


Selepas memasuki era pra-latihan, prestasi model pengecaman visual telah berkembang pesat, tetapi model penjanaan imej, seperti rangkaian musuh generatif (GAN), nampaknya ketinggalan.
Biasanya latihan GAN dilakukan dari awal tanpa pengawasan, yang memakan masa dan memerlukan tenaga kerja "pengetahuan" yang dipelajari melalui data besar dalam pra-latihan berskala besar tidak digunakan rugi besar?
Selain itu, penjanaan imej itu sendiri perlu dapat menangkap dan mensimulasikan data statistik yang kompleks dalam fenomena visual dunia sebenar, jika tidak, imej yang dijana tidak akan mematuhi undang-undang dunia fizikal dan akan dikenal pasti secara langsung sebagai "palsu" sekali pandang.

Model pra-latihan memberikan pengetahuan dan model GAN menyediakan keupayaan penjanaan Gabungan kedua-duanya mungkin satu perkara yang cantik.
Persoalannya, model pra-latihan manakah dan cara menggabungkannya boleh meningkatkan keupayaan penjanaan model GAN?
Baru-baru ini, penyelidik dari CMU dan Adobe menerbitkan artikel dalam CVPR 2022, menggabungkan latihan model pra-latihan dengan model GAN melalui "pemilihan".

