (sama seperti bahasa). Jika pendekatan CNN adalah seperti penskalaan bermula dari satu piksel, maka pengubah akan secara beransur-ansur membawa keseluruhan imej kabur menjadi fokus.

CNN menjana perwakilan ciri tempatan dengan berulang kali menggunakan penapis pada tampung tempatan data input, secara beransur-ansur meningkatkan medan pandangan penerimaan mereka dan membina Ciri global perwakilan. Apl Foto boleh membezakan pear daripada awan kerana lilitan. Sebelum seni bina pengubah, CNN dianggap sangat diperlukan untuk tugas penglihatan.
Seni bina model Vision Transformer hampir sama dengan transformer pertama yang dicadangkan pada 2017, dengan hanya beberapa perubahan kecil yang membolehkannya menganalisis imej dan bukannya perkataan. Memandangkan bahasa cenderung diskret, imej input perlu didiskritkan untuk membolehkan pengubah memproses input visual. Meniru pendekatan bahasa dengan tepat dan melakukan perhatian kendiri pada setiap piksel akan menjadi sangat mahal dalam masa pengiraan. Oleh itu, ViT membahagikan imej yang lebih besar kepada sel atau tampalan segi empat sama (serupa dengan token dalam NLP). Saiznya adalah sewenang-wenangnya kerana token boleh menjadi lebih besar atau lebih kecil bergantung pada resolusi imej asal (lalai ialah 16x16 piksel). Tetapi dengan memproses piksel dalam kumpulan dan menggunakan perhatian kendiri pada setiap piksel, ViT boleh memproses set data latihan yang besar dengan cepat dan mengeluarkan klasifikasi yang semakin tepat.
Berbanding dengan Transformer, seni bina pembelajaran mendalam yang lain hanya mempunyai satu teknik, manakala pembelajaran pelbagai mod memerlukan pemprosesan mod yang berbeza dalam mod seni bina yang lancar dan mempunyai bias induksi hubungan yang tinggi untuk mencapai tahap kecerdasan manusia. Dalam erti kata lain, terdapat keperluan untuk seni bina pelbagai guna tunggal yang boleh beralih dengan lancar antara deria seperti membaca/melihat, bercakap dan mendengar.
Untuk tugasan berbilang modal, berbilang jenis data perlu diproses secara serentak, seperti imej asal, video dan bahasa, dan Transformer menyediakan potensi seni bina umum.
Ini adalah tugas yang sukar untuk dicapai kerana pendekatan diskret yang diambil dalam seni bina terdahulu di mana setiap jenis data mempunyai model khusus Tugasan. Walau bagaimanapun, Transformers menyediakan cara mudah untuk menggabungkan berbilang sumber input. Sebagai contoh, rangkaian multimodal boleh kuasa sistem yang membaca pergerakan bibir orang dan mendengar suara mereka menggunakan representasi yang kaya bagi bahasa dan maklumat imej secara serentak. Melalui perhatian silang, Transformer dapat memperoleh vektor pertanyaan, kunci dan nilai daripada sumber yang berbeza, menjadikannya alat yang berkuasa untuk pembelajaran pelbagai mod.
Oleh itu, Transformer ialah langkah besar ke arah "gabungan" seni bina rangkaian saraf, yang boleh membantu mencapai pemprosesan universal berbilang data modal.
Berbanding dengan RNN/GRU/LSTM, Transformer boleh belajar lebih lama daripada RNN dan variannya (seperti GRU dan LSTM) Ketergantungan .
