


Xi Xiaoyao Technology Talk Original
Author|Small play, Python
Jika anda seorang pemula dalam model besar, anda akan membuat kekecohan apabila anda mula-mula melihat gabungan perkataan yang pelik seperti GPT, PaLm , dan LLaMA Apakah pendapat anda? Jika saya pergi lebih dalam dan melihat perkataan aneh seperti BERT, BART, RoBERTa, dan ELMo muncul satu demi satu, saya tertanya-tanya adakah saya, sebagai orang baru, akan menjadi gila?
Malah seorang veteran yang telah lama berada dalam bulatan kecil NLP, dengan kelajuan pembangunan model besar yang meletup, mungkin keliru dan tidak dapat mengikuti model besar yang berubah dengan pantas ini digunakan oleh puak mana? Pada masa ini, anda mungkin perlu meminta semakan model besar untuk membantu! Kajian model besar ini "Memanfaatkan Kuasa LLM dalam Amalan: Tinjauan tentang ChatGPT dan Seterusnya" yang dilancarkan oleh penyelidik dari Amazon, Texas A&M University dan Rice University memberi kita cara untuk membina "pokok keluarga" Artikel ini telah mempelajari tentang masa lalu, masa kini dan masa depan model besar yang diwakili oleh ChatGPT, dan berdasarkan tugas, ia telah membina panduan praktikal yang sangat komprehensif untuk model besar, memperkenalkan kepada kami kelebihan dan kekurangan model besar dalam tugas yang berbeza, dan akhirnya menunjukkan semasa risiko dan cabaran model.
Tajuk kertas:
Memanfaatkan Kuasa LLM dalam Amalan: Tinjauan tentang ChatGPT dan Seterusnya
Pautan kertas: //m.sbmmt.com/link/ f50fb34f27bd263e6be8ffcf8967ced0
Laman utama projek://m.sbmmt.com/link/968b15768f3d19770471e9436ddepan pokok.>
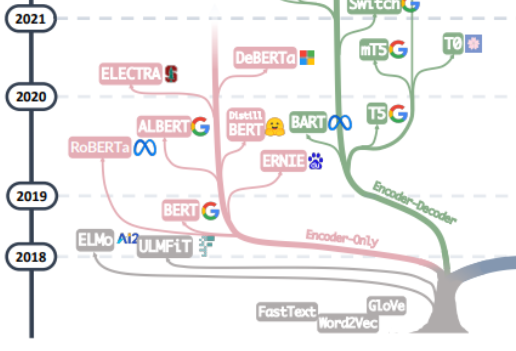 Sayang sekali pendekatan Bert gagal menembusi Undang-undang Skala, dan perkara ini ditentukan oleh kuasa utama model besar semasa, iaitu laluan lain untuk pembangunan model besar Keluarga GPT telah benar-benar mencapai ini dengan meninggalkan bahagian Pengekod dan berdasarkan bahagian Penyahkod. Kejayaan keluarga GPT datang daripada penemuan mengejutkan penyelidik: "Memperluas saiz model bahasa boleh meningkatkan keupayaan pembelajaran sifar pukulan (sifar pukulan) dan pukulan kecil (beberapa pukulan) ini konsisten dengan keluarga Bert berdasarkan penalaan halus Terdapat perbezaan yang besar, dan ia juga merupakan sumber kuasa ajaib model bahasa berskala besar hari ini. Keluarga GPT dilatih berdasarkan ramalan perkataan seterusnya memandangkan urutan perkataan sebelumnya Oleh itu, GPT pada mulanya hanya muncul sebagai model penjanaan teks, dan kemunculan GPT-3 adalah titik perubahan dalam nasib keluarga GPT-. 3 adalah yang pertama Ia menunjukkan kepada orang ramai keupayaan ajaib yang dibawa oleh model besar di luar penjanaan teks itu sendiri, dan menunjukkan keunggulan model bahasa autoregresif ini. Bermula dari GPT-3, ChatGPT, GPT-4, Bard, PaLM dan LLaMA semasa telah berkembang pesat, membawa kepada era semasa model besar.