Pautan kertas: https://arxiv.org/abs/2112.09130
Pautan projek: https://github.com/nupurkmr9/vision- aided-gan
Pautan video: https://www.youtube.com/watch?v=oHdyJNdQ9E4
Proses latihan model GAN terdiri daripada diskriminator dan penjana, di mana diskriminator Penjana digunakan untuk mempelajari statistik berkaitan yang membezakan sampel sebenar daripada sampel yang dijana, manakala matlamat penjana adalah untuk menjadikan imej yang dihasilkan selaras mungkin dengan pengedaran sebenar.
Sebaik-baiknya, pendiskriminasi harus dapat mengukur jurang pengedaran antara imej yang dijana dan imej sebenar.
Walau bagaimanapun, apabila jumlah data sangat terhad, secara langsung menggunakan model pra-latihan berskala besar kerana diskriminator boleh dengan mudah menyebabkan penjana "dihancurkan secara kejam" dan kemudian "terlalu pas".
Melalui percubaan pada set data FFHQ 1k, walaupun kaedah peningkatan data boleh dibezakan terkini digunakan, diskriminator masih akan dipasang secara berlebihan Prestasi set latihan adalah sangat kuat, tetapi ia berprestasi sangat teruk pada set pengesahan .
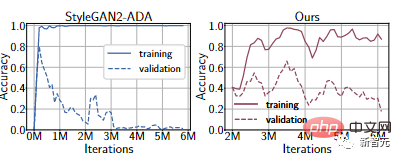
Selain itu, diskriminasi mungkin menumpukan pada penyamaran yang tidak dapat dibezakan oleh manusia tetapi jelas kepada mesin.
Untuk mengimbangi keupayaan diskriminasi dan penjana, penyelidik mencadangkan untuk mengumpulkan perwakilan set model pra-latihan yang berbeza sebagai diskriminator.
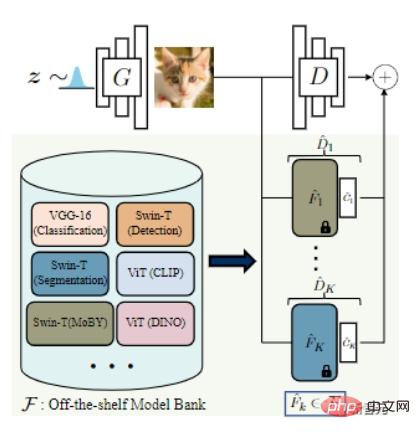
Kaedah ini mempunyai dua faedah:
1 Melatih pengelas cetek pada ciri pra-latihan membolehkan rangkaian dalam menyesuaikan diri dengan skala kecil Kaedah biasa untuk set data sambil mengurangkan overfitting.
Maksudnya, selagi parameter model pra-latihan ditetapkan, dan kemudian rangkaian pengelasan ringan ditambah ke lapisan atas, proses latihan yang stabil boleh disediakan.
Sebagai contoh, daripada lengkung Ours dalam percubaan di atas, anda dapat melihat bahawa ketepatan set pengesahan jauh lebih baik berbanding StyleGAN2-ADA.
2. Beberapa kajian terkini telah membuktikan bahawa rangkaian dalam boleh menangkap konsep visual yang bermakna, daripada isyarat visual peringkat rendah (tepi dan tekstur) kepada konsep peringkat tinggi (objek dan bahagian objek).
Pendiskriminasi yang dibina berdasarkan ciri ini mungkin lebih selaras dengan persepsi manusia.
Dan menggabungkan berbilang model pra-latihan boleh mempromosikan penjana untuk memadankan pengedaran sebenar dalam ruang ciri yang berbeza dan saling melengkapi.
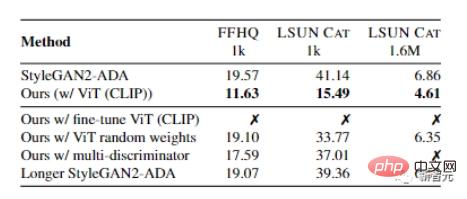
Untuk memilih rangkaian pra-latihan terbaik, para penyelidik mula-mula mengumpulkan beberapa model sota untuk membentuk "bank model", termasuk VGG-16 untuk pengelasan dan Swin-T untuk pengesanan dan pembahagian.
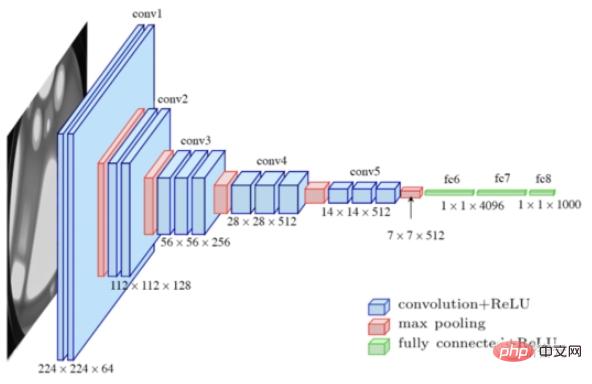
Kemudian, berdasarkan segmentasi linear imej sebenar dan palsu dalam ruang ciri, strategi carian model automatik dicadangkan, dan teknik pelicinan label dan boleh dibezakan digunakan untuk menstabilkan lagi latihan model untuk mengurangkan overfitting.
Khususnya, gabungan sampel latihan sebenar dan imej yang dijana dibahagikan kepada set latihan dan set pengesahan.
Untuk setiap model pra-latihan, latih diskriminator linear logistik untuk mengklasifikasikan sama ada sampel itu daripada sampel sebenar atau dijana, dan gunakan "kehilangan entropi silang binari negatif" pada pemisahan pengesahan untuk mengukur jurang pengedaran , dan Kembalikan model dengan ralat terkecil.
Ralat pengesahan yang lebih rendah dikaitkan dengan ketepatan pengesanan linear yang lebih tinggi, menunjukkan bahawa ciri ini berguna untuk membezakan sampel sebenar daripada sampel yang dijana dan menggunakan ciri ini boleh memberikan maklum balas yang lebih berguna kepada penjana.
Penyelidik Kami mengesahkan latihan GAN secara empirik menggunakan 1000 sampel latihan daripada set data FFHQ dan LSUN CAT.
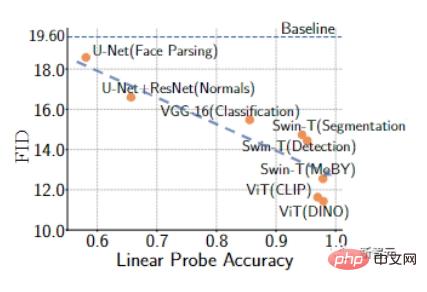
 Keputusan menunjukkan bahawa GAN yang dilatih dengan model pra-latihan mempunyai ketepatan pengesanan linear yang lebih tinggi dan, secara amnya, boleh mencapai penunjuk FID yang lebih baik.
Keputusan menunjukkan bahawa GAN yang dilatih dengan model pra-latihan mempunyai ketepatan pengesanan linear yang lebih tinggi dan, secara amnya, boleh mencapai penunjuk FID yang lebih baik.
Untuk menggabungkan maklum balas daripada berbilang model sedia, artikel itu turut meneroka dua strategi pemilihan dan penyepaduan model
1) Strategi pemilihan model tetap K, memilih yang terbaik K di permulaan latihan Model sedia dan latih sehingga penumpuan;
2) Strategi pemilihan model K-progresif, secara berulang memilih dan menambah model berprestasi terbaik dan tidak digunakan selepas bilangan lelaran tetap.
Keputusan eksperimen menunjukkan bahawa berbanding dengan strategi K-fixed, pendekatan progresif mempunyai kerumitan pengiraan yang lebih rendah dan juga membantu dalam memilih model pra-latihan untuk menangkap perbezaan dalam pengedaran data. Sebagai contoh, dua model pertama yang dipilih oleh strategi progresif biasanya merupakan sepasang model yang diselia sendiri dan diselia.
Eksperimen dalam artikel kebanyakannya progresif.
Algoritma latihan akhir mula-mula melatih GAN dengan kerugian lawan standard.