Walau bagaimanapun, manfaat terbesar datang daripada cara Transformers meminjamkan diri mereka kepada penyejajaran. Tidak seperti RNN yang memproses satu perkataan pada setiap langkah masa, sifat utama Transformer ialah perkataan pada setiap kedudukan mengalir melalui pengekod melalui laluannya sendiri. Dalam lapisan perhatian diri, terdapat kebergantungan antara laluan ini kerana lapisan perhatian diri mengira kepentingan perkataan lain dalam setiap urutan input kepada perkataan itu. Walau bagaimanapun, sebaik sahaja output perhatian kendiri dijana, lapisan suapan hadapan tidak mempunyai kebergantungan ini, jadi laluan individu boleh dilaksanakan secara selari semasa ia melalui lapisan hadapan suapan. Ini adalah ciri yang sangat berguna dalam kes pengekod Transformer, yang memproses setiap perkataan input selari dengan perkataan lain selepas lapisan perhatian diri. Walau bagaimanapun, ciri ini tidak begitu penting untuk penyahkod, kerana ia hanya menghasilkan satu perkataan pada satu masa dan tidak menggunakan laluan perkataan selari.
Masa berjalan seni bina Transformer berskala kuadratik dengan panjang jujukan input, yang bermaksud pemprosesan boleh menjadi perlahan apabila memproses dokumen atau aksara yang panjang sebagai input. Dalam erti kata lain, semasa pembentukan perhatian kendiri, semua pasangan interaksi perlu dikira, yang bermaksud bahawa pengiraan berkembang secara kuadratik dengan panjang jujukan, iaitu, O(T^2 d), di mana T ialah panjang jujukan dan D ialah dimensi. Contohnya, sepadan dengan ayat mudah d=1000, T≤30⇒T^2≤900⇒T^2d≈900K. Dan untuk saraf yang beredar, ia hanya tumbuh secara linear.
Bukankah bagus jika Transformer tidak perlu mengira interaksi berpasangan antara setiap pasangan perkataan dalam ayat? Terdapat kajian menunjukkan bahawa tahap prestasi yang agak tinggi boleh dicapai tanpa mengira interaksi antara semua pasangan perkataan (cth. dengan menganggarkan perhatian berpasangan).
Berbanding dengan CNN, Transformer mempunyai keperluan data yang sangat tinggi. CNN masih cekap sampel, yang menjadikannya pilihan yang sangat baik untuk tugas sumber rendah. Ini adalah benar terutamanya untuk tugas penjanaan imej/video, yang walaupun untuk seni bina CNN memerlukan sejumlah besar data (dengan itu membayangkan keperluan data yang sangat tinggi bagi seni bina Transformer). Sebagai contoh, seni bina CLIP baru-baru ini dicadangkan oleh Radford et al dilatih menggunakan ResNets berasaskan CNN sebagai tulang belakang visual (bukannya seni bina Transformer seperti ViT). Walaupun Transformers memberikan keuntungan ketepatan sebaik sahaja keperluan data mereka dipenuhi, CNN menyediakan cara untuk memberikan prestasi ketepatan yang baik dalam tugas yang jumlah data yang tersedia tidak begitu tinggi. Oleh itu, kedua-dua seni bina mempunyai kegunaannya.
Oleh kerana masa berjalan seni bina Transformer mempunyai hubungan kuadratik dengan panjang jujukan input. Iaitu, pengiraan perhatian pada semua pasangan perkataan memerlukan bilangan tepi dalam graf untuk berkembang secara kuadratik dengan bilangan nod, iaitu, dalam ayat n-perkataan, Transformer perlu mengira n^2 pasangan perkataan. Ini bermakna bilangan parameter adalah besar (iaitu, penggunaan memori adalah tinggi), mengakibatkan kerumitan pengiraan yang tinggi. Keperluan pengkomputeran yang tinggi mempunyai kesan negatif pada kuasa dan hayat bateri, terutamanya untuk peranti mudah alih. Secara keseluruhan, untuk memberikan prestasi yang lebih baik (seperti ketepatan), Transformer memerlukan kuasa pengkomputeran yang lebih tinggi, lebih banyak data, hayat kuasa/bateri dan jejak memori.
