


jieba ialah perpustakaan pihak ketiga yang sangat baik untuk segmentasi perkataan Cina. Oleh kerana setiap aksara Cina dalam teks bahasa Cina ditulis secara berterusan, kita perlu menggunakan kaedah tertentu untuk mendapatkan setiap perkataan di dalamnya Kaedah ini dipanggil pembahagian perkataan. Jieba ialah perpustakaan pihak ketiga yang sangat baik untuk pembahagian perkataan bahasa Cina dalam ekosistem pengkomputeran Python Anda perlu memasangnya untuk menggunakannya.
Perpustakaan jieba menyediakan tiga mod pembahagian perkataan, tetapi sebenarnya, untuk mencapai kesan pembahagian perkataan, cukup untuk menguasai satu fungsi sahaja, yang sangat mudah dan berkesan.
Untuk memasang perpustakaan pihak ketiga, anda perlu menggunakan alat pip dan jalankan arahan pemasangan pada baris arahan (bukan IDLE). Nota: Anda perlu menambah direktori Python dan direktori Skrip di bawahnya kepada pembolehubah persekitaran.
Gunakan arahan pip install jieba untuk memasang pustaka pihak ketiga Selepas pemasangan, ia akan berjaya dipasang dengan segera untuk memberitahu anda sama ada pemasangan itu berjaya.
Prinsip pembahagian perkataan: Ringkasnya, pangkalan data jieba mengenal pasti pembahagian perkataan melalui pangkalan data perbendaharaan kata bahasa Cina. Ia mula-mula menggunakan leksikon Cina untuk mengira kebarangkalian perkaitan antara aksara Cina melalui leksikon Oleh itu, dengan mengira kebarangkalian antara aksara Cina, hasil pembahagian perkataan boleh dibentuk. Sudah tentu, sebagai tambahan kepada perpustakaan perbendaharaan kata Cina jieba sendiri, pengguna juga boleh menambah frasa tersuai padanya, dengan itu menjadikan pembahagian perkataan jieba lebih dekat dengan penggunaan dalam bidang tertentu tertentu.
jieba ialah perpustakaan pembahagian perkataan bahasa Cina untuk ular sawa. Berikut ialah cara menggunakannya.
方式1: pip install jieba 方式2: 先下载 http://pypi.python.org/pypi/jieba/ 然后解压,运行 python setup.py install
Tiga mod yang biasa digunakan oleh jieba:
Mod tepat, Cuba potong ayat ke dalam bentuk yang paling tepat, sesuai untuk analisis teks
mod penuh, imbas semua perkataan dalam ayat yang boleh dibentuk menjadi perkataan, ia adalah sangat pantas, tetapi ia tidak dapat menyelesaikan kekaburan ;
Mod enjin carian, berdasarkan mod yang tepat, bahagikan semula perkataan panjang untuk meningkatkan kadar ingatan, sesuai untuk pembahagian perkataan enjin carian.
Anda boleh menggunakan kaedah jieba.cut dan jieba.cut_for_search untuk pembahagian perkataan Struktur yang dikembalikan oleh kedua-duanya ialah penjana boleh lelar Anda boleh menggunakan gelung for untuk mendapatkan setiap pembahagian perkataan. Satu perkataan (unicode), atau gunakan terus jieba.lcut dan jieba.lcut_for_search untuk mengembalikan senarai.
jieba.Tokenizer(dictionary=DEFAULT_DICT): Gunakan kaedah ini untuk menyesuaikan pembahagian perkataan dan menggunakan kamus yang berbeza pada masa yang sama. jieba.dt ialah pembahagian perkataan lalai, dan semua fungsi berkaitan pembahagian perkataan global ialah pemetaan pembahagian perkataan ini. Parameter yang boleh diterima untuk
jieba.cut dan jieba.lcut adalah seperti berikut:
Rentetan yang memerlukan pembahagian perkataan (rentetan unicode atau UTF-8, rentetan GBK)
cut_all: Sama ada hendak menggunakan mod penuh, nilai lalai ialah False
HMM: Digunakan untuk mengawal sama ada hendak menggunakan model HMM, nilai lalai ialah True
jieba.cut_for_search dan jieba.lcut_for_search menerima 2 parameter:
String untuk dibahagikan (unicode atau UTF -8 aksara Rentetan, rentetan GBK)
HMM: digunakan untuk mengawal sama ada hendak menggunakan model HMM, nilai lalai ialah True
Perlu diambil perhatian bahawa , cuba untuk tidak menggunakan rentetan GBK, yang mungkin tidak dapat diramalkan dan dinyahkod secara salah ke dalam UTF-8.
Perbandingan tiga mod pembahagian perkataan:
# 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']Pembangun boleh menentukan kamus tersuai mereka sendiri untuk memasukkan perkataan yang tiada dalam kamus jieba.
Penggunaan: jieba.load_userdict(dict_path)
dict_path: laluan ke fail kamus tersuai
Format kamus adalah seperti berikut:
Satu perkataan menduduki satu baris ; setiap baris dibahagikan kepada Tiga bahagian: perkataan, kekerapan perkataan (boleh diabaikan), sebahagian daripada pertuturan (boleh diabaikan), dipisahkan dengan ruang dan susunan tidak boleh diterbalikkan.