 Memandangkan penjana garis dasar, model pra-latihan terbaik boleh dicari menggunakan probing linear dan fungsi objektif kehilangan diperkenalkan semasa latihan.
Memandangkan penjana garis dasar, model pra-latihan terbaik boleh dicari menggunakan probing linear dan fungsi objektif kehilangan diperkenalkan semasa latihan.
Dalam strategi K-progresif, selepas latihan untuk bilangan lelaran tetap yang berkadar dengan bilangan sampel latihan sebenar yang tersedia, diskriminator bantuan visual baharu ditambah ke peringkat sebelumnya dengan set latihan terbaik Dalam petikan daripada FID.
Semasa latihan, penambahan data dilakukan dengan menyelak mendatar, dan teknik pembesaran yang boleh dibezakan dan pelicinan label sebelah pihak digunakan sebagai istilah penyelarasan.
Ia juga boleh diperhatikan bahawa menggunakan hanya model luar biasa sebagai diskriminasi membawa kepada perbezaan, manakala gabungan diskriminator asal dan model pra-latihan boleh memperbaiki keadaan ini.
Eksperimen akhir menunjukkan keputusan apabila sampel latihan set data FFHQ, LSUN CAT dan LSUN CHURCH berbeza dari 1k hingga 10k.
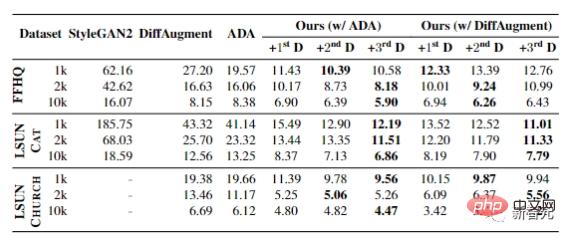
 Dalam semua tetapan, FID boleh mencapai peningkatan yang ketara, membuktikan keberkesanan kaedah ini dalam senario data terhad.
Dalam semua tetapan, FID boleh mencapai peningkatan yang ketara, membuktikan keberkesanan kaedah ini dalam senario data terhad.
Untuk menganalisis secara kualitatif perbezaan antara kaedah ini dan StyleGAN2-ADA, mengikut kualiti sampel yang dihasilkan oleh kedua-dua kaedah, kaedah baharu yang dicadangkan dalam artikel boleh meningkatkan kualiti sampel terburuk, terutamanya untuk FFHQ dan LSUN CAT