Setiap algoritma pembelajaran mesin yang digunakan dalam amalan, daripada jiran terdekat kepada rangsangan kecerunan, datang dengan berat sebelah induktifnya sendiri tentang kategori yang lebih mudah dipelajari. Hampir semua algoritma pembelajaran mempunyai berat sebelah dalam mempelajari bahawa item yang serupa ("dekat" antara satu sama lain dalam beberapa ruang ciri) lebih berkemungkinan tergolong dalam kelas yang sama. Model linear, seperti regresi logistik, juga menganggap bahawa kategori boleh dipisahkan oleh sempadan linear, yang merupakan bias "keras" kerana model tidak dapat mempelajari perkara lain. Walaupun untuk regresi teratur, yang hampir selalu merupakan jenis yang digunakan dalam pembelajaran mesin, terdapat kecenderungan terhadap sempadan pembelajaran yang melibatkan sebilangan kecil ciri, dengan wajaran ciri yang rendah Ini adalah berat sebelah "lembut" kerana model boleh belajar Melibatkan banyak kelas sempadan dengan ciri berat tinggi, tetapi ini lebih sukar/memerlukan lebih banyak data.
Malah model pembelajaran mendalam mempunyai bias inferens Sebagai contoh, rangkaian saraf LSTM sangat berkesan untuk tugas pemprosesan bahasa semula jadi kerana ia lebih suka mengekalkan maklumat kontekstual berbanding urutan yang panjang.

Memahami pengetahuan domain dan kesukaran masalah boleh membantu kami memilih aplikasi algoritma yang sesuai. Sebagai contoh, masalah mengekstrak istilah yang relevan daripada rekod klinikal untuk menentukan sama ada pesakit telah didiagnosis dengan kanser. Dalam kes ini, regresi logistik berfungsi dengan baik kerana terdapat banyak istilah bermaklumat bebas. Untuk masalah lain, seperti mengekstrak keputusan ujian genetik daripada laporan PDF yang kompleks, menggunakan LSTM boleh mengendalikan konteks jarak jauh setiap perkataan dengan lebih baik, menghasilkan prestasi yang lebih baik. Setelah algoritma asas dipilih, memahami biasnya juga boleh membantu kami melaksanakan kejuruteraan ciri, proses memilih maklumat untuk dimasukkan ke dalam algoritma pembelajaran.
Setiap struktur model mempunyai kecenderungan inferens yang wujud yang membantu memahami corak dalam data, dengan itu membolehkan pembelajaran. Contohnya, CNN mempamerkan perkongsian parameter spatial dan terjemahan/invarian ruang, manakala RNN mempamerkan perkongsian parameter temporal.
Pengekod lama cuba membandingkan dan menganalisis Transformer, CNN, RNN/GRU/LSTM dalam seni bina pembelajaran mendalam, dan memahami bahawa Transformer boleh mempelajari kebergantungan yang lebih lama, tetapi ia memerlukan Keperluan data dan kuasa pengkomputeran yang lebih tinggi; Transformer sesuai untuk tugasan pelbagai mod dan boleh bertukar dengan lancar antara deria seperti membaca/melihat, bercakap dan mendengar setiap struktur model mempunyai kecenderungan inferens yang wujud yang membantu memahami model data untuk mencapai pembelajaran .
【Rujukan】
Atas ialah kandungan terperinci Analisis perbandingan seni bina pembelajaran mendalam. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 html kepada txt
html kepada txt
 pemapar gambar windows tidak boleh memaparkan daripada memori
pemapar gambar windows tidak boleh memaparkan daripada memori
 Pengaturcaraan bahasa peringkat tinggi
Pengaturcaraan bahasa peringkat tinggi
 Bagaimana untuk mengubah suai pendaftaran
Bagaimana untuk mengubah suai pendaftaran
 Adakah perlu untuk menaik taraf windows 11?
Adakah perlu untuk menaik taraf windows 11?
 apa itu wechat
apa itu wechat
 Adakah OnePlus atau Honor lebih baik?
Adakah OnePlus atau Honor lebih baik?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