Sayang sekali pendekatan Bert gagal menembusi Undang-undang Skala, dan perkara ini ditentukan oleh kuasa utama model besar semasa, iaitu laluan lain untuk pembangunan model besar Keluarga GPT telah benar-benar mencapai ini dengan meninggalkan bahagian Pengekod dan berdasarkan bahagian Penyahkod. Kejayaan keluarga GPT datang daripada penemuan mengejutkan penyelidik: "Memperluas saiz model bahasa boleh meningkatkan keupayaan pembelajaran sifar pukulan (sifar pukulan) dan pukulan kecil (beberapa pukulan) ini konsisten dengan keluarga Bert berdasarkan penalaan halus Terdapat perbezaan yang besar, dan ia juga merupakan sumber kuasa ajaib model bahasa berskala besar hari ini. Keluarga GPT dilatih berdasarkan ramalan perkataan seterusnya memandangkan urutan perkataan sebelumnya Oleh itu, GPT pada mulanya hanya muncul sebagai model penjanaan teks, dan kemunculan GPT-3 adalah titik perubahan dalam nasib keluarga GPT-. 3 adalah yang pertama Ia menunjukkan kepada orang ramai keupayaan ajaib yang dibawa oleh model besar di luar penjanaan teks itu sendiri, dan menunjukkan keunggulan model bahasa autoregresif ini. Bermula dari GPT-3, ChatGPT, GPT-4, Bard, PaLM dan LLaMA semasa telah berkembang pesat, membawa kepada era semasa model besar.
 Daripada menggabungkan dua cabang salasilah keluarga ini, anda boleh melihat hari-hari awal Word2Vec dan FastText, hingga penerokaan awal model pra-latihan ELMo dan ULFMiT, dan kemudian kepada Bert Hengkong Ia adalah hit, tetapi keluarga GPT bekerja secara senyap-senyap sehingga debut menakjubkan GPT-3 ChatGPT melonjak ke langit Selain daripada lelaran teknologi, kita juga dapat melihat bahawa OpenAI secara senyap mematuhi teknikalnya sendiri laluan dan akhirnya menjadi peneraju LLM yang tidak dapat dipertikaikan Lihat Kami telah melihat sumbangan teori utama Google kepada keseluruhan seni bina model Pengekod-Penyahkod, penyertaan berterusan Meta dalam projek sumber terbuka model besar, dan sudah tentu arah aliran LLM secara beransur-ansur bergerak ke arah "tertutup. ” sumber sejak GPT-3 Besar kemungkinan pada masa hadapan kebanyakan penyelidikan perlu menjadi penyelidikan Berasaskan API.
Daripada menggabungkan dua cabang salasilah keluarga ini, anda boleh melihat hari-hari awal Word2Vec dan FastText, hingga penerokaan awal model pra-latihan ELMo dan ULFMiT, dan kemudian kepada Bert Hengkong Ia adalah hit, tetapi keluarga GPT bekerja secara senyap-senyap sehingga debut menakjubkan GPT-3 ChatGPT melonjak ke langit Selain daripada lelaran teknologi, kita juga dapat melihat bahawa OpenAI secara senyap mematuhi teknikalnya sendiri laluan dan akhirnya menjadi peneraju LLM yang tidak dapat dipertikaikan Lihat Kami telah melihat sumbangan teori utama Google kepada keseluruhan seni bina model Pengekod-Penyahkod, penyertaan berterusan Meta dalam projek sumber terbuka model besar, dan sudah tentu arah aliran LLM secara beransur-ansur bergerak ke arah "tertutup. ” sumber sejak GPT-3 Besar kemungkinan pada masa hadapan kebanyakan penyelidikan perlu menjadi penyelidikan Berasaskan API.

Dalam analisis akhir, adakah kuasa ajaib model besar datang daripada GPT? Saya rasa jawapannya adalah tidak. Hampir setiap lonjakan dalam keupayaan keluarga GPT telah membuat peningkatan penting dalam kuantiti, kualiti dan kepelbagaian data pra-latihan. Data latihan model besar termasuk buku, artikel, maklumat laman web, maklumat kod, dsb. Tujuan memasukkan data ini ke dalam model besar adalah untuk mencerminkan sepenuhnya dan tepat "manusia" dengan memberitahu perkataan model besar, tatabahasa, sintaks dan maklumat semantik membolehkan model memperoleh keupayaan untuk mengenali konteks dan menjana tindak balas yang koheren untuk menangkap aspek pengetahuan manusia, bahasa, budaya, dsb.