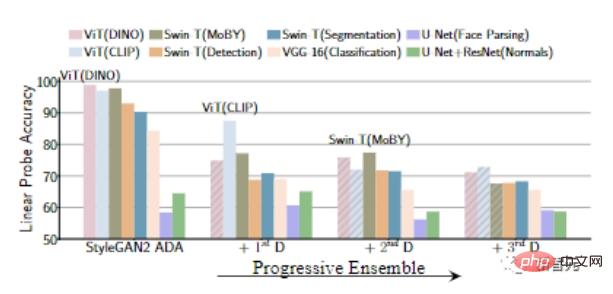
 Apabila kita menambah secara beransur-ansur diskriminator seterusnya, kita dapat melihat bahawa ketepatan pengesanan linear pada ciri model pra-latihan adalah secara beransur-ansur berkurangan, iaitu, Penjana lebih kuat.
Apabila kita menambah secara beransur-ansur diskriminator seterusnya, kita dapat melihat bahawa ketepatan pengesanan linear pada ciri model pra-latihan adalah secara beransur-ansur berkurangan, iaitu, Penjana lebih kuat.
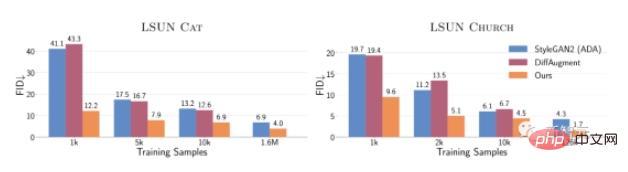
 Secara keseluruhan, dengan hanya 10,000 sampel latihan, kaedah ini menunjukkan prestasi yang lebih baik pada FID pada LSUN CAT berbanding latihan pada 1.6 juta imej Prestasi StyleGAN2 adalah serupa.
Secara keseluruhan, dengan hanya 10,000 sampel latihan, kaedah ini menunjukkan prestasi yang lebih baik pada FID pada LSUN CAT berbanding latihan pada 1.6 juta imej Prestasi StyleGAN2 adalah serupa.
 Pada set data penuh, kaedah ini meningkatkan FID sebanyak 1.5 hingga 2 kali ganda pada kategori kucing, gereja dan kuda LSUN.
Pada set data penuh, kaedah ini meningkatkan FID sebanyak 1.5 hingga 2 kali ganda pada kategori kucing, gereja dan kuda LSUN.

Pengarang Richard Zhang menerima PhD dari University of California, Berkeley, dan ijazah sarjana muda dan sarjananya dari Cornell University. Minat penyelidikan utama termasuk penglihatan komputer, pembelajaran mesin, pembelajaran mendalam, grafik dan pemprosesan imej, sering bekerja dengan penyelidik akademik melalui latihan atau universiti.

 Pengarang Jun-Yan Zhu ialah penolong profesor di Sekolah Robotik, Sekolah Sains Komputer, Universiti Carnegie Mellon, dan berkhidmat di Jabatan Komputer Sains dan Jabatan Pembelajaran Mesin ,Bidang penyelidikan utama termasuk penglihatan komputer, grafik komputer, pembelajaran mesin dan fotografi pengiraan.
Pengarang Jun-Yan Zhu ialah penolong profesor di Sekolah Robotik, Sekolah Sains Komputer, Universiti Carnegie Mellon, dan berkhidmat di Jabatan Komputer Sains dan Jabatan Pembelajaran Mesin ,Bidang penyelidikan utama termasuk penglihatan komputer, grafik komputer, pembelajaran mesin dan fotografi pengiraan.
Sebelum menyertai CMU, beliau adalah seorang saintis penyelidikan di Adobe Research. Beliau lulus dari Universiti Tsinghua dengan ijazah sarjana muda dan Ph.D dari University of California, Berkeley, dan kemudian bekerja sebagai felo pasca doktoral di MIT CSAIL.


Atas ialah kandungan terperinci CMU bergabung tenaga dengan Adobe: Model GAN menyambut era pra-latihan, hanya memerlukan 1% sampel latihan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



