


Saya melihat artikel hari ini, mengatakan bahawa Google membocorkan dokumen "Kami tidak mempunyai parit, dan OpenAI juga tidak menerangkan pandangan pekerja Google tertentu (bukan syarikat Google) pada sumber terbuka AI sangat menarik, kira-kira Maksudnya ialah:
Selepas ChatGPT menjadi popular, pengeluar utama telah berpusu-pusu ke LLM dan melabur secara gila-gila.
Google juga bekerja keras, berharap untuk membuat kemunculan semula, tetapi tiada siapa yang boleh memenangi perlumbaan senjata ini kerana pihak ketiga sedang makan kek besar ini secara senyap-senyap.
Pihak ketiga ini ialah model sumber terbuka yang besar.
Model besar sumber terbuka telah pun melakukan perkara ini:
1 Jalankan model asas pada Pixel 6 pada kelajuan 5 token sesaat.
2. Anda boleh memperhalusi AI diperibadikan pada PC anda dalam satu malam:
Walaupun model OpenAI dan Google mempunyai kelebihan dalam kualiti, Jurangnya adalah ditutup pada kadar yang membimbangkan:
Model sumber terbuka lebih pantas, boleh disesuaikan, lebih peribadi dan lebih berkuasa.
Model besar sumber terbuka melakukan perkara dengan parameter $100 dan 13B dan menyelesaikannya dalam beberapa minggu manakala Google bergelut dengan parameter $10 juta dan 540B dalam beberapa bulan;
Apabila alternatif percuma dan tanpa had bersaing dalam kualiti dengan model tertutup, orang ramai pasti akan meninggalkan model tertutup.
Semuanya bermula apabila LLaMA sumber terbuka Facebook pada awal Mac, komuniti sumber terbuka mendapat model asas yang benar-benar berkebolehan ini Walaupun tiada arahan, penalaan perbualan atau RLHF, komuniti segera menyedari kepentingan ini perkara.
Inovasi seterusnya adalah gila, malah diukur dalam beberapa hari:
2-24: Facebook melancarkan LLaMA, yang hanya dilesenkan untuk digunakan oleh institusi penyelidikan dan organisasi kerajaan pada masa ini
3-03: LLaMA telah bocor di Internet Walaupun penggunaan komersial tidak dibenarkan, tiba-tiba sesiapa sahaja boleh memainkannya.
3-12: Menjalankan LLaMA pada Raspberry Pi adalah sangat perlahan dan tidak praktikal
3-13: Stanford mengeluarkan Alpaca dan menambah penalaan arahan untuk LLaMA, yang lebih "menakutkan" Ya, Eric J. Wang dari Stanford menggunakan kad grafik RTX 4090 untuk melatih model yang setara dengan Alpaca dalam masa 5 jam sahaja, mengurangkan keperluan kuasa pengkomputeran model sedemikian kepada tahap pengguna.
3-18: 5 hari kemudian, Georgi Gerganov menggunakan teknologi pengkuantitian 4-bit untuk menjalankan LLaMA pada CPU MacBook, yang merupakan penyelesaian "tanpa GPU" yang pertama.