Secara umumnya, menghadapi banyak tugasan NLP, kami boleh mengklasifikasikannya kepada sampel sifar, beberapa sampel dan banyak sampel dari perspektif maklumat anotasi data. Tidak dinafikan, LLM ialah kaedah yang paling sesuai untuk tugasan sifar. Pada masa yang sama, tugasan beberapa sampel juga sangat sesuai untuk aplikasi model besar Dengan memaparkan pasangan "soal-jawab" untuk model besar, prestasi model besar boleh dipertingkatkan Pendekatan ini juga biasanya dipanggil Dalam Konteks Pembelajaran. Walaupun model besar juga boleh merangkumi tugas berbilang sampel, penalaan halus mungkin masih menjadi kaedah terbaik, di bawah beberapa kekangan seperti privasi dan pengkomputeran, model besar mungkin masih berguna.

Pada masa yang sama, model yang diperhalusi berkemungkinan menghadapi masalah perubahan dalam pengedaran data latihan dan data ujian Secara ketara, model yang diperhalusi secara amnya berfungsi dengan baik pada data OOD. Sejajar dengan itu, LLM berprestasi lebih baik kerana mereka tidak mempunyai proses pemadanan yang jelas. Pembelajaran pengukuhan ChatGPT biasa berdasarkan maklum balas manusia (RLHF) berprestasi baik dalam kebanyakan tugas klasifikasi dan terjemahan di luar pengedaran. Ia juga berfungsi dengan baik pada DDXPlus, a dataset diagnostik perubatan yang direka untuk penilaian OOD.
Banyak kali, pernyataan "Model besar adalah bagus!" mereka?" "Apabila berhadapan dengan tugas tertentu, patutkah kita memilih penalaan halus atau mula menggunakan model besar tanpa berfikir? Kertas kerja ini meringkaskan "aliran membuat keputusan" praktikal untuk membantu kita menilai sama ada akan menggunakan model besar berdasarkan beberapa soalan seperti "sama ada perlu meniru manusia", "sama ada keupayaan penaakulan diperlukan", "sama ada adalah pelbagai tugas".
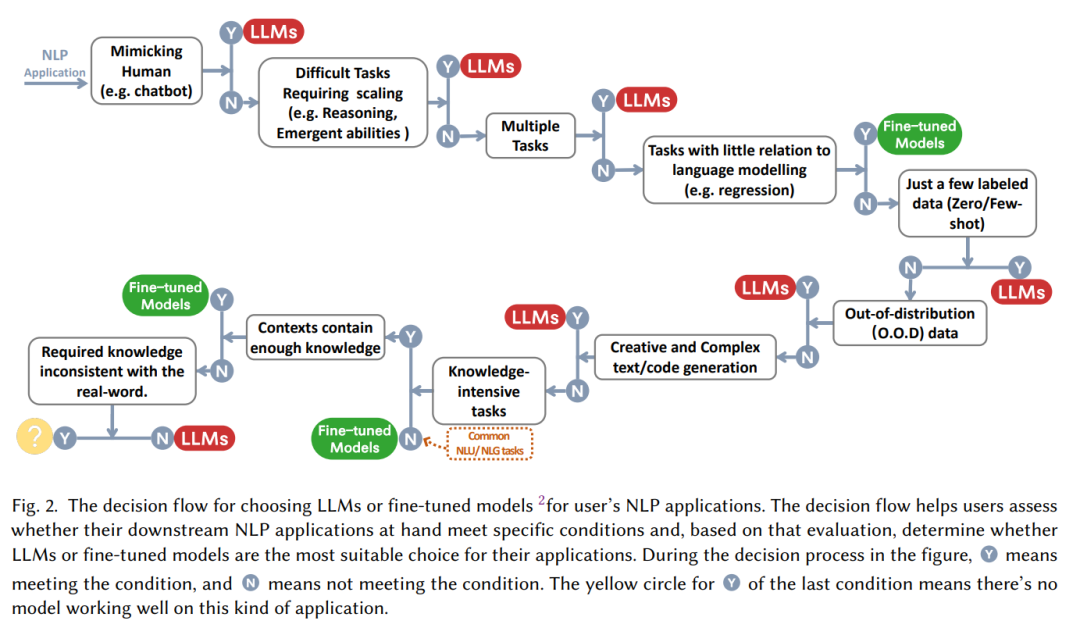
Dari perspektif klasifikasi tugas NLP:
Pada masa ini terdapat sejumlah besar data berlabel kaya Untuk banyak tugasan NLP, model yang diperhalusi mungkin masih mempunyai kelebihan yang kukuh Dalam kebanyakan set data, LLM adalah lebih rendah daripada model yang diperhalusi. LLM secara amnya Lebih rendah daripada model yang diperhalusi;
Berbanding dengan pemahaman bahasa semula jadi, penjanaan bahasa semula jadi mungkin peringkat untuk model besar. Matlamat utama penjanaan bahasa semula jadi adalah untuk mencipta urutan yang koheren, lancar dan bermakna Ia biasanya boleh dibahagikan kepada dua kategori Satu ialah tugasan yang diwakili oleh terjemahan mesin dan ringkasan maklumat perenggan, dan satu lagi adalah tugasan yang lebih terbuka seperti menulis e-mel, menulis berita, mencipta cerita, dsb. Khususnya:
Pemahaman bahasa berbilang tugas berskala besar: Pemahaman bahasa berbilang tugasan berskala besar (MMLU) mengandungi 57 soalan aneka pilihan mengenai topik yang berbeza, dan juga memerlukan model mempunyai umum Dalam hal ini Tugas yang paling mengagumkan ialah GPT-4, yang mencapai ketepatan 86.5% dalam MMLU.
Model besar sudah pasti akan menjadi sebahagian daripada kerja dan kehidupan kami untuk masa yang lama pada masa hadapan, dan untuk "lelaki besar" sedemikian yang sangat interaktif dengan kami kehidupan, Sebagai tambahan kepada prestasi, kecekapan, kos dan isu-isu lain, isu keselamatan model bahasa berskala besar hampir menjadi keutamaan di antara semua cabaran yang dihadapi oleh model besar Halusinasi mesin adalah masalah utama model besar yang pada masa ini tidak mempunyai kecemerlangan penyelesaian, keluaran halusinasi berat sebelah atau berbahaya oleh model besar akan membawa akibat yang serius kepada pengguna. Pada masa yang sama, apabila "kredibiliti" LLM meningkat, pengguna mungkin menjadi terlalu bergantung kepada LLM dan percaya bahawa mereka boleh memberikan maklumat yang tepat Aliran yang boleh diramal ini meningkatkan risiko keselamatan model besar.
Selain maklumat yang mengelirukan, disebabkan kualiti tinggi dan kos teks yang rendah yang dijana oleh LLM, LLM mungkin dieksploitasi sebagai alat untuk serangan seperti kebencian, diskriminasi, keganasan dan maklumat yang salah diserang tanpa niat jahat. Penyerang memberikan maklumat haram atau mencuri privasi Menurut laporan, pekerja Samsung secara tidak sengaja membocorkan data rahsia seperti atribut kod sumber program terkini dan rekod mesyuarat dalaman yang berkaitan dengan perkakasan semasa menggunakan ChatGPT untuk mengendalikan kerja.
Selain itu, kunci kepada sama ada model besar boleh digunakan dalam bidang sensitif, seperti penjagaan kesihatan, kewangan, undang-undang, dll., terletak pada isu "kredibiliti " bagi model besar, pada masa ini, keteguhan model besar dengan sampel sifar sering berkurangan. Pada masa yang sama, LLM telah terbukti berat sebelah atau diskriminasi dari segi sosial, dengan banyak kajian memerhatikan perbezaan prestasi yang ketara antara kategori demografi seperti loghat, agama, jantina dan bangsa. Ini boleh membawa kepada isu "keadilan" untuk model besar.
Akhirnya, jika kita melepaskan diri daripada isu sosial untuk membuat ringkasan, kita juga boleh melihat masa depan penyelidikan model besar Cabaran utama yang dihadapi oleh model besar pada masa ini boleh diklasifikasikan seperti berikut:
Atas ialah kandungan terperinci Kajian model besar ada di sini! Satu artikel akan membantu anda menjelaskan sejarah evolusi model besar gergasi AI global. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