Yang berikut menggunakan contoh untuk menggambarkan:
Kamus tersuai user_dict.txt:
Kursus Universiti
Pembelajaran Mendalam
Berikut membandingkan perbezaan antara padanan tepat, padanan penuh dan menggunakan kamus tersuai:
import jieba
test_sent = """
数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程
"""
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度',
# '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
words = jieba.cut(test_sent, cut_all=True)
print(list(words))
# ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度',
# '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n']
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
jieba.add_word("尤其是")
jieba.add_word("线性代数课程")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']Seperti yang anda boleh lihat daripada contoh di atas, perbezaan antara menggunakan kamus tersuai dan menggunakan kamus lalai.
jieba.add_word(): Tambahkan perkataan pada kamus tersuai
Pengekstrakan kata kunci boleh berdasarkan algoritma TF-IDF atau algoritma TextRank . Algoritma TF-IDF ialah algoritma yang sama digunakan dalam elasticsearch.
Gunakan fungsi jieba.analyse.extract_tags() untuk pengekstrakan kata kunci, dengan parameter berikut:
jieba.analyse.extract_tags(ayat, topK=20, withWeight=False, allowPOS=( ) )
ayat ialah teks yang akan diekstrak
topK ialah mengembalikan beberapa kata kunci dengan berat TF/IDF terbesar, nilai lalai ialah 20
withWeight menunjukkan sama ada untuk mengembalikan nilai berat kata kunci juga Nilai lalai adalah Palsu
allowPOS hanya termasuk perkataan dengan yang ditentukan. sebahagian daripada pertuturan. Nilai lalai adalah kosong , iaitu, jangan tapis
jieba.analyse.TFIDF(idf_path=None) Buat contoh TFIDF baharu, idf_path ialah frekuensi IDF fail
也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法和TextRank算法的关键词抽取:
import jieba.analyse file = "sanguo.txt" topK = 12 content = open(file, 'rb').read() # 使用tf-idf算法提取关键词 tags = jieba.analyse.extract_tags(content, topK=topK) print(tags) # ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军'] # 使用textrank算法提取关键词 tags2 = jieba.analyse.textrank(content, topK=topK) # withWeight=True:将权重值一起返回 tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) print(tags) # [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849), # ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185), # ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038), # ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]
上面的代码是读取文件,提取出现频率最高的前12个词。
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
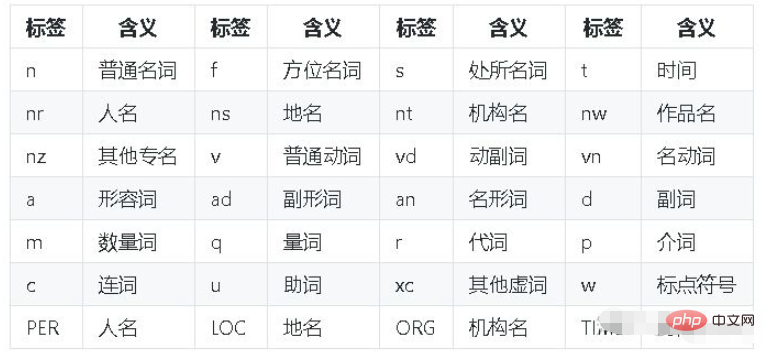
"""paddle模式的词性对照表如下:
jieba分词有三种模式:精确模式、全模式和搜索引擎模式。
简单说,精确模式就是把一段文本精确的切分成若干个中文单词,若干个中文单词之间经过组合就精确的还原为之前的文本,其中不存在冗余单词。精确模式是最常用的分词模式。
进一步jieba又提供了全模式,全模式是把一段中文文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式或者有不同的角度来切分变成不同的词语,那么jieba在全模式下把这样的不同的组合都挖掘出来,所以如果用全模式来进行分词,分词的信息组合起来并不是精确的原有文本,会有很多的冗余。
而搜索引擎模式更加智能,它是在精确模式的基础上对长词进行再次切分,将长的词语变成更短的词语,进而适合搜索引擎对短词语的索引和搜索,在一些特定场合用的比较多。
jieba.lcut(s)
精确模式,能够对一个字符串精确地返回分词结果,而分词的结果使用列表形式来组织。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.489 seconds.
Prefix dict has been built successfully.
['中国', '是', '一个', '伟大', '的', '国家']jieba.lcut(s,cut_all=True)
全模式,能够返回一个列表类型的分词结果,但结果存在冗余。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']jieba.lcut_for_search(s)
搜索引擎模式,能够返回一个列表类型的分词结果,也存在冗余。例如:
>>> import jieba
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']jieba.add_word(w)
向分词词库添加新词w
最重要的就是jieba.lcut(s)函数,完成精确的中文分词。
Atas ialah kandungan terperinci Bagaimana untuk menggunakan perpustakaan jieba dalam Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