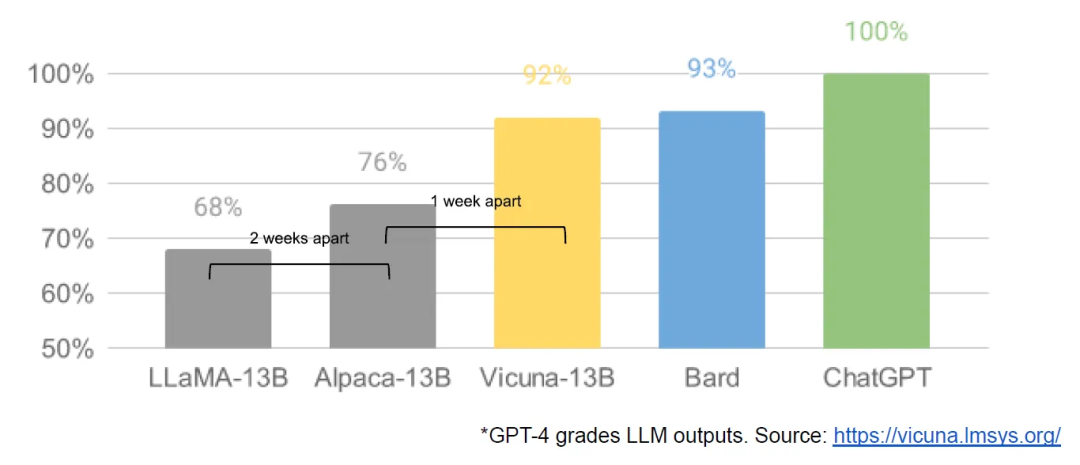
3-19: Hanya sehari kemudian, penyelidik dari University of California, Berkeley, CMU, Stanford University, dan University of California, San Diego bersama-sama melancarkan Vicuna, yang mendakwa telah mencapai lebih daripada 90% kualiti OpenAI ChatGPT dan Google Bard Ia juga mengatasi model lain seperti LLaMA dan Stanford Alpaca dalam lebih daripada 90% kes.
3-25: Nomic mencipta GPT4all, yang merupakan model dan ekosistem Buat pertama kalinya, kami melihat berbilang model berkumpul di satu tempat
…
Di. hanya sebulan, penalaan arahan, kuantisasi, peningkatan kualiti, penilaian manusia, multimodaliti, RLHF, dsb. semuanya muncul.
Lebih penting lagi, komuniti sumber terbuka telah menyelesaikan masalah kebolehskalaan, dan ambang untuk latihan telah diturunkan daripada syarikat besar kepada satu orang, satu malam dan komputer peribadi yang berkuasa.
Jadi penulis berkata pada akhirnya: OpenAI juga melakukan kesilapan seperti kami, dan ia tidak dapat menahan kesan sumber terbuka. Kita perlu membina ekosistem untuk menjadikan sumber terbuka berfungsi untuk Google.
Google telah pun melaksanakan paradigma ini pada Android dan Chrome dengan kejayaan yang cemerlang. Anda harus menetapkan diri anda sebagai pemimpin dalam sumber terbuka model besar dan terus mengukuhkan kedudukan anda sebagai pemimpin pemikiran dan pemimpin.
Sejujurnya, perkembangan model bahasa yang besar pada bulan lalu atau lebih telah benar-benar mempesonakan dan mengagumkan, dan saya dihujani setiap hari.
Ini mengingatkan saya pada hari-hari awal ketika Internet baru bermula Satu tapak web yang menarik muncul hari ini, dan satu lagi muncul esok. Dan apabila Internet mudah alih meletup, satu apl popular hari ini dan satu lagi apl popular esok...
Secara peribadi, saya tidak mahu model bahasa besar ini dikawal oleh syarikat gergasi. Adalah lebih baik untuk membiarkan seratus bunga mekar dan boleh diakses oleh orang ramai, supaya semua orang boleh membina model peribadi mereka sendiri.
Kini kos latihan sepatutnya berpatutan untuk syarikat kecil Jika pengaturcara mempunyai keupayaan untuk melatih, ia mungkin peluang yang baik untuk menggabungkannya dengan industri dan bidang tertentu.
Jika pengaturcara ingin mahir dalam model penswastaan berskala besar, sebagai tambahan kepada prinsip, mereka masih perlu berlatih sendiri Terdapat juga berpuluh-puluh orang di planet kita berlatih dalam pasukan komuniti telah banyak mengurangkan kos, ia masih memerlukan saya ingin melatih model yang berguna, tetapi keperluan persekitaran perkakasan untuk perkara ini masih terlalu tinggi RTX4090 berharga berpuluh-puluh ribu, yang menyakitkan menyewa GPU untuk latihan dalam awan adalah lebih tidak terkawal Jika latihan gagal, wang akan hilang dengan sia-sia.
Saya harap ambang akan diturunkan lagi!
Atas ialah kandungan terperinci Dokumen dalaman Google bocor: Model besar sumber terbuka terlalu menakutkan, malah OpenAI tidak tahan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



